
Tout projet client-serveur implique une séparation claire de la base de code en 2 parties (parfois plus) - client et serveur. Souvent, chacune de ces parties est exécutée sous la forme d'un projet indépendant distinct, soutenu par sa propre équipe de développeurs.
Dans cet article, je propose un regard critique sur la division matérielle standard du code en un backend et un frontend. Et considérez une alternative où le code n'a pas de ligne claire entre le client et le serveur.
Inconvénients de l'approche standard
Le principal inconvénient de la séparation standard du projet en 2 parties est l'érosion de la logique métier entre le client et le serveur. Nous modifions les données du formulaire dans le navigateur, les vérifions dans le code client et les envoyons au village du grand-père (au serveur). Le serveur est déjà un autre projet. Là, vous devez également vérifier l'exactitude des données reçues (c'est-à-dire dupliquer les fonctionnalités du client), effectuer des manipulations supplémentaires (enregistrer dans la base de données, envoyer des e-mails, etc.).
Ainsi, afin de tracer tout le chemin des informations depuis le formulaire dans le navigateur jusqu'à la base de données sur le serveur, nous devons plonger dans deux systèmes différents. Si les rôles sont divisés en équipe et que différents spécialistes sont responsables du backend et du frontend, des problèmes d'organisation supplémentaires surviennent liés à leur synchronisation.
Rêvons
Supposons que nous puissions décrire le chemin de données entier du formulaire sur le client à la base de données sur le serveur dans un modèle. Dans le code, cela peut ressembler à ceci (le code ne fonctionne pas):
class MyDataModel {
Ainsi, toute la logique métier du modèle est sous nos yeux. La gestion d'un tel code est plus facile. Voici les avantages que la combinaison de méthodes client-serveur dans un modèle peut apporter:
