→
Test des projets Node.js. Partie 1. Anatomie d'essai et types d'essaiAujourd'hui, dans la deuxième partie de la traduction du matériel consacré aux tests des projets Node.js, nous parlerons de l'évaluation de l'efficacité des tests et de l'analyse de la qualité du code.
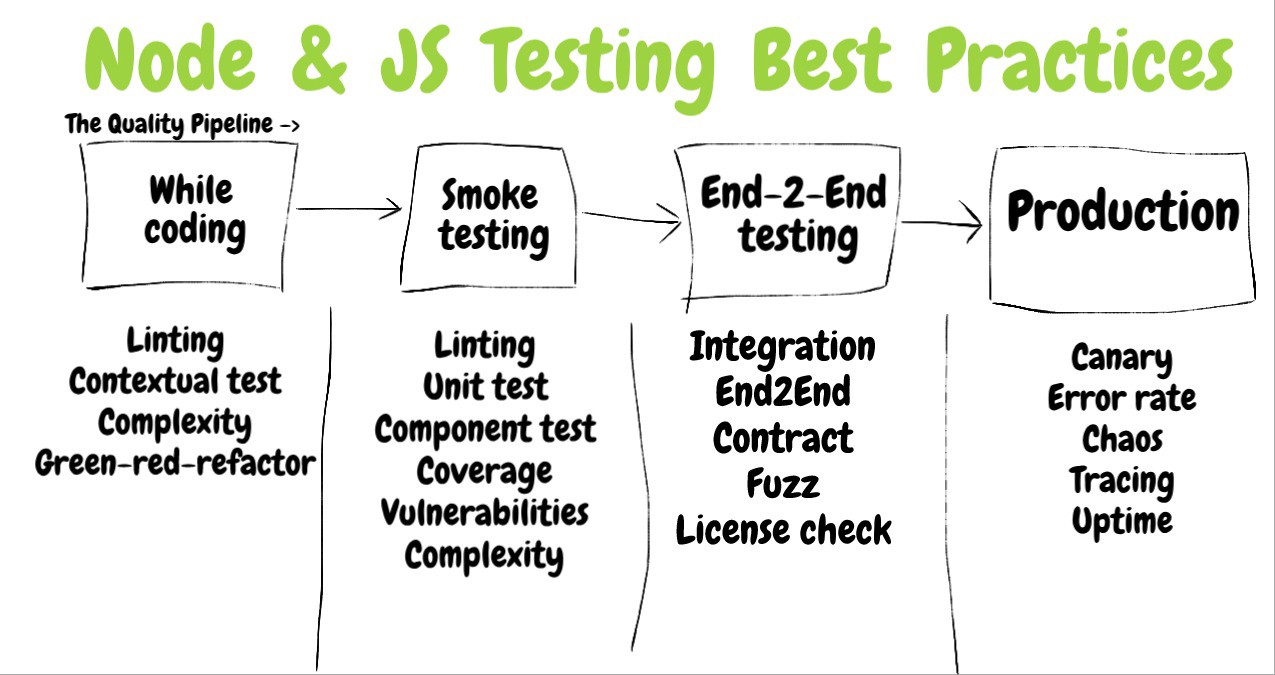
Section 3. Évaluation de l'efficacité des tests
▍19. Atteindre un niveau de couverture de code suffisamment élevé avec des tests afin de gagner en confiance dans son bon fonctionnement. Habituellement, une couverture d'environ 80% donne de bons résultats.
