Le premier service dans Nomad I a été lancé en septembre 2016. À l'heure actuelle, je l'utilise en tant que programmeur et support en tant qu'administrateur de deux clusters Nomad - un "home" pour mes projets personnels (6 machines micro-virtuelles dans Hetzner Cloud et ArubaCloud dans 5 centres de données différents en Europe) et le second en fonctionnement (environ 40 serveurs virtuels et physiques privés dans deux centres de données).
Au cours des dernières années, beaucoup d'expérience a été accumulée avec l'environnement Nomad, dans l'article, je décrirai les problèmes rencontrés par Nomad et comment y faire face.

Le nomade de Yamal crée une instance de livraison continue de votre logiciel © National Geographic Russia
1. Le nombre de nœuds de serveur par centre de données
Solution: un nœud de serveur suffit pour un centre de données.
La documentation n'indique pas explicitement le nombre de nœuds de serveur requis dans un centre de données. Il est seulement indiqué que 3 à 5 nœuds sont nécessaires par région, ce qui est logique pour le consensus du protocole de radeau.
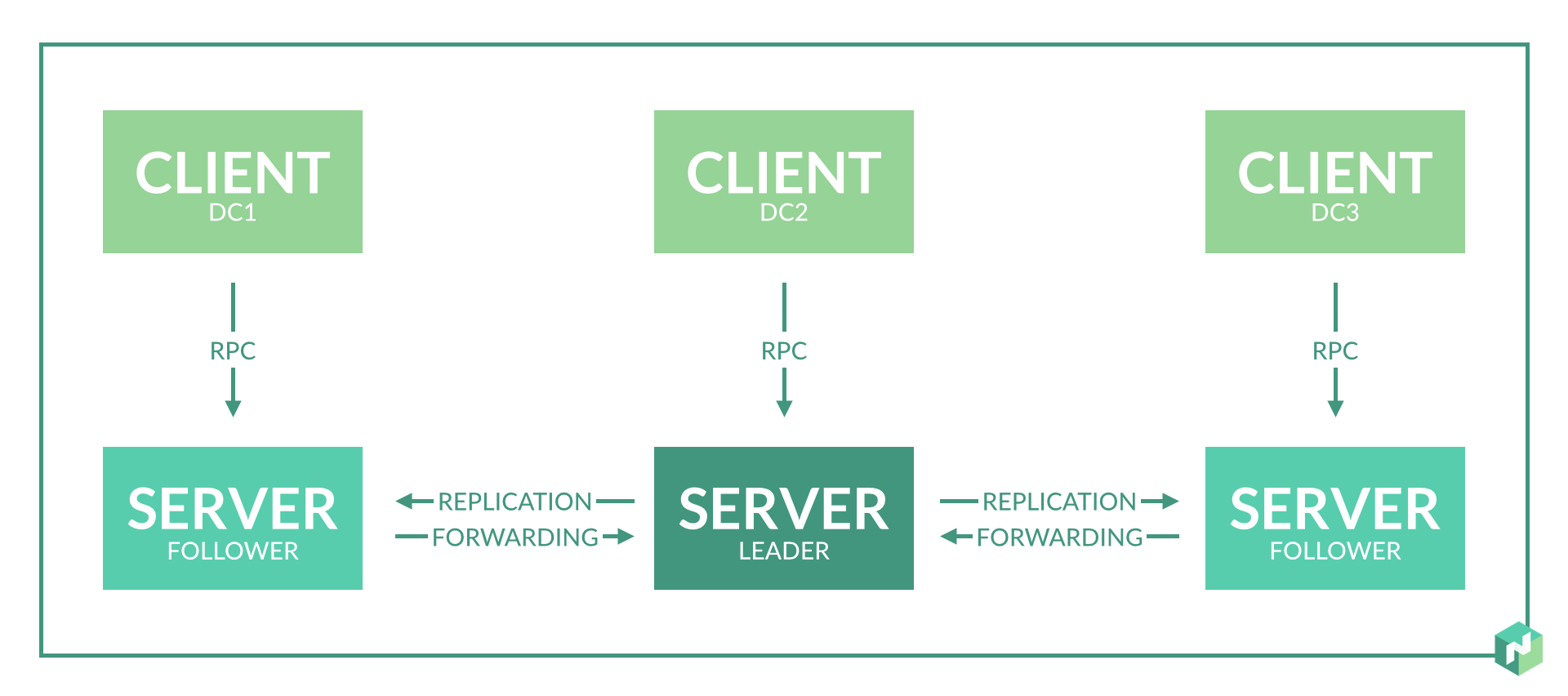
Au début, j'avais prévu 2 à 3 nœuds de serveur dans chaque centre de données pour assurer la redondance.
