
La tâche principale des services commerciaux (et non commerciaux également) est d'être toujours disponible pour l'utilisateur. Bien que tout le monde tombe en panne, la question est de savoir ce que fait l'équipe informatique pour les minimiser. Nous avons traduit un article de Ben Treynor, Mike Dahlin, Vivek Rau et Betsy Beyer «Calcul de la fiabilité du service», qui explique, y compris, par exemple, Google, pourquoi 100% est un mauvais point de référence pour l'indicateur de fiabilité, quelle est la «règle des quatre neuf» et comment, dans la pratique, prédire mathématiquement la faisabilité de petites et grandes pannes du service et / ou de ses composants critiques - le temps d'indisponibilité attendu, le temps nécessaire pour détecter une panne et le temps pour restaurer le service.
Calcul de la fiabilité du service
Votre système est aussi fiable que ses composants
Ben Trainor, Mike Dalin, Vivec Rau, Betsy Beyer
Comme décrit dans le livre « Site Reliability Engineering: Fiabilité et fiabilité comme dans Google » (ci-après dénommé le livre SRE), le développement de produits et services Google peut atteindre une vitesse de sortie élevée de nouvelles fonctions, tout en maintenant un SLO agressif (objectifs de niveau de service, objectifs de niveau de service) ) pour assurer une grande fiabilité et une réponse rapide. Les SLO exigent que le service soit presque toujours en bon état et presque toujours rapide. De plus, les SLO indiquent également les valeurs exactes de ce «presque toujours» pour un service particulier. Les SLO sont basés sur les observations suivantes:
Dans le cas général, pour n'importe quel service ou système logiciel, 100% est le mauvais point de référence pour l'indicateur de fiabilité, car aucun utilisateur ne peut remarquer la différence entre 100% et 99,999% de disponibilité. Entre l'utilisateur et le service, il existe de nombreux autres systèmes (son ordinateur portable, le Wi-Fi à domicile, le fournisseur, l'alimentation ...), et tous ces systèmes au total ne sont pas disponibles dans 99,999% des cas, mais beaucoup moins souvent. Par conséquent, la différence entre 99,999% et 100% est perdue en raison de facteurs aléatoires causés par l'inaccessibilité d'autres systèmes, et l'utilisateur ne tire aucun avantage du fait que nous avons consacré beaucoup d'efforts à atteindre cette dernière fraction d'un pour cent de la disponibilité du système. Les sérieuses exceptions à cette règle sont les freins antiblocage et les stimulateurs cardiaques!
Pour une discussion détaillée de la façon dont les SLO sont liés aux SLI (indicateurs de niveau de service) et aux SLA (accords de niveau de service), voir le chapitre SRE Target Level of Service. Ce chapitre décrit également en détail comment sélectionner des mesures pertinentes pour un service ou un système particulier, ce qui détermine à son tour le choix du SLO approprié pour ce service ou ce système.
Cet article étend la rubrique SLO pour se concentrer sur les composants de service. En particulier, nous examinerons comment la fiabilité des composants critiques affecte la fiabilité d'un service, ainsi que la façon de concevoir des systèmes pour atténuer l'impact ou réduire le nombre de composants critiques.
La plupart des services proposés par Google visent à fournir une accessibilité de 99,99% (parfois appelée les «quatre neuf») aux utilisateurs. Pour certains services, un nombre inférieur est indiqué dans l'accord d'utilisation, mais l'objectif de 99,99% est stocké à l'intérieur de l'entreprise. Cette barre supérieure donne un avantage dans les situations où les utilisateurs se plaignent de la performance du service bien avant la violation des termes de l'accord, car l'objectif numéro 1 de l'équipe SRE est de rendre les utilisateurs satisfaits des services. Pour de nombreux services, un objectif interne de 99,99% représente le juste milieu, qui équilibre le coût, la complexité et la fiabilité. Pour certains autres, en particulier les services cloud mondiaux, l'objectif interne est de 99,999%.
Fiabilité à 99,99%: observations et conclusions
Examinons quelques observations et conclusions clés sur la conception et le fonctionnement du service avec une fiabilité de 99,99%, puis passons à la pratique.
