Exemple de Wikibook (illustration d'un article scientifique )Tout le monde sait que Wikipedia est une précieuse ressource d'information. Vous pouvez passer des heures à étudier un sujet, passer d'un lien à un autre pour obtenir un contexte sur un sujet d'intérêt. Mais il n'est pas toujours évident de savoir comment collecter tout le contenu sur un même sujet commun. Par exemple, comment combiner tous les articles sur la chimie inorganique ou l'histoire du Moyen Âge, résumant les plus importants? À ce sujet, Shahar Admati et ses collègues de Ben-Gurion dans le Néguev (Israël), les développeurs du programme d'apprentissage automatique
Wikibook-Bot , ont essayé de le faire.
Wikipédia et le manuel sont deux choses différentes. C'est pourquoi le projet
Wikibooks a été créé, où les gens essaient conjointement de résumer les plus importants sur un sujet. Par exemple, vous pouvez trouver un manuel d'apprentissage automatique de plus de 6 000 pages, avec des sections mises à jour sur les réseaux de neurones, les algorithmes génétiques et la vision industrielle.
Wikibook-Bot résout plusieurs tâches d'apprentissage automatique. Tout d'abord, il s'agit d'une tâche de
classification , c'est-à-dire que vous devez déterminer si l'article appartient à un Wikibook spécifique. Deuxièmement, vous devez diviser les articles sélectionnés en chapitres - c'est la tâche du
clustering . Il a été résolu par des algorithmes bien connus. Enfin, la tâche de
systématisation , qui comprend deux sous-tâches: l'ordre des articles dans chaque chapitre et l'ordre des chapitres eux-mêmes.
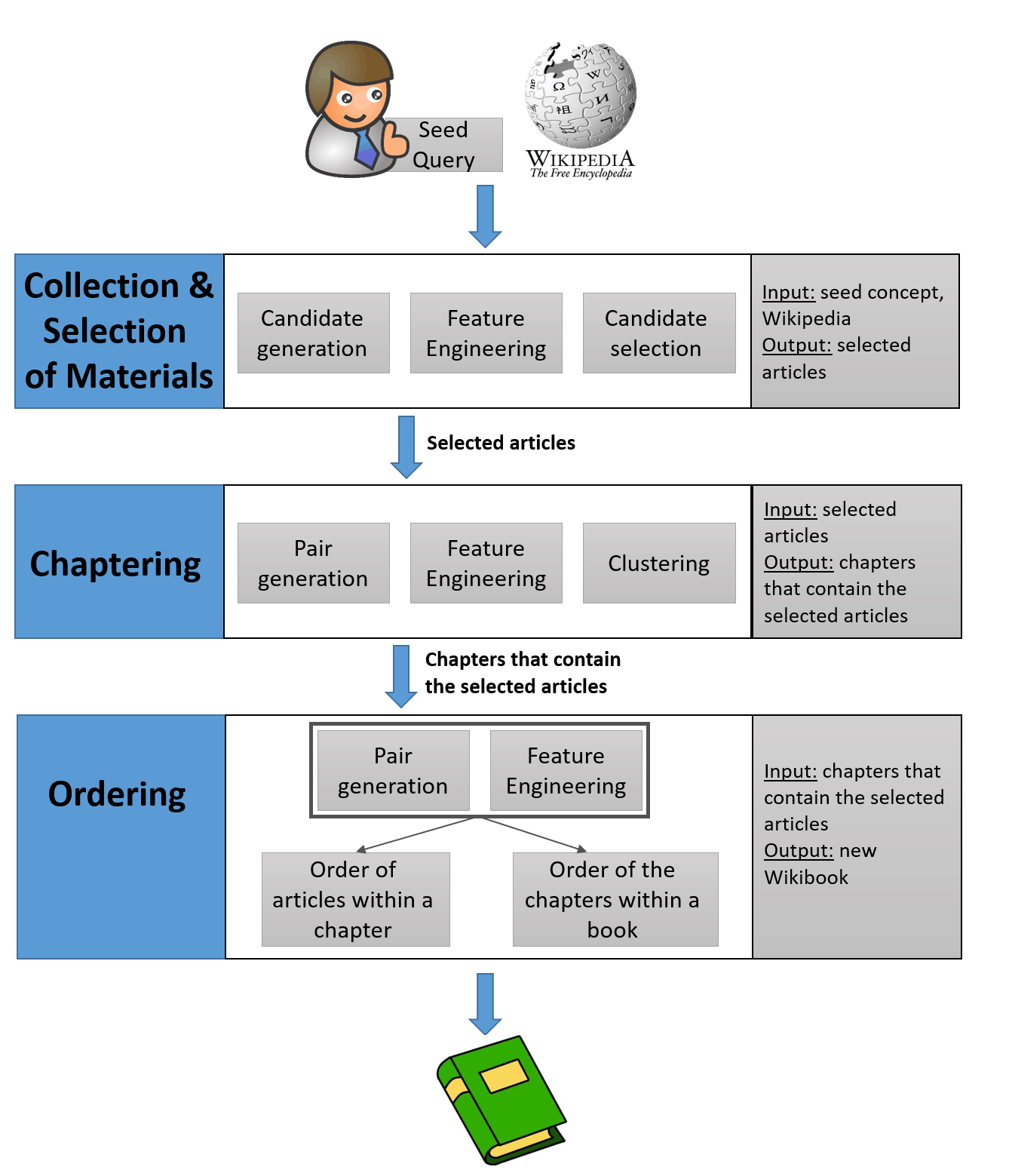
En fait, le programme fonctionne relativement simple. Le principe est clair pour tous ceux qui ont rencontré l'apprentissage des réseaux de neurones. La première étape consiste à créer un ensemble de données d'apprentissage. Sur les quelque 6 700 Wikibooks existants en anglais, des livres avec plus de 1 000 vues et 10 articles ou plus ont été sélectionnés.

Étant donné que ces Wikibooks forment une sorte de référence pour la formation et les tests, les développeurs l'ont considéré comme un standard de qualité. Après la formation du réseau neuronal, les travaux ultérieurs ont été divisés en plusieurs étapes, énumérées ci-dessus: classification, clustering et systématisation. Le travail commence par un titre de manuel généré par l'homme. Le nom décrit tout concept arbitraire. Par exemple, Machine Learning: A Complete Guide.