Lors de l'utilisation, il s'est avéré:
- Cela n'est tout simplement pas nécessaire, car en cas de défaillance d'un nœud dans le centre de données, le rôle du nœud de serveur pour les agents dans ce centre de données sera joué par d'autres nœuds de serveur dans la région.
- Cela s'avère encore pire si le problème 8 n'est pas résolu. Lorsque l'assistant est réélu, des incohérences peuvent se produire et Nomad redémarrera une partie des services.
2. Ressources serveur pour le nœud de serveur
Solution: une petite machine virtuelle suffit pour le nœud de serveur. Sur le même serveur, il est autorisé à exécuter d'autres services non gourmands en ressources.
La consommation de mémoire du démon Nomad dépend du nombre de tâches en cours d'exécution. Consommation CPU - basée sur le nombre de tâches et le nombre de serveurs / agents dans la région (non linéaire).
Dans notre cas: pour 300 tâches en cours d'exécution, la consommation de mémoire est d'environ 500 Mo pour le nœud maître actuel.
Dans un cluster fonctionnel, une machine virtuelle pour un nœud de serveur: 4 CPU, 6 Go de RAM.
Lancement supplémentaire: Consul, Etcd, Vault.
3. Consensus sur le manque de centres de données
Solution: nous fabriquons trois centres de données virtuels et trois nœuds de serveur pour deux centres de données physiques.
Le travail du nomade dans la région est basé sur le protocole du radeau. Pour un fonctionnement correct, vous avez besoin d'au moins 3 nœuds de serveur situés dans différents centres de données. Cela permettra un fonctionnement correct avec une perte complète de connectivité réseau avec l'un des centres de données.
Mais nous n'avons que deux centres de données. Nous faisons un compromis: nous sélectionnons un centre de données, auquel nous faisons davantage confiance, et y faisons un nœud de serveur supplémentaire. Pour ce faire, nous introduisons un centre de données virtuel supplémentaire, qui sera physiquement situé dans le même centre de données (voir le paragraphe 2 du problème 1).
Solution alternative: nous divisons les centres de données en régions distinctes.
Par conséquent, les centres de données fonctionnent indépendamment et un consensus n'est nécessaire que dans un seul centre de données. Dans un centre de données, dans ce cas, il est préférable de créer 3 nœuds de serveur en implémentant trois centres de données virtuels en un seul.
Cette option est moins pratique pour la répartition des tâches, mais donne une garantie à 100% de l'indépendance des services en cas de problèmes de réseau entre les centres de données.
4. "Serveur" et "agent" sur le même serveur
Solution: valide si vous avez un nombre limité de serveurs.
La documentation des nomades indique que cela n'est pas souhaitable. Mais si vous n'avez pas la possibilité d'allouer des machines virtuelles distinctes aux nœuds de serveur, vous pouvez placer le serveur et les nœuds d'agent sur le même serveur.
L'exécution simultanée signifie le démarrage du démon Nomad en mode client et en mode serveur.
Qu'est-ce que cela menace? Avec une lourde charge sur le CPU de ce serveur, le nœud du serveur Nomad fonctionnera de manière instable, la perte de consensus et les battements de cœur, les rechargements de service sont possibles.
Pour éviter cela, nous augmentons les limites de la description du problème n ° 8.
5. Mise en place d'espaces de noms
Solution: peut-être par l'organisation d'un data center virtuel.
Parfois, vous devez exécuter une partie des services sur des serveurs distincts.
La solution est la première, simple, mais plus exigeante en ressources. Nous divisons tous les services en groupes selon leur fonction: frontend, backend, ... Ajoutez des méta-attributs aux serveurs, prescrivez les attributs à exécuter pour tous les services.
La deuxième solution est simple. Nous ajoutons de nouveaux serveurs, leur prescrivons des méta-attributs, prescrivons ces attributs de lancement aux services nécessaires, tous les autres services prescrivent une interdiction de lancement sur les serveurs avec cet attribut.
