Salut Je m'appelle Dima et je suis en Python depuis un certain temps maintenant. Aujourd'hui, je veux vous montrer les différences entre deux cadres asynchrones - Tornado et Aiohttp. Je vais raconter l'histoire du choix entre les cadres de notre projet, en quoi les coroutines de Tornado et d'AsyncIO diffèrent, je vais montrer des repères et donner quelques conseils utiles sur la façon d'entrer dans la nature des cadres et d'en sortir avec succès.

Comme vous le savez, Avito est un service publicitaire assez important. Nous avons beaucoup de données et de charge, 35 millions d'utilisateurs chaque mois et 45 millions d'annonces actives par jour. Je travaille en tant que conseiller technique d'un groupe d'élaboration de recommandations. Mon équipe écrit des microservices, nous en avons maintenant une vingtaine. Une charge s'accumule sur tout cela - comme 5k RPS.
Choisir un cadre asynchrone
Je vais d'abord vous dire comment nous en sommes arrivés là où nous en sommes maintenant. En 2015, nous devions choisir un framework asynchrone, car nous savions:
- que vous devez faire beaucoup de demandes à d'autres microservices: http, json, rpc;
- dont vous aurez besoin de collecter des données de différentes sources tout le temps: Redis, Postgres, MongoDB.
Ainsi, nous avons beaucoup de tâches réseau, et l'application est principalement occupée par les entrées / sorties. La version actuelle de python à cette époque était la 3.4, async et wait n'apparaissaient pas encore. Aiohttp était également - dans la version 0.x. Facebook Asynchronous Tornado est apparu en 2010. Un grand nombre de pilotes de base de données sont écrits pour lui dont nous avons besoin. Tornado a montré des résultats stables sur les benchmarks. Ensuite, nous avons arrêté notre choix sur ce cadre.
Trois ans plus tard, nous avons beaucoup compris.
Tout d'abord, Python 3.5 est sorti avec des mécanismes asynchrones / attendent. Nous avons compris quelle est la différence entre le rendement et le rendement et comment Tornado est compatible avec l'attente (spoiler: pas très bon).
Deuxièmement, nous avons rencontré d'étranges problèmes de performances avec une grande quantité de coroutine dans le planificateur, même lorsque le processeur n'est pas complètement occupé.
Troisièmement, nous avons constaté que lors de l'exécution d'un grand nombre de demandes http vers d'autres services Tornado, vous devez être particulièrement amical avec le résolveur DNS asynchrone, il ne respecte pas les délais d'expiration pour établir une connexion et envoyer la demande que nous spécifions. Et en général, la meilleure méthode pour faire des requêtes http dans Tornado est curl, ce qui est plutôt étrange en soi.
Dans son
discours à PyCon Russie 2018, Andrei Svetlov a déclaré: «Si vous voulez écrire une sorte d'application Web asynchrone, veuillez simplement écrire asynchrone, attendez. Boucle d'événement, probablement, vous n'en aurez pas besoin du tout bientôt. N'entrez pas dans la nature des frameworks pour ne pas vous perdre. N'utilisez pas de primitives de bas niveau et tout ira bien pour vous ... ". Au cours des trois dernières années, malheureusement, nous avons dû monter assez souvent à l'intérieur de Tornado, apprendre beaucoup de choses intéressantes à partir de là et voir de gigantesques plateaux pour 30 à 40 appels.
Rendement vs rendement de
L'un des plus gros problèmes à comprendre en python asynchrone est la différence entre le rendement et le rendement.
Guido Van Rossum a écrit plus à ce sujet. Je joins la traduction avec de légères abréviations.
On m'a demandé à plusieurs reprises pourquoi PEP 3156 insiste pour utiliser yield-from au lieu de yield, ce qui exclut la possibilité de rétroportage en Python 3.2 ou même 2.7.
(...)
chaque fois que vous voulez un résultat futur, vous utilisez le rendement.
Ceci est implémenté comme suit. La fonction contenant yield est (évidemment) un générateur, donc il doit y avoir une sorte de code itératif. Appelons-le un planificateur. En fait, l'ordonnanceur n'itère pas au sens classique (avec for-loop); au lieu de cela, il prend en charge deux futures collections.
