
Il était une fois, quand le ciel était bleu, l'herbe était plus verte et les dinosaures parcouraient la Terre ... Non, oubliez les dinosaures. Eh bien, en général, il était une fois l'idée de distraire de la programmation Web standard et de faire quelque chose de plus fou. Cela pourrait bien sûr être n'importe quoi, mais le choix s'est porté sur l'écriture de votre propre interprète. Que puis-je dire ...
N'écrivez jamais vos propres langages de programmation . Mais j'ai pris de l'expérience de tout cela, alors j'ai décidé de la partager. Commençons par le fondement même - le lexer.
Préface
Avant de commencer à comprendre de quel type de «lexer» l’animal, il vaut la peine de déterminer de quoi sont faits les YaP.
Dans le monde moderne, chaque compilateur / interprète / transpilateur / quelque chose d'autre (comme je l'appellerai simplement «compilateur», sans distinction de types) est divisé en deux parties. Dans la terminologie des oncles intelligents, ces éléments sont appelés «frontend» et «backend». Non, ce n'est pas du tout ce que, quand on travaille avec le web, ce qu'on a l'habitude d'appeler et le front n'est pas écrit en JS avec HTML. Bien que ... D'accord.
La première tâche du frontend est de prendre le
texte et de le transformer en
AST (arbre de syntaxe abstraite), en vérifiant la syntaxe (et parfois la sémantique) en cours de route. La tâche du second backend est de tout faire fonctionner. Si le code est assemblé à l'intérieur de l'interpréteur, l'AST crée un ensemble d'instructions pour le processeur virtuel (machine virtuelle), si le compilateur, puis l'ensemble d'instructions pour le processeur réel. Dans la vie, tout est beaucoup plus compliqué et peut ne pas être implémenté comme ça. Par exemple, dans le cas du compilateur GCC, tout est mélangé, mais Clang est déjà plus canonique, LLVM est un représentant typique du «backend» pour les compilateurs.
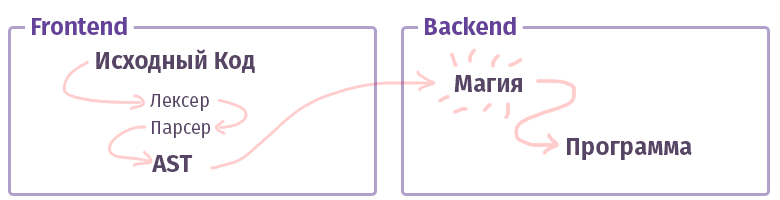
Maintenant, apprenons à connaître un morceau appelé le frontend.
Analyse lexicale
La tâche du lexer et du stade de l'analyse lexicale est d'obtenir de très nombreuses lettres à l'entrée et de les regrouper en certaines catégories - les «jetons». Par conséquent, l'analyse lexicale est également appelée «tokenisation». Il s'agit de la toute première étape du traitement de texte produite par chaque compilateur existant.
Quelque chose comme ça:
$tokens = ['class', '\w+', '}', '{']; var_dump(lex('class Example {}', $tokens));
Au fait, nous avons déjà écrit ici un tas d'outils pour vous faciliter la vie. Les mêmes fonctions
preg que nous avons utilisées pour analyser le texte sont tout à fait
capables de cette tâche. Cependant, il existe des outils plus pratiques à cet effet:
- Phlexy , écrit par Nikita Popov.
- Hoa est une boîte à outils composée de Lexer + Parser + Grammar.
- Port Yacc , écrit par Anthony Ferrara, qui est également une boîte à outils complète, et sur lequel l' analyseur PHP Popov bien connu est écrit, applicable dans les outils qui utilisent l'analyse de code.
- Railt Lexer mon implémentation pour PHP 7.1+
- Parle est une extension pour PHP qui autorise un ensemble limité d'expressions PCRE (pas d'anticipation et d'autres constructions de syntaxe).
- Et enfin, la fonction php standard token_get_all , qui est destinée directement à l'analyse lexicale de PHP.
