Chez OpenAI, nous avons constaté que l'échelle de bruit de gradient, une méthode statistique simple, prédit la parallélisabilité de l'apprentissage d'un réseau neutre à travers un large éventail de tâches. Étant donné que le gradient devient généralement plus bruyant pour les tâches plus complexes, une augmentation de la taille des paquets disponibles pour le traitement simultané s'avérera utile à l'avenir et éliminera l'une des limitations potentielles des systèmes d'IA. Dans le cas général, ces résultats montrent que l'entraînement des réseaux de neurones ne doit pas être considéré comme un art mystérieux, et qu'il peut être précis et systématisé.
Au cours des dernières années, les chercheurs en IA ont réussi de plus en plus à accélérer l'apprentissage des réseaux neuronaux en parallélisant les données, divisant de gros paquets de données en plusieurs ordinateurs. Les chercheurs ont utilisé avec succès des dizaines de milliers d'unités pour
la classification d'images et la
modélisation du langage , et même pour des millions
d'agents d'apprentissage renforçateurs qui ont joué à Dota 2. De tels gros packages peuvent augmenter la quantité de puissance de calcul qui est effectivement impliquée dans l'enseignement d'un modèle, et ne font qu'un des forces qui stimulent la
croissance de la
formation en IA. Cependant, avec des paquets de données trop volumineux, les retours algorithmiques diminuent rapidement et on ne sait pas pourquoi ces restrictions s'avèrent plus importantes pour certaines tâches et plus petites pour d'autres.
 La mise à l'échelle du bruit de gradient, calculée en moyenne sur les approches de formation, explique la majorité (r 2 = 80%) des variations critiques de la taille des paquets de données pour divers problèmes, différant de six ordres de grandeur. Les tailles de package sont mesurées en nombre d'images, de jetons (pour les modèles de langage) ou d'observations (pour les jeux).
La mise à l'échelle du bruit de gradient, calculée en moyenne sur les approches de formation, explique la majorité (r 2 = 80%) des variations critiques de la taille des paquets de données pour divers problèmes, différant de six ordres de grandeur. Les tailles de package sont mesurées en nombre d'images, de jetons (pour les modèles de langage) ou d'observations (pour les jeux).Nous avons constaté qu'en mesurant l'échelle du bruit de gradient, des statistiques simples qui déterminent numériquement le rapport signal / bruit dans les gradients du réseau, nous pouvons approximativement prédire la taille maximale du paquet. Heuristiquement, l'échelle de bruit mesure la variation des données du point de vue du modèle (à un stade particulier de la formation). Lorsque l'échelle de bruit est petite, l'apprentissage parallèle sur une grande quantité de données devient rapidement redondant, et lorsqu'elle est grande, nous pouvons apprendre beaucoup sur de grands ensembles de données.
Les statistiques de ce type sont largement utilisées pour
déterminer la taille de l' échantillon , et il a été
suggéré de les utiliser dans
l' apprentissage en
profondeur , mais elles n'ont pas été systématiquement utilisées pour la formation moderne des réseaux de neurones. Nous avons confirmé cette prédiction pour un large éventail de tâches d'apprentissage automatique décrites dans le graphique ci-dessus, y compris la reconnaissance des formes, la modélisation du langage, les jeux Atari et Dota. En particulier, nous avons formé des réseaux de neurones conçus pour résoudre chacun de ces problèmes sur des paquets de données de différentes tailles (en ajustant séparément la vitesse d'apprentissage pour chacun d'eux), et avons comparé l'accélération d'apprentissage avec celle prédite par l'échelle de bruit. Étant donné que les gros paquets de données nécessitent souvent un ajustement soigneux et coûteux ou un calendrier spécial de vitesse d'apprentissage pour que la formation soit efficace, en connaissant la limite supérieure à l'avance, vous pouvez obtenir un avantage significatif lors de la formation de nouveaux modèles.
Nous avons trouvé utile de visualiser les résultats de ces expériences comme un compromis entre le temps de formation réel et le montant total de calcul requis pour la formation (proportionnel à son coût en argent). Sur de très petits paquets de données, le doublement de la taille des paquets permet d'effectuer la formation deux fois plus rapidement sans utiliser de puissance de calcul supplémentaire (nous exécutons deux fois plus de threads individuels qui fonctionnent deux fois plus vite). Sur les très grandes maquettes de données, la parallélisation n'accélère pas l'apprentissage. La courbe dans les virages du milieu et l'échelle du bruit de gradient prédit où exactement le virage se produit.