J'appellerai la première collection une séquence "exécutable". Tel est l'avenir, dont les résultats sont disponibles. Bien que cette liste ne soit pas vide, le planificateur sélectionne un élément et effectue une étape d'itération. Cette étape appelle la méthode du générateur .send () avec le résultat du futur (qui peut être des données qui viennent d'être lues depuis le socket); dans le générateur, ce résultat apparaît comme la valeur de retour de l'expression de rendement. Lorsque send () renvoie un résultat ou se termine, le planificateur analyse le résultat (qui peut être StopIteration, une autre exception ou une sorte d'objet).
(Si vous êtes confus, vous devriez probablement lire sur le fonctionnement des générateurs, en particulier la méthode .send (). Peut-être que PEP 342 est un bon point de départ).
(...)
la deuxième future collection prise en charge par le planificateur est constituée du futur, qui attend toujours des E / S. Ils sont en quelque sorte transmis à select / poll / shell, etc. qui donne un rappel lorsque le descripteur de fichier est prêt pour les E / S. Le rappel effectue en fait l'opération d'E / S demandée par future, définit la valeur future résultante sur le résultat de l'opération d'E / S et déplace le futur vers la file d'attente d'exécution.
(...)
Maintenant, nous avons atteint le plus intéressant. Supposons que vous écrivez un protocole complexe. Dans votre protocole, vous lisez des octets à partir d'un socket en utilisant la méthode recv (). Ces octets parviennent au tampon. La méthode recv () est enveloppée dans un shell asynchrone, qui définit les E / S et renvoie l'avenir, qui est exécuté lorsque les E / S sont terminées, comme je l'ai expliqué ci-dessus. Supposons maintenant qu'une autre partie de votre code veuille lire les données du tampon une ligne à la fois. Supposons que vous ayez utilisé la méthode readline (). Si la taille du tampon est supérieure à la longueur de ligne moyenne, votre méthode readline () peut simplement obtenir la ligne suivante du tampon sans bloquer; mais parfois le tampon ne contient pas une ligne entière, et readline () appelle à son tour recv () sur le socket.
Question: readline () devrait-il retourner dans le futur ou non? Ce ne serait pas très bien s'il renvoyait parfois une chaîne d'octets, et parfois futur, forçant l'appelant à effectuer une vérification de type et un rendement conditionnel. Donc, la réponse est que readline () devrait toujours retourner à l'avenir. Lorsque readline () est appelé, il vérifie le tampon et s'il y trouve au moins une ligne entière, il crée un futur, définit le résultat futur d'une ligne prise dans le tampon et retourne futur. Si le tampon n'a pas de ligne entière, il lance les E / S et les attend, et lorsque les E / S sont terminées, il recommence.
(...)
Mais maintenant, nous créons de nombreux futurs qui ne nécessitent pas de blocage des E / S, mais qui forcent toujours un appel au planificateur, car readline () renvoie l'avenir, le rendement est requis de l'appelant, ce qui signifie un appel au planificateur.
Le planificateur peut transférer le contrôle directement à la coroutine s'il voit que le futur, qui est déjà terminé, est affiché, ou peut retourner le futur à la file d'attente d'exécution. Ce dernier ralentira considérablement le travail (à condition qu'il y ait plus d'une coroutine exécutable), car non seulement l'attente à la fin de la file d'attente est requise, mais la localité de la mémoire (si elle existe) est probablement également perdue.
(...)
L'effet net de tout cela est que les auteurs de coroutine doivent connaître l'avenir de rendement, et donc il y a une plus grande barrière psychologique à la réorganisation du code complexe en coroutines plus lisibles - beaucoup plus forte que la résistance existante, car les appels de fonction en Python sont assez lents. Et je me souviens d'une conversation avec Glyph que la vitesse est importante dans une structure d'E / S asynchrone typique.
Comparons maintenant cela avec le rendement de.
(...)
Vous avez peut-être entendu dire que «rendement de S» est à peu près équivalent à «pour i dans S: rendement i». Dans le cas le plus simple, c'est vrai, mais cela ne suffit pas pour comprendre la coroutine. Tenez compte des éléments suivants (ne pensez pas encore aux E / S asynchrones):
def driver(g): print(next(g)) g.send(42) def gen1(): val = yield 'okay' print(val) driver(gen1())
Ce code imprime deux lignes contenant «okay» et «42» (puis produit une StopIteration non gérée, que vous pouvez supprimer en ajoutant du rendement à la fin de gen1). Vous pouvez voir ce code en action sur pythontutor.com sur le lien .