Eh bien, il est clair qu'il y a beaucoup de gadgets qui peuvent diviser le texte en jetons, peut-être que j'ai même oublié quelque chose, comme le lexer
Doctrine . Mais quelle est la prochaine étape?
Types de Lexers
Et comme toujours, tout n'est pas aussi simple qu'il y paraissait. Il existe au moins deux catégories différentes de lexers. Il y a l'option habituelle, assez triviale, à laquelle vous glissez les règles, et elle divise déjà tout en jetons. La configuration de celui-ci n'est pas très différente de l'exemple montré par moi ci-dessus. Cependant, il existe une autre option appelée
multi-états . Ces lexers sont un peu plus difficiles à comprendre, donc je veux en parler un peu plus.
La tâche d'un lexer multi-états est d'afficher différents jetons en fonction de l'état précédent. Eh bien, par exemple, en PHP, de tels états "transitionnels" sont formés à l'aide des balises <? Php +?>, Des lignes internes, des commentaires et des constructions
HEREDOC /
NOWDOC .
Vous vous souvenez de l'exemple précédent avec 4 jetons ci-dessus? Modifions-le un peu pour comprendre quels sont ces états:
class Example {
Dans ce cas, si nous avons le lexer le plus simple sans les capacités étendues de PCRE, alors nous obtenons l'ensemble de jetons suivant:
var_dump(lex(...));
Comme vous pouvez le voir, nous avons obtenu un montant complètement banal sur les éléments 3 à 5: le commentaire a été pris de manière assez inattendue et a été divisé en jetons, bien qu'il aurait dû être considéré comme une pièce entière.
Bien sûr, avec la fonctionnalité PCRE, un tel jeton pourrait être arraché à l'aide d'une simple régularité "
// [^ \ n] * \ n ", mais si ce n'est pas le cas? Ou voulons-nous l'entailler avec nos mains? En bref, dans le cas d'un lexer multi-états - nous pouvons dire que tous les jetons doivent être dans le groupe n °
1 , dès que le jeton "
// " est trouvé, alors une transition vers le groupe n ° 2 doit se produire. Et à l'intérieur du deuxième groupe, la transition inverse, si le jeton "
\ n " est trouvé - la transition vers le premier groupe.
Quelque chose comme ça:
$tokens = [ 'group-1' => [ 'class', '\w+', '{', '}', '//' => 'group-2'
Je pense que maintenant il devient plus clair comment certains HEREDOC sont analysés, car même avec toute la puissance de PCRE, écrire un régulier pour ce cas est extrêmement problématique, étant donné que cette syntaxe HEREDOC prend en charge l'interpolation variable. Essayez simplement d'analyser quelque chose comme ça avec la fonction
intégrée token_get_all (note> 12 jetons):
<?php $example = 42; $a = <<<EOL Your answer is $example !!! EOL; var_dump(token_get_all(file_get_contents(__FILE__)));
Eh bien, il semble que nous soyons prêts à commencer à pratiquer.
Pratique
Rappelons-nous ce que nous avons en PHP pour de telles choses? Eh bien, bien sûr, preg_match! D'accord, descends. L'algorithme basé sur preg_match est implémenté dans
Hoa et
dans cette implémentation de Phelxy . Sa tâche est assez simple:
- Nous avons en main le texte source et un tableau de réguliers.
- Nous correspondons jusqu'à ce que quelque chose de approprié soit trouvé.
- Dès que vous trouvez une pièce, coupez-la du texte et faites-la correspondre davantage.
