Dans le monde de PHP, les outils de migration de la structure de base de données sont bien connus -
Doctrine ,
Phinx de CakePHP, de
Laravel , de
Yii - c'est la première chose qui m'est venue à l'esprit. Il y en a sûrement une douzaine d'autres. Et la plupart d'entre eux fonctionnent avec des migrations - des équipes pour apporter des modifications incrémentielles au schéma de la base de données.
Je ne décrirai pas pourquoi c'est, il y a beaucoup de messages sur ce sujet sur Habré. Par exemple:
De plus, le développement de mon
expérience en équipe avec un changement constant dans la structure de la base de données dans différentes branches.
API SQL vs PHP brute
Nous écrivons des migrations en SQL pur. De nombreux outils fournissent une API PHP pour écrire des instructions traduites en code SQL. Maintenant je ne comprends pas pourquoi c'est? Un tel outil sera toujours limité dans ses capacités. Ils ne permettent pas d'écrire des instructions spécifiques pour un moteur spécifique; vous devez toujours utiliser du SQL pur. Je ne parle pas d'écrire des procédures et des opinions.
Quelqu'un s'est plaint de ne pas vouloir apprendre la syntaxe des commandes ALTER ... Eh bien, je ne sais pas, j'ai ouvert le répertoire et écrit des exemples de la montagne, surtout dans un grand projet.
Les migrations de données (INSERT, UPDATE) sont également toujours écrites en SQL. Parce que vous ne pouvez jamais compter sur la version actuelle d'ORM et de modèles. Dans une révision, ils le sont, dans l'autre plus.
Par exemple:
Rollback Country::delete()->where(....)->execute();
Vous souhaitez restaurer l'état de la base de données. Et cette classe PHP n'est plus dans le repo. Vous devez rechercher le dernier commit où il était et revenir en arrière à partir de là. Brrr ...
Par conséquent, SQL est simple et fiable:
Transactions en DDL
Avec la transition vers PostgreSQL, j'ai oublié les migrations interrompues comme un cauchemar - la migration est tombée au milieu, quelque chose a roulé, quelque chose a disparu, assis et droitier ... Cela nous a forcés à écrire des commandes atomiques sur une seule ligne et à les exécuter une à la fois. Tout est simple avec les transactions: si quelque chose se casse - tout recule (enfin, presque tout))). Il suffit de le réparer et de le redémarrer. L'assemblage automatique fonctionne avec un coup, si quelque chose est tombé, il se corrige et monte rapidement.
Vues (vues) et fonctions
Le problème ici est qu'ils ne peuvent pas être mis à jour de manière incrémentielle, comme ALTER dans les tableaux. Besoin de DROP et CREATE. C'est-à-dire sur le différentiel (texte de migration) on ne sait pas du tout ce qui a finalement changé. Surtout quand la logique est tordue, c'est plutôt gênant. Par exemple:
Qu'est-ce qui a changé ici?
Nous nous sommes arrêtés au fait qu'à côté des migrations se trouve un papa, où la vue actuelle et le code de procédure sont stockés, qui sont mis à jour et copiés dans la migration de restauration.
Et maintenant, le diff devient comme:

De retour dans Avito, nous avons fait une solution intéressante pour
versionner le code de procédure stockée.En général, ce cas soulève un bon problème - comment regarder l'historique des changements dans un objet particulier de la structure de la base de données. Pour chaque tableau, je veux voir l'historique des changements liés à la solution de tâches spécifiques.

Trouvé sur Habré une
approche intéressante pour l'automatisation de la fixation des changements dans la structure de la base de données.
Travailler avec des succursales
Ma douleur éternelle est de savoir comment basculer entre deux branches A et B, dont chacune a modifié la structure de la base de données.

Il est nécessaire d'annuler les migrations dans la branche A (nous devons également nous rappeler lesquelles et combien), puis de passer à la branche B et de lancer de nouvelles migrations. D'accord, si nos modifications sont compatibles et je peux simplement passer à la deuxième branche et effectuer des migrations supplémentaires à partir de B.
Et sinon? Et si j'ai plusieurs succursales? Et puis annuler tous ces états de révision? J'ai toujours détesté ça ...
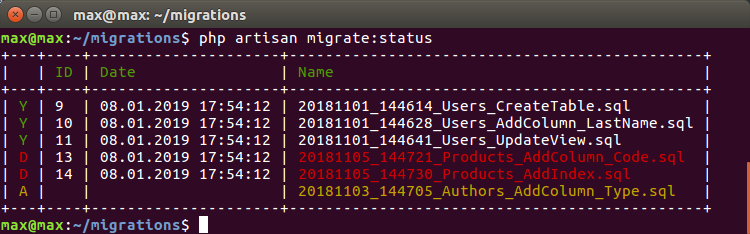
Désormais, lorsque je passe à la succursale de quelqu'un d'autre, je peux supprimer automatiquement les migrations des autres et lancer les migrations en cours:
où:
D - Migrations A qui ont été lancées dans la branche A, mais qui ne se trouvent pas dans la branche actuelle, et il est recommandé de les supprimer
A - Migrations B qui sont apparues dans la nouvelle branche et doivent être roulées
Il devient incroyablement pratique lors des tests et de l'assemblage automatique sur une seule base. Lorsqu'il n'y a pas de sens ou d'opportunité pour chaque branche de créer une base à partir de zéro. Basculez vers la branche et synchronisez automatiquement l'état de la base de données.
Numérotation et ordre d'exécution
Tous les outils que je connais sont des migrations horodatées est une bonne solution. Si j'écris plusieurs migrations, la séquence nécessaire est préservée. Un autre développeur peut avoir n'importe quelle date dans un autre fil, même le mien - mais peu importe l'ordre dans lequel nous roulons avec lui, nos modifications sont indépendantes les unes des autres. Même si nous travaillons avec la même table (ajouter par colonne), toutes les modifications nécessaires auront lieu dans n'importe quel ordre. L'essentiel est que la séquence de mes montages dépendants soit respectée.