Considérez maintenant ce qui suit:
def gen2(): yield from gen1() driver(gen2())
Cela fonctionne exactement de la même manière . Maintenant, réfléchis. Comment ça marche? L'extension yield-from simple dans la boucle for ne peut pas être utilisée ici, car dans ce cas, le code retournerait None. (Essayez-le) . Yield-from agit comme un "canal transparent" entre le pilote et gen1. Autrement dit, lorsque gen1 donne la valeur «okay», il laisse gen2, via yield-from, au pilote, et lorsque le pilote renvoie 42 à gen2, cette valeur est renvoyée via yield-from à gen1 (où elle devient le résultat du rendement )
La même chose se produirait si le conducteur jetait une erreur dans le générateur: l'erreur passe par le rendement du générateur interne qui la traite. Par exemple:
def throwing_driver(g): print(next(g)) g.throw(RuntimeError('booh')) def gen1(): try: val = yield 'okay' except RuntimeError as exc: print(exc) else: print(val) yield throwing_driver(gen1())
Le code donnera "okay" et "bah", ainsi que le code suivant:
def gen2(): yield from gen1()
(Voir ici: goo.gl/8tnjk )
Maintenant, j'aimerais introduire des graphiques simples (ASCII) afin de pouvoir parler de ce type de code. J'utilise [f1 -> f2 -> ... -> fN) pour représenter la pile avec f1 en bas (trame d'appel la plus ancienne) et fN en haut (trame d'appel la plus récente), où chaque élément de la liste est un générateur, et -> sont des rendements de . Le premier exemple, le pilote (gen1 ()) n'a pas de rendement, mais il a un générateur gen1, il ressemble donc à ceci:
[ gen1 )
Dans le deuxième exemple, gen2 appelle gen1 en utilisant yield-from, il ressemble donc à ceci:
[ gen2 -> gen1 )
J'utilise la notation mathématique de l'intervalle semi-ouvert [...] pour montrer qu'une autre trame peut être ajoutée à droite lorsque le générateur le plus à droite utilise yield-from pour appeler un autre générateur, tandis que l'extrémité gauche est plus ou moins fixe. La fin gauche correspond à ce que voit le pilote (c'est-à-dire le planificateur).
Je suis maintenant prêt à revenir à l'exemple readline (). Nous pouvons réécrire readline () comme un générateur qui appelle read (), un autre générateur utilisant yield-from; ce dernier, à son tour, appelle recv (), qui fait les entrées / sorties réelles de la socket. À notre gauche se trouve l'application, que nous considérons également comme un générateur qui appelle readline (), utilisant à nouveau le rendement de. Le schéma est le suivant:
[ app -> readline -> read -> recv )
Maintenant, le générateur recv () définit les E / S, les lie au futur et les transmet au planificateur en utilisant * yield * (et non yield-from!). future va vers la gauche le long des deux flèches de rendement de l'ordonnanceur (situées à gauche de "["). Notez que l'ordonnanceur ne sait pas qu'il contient une pile de générateurs; tout ce qu'il sait, c'est qu'il contient le générateur le plus à gauche et qu'il vient d'émettre un avenir. Lorsque les E / S sont terminées, le planificateur définit le résultat futur et le renvoie au générateur; le résultat se déplace vers la droite le long des deux flèches de départ vers le générateur recv, qui reçoit les octets qu'il voulait lire depuis le socket comme résultat de rendement.
En d'autres termes, le planificateur de cadre de rendement à partir de gère les opérations d'E / S tout comme le planificateur de cadre basé sur le rendement que j'ai décrit précédemment. * Mais: * il n'a pas à se soucier de l'optimisation lorsque le futur est déjà exécuté, puisque l'ordonnanceur ne participe pas au transfert de contrôle entre readline () et read () ou entre read () et recv (), et vice versa. Par conséquent, le planificateur ne participe pas du tout lorsque app () appelle readline () et readline () peut satisfaire la demande du tampon (sans appeler read ()) - l'interaction entre app () et readline () dans ce cas est complètement traitée par l'interpréteur de bytecode Python L'ordonnanceur peut être plus simple et le nombre de futurs créés et gérés par l'ordonnanceur est moindre, car il n'y a pas de futurs créés et détruits à chaque appel de coroutine. Les seuls futurs qui restent nécessaires sont ceux qui représentent les E / S réelles, par exemple, créées par recv ().