- La logique métier est concentrée en un seul endroit, il n'est pas nécessaire de la partager entre le client et le serveur.
- Vous pouvez facilement transférer des fonctionnalités du serveur au client ou du client au serveur pendant le développement du projet.
- Il n'est pas nécessaire de dupliquer les mêmes méthodes pour le backend et le frontend.
- Un seul ensemble de tests pour toute la logique métier du projet.
- Remplacement des lignes horizontales de délimitation des responsabilités dans le projet par des lignes verticales.
Je vais révéler le dernier point plus en détail. Imaginez une application client-serveur classique sous la forme d'un tel schéma:
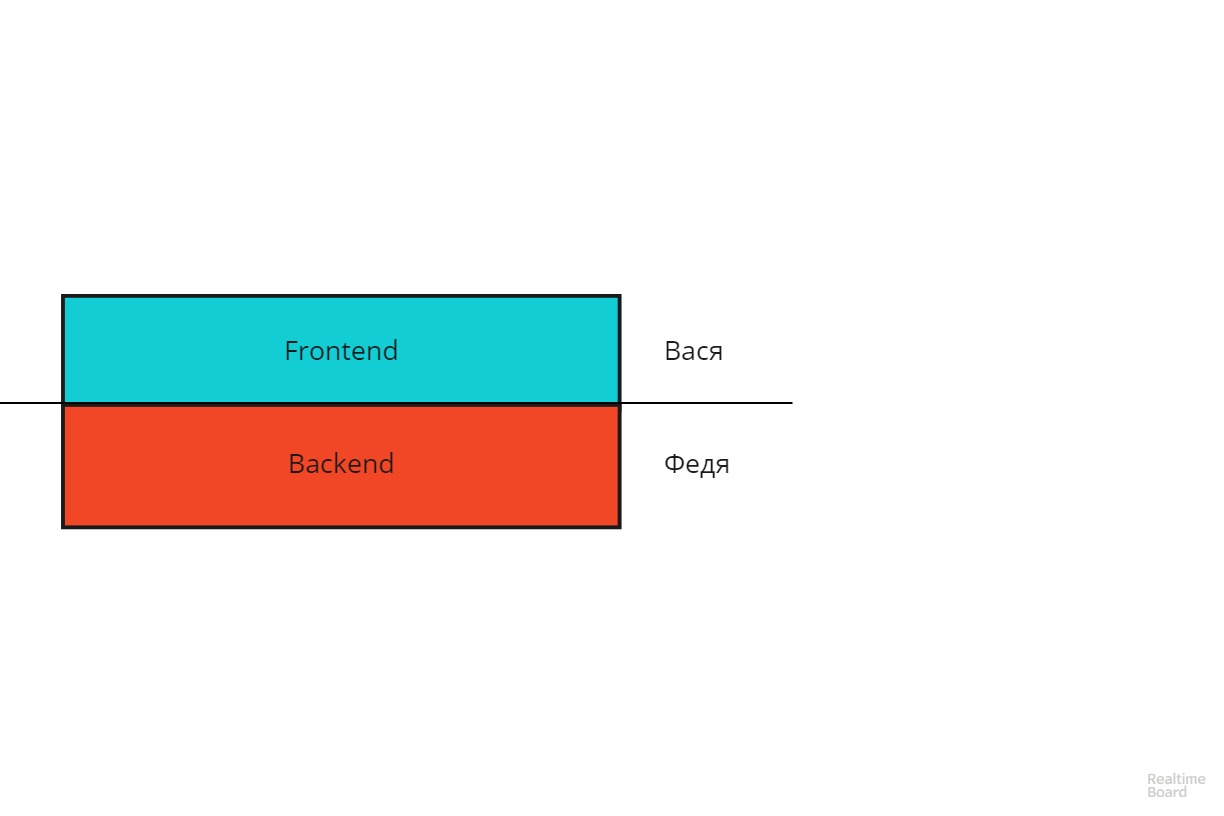
Vasya est responsable du frontend, Fedya - du backend. La ligne de délimitation des responsabilités est horizontale. Ce schéma présente les inconvénients de toute structure verticale - il est difficile à mettre à l'échelle et a une faible tolérance aux pannes. Si le projet prend de l'ampleur, vous devrez faire un choix assez difficile: qui renforcer Vasya ou Fedya? Ou si Fedya est tombé malade ou a démissionné, Vasya ne pourra pas le remplacer.
L'approche proposée ici vous permet d'élargir la ligne de partage des responsabilités de 90 degrés et de transformer l'architecture verticale en horizontale.
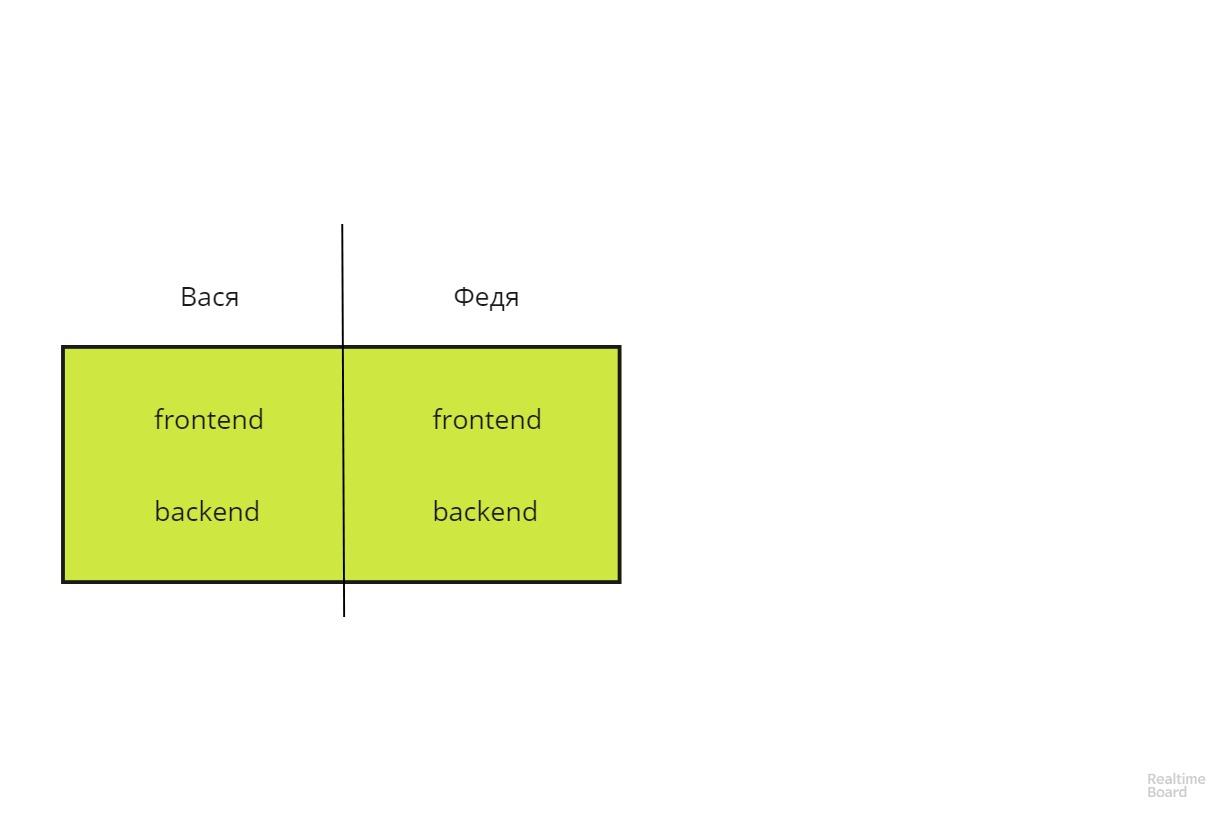
Une telle architecture est beaucoup plus facile à mettre à l'échelle et plus tolérante aux pannes. Vasya et Fedya deviennent interchangeables.
En théorie, cela semble bon, essayons d'implémenter tout cela dans la pratique, sans perdre tout ce qui nous donne l'existence séparée du client et du serveur en cours de route.
Énoncé du problème