Observation n ° 1: causes des échecs
Les échecs se produisent pour deux raisons principales: problèmes avec le service lui-même et problèmes avec les composants critiques du service. Un composant critique est un composant qui, en cas de défaillance, entraîne une défaillance correspondante dans le fonctionnement de l'ensemble du service.
Observation n ° 2: Mathématiques de la fiabilité
La fiabilité dépend de la fréquence et de la durée des temps d'arrêt. Elle se mesure à travers:
- Fréquence de ralenti ou inverse de celle-ci: MTTF (temps moyen avant défaillance).
- Temps d'arrêt, MTTR (temps moyen de réparation). Le temps d'arrêt est déterminé par le temps de l'utilisateur: du début du dysfonctionnement à la reprise du fonctionnement normal du service.
Ainsi, la fiabilité est mathématiquement définie comme MTTF / (MTTF + MTTR) en utilisant les unités appropriées.
Conclusion # 1: Règle des neuf supplémentaires
Un service ne peut pas être plus fiable que tous ses composants critiques réunis. Si votre service cherche à garantir la disponibilité à un niveau de 99,99%, tous les composants critiques devraient être disponibles beaucoup plus que 99,99% du temps.
À l'intérieur de Google, nous utilisons la règle empirique suivante: les composants critiques doivent fournir des neuf supplémentaires par rapport à la fiabilité revendiquée de votre service - dans l'exemple ci-dessus, une disponibilité de 99,999% - car tout service aura plusieurs composants critiques, ainsi que ses propres problèmes spécifiques. C'est ce qu'on appelle la «règle des neuf supplémentaires».
Si vous avez un composant critique qui ne fournit pas suffisamment de neuf (un problème relativement courant!), Vous devez minimiser les conséquences négatives.
Conclusion n ° 2: mathématiques de la fréquence, du temps de détection et du temps de récupération
Un service ne peut pas être plus fiable que le produit de la fréquence des incidents et du temps de détection et de récupération. Par exemple, trois arrêts totaux par an de 20 minutes chacun entraînent un total de 60 minutes d'arrêt. Même si le service fonctionnait parfaitement le reste de l'année, une fiabilité de 99,99% (pas plus de 53 minutes de temps d'arrêt par an) serait impossible.
Il s'agit d'une simple observation mathématique, mais elle est souvent négligée.
Conclusion des conclusions n ° 1 et n ° 2
Si le niveau de fiabilité sur lequel repose votre service ne peut être atteint, des efforts doivent être faits pour rectifier la situation - soit en augmentant la disponibilité du service, soit en minimisant les conséquences négatives, comme décrit ci-dessus. Réduire les attentes (c.-à-d. La fiabilité déclarée) est également une option, et souvent la plus vraie: indiquez clairement au service dépendant de vous qu'il doit soit reconstruire son système pour compenser l'erreur de fiabilité de votre service, soit réduire ses propres objectifs de niveau de service . Si vous n'éliminez pas vous-même l'écart, une défaillance suffisamment longue du système nécessitera inévitablement des ajustements.
Application pratique
Examinons un exemple de service avec une fiabilité cible de 99,99% et définissons les exigences pour ses composants et travaillons avec ses défaillances.
Les chiffres
Supposons que votre service à 99,99% soit disponible avec les caractéristiques suivantes:
- Une panne majeure et trois pannes mineures par an. Cela semble effrayant, mais notez qu'un niveau de confiance de 99,99% implique un temps d'arrêt à grande échelle de 20 à 30 minutes et quelques courts arrêts partiels par an. (Les mathématiques indiquent que: a) la défaillance d'un segment n'est pas considérée comme une défaillance de l'ensemble du système du point de vue de SLO, et b) la fiabilité totale est calculée par la somme de la fiabilité des segments.)
- Cinq composants critiques sous la forme d'autres services indépendants avec une fiabilité de 99,999%.
- Cinq segments indépendants qui ne peuvent pas échouer l'un après l'autre.
- Tous les changements sont effectués progressivement, un segment à la fois.
Le calcul mathématique de la fiabilité sera le suivant:
Exigences des composants
- La limite d'erreur totale pour l'année est de 0,01% de 525 600 minutes par an, soit 53 minutes (sur la base de l'année de 365 jours, dans le pire des cas).