Si vous avez lu jusqu'à ce point, vous méritez une récompense. J'ai omis de nombreux détails d'implémentation, mais l'illustration ci-dessus reflète essentiellement correctement l'image.
Je voudrais également souligner une autre chose. * Vous pouvez * faire une partie du code utiliser yield-from, et l'autre partie utiliser yield. Mais le rendement exige que chaque maillon de la chaîne ait un avenir, pas seulement une coroutine. Puisqu'il y a plusieurs avantages à utiliser le rendement de, je veux que l'utilisateur n'ait pas à se rappeler quand utiliser le rendement, et quand le rendement de, il est plus facile de toujours utiliser le rendement de. Une solution simple permet même à recv () d'utiliser le rendement de pour transmettre les futures E / S au planificateur: la méthode __iter__ est en fait le générateur que le futur émet.
(...)
Et encore une chose. Quelle valeur le rendement de retour? Il s'avère que c'est la valeur de retour du générateur * externe *.
(...)
Ainsi, bien que les flèches lient les cadres gauche et droit à la cible * de rendement *, elles transmettent également les valeurs de retour habituelles de la manière habituelle, une image de pile à la fois. Les exceptions sont déplacées de la même manière; bien sûr, à chaque niveau, essayez / except est nécessaire pour les attraper.
Il s'avère que le rendement est à peu près le même que celui attendu.
rendement de vs async
def coro () ^ y = rendement d'un | async def async_coro (): y = attendre un |
| 0 load_global | 0 load_global |
| 2 get_yield_from_iter | 2 get_awaitable |
| 4 load_const | 4 load_const |
| 6 yield_from | 6 yield_from |
| 8 store_fast | 8 store_fast |
| 10 load_const | 10 load_const
|
| 12 return_value | 12 return_value |
Les deux coroutines de l'ancienne et de la nouvelle école n'ont qu'une seule différence mineure: obtenir un rendement de iter vs get attendable.
Pourquoi tout cela? La tornade utilise un rendement simple. Avant la version 5, il connecte toute cette chaîne d'appels via le rendement, ce qui est peu compatible avec le nouveau paradigme cool yield from / wait.
La référence asynchrone la plus simple
Il est difficile de trouver un très bon framework, en le choisissant uniquement selon des tests synthétiques. Dans la vraie vie, beaucoup de choses peuvent mal tourner.
J'ai pris Aiohttp version 3.4.4, Tornado 5.1.1, uvloop 0.11, pris le processeur serveur Intel Xeon, CPU E5 v4, 3,6 GHz, et avec Python 3.6.5, j'ai commencé à vérifier la compétitivité des serveurs Web.
Le problème typique que nous résolvons à l'aide de microservices, et qui fonctionne en mode asynchrone, ressemble à ceci. Nous recevrons des demandes. Pour chacun d'eux, nous ferons une demande à un microservice, obtiendrons des données à partir de là, puis irons à deux ou trois microservices, également de manière asynchrone, puis écrireons les données quelque part dans la base de données et retournerons le résultat. Il s'avère que de nombreux points nous attendent.
Nous effectuons une opération plus simple. Nous allumons le serveur, le faisons dormir 50 ms. Créez une coroutine et complétez-la. Nous n'aurons pas un très grand RPS (ce n'est peut-être pas un ordre de grandeur similaire à ce qui est vu dans les benchmarks entièrement synthétiques) avec un délai acceptable en raison du fait que beaucoup de coroutine tourneront simultanément sur un serveur compétitif.
@tornado.gen.coroutine def old_school_work(): yield tornado.gen.sleep(SLEEP_TIME) async def work(): await tornado.gen.sleep(SLEEP_TIME)
Charger - GET requêtes HTTP. Durée - 300s, 1s - échauffement, 5 répétitions de la charge.
 Résultats sur les centiles du temps de réponse du service.
Résultats sur les centiles du temps de réponse du service.Que sont les centiles?Vous avez un grand nombre de numéros. Le 95e centile X signifie que 95% des valeurs de cet échantillon sont inférieures à X. Avec une probabilité de 5%, votre nombre sera supérieur à X.