Recommandations
Le but des tests est de s'assurer que le programmeur peut continuer à travailler de manière productive sur le projet, en s'assurant que ce qui a déjà été fait est correct. Évidemment, plus le volume du code testé est grand, plus la confiance que tout fonctionne comme il se doit est forte. L'indicateur de couverture du code par les tests indique le nombre de lignes (branches, commandes) vérifiées par les tests. Quel devrait être cet indicateur? Il est clair que 10 à 30% est trop peu pour donner l'assurance que le projet fonctionnera sans erreur. D'autre part, le désir de couvrir à 100% le code avec des tests peut être un plaisir trop cher et peut distraire le développeur des fragments de programme les plus importants, le forçant à rechercher dans le code les endroits où les tests existants n'atteignent pas. Si vous donnez une réponse plus complète à la question de savoir quelle devrait être la couverture du code avec des tests, alors nous pouvons dire que l'indicateur auquel nous devons nous efforcer dépend de l'application en cours de développement. Par exemple, si vous écrivez un logiciel pour la prochaine génération d'Airbus A380, alors 100% est un indicateur qui n'est même pas discuté. Mais si vous créez un site Web sur lequel des galeries de caricature seront affichées, alors probablement 50%, c'est déjà beaucoup. Bien que les experts en tests disent que le niveau de couverture du code avec des tests que vous devez rechercher dépend du projet, beaucoup d'entre eux mentionnent le chiffre de 80%, qui convient probablement à la plupart des applications. Par exemple, nous parlons ici de quelque chose de l'ordre de 80 à 90%, et, selon l'auteur de ce document, une couverture à 100% du code avec des tests le rend suspect, car cela peut indiquer que le programmeur écrit des tests uniquement pour obtenir beau numéro dans le rapport.
Afin d'utiliser les indicateurs des tests de couverture de code, vous devrez configurer correctement votre système pour une intégration continue (CI, intégration continue). Cela permettra, si l'indicateur correspondant n'atteint pas un certain seuil, d'arrêter le montage du projet.
Voici comment configurer Jest pour collecter les informations de couverture de test. De plus, vous pouvez configurer des seuils de couverture non pas pour tout le code, mais en vous concentrant sur les composants individuels. En plus de cela, envisagez de détecter une diminution de la couverture des tests. Cela se produit, par exemple, lors de l'ajout de nouveau code à un projet. Le contrôle de cet indicateur encouragera les développeurs à augmenter le volume du code testé, ou au moins à maintenir ce volume au niveau existant. Compte tenu de ce qui précède, la couverture du code par des tests n'est qu'un indicateur, quantifié, qui ne suffit pas pour évaluer pleinement la fiabilité des tests. De plus, comme cela sera montré ci-dessous, ses niveaux élevés ne signifient pas encore que le code «couvert de tests» est vraiment vérifié.
Conséquences de la dérogation aux recommandations
La confiance du programmeur dans la haute qualité du code et des indicateurs associés liés aux tests va de pair. Un programmeur ne peut s'empêcher d'avoir peur des erreurs s'il ne sait pas que la majeure partie du code de son projet est couverte par des tests. Ces préoccupations peuvent ralentir votre projet.
Exemple
Voici à quoi ressemble un rapport de couverture de test typique.
Rapport de couverture des tests généré par IstanbulBonne approche
Voici un exemple de définition du niveau souhaité de couverture de test du code composant et du niveau général de cet indicateur dans Jest.
Définition du niveau de couverture de code souhaité avec des tests pour l'ensemble du projet et pour un composant spécifique▍20. Examiner les rapports sur la couverture du code avec des tests pour identifier les parties non protégées du code et d'autres anomalies
Recommandations
Certains problèmes ont tendance à passer à travers une variété de systèmes de détection d'erreurs. De telles choses peuvent être difficiles à détecter à l'aide d'outils traditionnels. Cela ne s'applique peut-être pas aux vraies erreurs. Nous parlons plutôt d'un comportement d'application inattendu, qui peut avoir des conséquences dévastatrices. Par exemple, il arrive souvent que certains fragments de code ne soient jamais utilisés ou soient rarement appelés. Par exemple, vous pensez que les mécanismes de la classe
PricingCalculator toujours utilisés pour fixer le prix d'un produit, mais en fait il s'avère que cette classe n'est pas utilisée du tout, et il y a des enregistrements de 10000 produits dans la base de données et dans la boutique en ligne où le système est utilisé, beaucoup de ventes ... Les rapports sur la couverture du code avec des tests aident le développeur à comprendre si l'application fonctionne comme elle devrait fonctionner. De plus, à partir des rapports, vous pouvez savoir quel code de projet n'est pas testé. Si vous vous concentrez sur un indicateur général qui indique que les tests couvrent 80% du code, vous ne pouvez pas savoir si des parties critiques de l'application sont testées. Pour générer un tel rapport, il suffit de configurer correctement l'outil que vous utilisez pour exécuter les tests. De tels rapports sont généralement assez jolis, et leur analyse, qui ne prend pas beaucoup de temps, vous permet de détecter toutes sortes de surprises.