Je ne considère pas les cas où nous devons modifier la même chose - ces points sont toujours cohérents. Eh bien, ou il y aura un échec au stade de l'assemblage et des tests.
Voici un exemple intéressant.
Nous apportons différentes modifications dans une seule vue ou procédure, c.-à-d. dans les structures mises à jour par suppression. C'est-à-dire Par exemple, j'ai ajouté la colonne col_A à la vue et mon collègue col_B. Par conséquent, si son code se déploie après le mien, sa colonne n'aura pas ma colonne:
CREATE VIEW vusers AS SELECT login, name,
| branche-A | branche-B |
|---|
DROP VIEW vusers; CREATE VIEW vusers AS SELECT login, name, col_A, | DROP VIEW vusers; CREATE VIEW vusers AS SELECT login, name, col_B, |
Dans ce cas, une branche doit être rendue dépendante d'une autre.
Un autre cas intéressant est celui des corrections de migrations.
L'essentiel est que la migration qui a été appliquée ne sera plus appliquée à nouveau, quel que soit le nombre de modifications que vous y apportez (vous devez d'abord annuler, puis l'appliquer à nouveau). C'est-à-dire Vous avez envoyé Migration pour tester toutes les règles, puis vous l'avez réalisé et avez effectué une petite modification. Mais le test ou tout autre serveur sur lequel vous l'avez utilisé ne le saura pas.
Dans ces cas, nous renommons le fichier de migration, en ajoutant un nouveau numéro de version, afin que le migrant commence à interpréter cela comme 2 commandes - restaurer 1 et rouler 2,
par exemple:

Rollback
Écrivez toujours ROLLBACK, même s'il ne peut pas remettre la base dans son état d'origine. Par exemple, DROP TABLE, quel type de ROLLBACK peut-il être?
Dans de tels cas, nous écrivons une CREATE TABLE vide. L'essentiel est que le système de développement peut toujours facilement basculer entre les branches. Pour PROD, la gestion irréversible des révisions est déjà décidée à un niveau différent. Je peux faire une copie du tableau ou le renommer au lieu de le supprimer. Mais le principe de l'écriture de la migration - le rollback est OBLIGÉ pour ramener la STRUCTURE de la base au niveau initial, et les données sont déjà possibles.
Dans un environnement de combat, j'ai utilisé un retour en arrière seulement 1-2 fois dans ma vie. Et en dev tout le temps. Par conséquent, je vérifie toujours que la restauration ramène tout à l'état souhaité.
Souvent, les développeurs peuvent commettre des erreurs lors de la restauration. Parce que ils se concentrent principalement sur les nouvelles modifications, ils sont testés et fonctionnent avec eux. D'autres personnes et processus travaillent déjà avec la restauration. Par conséquent, je teste toujours les migrations UP - ROLLBACK - UP
Un point intéressant apparaît sur une base de test permanente (la base de données n'est pas supprimée). Ils ont écrit une migration, la restauration fonctionne bien, ils l'ont envoyée pour les tests, le testeur a généré des données dans un nouveau format, essaie de revenir en arrière, mais ils ne donnent pas de nouvelles données. Exemple classique
ALTER TABLE abc ALTER COLUMN code SET NULL
Super! Après le test, la base de données est pleine de valeurs NULL. Faites ROLLBACK:
ALTER TABLE abc ALTER COLUMN code SET NOT NULL
et vice versa :-(
Vous devez ajouter la commande:
DELETE FROM abc WHERE code IS NULL
La difficulté est que vous devez garder cela à l'esprit et ne pas l'automatiser si nous ne parlons pas de recréer la base de données à partir de zéro à chaque fois.
Un peu sur la suppression des données
Habituellement, nous essayons de NE PAS supprimer les tables et colonnes remplies à la fois. Il est préférable de renommer ou de faire une copie et de la supprimer plus tard, lorsque tout se calme et que les données perdent leur pertinence:
ALTER TABLE user_logs RENAME TO user_logs_20190223;
Migrateur
Nous travaillons actuellement avec Laravel - il dispose d'un moteur de gestion de migration standard et familier. Si vous le souhaitez, écrivez même en SQL pur, bien qu'il soit toujours dans la classe PHP. Mais mes tentatives répétées pour le faire fonctionner de la façon dont nous avions besoin ont abouti à un dépôt séparé:
- La solution se compose de 2 parties - lib et implémentation pour une console spécifique (Laravel, Symfony). Vous pouvez l'intégrer dans n'importe quelle console, ou au moins dans le web-museau.
- Il n'y a pas de configuration et de connexion - pourquoi, quand il est déjà dans votre projet. Accrochez votre connexion à l'interface et c'est parti.
- La restauration SQL est stockée dans la base de données. Cela est nécessaire pour basculer entre les branches.
- Testé sur Postgesql, Mysql (aucune transaction). Il convient en principe à toutes les bases et structures, car le format brut est utilisé.
Les références
-
migrations-lib-
mise en œuvre sous Laravel / Artisan-
implémentation sous Symfony / Console