OSGI n'est pas difficile
J'ai rencontré à plusieurs reprises que l'OSGI est difficile. Et d'ailleurs, lui-même avait une fois une telle opinion. Année en 2009, pour être exact. À cette époque, nous avons collecté des projets à l'aide de Maven Tycho et les avons déployés sur Equinox. Et c'était vraiment plus difficile que de développer et d'assembler des projets pour JavaEE (à ce moment, la version d'EJB 3 vient d'apparaître, vers laquelle nous sommes passés). Equinox était beaucoup moins pratique que Weblogic, par exemple, et les avantages d'OSGI n'étaient pas alors évidents pour moi.
Mais ensuite, après de nombreuses années, j'ai dû démarrer un projet dans un nouvel emploi, qui a été conçu sur la base d'Apache Camel et Apache Karaf. Ce n'était pas mon idée, je connaissais Camel depuis longtemps et j'ai décidé de lire sur Karaf, même sans offre. Je l'ai lu un soir et j'ai réalisé - la voici, simple et prête à l'emploi, presque la même solution à certains problèmes d'un JavaEE typique, similaire à ce que j'ai fait une fois à genoux en utilisant Weblogic WLST, Jython et Maven Aether.
Supposons donc que vous décidiez d'essayer OSGI sur la plate-forme Karaf. Par où commencer?
Si vous voulez une compréhension plus profonde
Vous pouvez bien sûr commencer par lire la documentation. Et c'est possible avec Habré - il y avait de très bons articles ici, disons il y a
si longtemps. Mais en général, le karaf a reçu jusqu'à présent, sans le mériter, peu d'attention. Il y avait quelques autres commentaires
ceci ou
cela . Il vaut mieux ignorer
cette mention de karaf. Comme on dit, ne lisez pas les journaux soviétiques pour la nuit ... car ils vous diront que le karaf est un cadre OSGI - donc vous n'y croyez pas. Les frameworks OSGI sont Apache Felix ou Eclipse Equinox, sur la base desquels karaf fonctionne. Vous pouvez choisir n'importe lequel d'entre eux.
Il convient de noter que lorsque Jboss Fuse ou Apache ServiceMix est mentionné, il doit être lu comme «Karaf, avec des composants préinstallés», c'est-à-dire en fait - la même chose, collectée uniquement par le vendeur. Je ne recommanderais pas de commencer par cela dans la pratique, mais il est tout à fait possible de lire des articles de revue sur ServiceMix, par exemple.
Pour commencer, je vais essayer de déterminer ici très brièvement ce qu'est l'OSGI et à quoi il peut servir.
Dans l'ensemble, OSGI est un outil pour créer des applications Java à partir de modules. Un analogue proche peut être considéré, par exemple, JavaEE, et dans une certaine mesure, les conteneurs OSGI peuvent exécuter des modules JavaEE (par exemple, des applications Web sous la forme de War), et d'autre part, de nombreux conteneurs JavaEE contiennent OSGI à l'intérieur comme moyen de mettre en œuvre la modularité "pour eux-mêmes" ". Autrement dit, JavaEE et OSGI sont des choses similaires à la compatibilité et complémentaires avec succès.
Une partie importante de tout système modulaire est la définition du module lui-même. Dans le cas d'OSGI, le module est appelé un bundle, et c'est une archive jar bien connue de tous les développeurs avec quelques ajouts (c'est-à-dire qu'elle est très similaire ici, par exemple, à war ou ear). Par analogie avec JavaEE, les bundles peuvent exporter et importer des services, qui sont essentiellement des méthodes de classe (c'est-à-dire qu'un service est une interface ou toutes les méthodes publiques d'une classe).