- La limite allouée à l'arrêt des composants critiques est de cinq composants critiques indépendants avec une limite de 0,001% chacun = 0,005%; 0,005% de 525 600 minutes par an, soit 26 minutes.
- La limite d'erreur restante de votre service est de 53-26 = 27 minutes.
Exigences de réponse à l'arrêt
- Temps d'arrêt prévu: 4 (1 arrêt complet et 3 arrêts affectant un seul segment)
- L'effet cumulé des interruptions attendues: (1 × 100%) + (3 × 20%) = 1,6
- Détection de panne et récupération après: 27 / 1.6 = 17 minutes
- Temps alloué à la surveillance pour détecter une panne et en informer: 2 minutes
- Temps accordé au spécialiste de garde pour commencer l'analyse de l'alerte: 5 minutes. (Le système de surveillance doit suivre les violations SLO et envoyer un signal au pager en service chaque fois qu'un incident système se produit. De nombreux services Google sont pris en charge par des ingénieurs SR de quart de travail en service qui répondent à des questions urgentes.)
- Temps restant pour minimiser efficacement les effets indésirables: 10 minutes
Conclusion: un levier pour augmenter la fiabilité du service
Il vaut la peine d'examiner attentivement les chiffres présentés, car ils mettent l'accent sur le point fondamental: il existe trois principaux leviers pour augmenter la fiabilité du service.
- Réduisez la fréquence des pannes - grâce à des politiques de publication, des tests, des évaluations périodiques de la structure du projet, etc.
- Réduisez vos temps d'arrêt moyens grâce à la segmentation, l'isolement géographique, la dégradation progressive ou l'isolement des clients.
- Réduisez le temps de récupération - grâce à la surveillance, aux opérations de sauvetage à un bouton (par exemple, revenir à un état précédent ou ajouter une alimentation de secours), des pratiques de préparation opérationnelle, etc.
Vous pouvez équilibrer ces trois méthodes pour simplifier la mise en œuvre de la tolérance aux pannes. Par exemple, s'il est difficile d'atteindre un MTTR de 17 minutes, concentrez-vous sur la réduction des temps d'arrêt moyens. Les stratégies pour minimiser les effets négatifs et atténuer les effets des composants critiques sont discutées plus en détail plus loin dans cet article.
Clarification «Règles pour les neuf supplémentaires» pour les composants imbriqués
Un lecteur aléatoire peut conclure que chaque lien supplémentaire dans la chaîne de dépendance nécessite neuf supplémentaires, donc deux neuf supplémentaires sont nécessaires pour les dépendances de second ordre, trois neuf supplémentaires sont nécessaires pour les dépendances de troisième ordre, etc.
Ce n'est pas la bonne conclusion. Il est basé sur un modèle naïf d'une hiérarchie de composants sous la forme d'un arbre avec une ramification constante à chaque niveau. Dans un tel modèle, comme le montre la Fig. 1, il existe 10 composants uniques du premier ordre, 100 composants uniques du deuxième ordre, 1 000 composants uniques du troisième ordre, etc., ce qui donne un total de 1 111 services uniques, même si l'architecture est limitée à quatre couches. Un écosystème de services hautement fiables avec autant de composants critiques indépendants est clairement irréaliste.
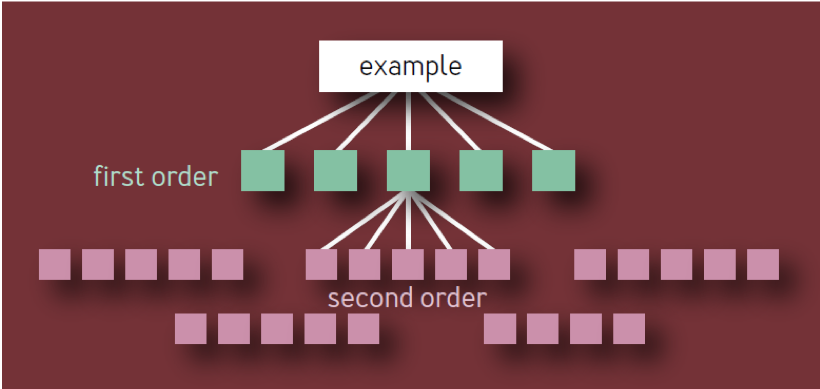
Fig. 1 - Hiérarchie des composants: modèle non valide
Un composant critique en lui-même peut entraîner la défaillance de l'ensemble du service (ou segment de service), quel que soit son emplacement dans l'arborescence de dépendances. Par conséquent, si un composant donné de X est affiché comme une dépendance de plusieurs composants de premier ordre, X ne doit être compté qu'une seule fois, car sa défaillance entraînera finalement une défaillance du service, quel que soit le nombre de services intermédiaires également affectés.