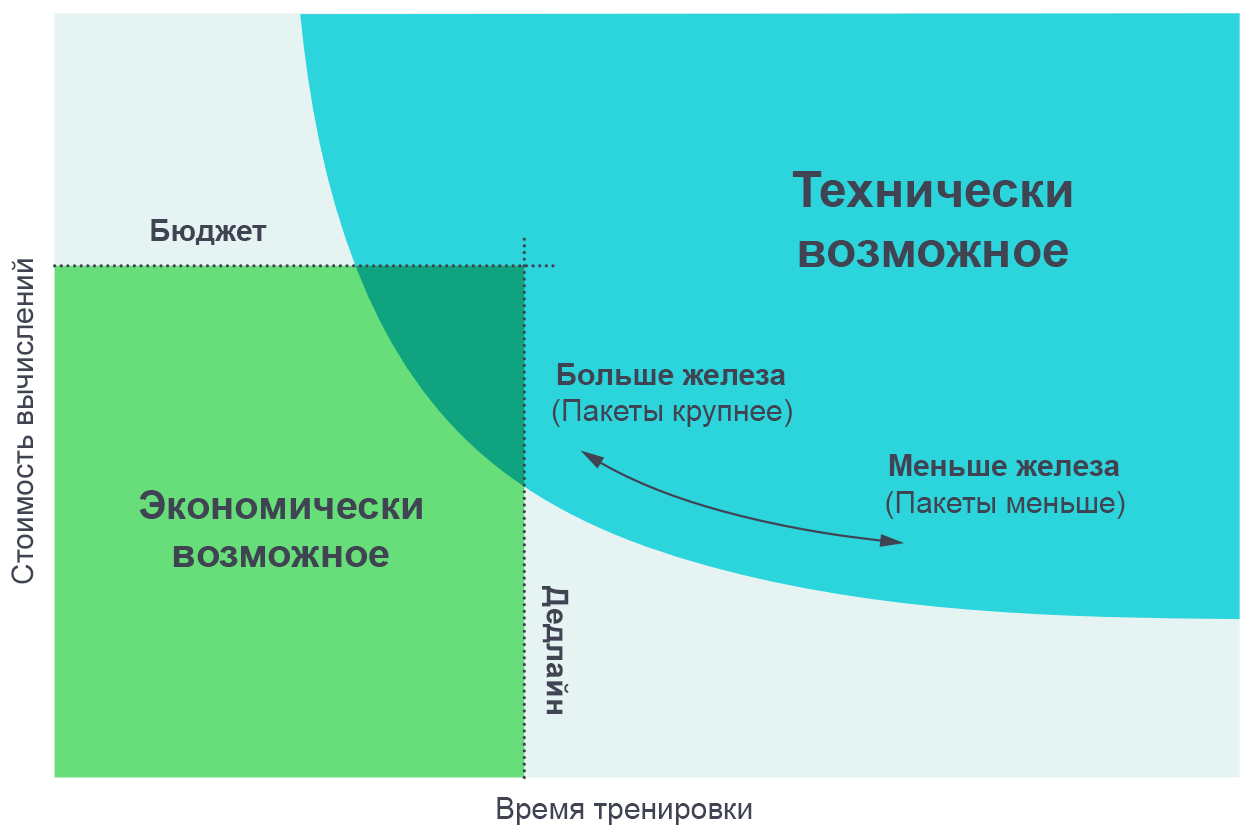 L'augmentation du nombre de processus parallèles vous permet de former des modèles plus complexes dans un délai raisonnable. Le diagramme de bordure de Pareto est le moyen le plus intuitif de visualiser les comparaisons d'algorithmes et d'échelles.
L'augmentation du nombre de processus parallèles vous permet de former des modèles plus complexes dans un délai raisonnable. Le diagramme de bordure de Pareto est le moyen le plus intuitif de visualiser les comparaisons d'algorithmes et d'échelles.Nous obtenons ces courbes en attribuant un objectif à la tâche (par exemple, 1000 points dans le jeu Atari Beam Rider), et en observant combien de temps il faut pour former le réseau neuronal pour atteindre cet objectif sur différentes tailles de paquets. Les résultats coïncident assez précisément avec les prédictions de notre modèle, en tenant compte des différentes valeurs des objectifs que nous nous sommes fixés.