Les métadonnées du bundle sont familières à tout le monde META-INF / MANIFEST.MF. Les en-têtes du manifeste OSGI ne se croisent pas avec les en-têtes pour le JRE, respectivement, en dehors du bundle de conteneur OSGI est un bocal ordinaire. Il est significatif que parmi les métadonnées, il y ait toujours:
Bundle-SymbolicName: com.example.myosgi Bundle-Version: 1.0.0
Ce sont les «coordonnées» du bundle, et le fait que nous pouvons avoir deux ou plusieurs versions simultanément installées et fonctionnelles du même bundle dans un conteneur est important.
Comme pour JavaEE, les bundles ont un cycle de vie qui ressemble à ceci:
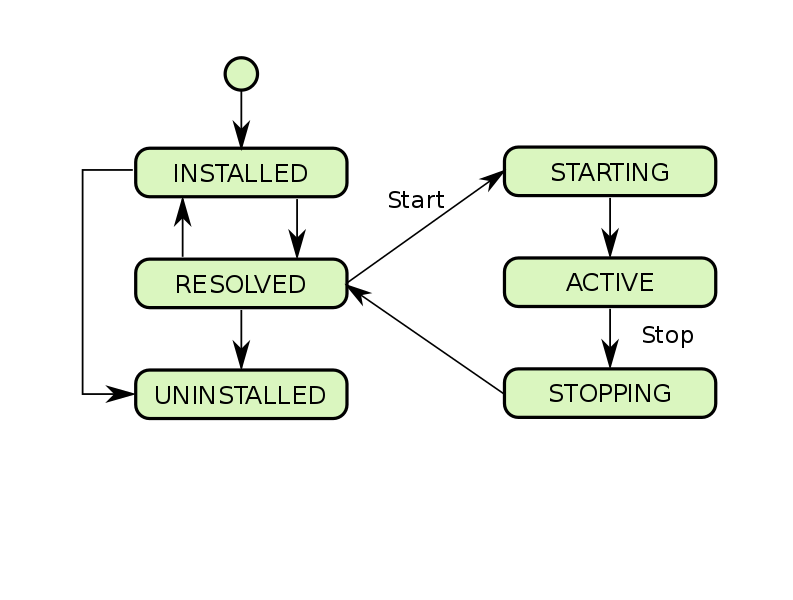
En plus des services, les bundles peuvent également importer et exporter des packages (packages, au sens habituel du terme pour java). Les packages exportés sont définis à l'intérieur du bundle et sont mis à la disposition des autres composants lorsque le bundle est installé sur le système. Ceux importés sont définis quelque part de l'extérieur, doivent être exportés par quelqu'un et fournis au bundle par le conteneur avant qu'il puisse commencer à fonctionner.
Les importations de packages peuvent être déclarées facultatives, ainsi que les importations de services. Et il est assez important que l'importation et l'exportation contiennent une indication de la version (ou de la plage de versions).
Différences avec JavaEE
Eh bien, c'est bien qu'ils se ressemblent - nous avons compris. Et en quoi diffèrent-ils?
À mon avis, la principale différence est que l'OSGI nous donne beaucoup plus de flexibilité. Une fois que le bundle est à l'état DÉMARRÉ, les possibilités ne sont limitées que par votre imagination. Disons que vous pouvez facilement créer des threads (oui, oui, je connais ManagedExecutorService), des pools de connexions aux bases de données, etc. Un conteneur ne prend pas le contrôle de toutes les ressources dans la même mesure que JavaEE.
Vous pouvez exporter de nouveaux services dans le processus. Essayez de dire en JavaEE créer dynamiquement un nouveau servlet? Et ici, il est tout à fait possible, en outre, que le conteneur de servlet karaf créé sur la base de jetty soit immédiatement détecté par votre servlet créé et qu'il soit disponible pour les clients à une URL spécifique.
Bien que ce soit une légère simplification, mais si l'application JavaEE dans sa forme classique se compose principalement de composants:
- passif, en attente d'un appel du client
- définis statiquement, c'est-à-dire au moment du déploiement de l'application.