La troisième solution est compliquée. Nous créons un datacenter virtuel: lancez Consul pour un nouveau datacenter, lancez le nœud serveur Nomad pour ce datacenter, sans oublier le nombre de nœuds serveur pour cette région. Vous pouvez désormais exécuter des services individuels dans ce centre de données virtuel dédié.
6. Intégration avec Vault
Solution: évitez les dépendances circulaires Nomad <-> Vault.
Launched Vault ne devrait pas avoir de dépendances sur Nomad. L'adresse du coffre-fort enregistrée dans Nomad doit de préférence pointer directement vers le coffre-fort, sans couches d'équilibreurs (mais valide). Dans ce cas, la réservation du coffre-fort peut être effectuée via DNS - Consul DNS ou externe.
Si les données Vault sont écrites dans les fichiers de configuration de Nomad, Nomad essaie d'accéder à Vault au démarrage. Si l'accès échoue, alors Nomad refuse de commencer.
J'ai fait une erreur avec une dépendance cyclique il y a longtemps, cela a une fois brièvement détruit presque complètement le cluster Nomad. Vault a été lancé correctement, indépendamment de Nomad, mais Nomad a examiné l'adresse de Vault via les équilibreurs qui s'exécutaient dans Nomad lui-même. La reconfiguration et le redémarrage des nœuds du serveur Nomad ont provoqué un redémarrage des services d'équilibrage, ce qui a entraîné l'échec du démarrage des nœuds du serveur eux-mêmes.
7. Lancement d'importants services publics
Solution: valide, mais pas moi.
Est-il possible d'exécuter PostgreSQL, ClickHouse, Redis Cluster, RabbitMQ, MongoDB via Nomad?
Imaginez que vous disposez d'un ensemble de services importants, dont le travail est lié à la plupart des autres services. Par exemple, une base de données dans PostgreSQL / ClickHouse. Ou stockage général à court terme dans Redis Cluster / MongoDB. Ou un bus de données dans Redis Cluster / RabbitMQ.
Tous ces services implémentent en quelque sorte un schéma tolérant aux pannes: Stolon / Patroni pour PostgreSQL, sa propre implémentation de radeau dans Redis Cluster, sa propre implémentation de cluster dans RabbitMQ, MongoDB, ClickHouse.
Oui, tous ces services peuvent être lancés via Nomad en référence à des serveurs spécifiques, mais pourquoi?
Plus - facilité de lancement, un format de script unique, comme d'autres services. Pas besoin de s'inquiéter avec les scripts ansibles / quoi que ce soit d'autre.
Le moins est un point de défaillance supplémentaire, qui ne présente aucun avantage. Personnellement, j'ai complètement abandonné le cluster Nomad à deux reprises pour diverses raisons: une fois «chez moi», une fois au travail. C'était au début de l'introduction de Nomad et en raison de la négligence.
De plus, Nomad commence à mal se comporter et redémarre les services en raison du problème numéro 8. Mais même si ce problème est résolu, le danger demeure.
8. Stabilisation du travail et des redémarrages de service dans un réseau instable
Solution: utilisez les options de réglage du rythme cardiaque.
Par défaut, Nomad est configuré de sorte que tout problème de réseau à court terme ou charge de processeur entraîne une perte de consensus et une réélection de l'assistant ou le marquage du nœud d'agent comme inaccessible. Et cela conduit à des redémarrages spontanés des services et à leur transfert vers d'autres nœuds.
Statistiques du cluster "home" avant de résoudre le problème: la durée de vie maximale du conteneur avant redémarrage est d'environ 10 jours. Ici, il est toujours surchargé d'exécuter l'agent et le serveur sur un seul serveur et de le placer dans 5 centres de données différents en Europe, ce qui implique une charge importante sur le processeur et un réseau moins stable.
Statistiques du cluster de travail avant de résoudre le problème: la durée de vie maximale du conteneur avant redémarrage est supérieure à 2 mois. Tout est relativement bon ici en raison des serveurs séparés pour les nœuds de serveur Nomad et de l'excellent réseau entre les centres de données.
Valeurs par défaut
heartbeat_grace = "10s" min_heartbeat_ttl = "10s" max_heartbeats_per_second = 50.0
A en juger par le code: dans cette configuration, les battements de cœur sont effectués toutes les 10 secondes. Avec la perte de deux battements de cœur, la réélection du maître ou le transfert de services du nœud d'agent commence. Des paramètres controversés, à mon avis. Nous les modifions en fonction de l'application.