Sous forme de code, cela ressemblera à ceci:
Feuille de code <?php class SimpleLexer { private $tokens = []; public function __construct(array $tokens) { foreach ($tokens as $name => $definition) { $this->tokens[$name] = \sprintf('/\G%s/isSum', $definition); } } public function lex(string $sources): iterable { [$offset, $length] = [0, \strlen($sources)]; while ($offset < $length) { [$name, $token] = $this->next($sources, $offset); yield $name => $token; $offset += \strlen($token); } } private function next(string $sources, int $offset): array { foreach ($this->tokens as $name => $pcre) { \preg_match($pcre, $sources, $matches, 0, $offset); $token = \reset($matches); if (\count($matches) && \strpos($sources, $token, $offset) === $offset) { return [$name, $token]; } } throw new \RuntimeException('Unrecognized token at offset ' . $offset); } }
Utilisation d'une feuille de code $lexer = new SimpleLexer([ 'T_CLASS' => 'class', 'T_CONST' => '\w+', 'T_BRACE_OPEN' => '{', 'T_BRACE_CLOSE' => '}', 'T_WHITESPACE' => '\s+', ]); echo \sprintf('| %-10s | %-20s |', 'VALUE', 'NAME') . "\n"; foreach ($lexer->lex('class Example {}') as $name => $token) { echo \sprintf('| %-10s | %-20s |', '"' . \trim($token, "\n") . '"', $name) . "\n"; }
Cette approche est assez banale et permet à quelques pressions sur le clavier de modifier le lexer dans la région de la méthode next (), en ajoutant une transition entre les états et en transformant cette division de la masturbation en un lexer primitif à plusieurs états. Dans la zone
$ this-> tokens, ajoutez simplement quelque chose comme
$ this-> tokens [$ this-> state] .
Cependant, en plus du primitivisme lui-même, il y a un autre inconvénient, pas fatal comme cela pourrait se révéler, mais quand même ... Une telle implémentation est incroyablement lente. Sur i7 7600k, le propriétaire dont je me trouvais par hasard - un algorithme similaire traite environ 400 jetons par seconde, et avec une augmentation de leurs variations (c'est-à-dire les définitions que nous avons transmises au constructeur) - il peut ralentir à la vitesse du changement de président en Russie ... ahem désolé. Je voulais dire, bien sûr, que cela fonctionnera
très lentement .
D'accord, que pouvons-nous faire? Pour commencer, vous pouvez comprendre ce qui ne va pas. Le fait est que chaque fois que nous appelons
preg_match à l'intérieur du
joker du langage, un compilateur avec son JIT appelé PCRE se lève (Et avec PHP 7.3, PCRE2 l'est déjà). Chaque fois, il analyse les habitués eux-mêmes et recueille un analyseur pour eux, avec lequel nous analysons le texte pour créer des jetons. Cela semble un peu étrange et tautologique. Mais en bref, chaque jeton nécessite une compilation de 1 à N réguliers, où N est le nombre de définitions de ces jetons. Dans le même temps, il convient de noter que même l'indicateur "
S " appliqué et l'optimisation utilisant "
\ G " dans le constructeur, où des expressions régulières pour les jetons sont générées, n'aident pas.
Il n'y a qu'un seul moyen de sortir de cette situation - vous devez analyser tout ce texte en un seul passage, c'est-à-dire en exécutant une
seule fonction
preg_match . Il reste à résoudre deux problèmes:
- Comment indiquer que le résultat de l'expression régulière N1 correspond au jeton N2? C'est-à-dire comment indiquer que " \ w + ", par exemple, est T_CONST .
- Comment déterminer la séquence de jetons en conséquence. Comme vous le savez, le résultat de preg_match ou preg_match_all contiendra tout mélangé. Et même avec l'aide de drapeaux passés comme quatrième argument, la situation ne changera pas.
Ici, vous pouvez faire une pause et réfléchir un peu. Eh bien ou pas.
La solution au premier problème
s'appelle les groupes PCRE , également appelés «sous-masques». En utilisant les règles: "
(?? <T_WHITESPACE> \ s + | <T_WORD> \ w + | ...) ", vous pouvez obtenir tous les jetons en un seul passage en les comparant avec leurs noms. À la suite de la correspondance, un tableau associatif sera formé, composé des paires "
[TOKEN_NAME => TOKEN_VALUE] ".