En revanche, une application basée sur OSGI peut contenir:
- composants programmés actifs et passifs, exécution de sondages, enfin, écoute d'une socket, etc.
- les services peuvent être définis et publiés dynamiquement
- Vous pouvez vous abonner à des événements de cadre, par exemple, écouter l'enregistrement des services, des bundles, etc., recevoir des liens vers d'autres bundles et services, et faire bien plus encore.
Oui, sur JavaEE, une grande partie de cela est également partiellement possible (par exemple, via JNDI), mais dans le cas d'OSGI, dans la pratique, cela est rendu plus facile. Bien qu'il y ait probablement quelques risques supplémentaires ici.
Différences entre karaf et OSGI pur
En plus du framework karaf, il y a beaucoup de choses utiles. Essentiellement, karaf est un outil pour gérer facilement le cadre OSGI - y installer des bundles (y compris des groupes), les configurer, surveiller, décrire le modèle de rôle et assurer la sécurité, etc.
Et pratiquons déjà?
Eh bien, commençons tout de suite avec l'installation. Il n'y a pas grand-chose à écrire ici - allez sur karaf.apache.org, téléchargez le package de distribution, décompressez-le. Les versions de karaf diffèrent dans la prise en charge des différentes spécifications OSGI (4, 5 ou 6) et des versions Java. Je ne recommande pas la famille 2.x, mais 3 (si vous avez Java 8, comme le mien) et 4 peuvent être utilisés, bien qu'aujourd'hui seule la famille 4.x se développe (version actuelle 4.2.2, elle prend en charge OSGI 6 et Java jusqu'à 10).
Karaf fonctionne bien sous Windows et Linux, tout ce dont vous avez besoin pour créer un service et l'exécution automatique est disponible. La prise en charge de MacOS et de nombreux autres types d'Unix est également déclarée.
Vous pouvez généralement démarrer karaf immédiatement si vous êtes sur Internet. Sinon, cela vaut généralement la peine de corriger le fichier de configuration, en indiquant où vous avez le ou les référentiels maven. Habituellement, ce sera un Nexus d'entreprise, ou disons Artifactory, qui aime quoi. La configuration karaf se trouve dans le dossier etc de la distribution. Les noms des fichiers de configuration ne sont pas très évidents, mais dans ce cas, vous avez besoin du fichier org.ops4j.pax.url.mvn.cfg. Le format de ce fichier est les propriétés java.
Vous pouvez spécifier le (s) référentiel (s) à la fois dans le fichier de configuration lui-même, en répertoriant la liste des URL dans les paramètres ou simplement en montrant où se trouve votre fichier settings.xml. Là, le karaf prendra l'emplacement de votre proxy, ce qui est généralement nécessaire de connaître sur l'intranet.
Kafar a besoin de plusieurs ports, ce sont HTTP, HTTPS (si le web est configuré, par défaut non), SSH, RMI, JMX. S'ils sont occupés avec vous ou si vous souhaitez exécuter plusieurs copies sur le même hôte, vous devrez également les modifier. Il y a environ cinq de ces ports.
Ports tels que jmx et rmi - ici: org.apache.karaf.management.cfg, ssh - org.apache.karaf.shell.cfg, pour changer les ports http / https, vous devrez créer (très probablement pas) le fichier etc / org.ops4j.pax.web.cfg et écrivez la valeur org.osgi.service.http.port = port dont vous avez besoin.
Ensuite, vous pouvez certainement le démarrer, et en règle générale, tout commencera. Pour une utilisation industrielle, vous devrez évidemment apporter des modifications au fichier bin / setenv ou bin / setenv.bat, par exemple, pour allouer la quantité de mémoire requise, mais d'abord, pour voir, ce n'est pas nécessaire.
