Mes amis, fin janvier, nous commencerons un nouveau cours intitulé «MS SQL Server Developer ». En prévision de son lancement, nous avons demandé à l'enseignante du cours, Kristina Kucherova , de préparer un article d'auteur. Cet article vous sera utile si vous avez une table très populaire sur la prod avec un accès 24h / 24 et 7j / 7 et que vous vous rendez compte que vous devez de toute urgence ajouter un index et ne rien casser dans le processus.Alors que faire? La méthode traditionnelle CREATE INDEX WITH (ONLINE = ON) ne vous convient pas, car, par exemple, elle provoque un crash système et une crise cardiaque de votre DBA, tous les sommets surveillent de près le temps de réponse de votre système et, si elle augmente, ils viennent à vous et à votre DBA pour parler concernant les chiffres surestimés de votre rémunération du travail.
Les scripts et les techniques décrites ont été utilisés sur un système avec une charge de 400 000 requêtes par minute, versions de SQL Server 2012 et 2016 (Enterprise).
Il existe deux approches très différentes pour créer un index, qui sont utilisées en fonction de la taille de la table.
Cas n ° 1. Une petite table mais très populaire
Un tableau de 50 000 enregistrements (petit), mais très populaire (plusieurs milliers de hits par minute). Vous avez besoin d'un nouvel index, d'un temps d'arrêt minimal et de verrous sur la table.
Dans l'application, tout accès à la base de données se fait uniquement par le biais de procédures.
Si une erreur se produit, l'application réessayera d'accéder à la table.

Quel est le problème de l'application de cet indice simplement, demandez-vous? Avec la phrase WITH ONLINE = ON (oui, nous avons eu de la chance, et celle-ci était Enterprise).
Le fait est qu'avec un tel accès actif, il faut un certain temps pour obtenir un verrou (même le minimum requis avec l'option with Online = ON). En cours d'attente, de nouvelles demandes sont mises en file d'attente, la file d'attente s'accumule, le processeur augmente, le DBA transpire et plisse nerveusement vers les développeurs, tandis que sur les graphiques de surveillance des applications, votre temps de réponse commence à augmenter en douceur, mais inévitablement. Votre vice-président de l'ingénierie souhaite vivement savoir si, en raison de cette augmentation du temps de réponse, il y aura une sorte d'arrêt du système, qu'à la fin de l'année, la disponibilité de l'application sera estimée non pas à 5 neuf (99 999), mais moins? Et puis l'entreprise a des contrats, des obligations et de lourdes amendes en cas de disponibilité réduite, et, bien sûr, nous n'oublierons pas les pertes de réputation.
Qu'avons-nous fait pour éviter cette situation malheureuse?
Le système a toujours besoin d'un index.
Ils ont pris les droits de tout le monde sauf la session en cours sur cette table.
Appliquez l'index.
Oui, la solution a un inconvénient: tous ceux qui se sont tournés vers la table dans ces secondes recevront un accès refusé. Si votre application gère normalement une telle situation et répète la requête dans la base de données, vous devez alors examiner cette option. Dans le cas de notre projet, cette méthode a bien fonctionné. Encore une fois, vous pouvez supprimer ONLINE = ON en toute sécurité, car nous savons que seule la session aura accès à la table lors de la création de l'index.
Code d'application de l'index:
REVOKE EXECUTE ON [dbo].[spUserLogin] TO [User1] REVOKE EXECUTE ON [dbo].[spUserLogin] TO [User2] REVOKE EXECUTE ON [dbo].[spUserCreate] TO [User1] REVOKE EXECUTE ON [dbo].[spUserCreate] TO [User2] CREATE NONCLUSTERED INDEX IX_Users_Email_Status ON [dbo].[Users] ([Email],[Status]); GRANT EXECUTE ON [dbo].[spUserCreate] TO [User1] GRANT EXECUTE ON [dbo].[spUserCreate] TO [User2] GRANT EXECUTE ON [dbo].[spUserLogin] TO [User1] GRANT EXECUTE ON [dbo].[spUserLogin] TO [User2]
Calendrier du temps de réponse et pourcentage d'erreurs lors des tests sous charge.
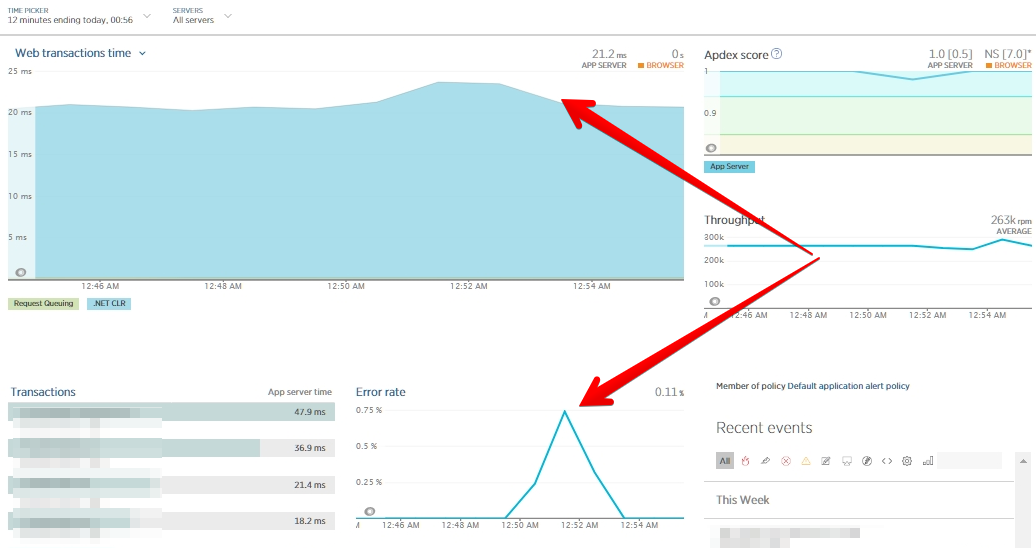
La méthode peut être appliquée si vous, comme dans le cas décrit, avez une petite table et que vous savez que sans charge, l'index sera créé en quelques secondes (ou dans un délai acceptable pour vous). Dans le même temps, comme vous pouvez le voir sur le graphique ci-dessus, le temps de réponse de l'application n'augmentera pas, bien que l'on puisse voir que le taux d'erreur en secondes sans accès au tableau était plus élevé.