La première tâche consiste à trier l'ensemble des articles et à déterminer ceux qui sont suffisamment pertinents pour être inclus dans cette rubrique. «Cette tâche est difficile en raison de l'énorme volume d'articles sur Wikipédia et de la nécessité de sélectionner les articles les plus pertinents parmi les millions disponibles», écrivent les auteurs dans un article scientifique. Pour résoudre ce problème, ils ont utilisé la structure du réseau Wikipédia, car certains articles sont souvent liés à d'autres. Il est raisonnable de supposer que l'article correspondant portera également sur le sujet.
Ainsi, le travail commence par un petit noyau d'articles dans le titre dont un titre donné est mentionné. Ensuite, tous les articles situés à une distance allant jusqu'à trois transitions du noyau sont déterminés. Mais combien d'articles trouvés figurent dans le manuel? La réponse à cette question est donnée par des Wikibooks créés par des gens. Une analyse automatique de leur contenu vous permet de déterminer la quantité de contenu de Wikipedia dans les livres créés par l'homme est inclus dans le manuel.
Chaque wikibook créé par l'homme a une structure de réseau définie par le nombre de liens pointant vers d'autres articles, un certain nombre de liens pointant vers des pages, le classement des articles inclus, etc. L'algorithme développé analyse chaque article sélectionné automatiquement pour un sujet donné et répond à la question: si vous l'incluez dans un Wikibook, sa structure de réseau deviendra-t-elle plus similaire aux livres créés par une personne ou non. Sinon, l'article est omis.
Sur la base principalement des données de formation et des méthodes d'apprentissage automatique existantes, d'autres tâches sont également résolues. Ainsi, l'équipe a pu générer automatiquement des Wikibooks déjà créés par des personnes. L'efficacité de la méthode proposée a été évaluée en comparant des livres générés automatiquement avec 407 vrais Wikibooks. On dit que pour toutes les tâches, il a été possible d'obtenir des résultats élevés et statistiquement significatifs lors de la comparaison. Mais encore, la véritable efficacité de l'algorithme peut être estimée après avoir généré des Wikibooks sur d'autres sujets, et pas seulement sur ceux sur lesquels il a étudié.
La description du bot a été publiée sous la forme d'un article scientifique
«Wikibook-Bot - Génération automatique de livres Wikipédia» sur le site de préimpression arXiv.org.