Vous pouvez démarrer Karaf immédiatement avec la console, la commande karaf, ou vous pouvez l'exécuter en arrière-plan avec la commande start server, puis vous y connecter via SSH. Il s'agit d'un SSH entièrement standard, avec prise en charge de SCP et SFTP. Vous pouvez exécuter des commandes et copier des fichiers dans les deux sens. Il est possible de se connecter avec n'importe quel client, par exemple, mon outil préféré est Far NetBox. La connexion est disponible par identifiant et mot de passe, ainsi que par clés. Dans les abats jsch, avec tout ce que cela implique.
Je recommande d'avoir une fenêtre de console supplémentaire immédiatement pour afficher les journaux qui se trouvent dans data / log / karaf.log (et d'autres fichiers sont généralement là, bien que cela soit personnalisable). Les journaux vous sont utiles, à partir de messages courts dans la console, tout n'est pas clair.
Je conseillerais d'installer immédiatement le Web et la console Web hawtio. Ces deux choses vous permettront de naviguer plus facilement dans ce qui se passe dans le conteneur et de diriger le processus à partir de là dans une large mesure (en bonus, vous obtiendrez du jolokia et la possibilité de surveiller via http). L'installation de hawtio se fait par deux commandes depuis la console karaf (
comme décrit ici ), et hélas, aujourd'hui la version de karaf 3.x n'est plus supportée (vous devrez chercher des versions plus anciennes de hawtio).
Hors de la boîte, https ne sera pas immédiatement, pour cela, vous devez faire des efforts tels que la génération de certificats, etc. L'implémentation est basée sur Jetty, donc tous ces efforts sont principalement effectués de la même manière.
OK, ça a commencé, quelle est la prochaine étape?

En fait, à quoi vous attendiez-vous? J'ai dit que ce sera ssh. Tab fonctionne, si cela.
Il est temps d'installer une application. Une application pour OSGI est soit un bundle, soit se compose de plusieurs bundles. Karaf peut déployer des applications dans plusieurs formats:
- Un ensemble de pots, avec ou sans manifeste OSGI
- xml contenant Spring DM ou Blueprint
- xml contenant la soi-disant fonctionnalité, qui est une collection de bundles, d'autres fonctionnalités et de ressources (fichiers de configuration)
- Archive .kar contenant plusieurs fonctionnalités et un référentiel maven avec des dépendances
- Applications JavaEE (sous certaines conditions supplémentaires), par exemple .war
Il existe plusieurs façons de procéder:
- mettre l'application dans le dossier de déploiement
- installez à partir de la console avec la commande install
- installer la fonctionnalité avec la commande de la fonctionnalité: installer la console
- kar: installer
Eh bien, en général, c'est assez similaire à ce qu'un conteneur JavaEE typique peut faire, mais c'est un peu plus pratique (je dirais que c'est beaucoup plus pratique).
Pot simple
L'option la plus simple consiste à installer un bocal ordinaire. Si vous l'avez dans le référentiel maven, alors la commande suffit pour installer:
install mvn:groupId/artifactId/version
Dans le même temps, Karaf se rend compte qu'il a un pot régulier devant lui et le traite, créant un emballage de paquet à la volée, le soi-disant wrapper, générant un manifeste par défaut, avec les importations et les exportations de packages.
Le sentiment d'installer juste un bocal n'est généralement pas beaucoup, car ce bundle sera passif - il exporte uniquement les classes qui seront disponibles pour d'autres bundles.
Cette méthode est utilisée pour installer des composants comme Apache Commons Lang, par exemple:
install mvn:org.apache.commons.lang3/commons-lang/3.8.1
Mais cela n'a pas fonctionné :) Voici les coordonnées correctes:
install mvn:org.apache.commons/commons-lang3/3.8.1
Voyons ce qui s'est passé: list -u nous montrera les bundles et leurs sources:
karaf@root()> list -u START LEVEL 100 , List Threshold: 50 ID | State | Lvl | Version | Name | Update location ------------------------------------------------------------------------------------------------- 87 | Installed | 80 | 3.8.1 | Apache Commons Lang | mvn:org.apache.commons/commons-lang3/3.8.1 88 | Installed | 80 | 3.6.0 | Apache Commons Lang | mvn:org.apache.commons/commons-lang3/3.6
Comme vous pouvez le voir, il est tout à fait possible d'installer deux versions d'un composant. Emplacement de mise à jour - c'est là que nous avons obtenu le bundle et où il peut être mis à jour si nécessaire.