Le second est un peu plus compliqué. Mais ici, vous pouvez appliquer une astuce tactique et utiliser la fonction
preg_replace_callback . Sa particularité est que l'anonym passé comme deuxième argument sera appelé strictement séquentiellement pour chaque jeton, du premier au dernier.
Afin de ne pas languir - la mise en œuvre est la suivante:
Un autre volet de code class PregReplaceLexer { private $tokens = []; public function __construct(array $tokens) { foreach ($tokens as $name => $definition) { $this->tokens[] = \sprintf('(?<%s>%s)', $name, $definition); } } public function lex(string $sources): iterable { $result = []; \preg_replace_callback($this->compilePcre(), function (array $matches) use (&$result) { foreach (\array_reverse($matches) as $name => $value) { if (\is_string($name) && $value !== '') { $result[] = [$name, $value]; break; } } }, $sources); foreach ($result as [$name, $value]) { yield $name => $value; } } private function compilePcre(): string { return \sprintf('/\G(?:%s)/isSum', \implode('|', $this->tokens)); } }
Et son utilisation n'est pas différente de la version précédente. Dans le même temps, la vitesse de travail passe de
400 à
57 000 jetons par seconde. C'est cet algorithme que j'ai appliqué
dans mon implémentation , reprenant la réécriture du code source Hoa. Soit dit en passant, si vous utilisez Parle, vous pouvez compresser jusqu'à
600 000 jetons par seconde. Et l'image globale ressemble à ceci (avec XDebug activé en PHP 7.1, donc les chiffres sont inférieurs, mais le ratio peut être grossièrement représenté).
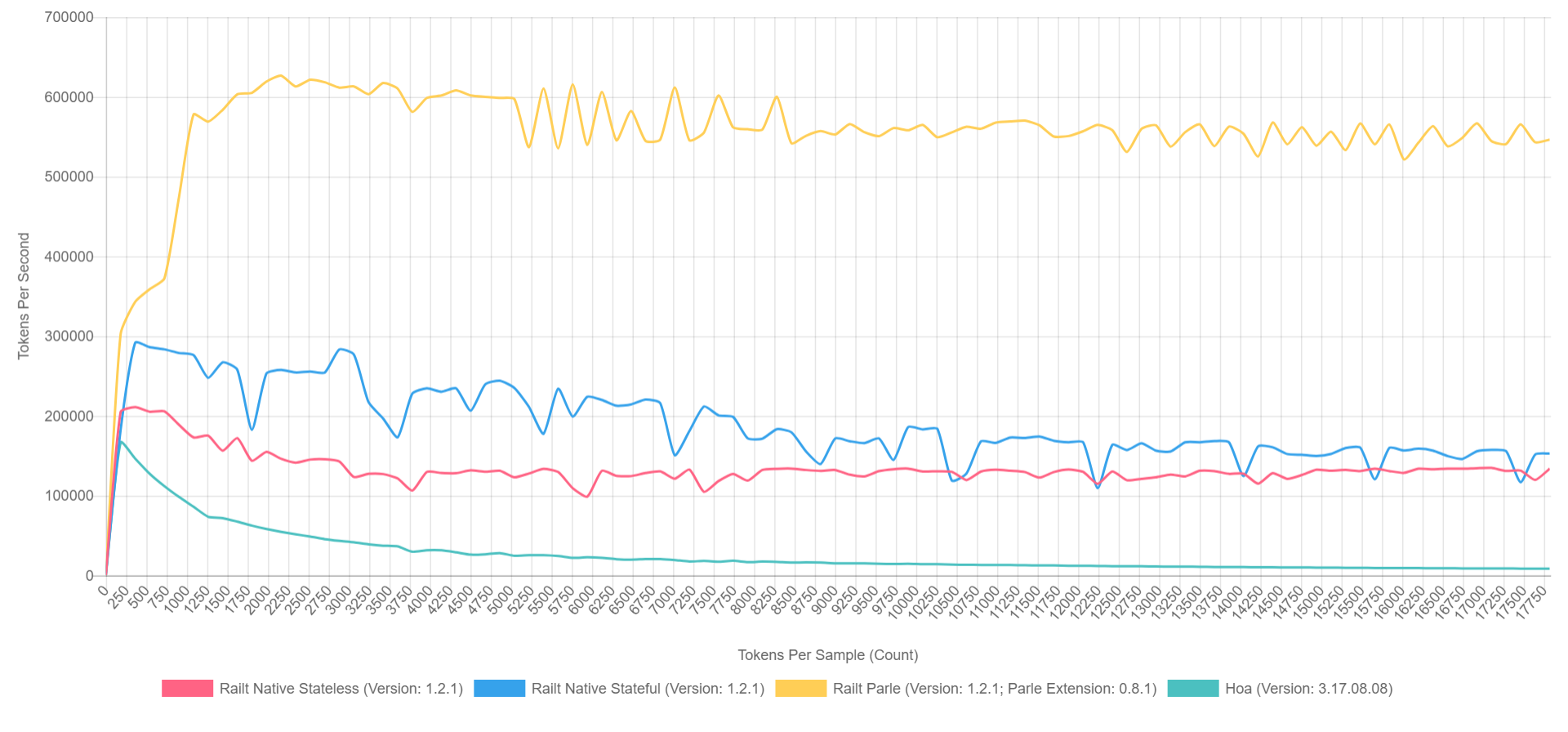
- Le jaune est l'extension native de Parle.
- Bleu - implémentation via preg_replace_callback avec un pré-assemblé régulier.
- Rouge - tout de même, mais avec la régularité générée lors de l'appel à preg_replace_callback .
- Vert - implémentation via preg_match .
Pourquoi?
