Dans un article précédent du HSE de Saint-Pétersbourg, nous avons montré comment l'apprentissage automatique peut rechercher des bogues dans le code du programme. Dans cet article, nous parlerons de la manière dont nous, avec JetBrains Research, essayons d'utiliser l'une des sections les plus intéressantes, modernes et à croissance rapide de l'apprentissage automatique - l'apprentissage par renforcement - à la fois dans des problèmes pratiques réels et dans des exemples de modèles.

À propos de moi
Je m'appelle Nikita Sazanovich. Jusqu'en juin 2018, j'ai étudié au SPbAU pendant trois ans, puis, avec mes autres camarades de classe, transféré au HSE de Saint-Pétersbourg, où je termine maintenant mes études de premier cycle. Récemment, je travaille également comme chercheur chez JetBrains Research. Avant d'entrer à l'université, j'aimais la programmation sportive et j'ai joué pour l'équipe nationale du Bélarus.
Formation de renforcement
L'apprentissage par renforcement est une branche de l'apprentissage automatique dans laquelle l'agent, en interaction avec l'environnement, reçoit un renforcement (d'où le nom) sous la forme d'une récompense positive ou négative. En fonction de ces invites, l'agent modifie son comportement. Le but ultime de ce processus est de recevoir la plus grande récompense possible, ou, d'une autre manière, de réaliser les actions que l'agent a définies.
Les agents opèrent selon des conditions et sélectionnent des actions. Par exemple, dans le problème de la sortie du labyrinthe, nos états seront les coordonnées x et y, et les actions seront haut / bas / gauche / droite. Le schéma général ressemble à ceci:
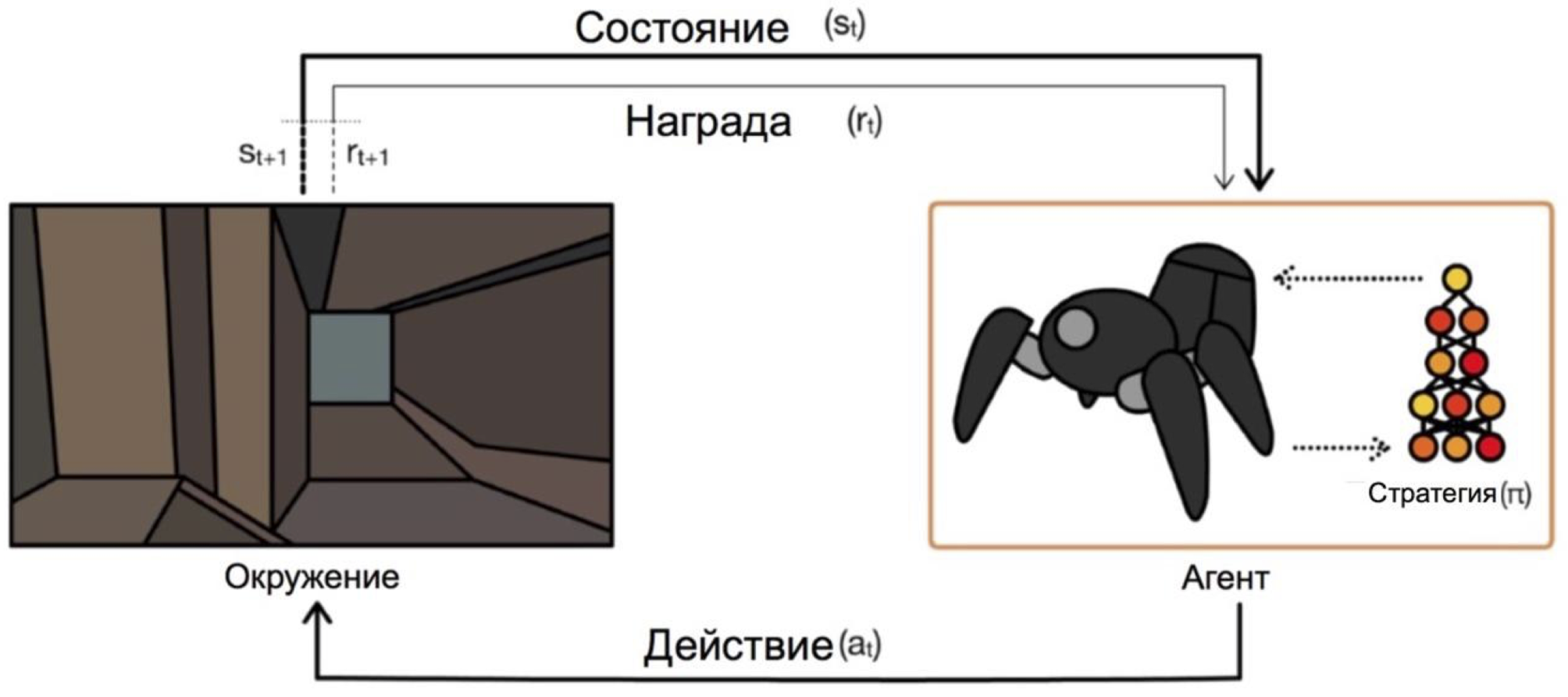
Le principal problème dans la transition des tâches fictives / simples (comme le même labyrinthe) aux tâches réelles / pratiques est le suivant: les récompenses dans de tels problèmes sont généralement très rares. Si nous voulons qu'un agent, par exemple, livre une pizza sur un plan de ville, alors il comprendra qu'il a bien fait quelque chose, seulement en livrant la commande à la porte, et cela ne se produira que si vous suivez une séquence d'actions longue et correcte.