Si vous avez tous les services exécutés dans plusieurs instances et distribués par des centres de données, alors très probablement, peu importe pour vous une longue période de détermination de l'inaccessibilité du serveur (environ 5 minutes, dans l'exemple ci-dessous) - nous rendons moins fréquents l'intervalle de pulsation et une plus longue période de détermination de l'inaccessibilité. Voici un exemple de configuration de mon cluster d'origine:
heartbeat_grace = "300s" min_heartbeat_ttl = "30s" max_heartbeats_per_second = 10.0
Si vous disposez d'une bonne connectivité réseau, de serveurs séparés pour les nœuds de serveur et que la période de détermination de l'inaccessibilité du serveur est importante (il existe un service en cours d'exécution dans une instance et il est important de le transférer rapidement), augmentez la période de détermination de l'inaccessibilité (heartbeat_grace). En option, vous pouvez faire plus de battements de cœur (en diminuant min_heartbeat_ttl) - cela augmentera légèrement la charge sur le CPU. Exemple de configuration de cluster de travail:
heartbeat_grace = "60s" min_heartbeat_ttl = "10s" max_heartbeats_per_second = 50.0
Ces paramètres résolvent complètement le problème.
9. Démarrage de tâches périodiques
Solution: les services périodiques Nomade peuvent être utilisés, mais cron est plus pratique pour le support.
Nomad a la possibilité de lancer périodiquement le service.
Le seul avantage est la simplicité de cette configuration.
Le premier inconvénient est que si le service démarre fréquemment, il jonchera la liste des tâches. Par exemple, au démarrage toutes les 5 minutes, 12 tâches supplémentaires seront ajoutées à la liste toutes les heures, jusqu'à ce que le GC Nomad se déclenche, ce qui supprimera les anciennes tâches.
Le deuxième inconvénient - on ne sait pas comment configurer correctement la surveillance d'un tel service. Comment comprendre qu'un service commence, remplit et fait son travail jusqu'à la fin?
En conséquence, pour moi, je suis venu à la mise en œuvre "cron" des tâches périodiques:
- Il peut s'agir d'un cron régulier dans un conteneur en fonctionnement constant. Cron exécute périodiquement un certain script. Un script-healthcheck est facilement ajouté à un tel conteneur, qui vérifie tout indicateur qui crée un script en cours d'exécution.
- Il peut s'agir d'un conteneur en cours d'exécution, avec un service en cours d'exécution. Un lancement périodique a déjà été mis en place au sein du service. Un script-healthcheck ou http-healthcheck similaire peut être facilement ajouté à un tel service, qui vérifie immédiatement l'état par ses "éléments internes".
Pour le moment, j'écris la plupart du temps en Go, respectivement, je préfère la deuxième option avec http healthcheck - on Go et le lancement périodique, et http healthcheck'i sont ajoutés avec quelques lignes de code.
10. Fournir des services redondants
Solution: il n'y a pas de solution simple. Il existe deux options plus difficiles.
Le schéma d'approvisionnement fourni par les développeurs de Nomad doit prendre en charge le nombre de services en cours d'exécution. Vous dites que le nomade "lance-moi 5 instances du service" et il les démarre quelque part là-bas. Il n'y a aucun contrôle sur la distribution. Les instances peuvent s'exécuter sur le même serveur.
Si le serveur tombe en panne, les instances sont transférées vers d'autres serveurs. Pendant le transfert des instances, le service ne fonctionne pas. Il s'agit d'une mauvaise option de provision de réserve.
Nous le faisons bien:
- Nous distribuons des instances sur des serveurs via des hôtes distincts .
- Nous distribuons des instances dans les centres de données. Malheureusement, seulement en créant une copie du script du formulaire service1, service2 avec le même contenu, des noms différents et une indication du lancement dans différents centres de données.
Dans Nomad 0.9, une fonctionnalité apparaîtra qui résoudra ce problème: il sera possible de répartir les services dans un rapport de pourcentage entre les serveurs et les centres de données.
11. Web UI Nomad
Solution: l'interface utilisateur intégrée est terrible, hashi-ui est magnifique.
Le client de la console exécute la plupart des fonctionnalités requises, mais parfois vous voulez voir les graphiques, appuyez sur les boutons ...