Conséquences de la dérogation aux recommandations
Si vous ne savez pas quelles parties de votre code restent non testées, vous ne savez pas où vous pouvez vous attendre à des problèmes.
Mauvaise approche
Examinez le prochain rapport et réfléchissez à ce qui semble inhabituel.
Rapport indiquant un comportement inhabituel du systèmeLe rapport est basé sur un scénario réel d'utilisation de l'application et vous permet de voir le comportement inhabituel du programme associé aux utilisateurs se connectant au système. À savoir, un nombre étonnamment élevé de tentatives infructueuses pour entrer dans le système attire votre attention par rapport à celles qui ont réussi. Après analyse du projet, il s'est avéré que la raison en était une erreur dans le frontend, en raison de laquelle la partie interface du projet envoyait constamment des demandes correspondantes à l'API du serveur pour entrer dans le système.
▍21. Mesurer la couverture du code logique avec des tests à l'aide de tests de mutation
Recommandations
Les paramètres d'analyse comparative traditionnels peuvent ne pas être fiables. Ainsi, dans le rapport, il peut y avoir un chiffre de 100%, mais en même temps, absolument toutes les fonctions du projet renverront des valeurs incorrectes. Comment expliquer ça? Le fait est que l'indicateur de couverture du code par les tests n'indique que les lignes de code qui ont été exécutées sous le contrôle du système de test, mais cela ne dépend pas de savoir si quelque chose a été vraiment vérifié, c'est-à-dire si les déclarations du test ont été visant à vérifier l'exactitude des résultats du code. Cela ressemble à une personne qui, de retour d'un voyage d'affaires à l'étranger, montre des tampons dans son passeport. Les timbres prouvent qu'il est allé quelque part, mais ils ne disent pas s'il a fait ce qu'il est allé en voyage d'affaires.
Ici, les tests de mutation peuvent nous être utiles, ce qui nous permet de savoir combien de code a été réellement testé, et pas seulement visité par le système de test. Pour les tests mutationnels, vous pouvez utiliser la bibliothèque
Stryker JS. Voici les principes selon lesquels cela fonctionne:
- Elle modifie intentionnellement le code, créant des erreurs. Par exemple, le code
newOrder.price===0 devient newOrder.price!=0 . Ces «erreurs» sont appelées mutations. - Elle exécute des tests. S'ils s'avèrent être réussis, alors nous avons des problèmes, car les tests ne remplissent pas leur tâche de détection des erreurs, et les «mutants», comme on dit, «survivent». Si les tests indiquent des erreurs dans le code, alors tout est en ordre - les "mutants" "meurent".
S'il s'avère que tous les "mutants" ont été "tués" (ou, du moins, la plupart d'entre eux n'ont pas survécu), cela donne un niveau de confiance plus élevé dans la haute qualité du code et les tests qui le testent que les mesures traditionnelles pour couvrir le code avec des tests. Dans le même temps, le temps requis pour configurer et effectuer des tests mutationnels est comparable à celui nécessaire lors de l'utilisation de tests conventionnels.
Conséquences de la dérogation aux recommandations
Si l'indicateur traditionnel de couverture du code par des tests indique que 85% du code est couvert par des tests, cela ne signifie pas que les tests sont capables de détecter des erreurs dans ce code.