[
La page avec l'article d'origine présente des graphiques interactifs d'un compromis entre l'expérience et le temps de formation nécessaire pour atteindre un objectif donné ]
Modèles d'échelle de bruit de gradient
Nous sommes tombés sur plusieurs modèles dans l'échelle du bruit de gradient, sur la base desquels nous pouvons faire des hypothèses sur l'avenir de la formation à l'IA.
Premièrement, dans nos expériences dans le processus d'apprentissage, l'échelle de bruit augmente généralement d'un ordre de grandeur ou plus. Apparemment, cela signifie que le réseau apprend des caractéristiques plus «évidentes» du problème au tout début de la formation, puis étudie les petits détails. Par exemple, dans la tâche de classification des images, un réseau de neurones peut d'abord apprendre à identifier les caractéristiques à petite échelle, telles que les bords ou les textures montrés sur la plupart des images, puis comparer ces petites choses ensemble plus tard, créant des concepts plus généraux, tels que les chats ou les chiens. Pour avoir une idée de toute la variété des visages et des textures, les réseaux de neurones doivent voir un petit nombre d'images, donc l'échelle de bruit est plus petite; dès que le réseau en saura plus sur les objets plus gros, il pourra traiter beaucoup plus d'images en même temps sans prendre en compte les données en double.
Nous avons vu quelques
indications préliminaires qu'un effet similaire fonctionne également sur d'autres modèles traitant du même ensemble de données - dans les modèles plus puissants, l'échelle du bruit de gradient est plus élevée, mais uniquement parce qu'ils ont moins de perte. Par conséquent, il existe des preuves que l'augmentation de l'échelle du bruit pendant la formation n'est pas seulement un artefact de convergence, mais est due à une amélioration du modèle. Si tel est le cas, alors nous pouvons nous attendre à ce que les modèles améliorés futurs aient une grande échelle de bruit et soient mieux adaptés à la parallélisation.
Deuxièmement, les tâches objectivement plus complexes se prêtent mieux à la parallélisation. Dans le contexte de l'enseignement avec un enseignant, des progrès évidents sont observés dans la transition du MNIST à SVHN et ImageNet. Dans le contexte de la formation par renforcement, des progrès nets sont observés dans la transition d'Atari Pong à
Dota 1v1 et
Dota 5v5 , et la taille du paquet de données optimal varie 10 000 fois. Par conséquent, alors que l'IA fait face à des tâches de plus en plus complexes, les modèles devraient faire face à des ensembles de données de plus en plus volumineux.
Les conséquences
Le degré de parallélisation des données affecte sérieusement la vitesse de développement des capacités d'IA. L'accélération de l'apprentissage permet de créer des modèles plus performants et accélère la recherche, vous permettant de raccourcir le temps de chaque itération.
Dans une étude antérieure, «
AI et calculs », nous avons vu que les calculs pour la formation des plus grands modèles doublent tous les 3,5 mois, et avons noté que cette tendance est basée sur une combinaison d'économie (le désir de dépenser de l'argent pour les calculs) et de capacités algorithmiques pour paralléliser l'apprentissage . Le dernier facteur (parallélisabilité algorithmique) est plus difficile à prévoir, et ses limites n'ont pas encore été entièrement étudiées, mais nos résultats actuels représentent un pas en avant dans sa systématisation et son expression numérique. En particulier, nous avons la preuve que des tâches plus complexes, ou des modèles plus puissants visant une tâche connue, permettront un travail plus parallèle avec les données. Ce sera un facteur clé soutenant la croissance exponentielle de l'informatique liée à l'apprentissage. Et nous ne considérons même pas
les développements récents dans le domaine des modèles parallèles, qui peuvent nous permettre d'améliorer encore la parallélisation en l'ajoutant au traitement de données parallèle existant.
La croissance continue du domaine de l'informatique d'entraînement et sa base algorithmique prévisible parlent de la possibilité d'une augmentation explosive des capacités de l'IA au cours des prochaines années, et soulignent la nécessité d'une
étude précoce
de l'utilisation sûre et
responsable de ces systèmes. La principale difficulté de la création d'une politique en matière d'IA sera de décider comment ces mesures peuvent être utilisées pour prédire les caractéristiques des futurs systèmes d'IA, et d'utiliser ces connaissances pour créer des règles permettant à la société de maximiser son utilité et de minimiser les dommages de ces technologies.
OpenAI prévoit de mener une analyse rigoureuse pour prédire l'avenir de l'IA et de répondre de manière proactive aux défis soulevés par cette analyse.