Contexte Jar et Spring
S'il y a un contexte printanier à l'intérieur de votre pot, les choses deviennent plus intéressantes. Karaf Deployer recherche automatiquement les contextes xml dans le dossier META-INF / spring et les crée si tous les bundles externes nécessaires au bundle ont été trouvés avec succès.
Ainsi, tous les services qui étaient à l'intérieur des contextes démarreront déjà. Si vous aviez Camel Spring là-bas, par exemple, les itinéraires Camel commenceront également. Cela signifie que nous disons un service REST, ou un service d'écoute sur un port TCP, vous pouvez déjà démarrer. Bien sûr, lancer plusieurs services en écoutant sur un port ne fonctionnera pas de cette façon.
Contexte XML Just Spring
Si, par exemple, vous disposiez de définitions JDBC DataSources dans Spring Context, vous pouvez les installer séparément dans Karaf. C'est-à-dire prendre un fichier xml contenant uniquement un DataSource sous la forme de <bean>, ou tout autre ensemble de composants, vous pouvez le placer dans le dossier de déploiement. Le contexte sera lancé de manière standard. Le seul problème est que les DataSources créées de cette manière ne seront pas visibles par les autres bundles. Ils doivent être exportés vers OSGI en tant que services. À ce sujet - un peu plus tard.
Printemps dm
Quelle est la différence entre Spring DM (version compatible OSGI) et Spring classique? Ainsi, dans le cas classique, tous les beans du contexte sont créés au stade de l'initialisation du contexte. Les nouveaux ne peuvent pas apparaître, les anciens n'iront nulle part. Dans le cas d'OSGI, de nouveaux bundles peuvent être installés et les anciens bundles supprimés. L'environnement devient plus dynamique, vous devez en quelque sorte réagir.
La méthode de réponse est appelée services. Un service est généralement une certaine interface, avec ses propres méthodes, qui est publiée par un ensemble. Un service a des métadonnées qui lui permettent d'être recherché et distingué d'un autre service qui implémente une interface similaire (évidemment, à partir d'une autre DataSource). Les métadonnées sont un simple ensemble de propriétés de valeur-clé.
Étant donné que les services peuvent apparaître et disparaître, ceux qui en ont besoin peuvent souscrire à des services au démarrage ou écouter des événements pour connaître leur apparition ou leur disparition. Au niveau de Spring DM, en XML, cela est implémenté en deux éléments, service et référence, dont le but de base est assez simple: publier le bean existant à partir du contexte en tant que service, et s'abonner à un service externe en le publiant dans le contexte Spring actuel.
Par conséquent, lors de l'initialisation d'un tel bundle, le conteneur trouvera les services externes dont il a besoin pour lui et publiera les bundles implémentés à l'intérieur, les rendant accessibles de l'extérieur. Un bundle ne démarre qu'après la résolution des liens de service.
En fait, tout est un peu plus compliqué, car le bundle peut utiliser une liste de services similaires et s'abonner immédiatement à la liste. C'est-à-dire un service, en général, a une propriété telle que la cardinalité, qui prend la valeur 0..N. Dans ce cas, l'abonnement, où 0..1 est indiqué, décrit un service facultatif, et dans ce cas, le bundle démarre correctement même s'il n'y a pas un tel service dans le système (et au lieu d'un lien vers celui-ci, il obtiendra un talon).
Je note qu'un service est n'importe quelle interface (ou vous pouvez publier uniquement des classes), vous pouvez donc bien publier java.util.Map avec des données en tant que service.