Nomad a une interface utilisateur intégrée. Ce n'est pas très pratique (encore pire que la console).
La seule alternative que je connaisse est le hashi-ui .
En fait, maintenant, j'ai personnellement besoin du client de console uniquement pour "run nomade". Et même cela prévoit de transférer à CI.
12. Prise en charge de la sursouscription de la mémoire
Solution: non.
Dans la version actuelle de Nomad, vous devez spécifier une limite de mémoire stricte pour le service. Si la limite est dépassée, le service sera tué par OOM Killer.
La sursouscription est le moment où les limites d'un service peuvent être spécifiées "de et vers". Certains services nécessitent plus de mémoire au démarrage qu'en fonctionnement normal. Certains services peuvent consommer plus de mémoire que d'habitude pendant une courte période.
Le choix d'une restriction stricte ou d'un logiciel est un sujet de discussion, mais, par exemple, Kubernetes permet au programmeur de faire un choix. Malheureusement, dans les versions actuelles de Nomad, cette possibilité n'existe pas. J'avoue que cela apparaîtra dans les futures versions.
13. Nettoyage du serveur des services Nomad
Solution:
sudo systemctl stop nomad mount | fgrep alloc | awk '{print $3}' | xargs -I QQ sudo umount QQ sudo rm -rf /var/lib/nomad sudo docker ps | grep -v '(-1|-2|...)' | fgrep -v IMAGE | awk '{print $1}' | xargs -I QQ sudo docker stop QQ sudo systemctl start nomad
Parfois "quelque chose ne va pas". Sur le serveur, il tue le nœud d'agent et refuse de démarrer. Ou le nœud d'agent cesse de répondre. Ou le nœud d'agent "perd" des services sur ce serveur.
Cela arrivait parfois avec les anciennes versions de Nomad, maintenant cela ne se produit pas, ou très rarement.
Dans ce cas, quelle est la plus simple à faire, étant donné que le serveur de vidange ne produira pas le résultat souhaité? Nous nettoyons le serveur manuellement:
- Arrêtez l'agent nomade.
- Faites un démontage sur le support qu'il crée.
- Supprimez toutes les données de l'agent.
- Nous supprimons tous les conteneurs en filtrant les conteneurs de service (le cas échéant).
- Nous démarrons l'agent.
14. Quelle est la meilleure façon de déployer Nomad?
Solution: bien sûr, par le biais du Consul.
Le consul dans ce cas n'est en aucun cas une couche supplémentaire, mais un service qui s'intègre organiquement dans l'infrastructure, ce qui donne plus d'avantages que d'inconvénients: DNS, stockage KV, recherche de services, surveillance de la disponibilité du service, possibilité d'échanger des informations en toute sécurité.
De plus, il se déroule aussi facilement que Nomad lui-même.
15. Quel est le meilleur - Nomad ou Kubernetes?
Solution: dépend de ...
Auparavant, j'avais parfois l'idée de commencer une migration vers Kubernetes - j'étais tellement ennuyé par le redémarrage périodique et spontané des services (voir problème numéro 8). Mais après une solution complète au problème, je peux dire: Nomad me convient en ce moment.
D'autre part: Kubernetes a également un rechargement semi-spontané de services - lorsque le planificateur Kubernetes redistribue les instances en fonction de la charge. Ce n'est pas très cool, mais là, il est très probablement configuré.
Avantages de Nomad: l'infrastructure est très facile à déployer, des scripts simples, une bonne documentation, un support intégré pour Consul / Vault, ce qui donne à son tour: une solution simple au problème de stockage de mot de passe, DNS intégré, helchecks faciles à configurer.
Avantages de Kubernetes: Maintenant, c'est une «norme de facto». Bonne documentation, nombreuses solutions toutes faites, avec une bonne description et standardisation du lancement.
Malheureusement, je n'ai pas la même grande expertise dans Kubernetes pour répondre sans équivoque à la question - quoi utiliser pour le nouveau cluster. Dépend des besoins planifiés.
Si vous avez prévu beaucoup d'espaces de noms (problème numéro 5) ou si vos services spécifiques consomment beaucoup de mémoire au début, alors libérez-les (problème numéro 12) - certainement Kubernetes, car ces deux problèmes dans Nomad ne sont pas entièrement résolus ou incommodes.