Nous voyons que Aiohttp a fait du bon travail à 1000 RPS sur un test aussi simple. Jusqu'à présent, sans
uvloop .
Comparez Tornado avec les coroutines des anciennes écoles (rendement) et nouvelles (asynchrones). Les auteurs recommandent fortement d'utiliser async. Nous pouvons nous assurer qu'ils sont vraiment beaucoup plus rapides.
À 1200 RPS, Tornado, même avec les nouvelles coroutines scolaires, commence déjà à abandonner, et Tornado avec les anciennes coroutines scolaires est complètement emporté. Si nous dormons pendant 50 ms et que le microservice est responsable de 80 ms, cela n'entre dans aucune porte.
La nouvelle école de Tornado à 1 500 RPS a complètement abandonné, tandis que Aiohttp est encore loin de la limite de 3 000 RPS. Le plus intéressant reste à venir.
Pyflame, profilant un microservice fonctionnel
Voyons ce qui se passe en ce moment avec le processeur.

Lorsque nous avons compris comment les microservices asynchrones Python fonctionnent en production, nous avons essayé de comprendre dans quoi tout cela s'est heurté. Dans la plupart des cas, le problème venait du processeur ou des descripteurs. Il existe un excellent outil de profilage créé dans Uber, le profileur
Pyflame , qui est basé sur l'appel système ptrace.
Nous commençons un service dans le conteneur et commençons à lancer une charge de combat dessus. Souvent, ce n'est pas une tâche très triviale - pour créer exactement une telle charge qui est au combat, car il arrive souvent que vous exécutiez des tests synthétiques sur les tests de charge, l'apparence et tout fonctionne bien. Vous poussez la charge de combat sur lui, et ici le microservice commence à émousser.
Pendant le fonctionnement, ce profileur fait pour nous des instantanés de la pile d'appels. Vous ne pouvez pas changer le service du tout, lancez pyflame à proximité. Il collectera une trace de pile une fois dans une certaine période de temps, puis effectuera une visualisation cool. Ce profileur donne très peu de frais généraux, en particulier par rapport à cProfile. Pyflame prend également en charge les programmes multithread. Nous avons lancé cette chose directement dans la prod, et les performances ne se sont pas beaucoup dégradées.