Nous n'avons absolument pas besoin d'avoir un serveur client intégré dans le produit. Au contraire, une telle décision serait extrêmement préjudiciable à tous points de vue. La tâche est que dans le processus de développement, nous aurions une base de code unique pour les modèles de données pour le backend et le frontend, mais la sortie serait un client et un serveur indépendants. Dans ce cas, nous bénéficierons de tous les avantages de l'approche standard et bénéficierons des équipements listés ci-dessus pour le développement et l'accompagnement du projet.
Solution
J'expérimente avec l'intégration du client et du serveur dans un fichier depuis un certain temps. Jusqu'à récemment, le problème principal était que dans JS standard, la connexion des modules tiers sur le client et le serveur était trop différente: nécessite (...) dans node.js, toute la magie AJAX sur le client. Tout a changé avec l'avènement des modules ES. Dans les navigateurs modernes, «l'importation» est prise en charge depuis longtemps. Node.js est légèrement en retard à cet égard et les modules ES ne sont pris en charge qu'avec le drapeau "--experimental-modules" activé. On espère que dans un avenir prévisible, les modules fonctionneront hors de la boîte dans node.js. En outre, il est peu probable que quelque chose change beaucoup, car dans les navigateurs, cette fonctionnalité fonctionne depuis longtemps par défaut. Je pense que maintenant vous pouvez utiliser les modules ES non seulement côté client mais aussi côté serveur (si vous avez des contre-arguments à ce sujet, écrivez dans les commentaires).
Le schéma de solution ressemble à ceci:

Le projet contient trois catalogues principaux:
protégé - backend;
public - frontend;
shared - modèles client-serveur partagés.
Un processus d'observation distinct surveille les fichiers dans le répertoire partagé et, avec toutes les modifications, crée des versions du fichier modifié séparément pour le client et séparément pour le serveur (dans les répertoires protégé / partagé et public / partagé).