Mauvaise approche
Voici un exemple de couverture à 100% du code avec des tests, dans lequel le code n'est pas complètement testé.
function addNewOrder(newOrder) { logger.log(`Adding new order ${newOrder}`); DB.save(newOrder); Mailer.sendMail(newOrder.assignee, `A new order was places ${newOrder}`); return {approved: true}; } it("Test addNewOrder, don't use such test names", () => { addNewOrder({asignee: "John@mailer.com",price: 120}); });
Bonne approche
Voici le rapport de test de mutation généré par la bibliothèque Stryker. Il vous permet de savoir combien de code n'est pas testé (cela est indiqué par le nombre de "mutants" "survivants").
Rapport StrykerLes résultats de ce rapport permettent avec plus de confiance que les indicateurs habituels de couverture du code avec des tests de dire que les tests fonctionnent comme prévu.
- Une mutation est un code qui a été délibérément modifié par la bibliothèque Stryker pour tester l'efficacité d'un test.
- Le nombre de «mutants» (tués) «tués» indique le nombre de défauts de code («mutants») créés intentionnellement qui ont été identifiés au cours des tests.
- Le nombre de «mutants» «survécus» (survécu) vous permet de savoir combien de tests de défauts de code n'ont pas trouvés.
Section 4. Intégration continue, autres indicateurs de qualité du code
▍ 22. Profitez des capacités de linter et interrompez le processus de construction du projet lorsqu'il détecte les problèmes signalés
Recommandations
Aujourd'hui, les linters sont des outils puissants qui peuvent identifier de graves problèmes de code. Il est recommandé, en plus de quelques règles de base de linting (telles que celles implémentées par les
plugins eslint-plugin-standard et
eslint-config-airbnb ), d'utiliser des règles spécialisées. Par exemple, ce sont les règles implémentées au moyen du
plugin eslint-plugin-chai-expect pour vérifier l'exactitude du code de test, ce sont les règles du
plugin eslint-plugin-promise qui contrôlent le travail avec les promesses, ce sont les règles de
eslint-plugin-security qui vérifient la présence du code il contient des expressions régulières dangereuses. Ici, vous pouvez également mentionner le
plug-in eslint-plugin-you-dont-need-lodash-underscore , qui vous permet de trouver dans le code l'utilisation de méthodes provenant de bibliothèques externes qui ont des analogues en JavaScript pur.
Conséquences de la dérogation aux recommandations
Un jour de pluie est arrivé, le projet donne des échecs continus de production et il n'y a aucune information sur les piles d'erreurs dans les journaux. Qu'est-il arrivé? Il s'est avéré que ce que le code lève comme exception n'est pas vraiment un objet d'erreur. Par conséquent, les informations sur la pile n'entrent pas dans les journaux. En fait, dans une telle situation, le programmeur peut tuer contre le mur ou, ce qui est beaucoup mieux, passer 5 minutes à configurer le linter, ce qui détectera facilement le problème et assurera le projet contre des problèmes similaires qui pourraient survenir à l'avenir.
Mauvaise approche
Voici le code qui, par inadvertance, lève un objet ordinaire comme exception, alors qu'ici vous avez besoin d'un objet de type
Error . Sinon, les données sur la pile ne seront pas enregistrées dans le journal. ESLint trouve ce qui pourrait causer des problèmes de production, aidant à éviter ces problèmes.