Eh bien, tout cela, bien sûr, est merveilleux, mais les impatients sont impatients de poser la question: "Qui en a besoin?" Dans le monde abstrait de PHP, où le principe de "fig-fig-and-site-ready" domine - de telles bibliothèques ne sont pas nécessaires, nous serons honnêtes. Mais si nous parlons de l'écosystème dans son ensemble, nous pouvons rappeler les bibliothèques notoires comme
symfony / yaml ou
Doctrine . Les annotations dans Symfony sont le même sous-langage dans PHP, nécessitant une analyse lexicale et syntaxique distincte. De plus, il existe des transpilateurs CoffeeScript, Less et Scss / Sass encore moins connus, écrits en PHP. Eh bien, ou
Yay et
prétraitez en fonction de cela. Je ne mentionnerai même pas les outils d'analyse de code comme phpmd ou phpcs. Et les générateurs de documentation comme phpDocumentnor ou Sami sont assez triviaux. Chacun de ces projets à un degré ou un autre utilise l'analyse lexicale à la première étape de l'analyse du texte / code.
Ce n'est pas une liste complète de projets et j'espère peut-être que mon histoire vous aidera à découvrir quelque chose de nouveau et à le reconstituer.
Postface
À l'avenir, s'il y a quelqu'un qui s'intéresse au sujet des analyseurs et des compilateurs, alors il y a quelques rapports intéressants sur ce sujet, en particulier des gars de JetBrains:
Pourtant, bien sûr, la plupart des performances d'Andrei Breslav (
abreslav ), qui peuvent être trouvées sur l'immensité de YouTube - je vous conseille de regarder.
Eh bien, pour les fans de fiction,
il existe une telle ressource qui m'a personnellement été extrêmement utile.
Post post scriptum. Si vous êtes quelque part enfermé dans l'immensité de cette épopée, vous pouvez en informer l'auteur en toute sécurité sous n'importe quelle forme qui vous convient.
En prime, je voudrais donner
un exemple d'un simple lexeur PHP , il semble que ce n'est pas si effrayant maintenant, et maintenant c'est même clair ce qu'il fait, non? Bien que je trompe, les yeux saignent des habitués. =)
Je vous remercie!