Implémentation
Prenons l'exemple d'un simple messager en temps réel. Nous aurons besoin de nouveaux node.js (j'ai la version 11.0.0) et Redis (les installer n'est pas couvert ici).
Clonez un exemple:
git clone https://github.com/Kolbaskin/both-example cd ./both-example npm i
Installez et exécutez le processus d'observation (observateur dans le diagramme):
npm i both-js -g both ./index.mjs
Si tout est en ordre, l'observateur lance le serveur Web et commence à surveiller les modifications apportées aux fichiers dans les répertoires partagés et protégés. Lorsque des modifications sont apportées au partage, les versions correspondantes des modèles de données pour le client et le serveur sont créées. En cas de modification de la protection, l'observateur redémarre automatiquement le serveur Web.
Vous pouvez voir les performances du messager dans le navigateur en cliquant sur le lien
http://localhost:3000/index.html?token=123&user=Vasya(le jeton et l'utilisateur sont arbitraires). Pour émuler plusieurs utilisateurs, ouvrez la même page dans un autre navigateur en spécifiant un jeton et un utilisateur différents.
Maintenant un petit code.
Serveur Web
protected / server.mjs
import express from 'express'; import bodyParser from 'body-parser';
Il s'agit d'un serveur express régulier, il n'y a rien d'intéressant ici. L'extension mjs est nécessaire pour les modules ES dans node.js. Par souci de cohérence, nous utiliserons cette extension pour le client.
Client
public / index.html
<!DOCTYPE html> <html lang="en"> <head> ... <script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script> <script src="/main.mjs" type="module"></script> </head> <body> ... <ul id="users"> <li v-for="user in users"> {{ user.name }} ({{user.id}}) </li> </ul> <div id="messages"> <div> <input type="text" v-model="msg" /> <button v-on:click="sendMessage()"></button> </div> <ul> <li v-for="message in messages">[{{ message.date }}] <strong>{{ message.text }}</strong></li> </ul> </div> </body> </html>
Par exemple, j'utilise Vue sur le client, mais cela ne change pas l'essence. Au lieu de Vue, il peut y avoir n'importe quoi où vous pouvez séparer le modèle de données dans une classe distincte (knockout, angular).
public / main.mjs
main.mjs est un script qui associe les modèles de données aux vues correspondantes. Pour simplifier le code, des exemples de représentations pour la liste des utilisateurs actifs et les flux de messages sont intégrés directement dans index.html
Modèle de données
partagé / messages / model / dataModel.mjs
Ces différentes méthodes implémentent toutes les fonctionnalités d'envoi et de réception de messages en temps réel. Les directives! #Client et! #Server indiquent au processus d'observation quelle méthode pour quelle partie (client ou serveur) est destinée. S'il n'y a pas ces directives avant de définir une méthode, une telle méthode est disponible à la fois sur le client et sur le serveur. Les barres obliques de commentaire avant la directive sont facultatives et n'existent que pour empêcher l'IDE standard de jurer lors d'erreurs de syntaxe.
La première ligne du chemin utilise la recherche & root. Lors de la génération des versions client et serveur, & root sera remplacé par le chemin relatif vers les répertoires public et protégé, respectivement.
Autre point important: à partir de la méthode client, vous ne pouvez appeler que la méthode serveur, dont le nom commence par "$":
...
Cela se fait pour des raisons de sécurité: de l'extérieur, vous ne pouvez vous tourner que vers des méthodes spécialement conçues pour cela.
Examinons les versions des modèles de données que l'observateur a générés pour le client et le serveur.