ESLint vous aide à trouver un bogue dans votre code▍23. Retour d'information plus rapide avec les développeurs utilisant l'intégration continue locale
Recommandations
Vous utilisez un système centralisé d'intégration continue, qui aide à contrôler la qualité du code, à le tester, à l'aide du linter, à le rechercher des vulnérabilités? Si tel est le cas, assurez-vous que les développeurs peuvent exécuter ce système localement. Cela leur permettra de vérifier instantanément leur code, ce qui accélère les
commentaires et réduit le temps de développement du projet. Pourquoi en est-il ainsi? Un processus de développement et de test efficace implique de nombreuses opérations répétées cycliquement. Le code est testé, puis le développeur reçoit un rapport, puis, si nécessaire, le code est refactorisé, après quoi tout est répété. Plus la boucle de rétroaction fonctionne rapidement, plus les développeurs reçoivent rapidement des rapports sur les tests de code, plus ils peuvent effectuer d'itérations d'amélioration de ce code. S'il faut beaucoup de temps pour obtenir un rapport de test, cela peut entraîner une mauvaise qualité du code. Supposons que quelqu'un travaille sur un module, puis commence à travailler sur autre chose, puis reçoive un rapport sur le module, ce qui indique que le module doit être amélioré. Cependant, déjà occupé par des sujets complètement différents, le développeur ne fera pas assez attention au module problème.
Certains fournisseurs de solutions CI (disons que cela s'applique à
CircleCI ) vous permettent d'exécuter le pipeline CI localement. Certains outils payants, comme
Wallaby.js (l'auteur note qu'il n'est pas connecté à ce projet), peuvent rapidement obtenir des informations précieuses sur la qualité du code. De plus, le développeur peut simplement ajouter le script npm approprié à
package.json , qui effectue des vérifications de la qualité du code (tests, analyses avec un linter, recherche des vulnérabilités), et utilise même le package
simultanément pour accélérer les vérifications. Maintenant, afin de vérifier complètement le code, il suffira d'exécuter une seule commande, comme la
npm run quality , et d'obtenir immédiatement un rapport. De plus, si les tests de code indiquent qu'il a des problèmes, vous pouvez annuler les validations à l'aide de git hooks (la bibliothèque
husky peut être utile pour résoudre ce problème).
Conséquences de la dérogation aux recommandations
Si un développeur reçoit un rapport sur la qualité du code un jour après avoir écrit ce code, un tel rapport est susceptible de se transformer en quelque chose comme un document formel, et les tests de code seront dissociés du travail, ne devenant pas sa partie naturelle.
Bonne approche
Voici un script npm qui vérifie la qualité du code. La réalisation des vérifications est parallélisée. Le script est exécuté lors de la tentative d'envoi de nouveau code au référentiel. De plus, le développeur peut le lancer de sa propre initiative.
"scripts": { "inspect:sanity-testing": "mocha **/**--test.js --grep \"sanity\"", "inspect:lint": "eslint .", "inspect:vulnerabilities": "npm audit", "inspect:license": "license-checker --failOn GPLv2", "inspect:complexity": "plato .", "inspect:all": "concurrently -c \"bgBlue.bold,bgMagenta.bold,yellow\" \"npm:inspect:quick-testing\" \"npm:inspect:lint\" \"npm:inspect:vulnerabilities\" \"npm:inspect:license\"" }, "husky": { "hooks": { "precommit": "npm run inspect:all", "prepush": "npm run inspect:all" } }
▍24. Effectuer des tests de bout en bout sur un miroir d'environnement de production réaliste
Recommandations
Dans le vaste écosystème de Kubernetes, il existe toujours un consensus pour utiliser des outils adaptés au déploiement des environnements locaux, bien que de tels outils apparaissent assez souvent. Une approche possible ici consiste à exécuter un Kubernetes «minimisé» à l'aide d'outils tels que
Minikube ou
MicroK8 , qui vous permettent de créer des environnements légers qui ressemblent à de vrais. Une autre approche consiste à tester des projets dans un environnement Kubernetes «réel» distant. Certains fournisseurs de CI (tels que
Codefresh ) permettent d'interagir avec les environnements intégrés de Kubernetes, ce qui simplifie le travail des pipelines de CI lors du test de projets réels. D'autres vous permettent de travailler avec des environnements Kubernetes distants.
Conséquences de la dérogation aux recommandations
L'utilisation de différentes technologies dans la production et les tests nécessite le support de deux modèles de développement et conduit à la séparation des équipes de programmeurs et de spécialistes DevOps.