Ce problème peut être résolu en donnant à l'agent au début des exemples de la façon de "jouer" - les soi-disant démonstrations d'experts.
Tâche d'apprentissage
Le problème de modèle qui sera discuté dans l'article est Dota 2.
Dota 2 est un jeu MOBA populaire dans lequel une équipe de cinq héros doit vaincre une équipe adverse en détruisant leur "forteresse". Dota 2 est considéré comme un jeu assez compliqué, il a des esports avec des prix dans le tournoi principal à 25000000 $ .
Vous pouviez entendre parler des récents succès d'OpenAI dans Dota 2. Ils ont d'abord créé un bot en tête-à-tête et battu des joueurs professionnels , puis ils sont passés à un jeu 5x5 et ont montré des résultats impressionnants cet été, bien qu'ils aient perdu contre des équipes professionnelles.

Le seul problème est qu'ils ont formé l'agent pour un jeu en tête-à-tête, selon eux , sur 60 000 CPU et 256 GPU K80 sur le cloud Azure. Ils ont bien sûr la possibilité de commander autant de pouvoir. Mais si vous avez moins de puissance, vous devez utiliser des astuces. L'une de ces astuces est l'utilisation de jeux déjà joués par des personnes.
Démos dans le jeu
Dans la plupart des cas, les démonstrations sont enregistrées artificiellement: vous terminez simplement une tâche / jouez à un jeu et collectez en quelque sorte les actions que vous avez prises. Vous collectez donc des données qui peuvent être intégrées à la formation de différentes manières. Jusqu'à présent, je l'ai fait, mais comment exactement - il sera clair après la partie sur le schéma d'interaction avec le client du jeu.
Un objectif plus large et plus aventureux est d'obtenir plus de données à partir d'un accès ouvert. L'une des raisons lors du choix de Dota 2 pour accélérer l'apprentissage était une ressource comme dotabuff . Il existe différentes statistiques sur le jeu, mais plus important encore, il existe des rediffusions complètes des jeux. Et ils peuvent être triés par note.
Jusqu'à présent, je n'ai pas essayé de savoir comment les gigaoctets de ces données aideront grandement par rapport à plusieurs épisodes. Réaliser la collecte de données était assez simple: vous obtenez des liens vers des jeux dotabuff, téléchargez des jeux et utilisez l'analyseur de jeu Dota 2 .