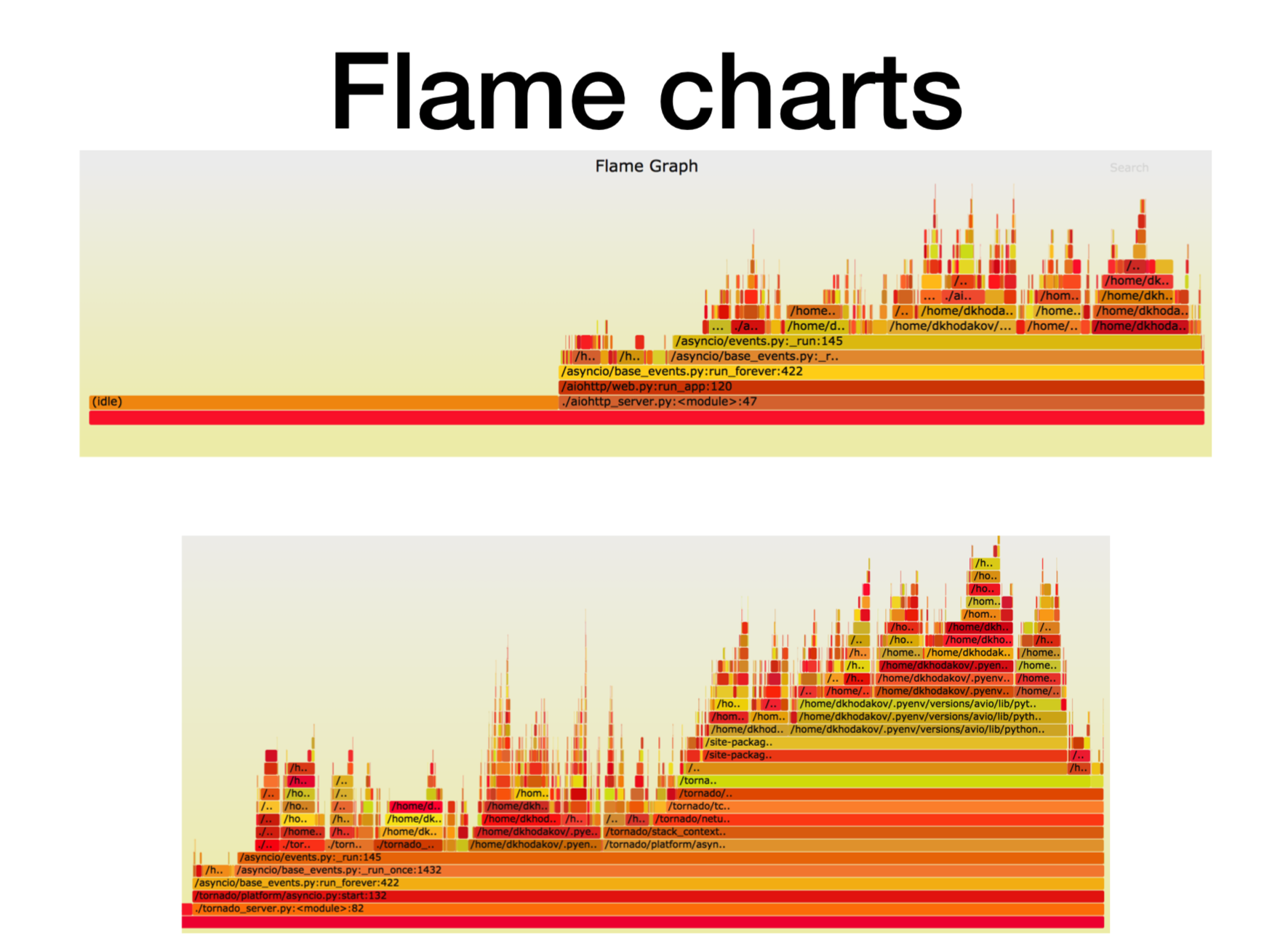
Ici, l'axe X est la quantité de temps, le nombre d'appels, lorsque le cadre de pile était sur la liste de tous les cadres de pile Python. Il s'agit du temps approximatif du processeur que nous avons passé dans ce cadre particulier de la pile.
Comme vous pouvez le voir, ici la plupart du temps dans aiohttp passe au ralenti. Très bien: c'est ce que nous voulons d'un service asynchrone pour qu'il traite la plupart du temps les appels réseau. La profondeur de la pile dans ce cas est d'environ 15 images.
Dans Tornado (deuxième image) avec la même charge, beaucoup moins de temps est consacré au repos et la profondeur de pile dans ce cas est d'environ 30 images.
Voici un
lien vers svg , vous pouvez vous tordre.
Benchmark asynchrone plus complexe
async def work():
Attendez-vous à un temps d'exécution de 125 ms.

La tornade avec uvloop résiste mieux. Mais Aiohttp uvloop aide beaucoup plus. Aiohttp commence à mal se comporter sur 2300-2400 RPS, et avec uvloop, il étend considérablement la plage de charge. Une ligne d'importation, et maintenant vous avez un service beaucoup plus productif.
Résumé
Je vais résumer ce que je voulais vous transmettre aujourd'hui.
- Tout d'abord, j'ai lancé une certaine référence artificielle, où il y avait une bonne quantité de coroutine longue. Dans notre test, Aiohttp a fait mieux 2,5 fois que Tornado.
- Le deuxième fait. Uvloop aide très bien à améliorer les performances d'Aiohttp (mieux que Tornado).
- Je vous ai parlé de Pyflame, avec lequel nous profilons souvent l'application directement en production.
- Et nous avons également parlé du rendement de (attendre) par rapport au rendement.
À la suite de ces benchmarks, notre équipe de recommandations (et quelques autres) est presque complètement passée à Aiohttp avec Tornado pour les microservices en Python en production.
- Pour les services de combat, la consommation du processeur a diminué de plus de 2 fois.
- Nous avons commencé à respecter les délais d'expiration des requêtes http.
- Les services de latence ont chuté de 2 à 5 fois.
Voici un
lien vers le benchmark . Si vous êtes intéressé, vous pouvez le répéter. Merci à tous pour votre attention. Posez des questions, je vais essayer d'y répondre.