Bonne approche
Voici un exemple de chaîne CI, qui, comme on dit, crée à la volée un cluster Kubernetes (c'est tiré
d'ici ).
deploy: stage: deploy image: registry.gitlab.com/gitlab-examples/kubernetes-deploy script: - ./configureCluster.sh $KUBE_CA_PEM_FILE $KUBE_URL $KUBE_TOKEN - kubectl create ns $NAMESPACE - kubectl create secret -n $NAMESPACE docker-registry gitlab-registry --docker-server="$CI_REGISTRY" --docker-username="$CI_REGISTRY_USER" --docker-password="$CI_REGISTRY_PASSWORD" --docker-email="$GITLAB_USER_EMAIL" - mkdir .generated - echo "$CI_BUILD_REF_NAME-$CI_BUILD_REF" - sed -e "s/TAG/$CI_BUILD_REF_NAME-$CI_BUILD_REF/g" templates/deals.yaml | tee ".generated/deals.yaml" - kubectl apply --namespace $NAMESPACE -f .generated/deals.yaml - kubectl apply --namespace $NAMESPACE -f templates/my-sock-shop.yaml environment: name: test-for-ci
▍25. S'efforcer de paralléliser l'exécution des tests
Recommandations
Si le système de test est bien organisé, il deviendra votre ami fidèle, 24 heures sur 24, prêt à signaler les problèmes avec le code. Pour ce faire, les tests doivent être effectués très rapidement. En pratique, il s'avère que l'exécution en mode unitaire 500 tests unitaires qui utilisent intensivement le processeur prend trop de temps. Et ces tests doivent être effectués assez souvent. Heureusement, les outils modernes pour exécuter des tests (
Jest ,
AVA , une
extension pour Mocha ) et les plates-formes CI peuvent exécuter des tests en parallèle en utilisant plusieurs processus, ce qui peut considérablement améliorer la vitesse de réception des rapports de test. Certaines plateformes CI savent même comment paralléliser les tests entre les conteneurs, ce qui améliore encore la boucle de rétroaction. Pour réussir à paralléliser l'exécution des tests, locaux ou distants, les tests ne doivent pas dépendre les uns des autres. Les tests autonomes peuvent être exécutés sans problème dans différents processus.
Conséquences de la dérogation aux recommandations
Obtenir des résultats de test une heure après l'envoi du code au référentiel tout en travaillant sur de nouvelles fonctionnalités de projet est un excellent moyen de réduire l'utilité des résultats de test.
Bonne approche
Grâce à l'exécution parallèle de tests, la bibliothèque
mocha-parallel-test et le framework
Jest contournent facilement Mocha (
c'est la source de cette information).
Tester les outils de test de performance▍26. Protégez-vous contre les problèmes juridiques en utilisant la vérification de licence et la vérification du code de plagiat
Recommandations
Peut-être que maintenant vous n'êtes pas particulièrement préoccupé par les problèmes avec la loi et le plagiat. Cependant, pourquoi ne pas rechercher des problèmes similaires dans votre projet? Il existe de nombreux outils pour organiser de telles inspections. Par exemple, ce sont le
vérificateur de licence et le vérificateur de plagiat (il s'agit d'un package commercial, mais il est possible de l'utiliser gratuitement). Il est facile d'intégrer de telles vérifications dans le pipeline CI et de vérifier le projet, par exemple, pour la présence de dépendances avec des licences limitées, ou pour la présence de code copié à partir de StackOverflow et portant probablement atteinte aux droits d'auteur de quelqu'un d'autre.
Conséquences de la dérogation aux recommandations
Le développeur peut, par inadvertance, utiliser le package avec une licence qui ne convient pas à son projet, ou copier le code commercial, ce qui peut entraîner des problèmes juridiques.