Entre autres choses, le service vous permet de spécifier des métadonnées et la référence vous permet de rechercher un service par ces métadonnées.
Blueprint
Blueprint est la nouvelle incarnation de Spring DM, qui est un peu plus simple. À savoir, si au printemps vous avez des éléments XML personnalisés, ils ne sont pas là, car ils ne sont pas nécessaires. Parfois, cela cause toujours des désagréments, mais franchement - rarement. Si vous ne migrez pas un projet à partir de Spring, vous pouvez commencer immédiatement avec Blueprint.
L'essence ici est la même - c'est XML, qui décrit les composants à partir desquels le contexte du bundle est assemblé. Pour ceux qui connaissent le printemps, rien n'est inconnu du tout.
Voici un exemple de description d'un DataSource et de son exportation en tant que service:
<?xml version="1.0" encoding="UTF-8"?> <blueprint xmlns="http://www.osgi.org/xmlns/blueprint/v1.0.0"> <bean id="dataSource" class="oracle.jdbc.pool.OracleDataSource"> <property name="URL" value="URL"/> <property name="user" value="USER"/> <property name="password" value="PASSWORD"/> </bean> <service interface="javax.sql.DataSource" ref="dataSource" id="ds"> <service-properties> <entry key="osgi.jndi.service.name" value="jdbc/ds"/> </service-properties> </service> </blueprint>
Eh bien, nous avons déployé ce fichier dans le dossier de déploiement et examiné les résultats de la commande list. Ils ont vu que le paquet n'a pas commencé - dans le statut Indtalled. Nous essayons de démarrer et nous obtenons un message d'erreur.
Maintenant dans la liste des bundles au statut Echec. Quoi de neuf? Évidemment, il a également besoin de dépendances, dans ce cas, un Jar avec des classes Oracle JDBC, ou plus précisément, le package oracle.jdbc.pool.
Nous trouvons le fichier jar nécessaire dans le référentiel, ou téléchargeable à partir du site Oracle, et installons, comme décrit précédemment. Notre DataSource a démarré.
Comment utiliser tout ça? Le lien de service est appelé dans la référence Blueprint (quelque part, dans le contexte d'un autre bundle):
<reference id="dataSource" interface="javax.sql.DataSource"/>
Ensuite, ce bean devient, comme d'habitude, une dépendance pour d'autres beans (dans l'exemple camel-sql):
<bean id="sql" class="org.apache.camel.component.sql.SqlComponent"> <property name="dataSource" ref="dataSource"/> </bean>
Pot et activateur
La manière canonique d'initialiser des bundles consiste à utiliser une classe qui implémente l'interface Activator. Il s'agit d'une interface de cycle de vie typique contenant des méthodes de démarrage et d'arrêt qui passent le
contexte . À l'intérieur, le bundle démarre généralement ses threads, si nécessaire, commence à écouter les ports, s'abonne à des services externes à l'aide de l'API OSGI, etc. C'est peut-être la manière la plus complexe, la plus élémentaire et la plus flexible. Depuis trois ans, je n'en ai jamais eu besoin.
Paramètres et configuration
Il est clair qu'une telle configuration de DataSource, comme le montre l'exemple, nécessite peu de personnes. Login, mot de passe et plus encore, tout est codé en dur dans XML. Il est nécessaire de supprimer ces paramètres.
<property name="url" value="${oracle.ds.url}"/> <property name="user" value="${oracle.ds.user}"/> <property name="password" value="${oracle.ds.password}"/>
La solution est assez simple et similaire à celle utilisée dans le Spring classique: à un certain point du cycle de vie du contexte, les valeurs des propriétés sont substituées à partir de diverses sources.
Sur ce, nous terminerons la première partie. S'il y a un intérêt pour ce sujet, alors continuez. Nous verrons comment assembler des applications à partir de bundles, configurer, surveiller et déployer automatiquement des systèmes sur cette plate-forme.