Client (public / partagé / messages / modèle / dataModel.mjs)
import Base from '/lib/Base.mjs'; export default class dataModel extends Base { __getFilePath__() {return "messages/model/dataModel.mjs"}
Côté client, le modèle est un descendant de la classe Vue (via Base.mjs). Ainsi, vous pouvez travailler avec lui comme avec un modèle de données Vue standard. L'observateur a ajouté la méthode __getFilePath__ à la version client du modèle, qui renvoie le chemin d'accès au fichier de classe et remplace le code de méthode du serveur $ sendMessage par une construction qui, par essence, appellera la méthode dont nous avons besoin sur le serveur via le mécanisme rpc (__runSharedFunction est défini dans la classe parente).
Serveur (protégé / partagé / messages / modèle / dataModel.mjs)
import Base from '../../lib/Base.mjs'; export default class dataModel extends Base { __getFilePath__() {return "messages/model/dataModel.mjs"} ... ...
Dans la version serveur, la méthode __getFilePath__ a également été ajoutée et les méthodes client marquées avec la directive ont été supprimées! #Client
Dans les deux versions générées du modèle, toutes les lignes supprimées sont remplacées par des lignes vides. Ceci est fait pour que le message d'erreur sur le débogueur puisse facilement trouver la ligne problématique dans le code source du modèle.
Interaction client-serveur
Lorsque nous devons appeler une méthode serveur sur le client, nous le faisons simplement.
Si l'appel est dans le même modèle, alors tout est simple:
... !#client async sendMessage(e) { await this.$sendMessage(this.msg); this.msg = ''; } !#server async $sendMessage(msg) {
Vous pouvez «tirer» un autre modèle:
import dataModel from "/shared/messages/model/dataModel.mjs"; var msg = new dataModel(); msg.$sendMessage('blah-blah-blah');
Dans la direction opposée, c'est-à-dire L'appel d'une méthode client sur le serveur ne fonctionne pas. Techniquement, c'est faisable, mais d'un point de vue pratique, cela n'a aucun sens, car le serveur est un, mais il y a beaucoup de clients. Si nous devons lancer certaines actions sur le serveur sur le client, nous utilisons le mécanisme d'événement:
La méthode fireEvent prend 3 paramètres: le nom de l'événement, à qui il est adressé et les données. Vous pouvez définir le destinataire de plusieurs manières: mot-clé «tous» - l'événement sera envoyé à tous les utilisateurs ou dans le tableau pour répertorier les jetons de session des clients auxquels l'événement est adressé.
L'événement n'est pas lié à une instance spécifique de la classe de modèle de données et les gestionnaires se déclencheront dans toutes les instances de la classe dans laquelle fireEvent a été appelé.
Mise à l'échelle horizontale du backend
La monolithicité des modèles client-serveur dans l'implémentation proposée, à première vue, devrait imposer des restrictions importantes sur la possibilité d'une mise à l'échelle horizontale de la partie serveur. Mais ce n'est pas le cas: techniquement, le serveur est indépendant du client. Vous pouvez copier le répertoire «public» n'importe où et donner son contenu via n'importe quel autre serveur Web (nginx, apache, etc.).
Le côté serveur peut être facilement étendu en lançant de nouvelles instances backend. Redis et le système de file d'attente Kue sont utilisés pour interagir avec des instances individuelles.
API et différents clients sur un seul backend
Dans les projets réels, divers clients serveurs peuvent utiliser une API serveur - sites Web, applications mobiles, services tiers. Dans la solution proposée, tout cela est disponible sans aucune danse supplémentaire. Sous le capot des méthodes de serveur d'appel se trouve le bon vieux rpc. Le serveur Web lui-même est une application express classique. Il suffit d'y ajouter un wrapper pour les routes avec appel des méthodes nécessaires des mêmes modèles de données.
Post scriptum
L'approche proposée dans l'article ne prétend aucun changement révolutionnaire dans les applications client-serveur. Il ajoute seulement un peu de confort au processus de développement, vous permettant de vous concentrer sur une logique métier assemblée en un seul endroit.
Ce projet est expérimental, écrivez dans les commentaires si, à votre avis, cela vaut la peine de poursuivre cette expérience.