Bundle avec le client du jeu pour la formation
Nous avons un jeu Dota 2 dont le client existe sous les plates-formes Windows, Linux et macOS. Mais toujours, la formation se déroule généralement dans une sorte de script python, et vous y créez un environnement, que ce soit un labyrinthe, une machine à gravir une colline ou quelque chose comme ça. Mais il n'y a pas d'environnement pour Dota 2. Par conséquent, j'ai moi-même dû créer ce wrapper, ce qui était assez intéressant techniquement. Il s'est avéré le faire comme ceci:
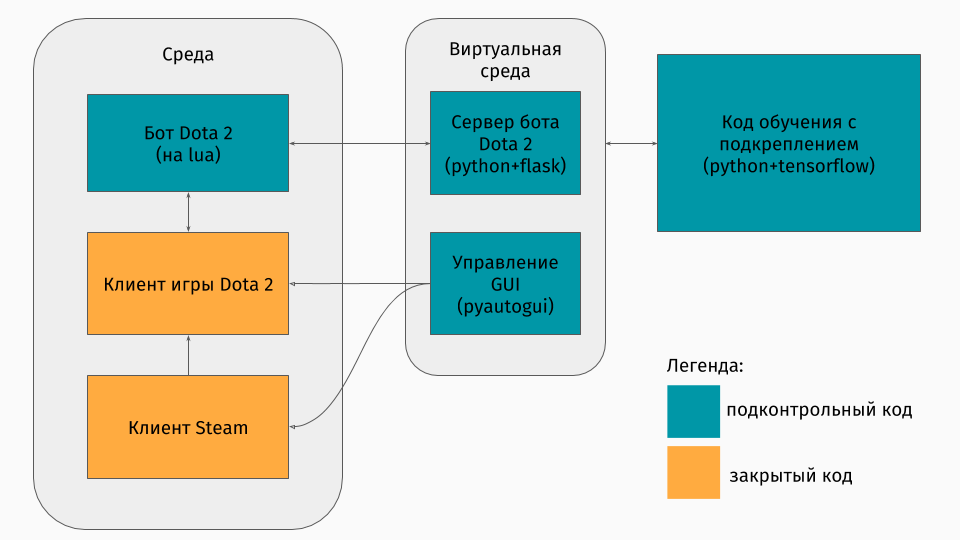
La première partie est un script pour communiquer avec le client du jeu. Heureusement, pour Dota 2, il existe une API officielle pour créer des bots: Dota Bot Scripting . Il est implémenté sous forme d'inserts dans le langage Lua, qui s'est avéré être populaire dans le développement de jeux. Le script du bot, en interaction avec le client du jeu, extrait au bon moment les informations qui nous intéressent (par exemple, les coordonnées sur la carte, les positions des adversaires) et envoie json avec lui au serveur.
La deuxième partie est le wrapper lui-même. Il est conçu comme un serveur qui traite toute la logique du lancement de Steam, Dota et de la réception de json à partir d'un script dans le jeu. La gestion du lancement des jeux et des clients est organisée via pyautogui , et la communication avec le lua-insert dans le jeu se fait via le serveur Flask.
La troisième partie comprend l'algorithme d'apprentissage lui-même. Cet algorithme sélectionne les actions, reçoit les états et récompenses suivants du serveur, derrière lequel toute communication avec le jeu est cachée, et améliore son comportement.
Apprendre des experts
L'algorithme lui-même n'est pas particulièrement important dans cet article, car ces techniques peuvent être utilisées avec n'importe quel algorithme. Nous avons utilisé DQN (que vous pouvez lire sur le hub ). Il s'agit essentiellement d'un réseau neuronal profond + d' un algorithme d' apprentissage Q. Oui, c'est exactement le DQN que DeepMind a créé pour jouer aux jeux Atari.
Il est également plus intéressant de parler de l'utilisation des jeux précédents. J'ai essayé deux approches: la mise en forme des récompenses basées sur le potentiel et les conseils d'action.
L'idée générale des approches est que l'agent recevra une récompense non seulement pour les objectifs de la tâche (par exemple, à la fin du labyrinthe ou pour l'ascension de la montagne), mais aussi lors de la formation à chaque étape. Cette récompense supplémentaire montrera à quel point l'agent travaille pour atteindre l'objectif final. Bien sûr, je voudrais lui demander automatiquement et ne pas sélectionner les règles / conditions. Les approches suivantes aident à atteindre cet objectif.
L'essence de la mise en forme des récompenses basées sur le potentiel est que certains états nous semblent initialement plus prometteurs que d'autres, et sur cette base, nous modifions les récompenses réelles que l'algorithme reçoit. Nous le faisons comme ceci: où - prix modifié, - la récompense est réelle, - facteur d'actualisation de l'algorithme d'apprentissage (pas très important pour nous), mais et il y a notre potentiel pour la condition que nous avons visitée pendant . Un exemple simple est de surmonter un labyrinthe.