Bonne approche
Installez le package de vérificateur de licence localement ou dans un environnement CI:
npm install -g license-checker
Nous vérifierons les licences avec lui et s'il trouve quelque chose qui ne nous convient pas, nous reconnaîtrons que le chèque a échoué. Le système CI, après avoir détecté un problème lors de la vérification des licences, arrêtera l'assemblage du projet.
license-checker --summary --failOn BSD
Vérification de licence▍27. Vérifier constamment le projet pour les dépendances vulnérables
Recommandations
Même les packages hautement respectés et fiables, tels qu'Express, présentent des vulnérabilités. Afin d'identifier ces vulnérabilités, vous pouvez utiliser des outils spéciaux - comme l'outil standard pour l'
audit des packages npm ou le projet commercial
snyk , qui a une version gratuite. Ces vérifications, ainsi que d'autres, peuvent faire partie du pipeline CI.
Conséquences de la dérogation aux recommandations
Afin de protéger votre projet contre les vulnérabilités de ses dépendances sans utiliser d'outils spéciaux, vous devrez surveiller en permanence les publications sur ces vulnérabilités. C'est une tâche qui prend beaucoup de temps.
Bonne approche
Voici les résultats de la vérification du projet à l'aide de NPM Audit.
Rapport du package de vérification de la vulnérabilité▍28. Automatiser les mises à jour des dépendances
Recommandations
La route de l'enfer est pavée de bonnes intentions. Cette idée est pleinement applicable au
package-lock.json , dont l'utilisation, par défaut, bloque les mises à jour des packages. Cela se produit même dans les cas où les projets sont amenés à un état sain par les commandes
npm install et
npm update . Cela conduit, au mieux, à l'utilisation de packages obsolètes, ou, au pire, à l'apparition de code vulnérable dans le projet. En conséquence, les équipes de développement s'appuient soit sur une mise à jour manuelle des informations sur les versions appropriées des packages, soit sur des utilitaires comme
ncu , qui, là encore, sont lancés manuellement. Le processus de mise à jour des dépendances est mieux automatisé, en se concentrant sur l'utilisation des versions les plus fiables des packages utilisés dans le projet. Ce n'est pas la seule bonne solution, cependant, dans l'automatisation des mises à jour de packages, il existe quelques approches notables. La première consiste à
injecter quelque chose comme la vérification des packages en utilisant
npm-obsolète ou
npm-check-updates (ncu) dans le pipeline CI. Cela aidera à identifier les packages obsolètes et encouragera les développeurs à les mettre à niveau. La deuxième approche consiste à utiliser des outils commerciaux qui vérifient le code et effectuent automatiquement des requêtes d'extraction visant à mettre à jour les dépendances. Dans le domaine de la mise à jour automatique des dépendances, nous sommes confrontés à une autre question intéressante concernant la politique de mise à jour. Si elle est mise à jour avec chaque nouveau patch, la mise à jour peut mettre trop de pression sur le système. Si vous mettez à jour immédiatement après la publication de la prochaine version majeure du package, cela peut conduire à l'utilisation de solutions instables dans le projet (les vulnérabilités de nombreux packages se trouvent exactement dans les tout premiers jours après la publication,
lisez l'incident avec eslint-scope). « », , . , 1.3.1, 1.3.2, 1.3.8.
, , , .
ncu , , , .
ncu▍29. , Node.js
, Node.js-, , Node.js .
- . — , , , Jenkins .
- , Docker.
- . , , . (, ), , , , .
- , , , . — , , , .
- , . , feature, — master, , ( ).
- . , .
- .
- (, Docker) .
- , , , . ,
node_modules .
, , .
▍30.
, . , , , Node.js , . CI-, , « ». , , , . , , mySQL, — Postgres. , Node.js, — 8, 9 10. , . CI-.
, , , . , , .
CI- Travis Node.js.
language: node_js node_js: - "7" - "6" - "5" - "4" install: - npm install script: - npm run test
Résumé
, , . , , .
Chers lecteurs! ?