Une lecture correcte de la règle est la suivante:
- Si un service a N composants critiques uniques, alors chacun d'eux contribue 1 / N à la non-fiabilité de l'ensemble du service causée par ce composant, quelle que soit sa faible dans la hiérarchie des composants.
- Chaque composant ne doit être compté qu'une seule fois, même s'il apparaît plusieurs fois dans la hiérarchie des composants (en d'autres termes, seuls les composants uniques sont comptés). Par exemple, lors du calcul des composants du service A de la Fig. 2, le service B ne doit être envisagé qu'une seule fois.
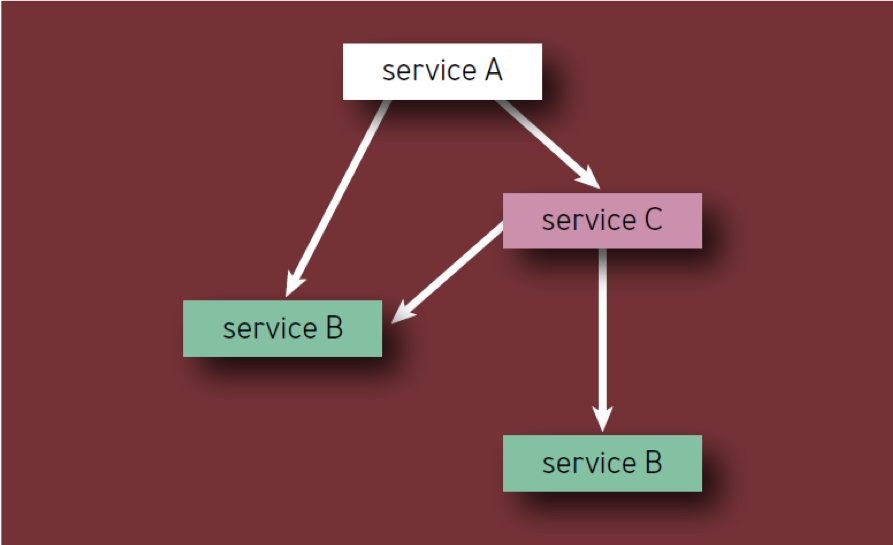
Fig. 2 - Composants dans la hiérarchie
Par exemple, considérons un service hypothétique A avec une limite d'erreur de 0,01%. Les propriétaires de services sont prêts à consacrer la moitié de cette limite à leurs propres erreurs et pertes, et la moitié aux composants critiques. Si le service a N de tels composants, chacun d'eux reçoit 1 / N de la limite d'erreur restante. Les services typiques ont souvent de 5 à 10 composants critiques, et chacun d'eux ne peut donc refuser qu'un dixième ou un vingtième de la limite d'erreur du service A. Par conséquent, en règle générale, les parties critiques du service doivent avoir une fiabilité supplémentaire de neuf.
Limites d'erreur
Le concept de limites d'erreur est couvert en détail dans le livre SRE, mais ici il convient de le mentionner. Les ingénieurs de Google SR utilisent des limites d'erreur pour équilibrer la fiabilité et le rythme des mises à jour. Cette limite détermine le niveau de défaillance acceptable pour le service pendant une certaine période de temps (généralement un mois). La limite d'erreur n'est que de 1 moins le SLO du service, de sorte que le service disponible à 99,99% précédemment discuté a une «limite» de 0,01% sur le manque de fiabilité. Jusqu'à ce que le service ait épuisé sa limite d'erreur dans un mois, l'équipe de développement est libre (dans des limites raisonnables) de lancer de nouvelles fonctions, mises à jour, etc.