Cas n ° 2. Grande table
Si vous avez une grande table et que vous devez modifier les index dessus, alors le moyen le plus indolore de vendre est de créer une table à côté avec l'index correct et de transférer progressivement les données vers une nouvelle table.
Il y a 2 façons:
- Si vous avez une procédure spéciale pour modifier une table, vous changez simplement le code de la procédure afin que les nouvelles données soient insérées uniquement dans la nouvelle table, la suppression provient des deux, la mise à jour a également été appliquée aux deux, et la sélection a été effectuée à partir de deux tables avec UNION ALL.
- Si vous avez de nombreuses parties différentes du code où vous pouvez modifier les données dans la table, il existe deux astuces populaires: afficher avec des déclencheurs ou réécrire toutes les parties du code pour insérer des données dans une nouvelle table, supprimer des deux et mettre à jour les deux tables. Une vue avec des déclencheurs est une option lorsque vous créez une vue avec deux tables et la renommez, renommez votre table actuelle en TableOld et affichez en Table. Ensuite, vous obtenez automatiquement tous les appels de table à la vue, ici avec renommer, il peut également y avoir un problème, car SchemaLock est nécessaire, mais renommer passe très rapidement.
Une version légèrement plus détaillée sur la réécriture des appels vers une nouvelle table:
- Vous avez la table Orders, créez une nouvelle table OrdersNew avec le même schéma, mais avec l'index souhaité. Dans le même temps, si vous utilisez Indentity, vous devez définir la première valeur d'identité dans la nouvelle table pour qu'elle soit égale à la valeur maximale dans l'ancienne table + l'étape de modification ou l'écart que vous pouvez vous permettre de dévier de la valeur maximale dans Orders.
- Créer un OrdersView, dans lequel une sélection de Orders UNION ALL OrdersNew
- Modifiez toutes les procédures / appels pour sélectionner les données de la vue, insérez-les dans OrdersNew, supprimez et modifiez les deux tables.
- Migrez les données de l'ancienne table vers la nouvelle, par exemple, comme ceci:
DECLARE @rowcount INT, @batchsize INT = 4999; SET IDENTITY_INSERT dbo.OrdersNew ON; SET @rowcount = @batchsize; WHILE @rowcount = @batchsize BEGIN BEGIN TRY DELETE TOP (@batchsize) FROM dbo.Orders OUTPUT deleted.Id ,deleted.Column1 ,deleted.Column2 ,deleted.Column3 INTO dbo.OrdersNew (Id ,Column1 ,Column2 ,Column3); SET @rowcount = @@ROWCOUNT; END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS ErrorNumber, ERROR_MESSAGE() AS ErrorMessage; THROW; END CATCH; END; SET IDENTITY_INSERT dbo.OrdersNew OFF;
- Retournez toutes les procédures à la version avant la migration - avec une seule table. Cela peut être fait via alter ou par la suppression et la création de procédures (puis n'oubliez pas les droits), et vous pouvez renommer la nouvelle table en commandes, en supprimant la table et la vue vides.
À l'étape 2, il était possible, si le chargement le permet, de renommer la table principale Orders -> OrdersOld et OrdersView -> Orders et la vue elle-même en OrdersOld UNION ALL OrdersNew, vous n'avez donc pas besoin de modifier tous les endroits où il y a une sélection dans la table.
Lorsque vous déplacez des blocs d'une table à une autre, les données sont fragmentées.
Si la table en cours de modification est activement utilisée pour la lecture, mais que les données qu'elle contient changent rarement, vous pouvez à nouveau utiliser des déclencheurs - écrire une copie de toutes les modifications dans la 3e table - transférer les données de la table via bcp out et bcp in (ou insertion en bloc) vers une nouvelle table , créez des index dessus après le transfert de données, puis appliquez les modifications de la table avec le journal des modifications - et basculez d'une table à une autre - l'actuelle, en la renommant TableOld et la nouvelle de TableNew en Table.
La probabilité d'erreurs dans cette situation est légèrement plus élevée, alors testez l'application des changements et des différents cas de commutation dans ce cas.
Les options décrites ne sont pas les seules. Ils ont été utilisés par moi sur une base de données SQL Server très chargée et n'ont pas causé de problèmes lors de l'application, ce qui a plu à notre équipe DBA. Un tel rebond n'est généralement pas nécessaire pour les bases avec un mode de charge plus calme, lorsque vous pouvez appliquer en toute sécurité des changements dans les heures de moindre activité. Les utilisateurs du projet qui ont utilisé les approches décrites se trouvent aux États-Unis et en Europe et utilisent activement l'application les jours de semaine et les week-ends, et les tableaux sur lesquels les modifications ont été appliquées sont constamment utilisés dans le travail. Des objets plus «silencieux» étaient généralement modifiés par des scripts automatiques générés via Redgate Toolkit après que les scripts aient été examinés par le développeur et l'un des administrateurs de base de données.
Bon à tous! Partagez les commentaires si vous avez utilisé l'une de ces méthodes ou décrivez votre méthode! Nous vous invitons également à une leçon ouverte et une journée portes ouvertes de notre nouveau cours "MS SQL Server Developer"