Supposons qu'il y ait un labyrinthe dans lequel nous voulons passer de la cellule (0,0) à la cellule (5,5). Ensuite, notre potentiel pour l'état (x, y) peut être moins la distance euclidienne de (x, y) à notre cible (5.5): . Autrement dit, plus nous nous rapprochons de la ligne d'arrivée, plus le potentiel de l'État est élevé (par exemple, , , ) Nous motivons donc l'agent par tous les moyens pour atteindre l'objectif.
Pour Dota 2, l'idée est la même, mais les potentiels sont un peu plus compliqués:

Imaginez que nous voulons simplement passer par les mêmes états que le manifestant. Ensuite, plus nous passons d'états, plus le potentiel est élevé. Nous mettons le potentiel de l'État par le pourcentage d'achèvement de la rediffusion, s'il existe une condition proche de la nôtre. Cela a différentes significations dans diverses tâches. Mais c'est dans Dota 2 que cela signifie qu'au début, nous voulons que le bot atteigne le centre (après tout, au début des démonstrations, il n'y a que des marches vers le centre), puis l'état du joueur humain est conservé (excellente santé, distance de sécurité par rapport aux adversaires, etc. )
La deuxième méthode, action-conseil, est tirée de cet article . Son essence est que maintenant nous conseillons à l'agent non l'utilité des états, mais l'utilité des actions. Par exemple, dans notre jeu Dota 2, il peut y avoir de tels conseils: s'il y a un serviteur ennemi près de vous, alors attaquez-le; si vous n'avez pas atteint le centre, allez dans sa direction; si vous perdez des points de vie, retirez-vous dans votre tour. Et cet article décrit une méthode pour spécifier de tels conseils sans aucune pensée par le programmeur lui-même - automatiquement.
Les potentiels sont générés selon ce principe: potentiel d'action capable de
augmente en présence de conditions connexes avec le même
action dans les manifestations. Récompense supplémentaire pour l'action dans le diagramme ci-dessus
varie comme .
Il convient de noter ici que nous avons déjà défini des potentiels pour des actions dans les États.
Résultats
Pour commencer, je constate que l'objectif du jeu a été légèrement simplifié, car j'ai tout appris sur mon ordinateur portable. Le but de l'agent était d'infliger autant d'attaques que possible, ce qui semble être une véritable cible dans une certaine approximation. Pour ce faire, vous devez d'abord vous rendre au centre de la carte, puis attaquer les adversaires en essayant de ne pas mourir. Pour accélérer l'apprentissage, seules quelques (1 à 3) démonstrations de deux minutes ont été enregistrées par moi.
La formation d'un agent utilisant l'une des approches ne prend que 20 heures sur un ordinateur personnel (la plupart du temps, il faut pour rendre un jeu Dota 2), et à en juger par les graphiques OpenAI, la formation sur leurs serveurs prend plusieurs semaines.
Brève exposition du jeu lors de l'utilisation de l'approche de mise en forme des récompenses basée sur le potentiel:
Et pour l'approche conseil d'action:
Ces notes ont été prises à une vitesse d'entraînement de x10. Des inexactitudes dans le comportement de l’agent lors de son déplacement vers le centre sont encore visibles, mais la lutte au centre montre toujours les manœuvres apprises. Par exemple, se retirer en mauvaise santé.
Vous pouvez également voir les différences dans les approches: avec la mise en forme de la récompense basée sur le potentiel, l'agent se déplace en douceur, car «Passe par le potentiel»; avec des conseils d'action, le bot joue plus agressivement au centre, car il reçoit des indices sur l'attaque.
Résumé
Je note tout de suite que certains points ont été intentionnellement omis: quel algorithme était exactement, comment l'état était représenté, et s'il était possible de former un agent pour jouer avec de vrais joueurs, etc.
Tout d'abord, dans cet article, je voulais montrer que dans le cas d'une formation par renforcement, vous n'avez pas toujours besoin de choisir entre un environnement très simple (échapper au labyrinthe) ou un coût de formation très élevé (selon mes calculs superficiels, OpenAI a coûté ces serveurs pour la formation sur Azure 4715 $ par heure). Il existe des techniques qui peuvent accélérer l'apprentissage, et je n'en ai parlé que d'une seule - l'utilisation de démonstrations. Il est important de noter que de cette façon, vous ne vous contentez pas de répéter le démonstrateur, mais seulement de le «repousser». Il est important qu'avec une formation continue, l'agent ait la possibilité de dépasser les experts.
Si vous êtes intéressé par les détails, alors le code du processus de formation peut être trouvé sur GitHub .