Si la limite d'erreur est épuisée, les modifications apportées au service sont suspendues (à l'exception des correctifs de sécurité urgents et des modifications visant à provoquer la violation en premier lieu) jusqu'à ce que le service reconstitue la réserve dans la limite d'erreur ou jusqu'à ce que le mois change. De nombreux services chez Google utilisent une méthode de fenêtre coulissante pour SLO afin que la limite d'erreur soit restaurée progressivement. Pour les services sérieux avec un SLO supérieur à 99,99%, il est conseillé d'utiliser une remise à zéro trimestrielle plutôt que mensuelle de la limite, car le nombre de temps d'arrêt autorisé est faible.
Les limites d'erreur éliminent les tensions entre les services qui pourraient autrement se produire entre les ingénieurs SR et les développeurs de produits, en leur fournissant un outil commun d'évaluation des risques basé sur des données pour lancer un produit. Ils donnent également aux ingénieurs SR et aux équipes de développement un objectif commun de développer des méthodes et des technologies qui leur permettront d'innover plus rapidement et de lancer des produits sans «budget gonflé».
Stratégies de réduction et d'atténuation des composants critiques
À ce stade, dans cet article, nous avons établi ce que l'on peut appeler la «règle d'or pour la fiabilité des composants» . Cela signifie que la fiabilité de tout composant critique doit être 10 fois supérieure au niveau de fiabilité cible de l'ensemble du système afin que sa contribution à la non-fiabilité du système reste au niveau d'erreur. Il s'ensuit que dans le cas idéal, la tâche consiste à rendre autant de composants que possible non critiques. Cela signifie que les composants peuvent adhérer à un niveau de fiabilité inférieur, donnant aux développeurs la possibilité d'innover et de prendre des risques.
La stratégie la plus simple et la plus évidente pour réduire les dépendances critiques consiste à éliminer les points de défaillance uniques dans la mesure du possible. Un système plus grand devrait pouvoir fonctionner de manière acceptable sans aucun composant donné qui ne soit pas une dépendance critique ou SPOF.
En fait, vous ne pouvez probablement pas vous débarrasser de toutes les dépendances critiques; mais vous pouvez suivre certaines directives de conception de système pour optimiser la fiabilité. Bien que cela ne soit pas toujours possible, il est plus facile et plus efficace d'atteindre une fiabilité élevée du système si vous définissez la fiabilité aux étapes de conception et de planification, et non après que le système fonctionne et affecte les utilisateurs réels.
Évaluation de la structure du projet
Lors de la planification d'un nouveau système ou service, ou lors de la refonte ou de l'amélioration d'un système ou service existant, un examen de l'architecture ou du projet peut révéler une infrastructure commune, ainsi que des dépendances internes et externes.
Infrastructure partagée
Si votre service utilise une infrastructure partagée (par exemple, le service de base de données principal utilisé par plusieurs produits disponibles pour les utilisateurs), déterminez si cette infrastructure est utilisée correctement. . , — .
— , . .
:
, . , 99,9- , , , 1 — 0,013 , .
( , ), , , .
, RPC (remote procedure call, ) 99- , RPC (. ). «» , RPC. ( RPC , Google : RPC RPC.)
, (fail safe) . , , , , , .
, , . RPC , , . RPC . , .
, . , — .
, \ .
, . . . , .
SLO. , , . , , , MTTR .
, . :
, , , . :
, : , , . — , . , , , .
, . , Google , 10 .
Conclusion
Bien que les lecteurs connaissent probablement certains ou plusieurs des concepts décrits dans cet article, des exemples spécifiques de leur utilisation les aideront à mieux comprendre leur essence et à transmettre ces connaissances à d'autres. Nos recommandations ne sont pas simples, mais pas inaccessibles. Un certain nombre de services Google ont démontré à plusieurs reprises la fiabilité au-delà de quatre neuf non pas en raison d'efforts ou d'intelligence surhumains, mais en raison de l'application réfléchie des principes et des meilleures pratiques développés au fil des ans (voir SRE, Annexe B: Lignes directrices pratiques pour les services dans les opérations industrielles).