Un peu plus d'un an avec ma participation, le "dialogue" suivant a eu lieu:
Application .Net : Hey Entity Framework, veuillez me donner beaucoup de données!
Entity Framework : Désolé, je ne vous ai pas compris. Que voulez-vous dire?
Application .Net : Oui, je viens de recevoir une collection de 100 000 transactions. Et maintenant, nous devons vérifier rapidement l'exactitude des prix des titres qui y sont indiqués.
Entity Framework : Ahh, eh bien, essayons ...
Application .Net : voici le code:
var query = from p in context.Prices join t in transactions on new { p.Ticker, p.TradedOn, p.PriceSourceId } equals new { t.Ticker, t.TradedOn, t.PriceSourceId } select p; query.ToList();
Cadre d'entité :

Classique Je pense que beaucoup de gens connaissent cette situation: quand je veux vraiment "magnifiquement" et faire rapidement une recherche dans la base de données en utilisant le JOIN de la collection locale et DbSet . Habituellement, cette expérience est décevante.
Dans cet article (qui est une traduction gratuite de mon autre article ), je vais mener une série d'expériences et essayer différentes manières de contourner cette limitation. Il y aura un code (simple), des pensées et quelque chose comme une fin heureuse.
Présentation
Tout le monde connaît Entity Framework , beaucoup l'utilisent tous les jours et il existe de nombreux bons articles sur la façon de le cuisiner correctement (utilisez des requêtes plus simples, utilisez les paramètres de Skip and Take, utilisez VIEW, demandez uniquement les champs nécessaires, surveillez la mise en cache des requêtes et autre), cependant, le thème JOIN de la collection locale et DbSet est toujours un point faible.
Défi
Supposons qu'il existe une base de données avec les prix et qu'il existe une collection de transactions pour lesquelles vous devez vérifier l'exactitude des prix. Et supposons que nous ayons le code suivant.
var localData = GetDataFromApiOrUser(); var query = from p in context.Prices join s in context.Securities on p.SecurityId equals s.SecurityId join t in localData on new { s.Ticker, p.TradedOn, p.PriceSourceId } equals new { t.Ticker, t.TradedOn, t.PriceSourceId } select p; var result = query.ToList();
Ce code ne fonctionne pas du tout dans Entity Framework 6 . Dans Entity Framework Core - cela fonctionne, mais tout sera fait côté client et dans le cas où il y a des millions d'enregistrements dans la base de données - ce n'est pas une option.
Comme je l'ai dit, je vais essayer différentes façons de contourner ce problème. Du simple au complexe. Pour mes expériences, j'utilise le code du référentiel suivant. Le code est écrit en utilisant: C # , .Net Core , EF Core et PostgreSQL .
J'ai également réalisé quelques métriques: le temps passé et la consommation de mémoire. Avertissement: si le test a été effectué pendant plus de 10 minutes, je l'ai interrompu (la restriction vient d'en haut). Test machine Intel Core i5, 8 Go de RAM, SSD.
Schéma DB
Seulement 3 tableaux: prix , titres et sources de prix . Prix - contient 10 millions d'entrées.
Méthode 1. Naive
Commençons simplement et utilisons le code suivant:
Code pour la méthode 1 var result = new List<Price>(); using (var context = CreateContext()) { foreach (var testElement in TestData) { result.AddRange(context.Prices.Where( x => x.Security.Ticker == testElement.Ticker && x.TradedOn == testElement.TradedOn && x.PriceSourceId == testElement.PriceSourceId)); } }
L'idée est simple: dans une boucle, nous lisons les enregistrements de la base de données un par un et les ajoutons à la collection résultante. Ce code n'a qu'un seul avantage: la simplicité. Et un inconvénient est la faible vitesse: même s'il y a un index dans la base de données, la plupart du temps il faudra une communication avec le serveur de base de données. Les mesures sont les suivantes:
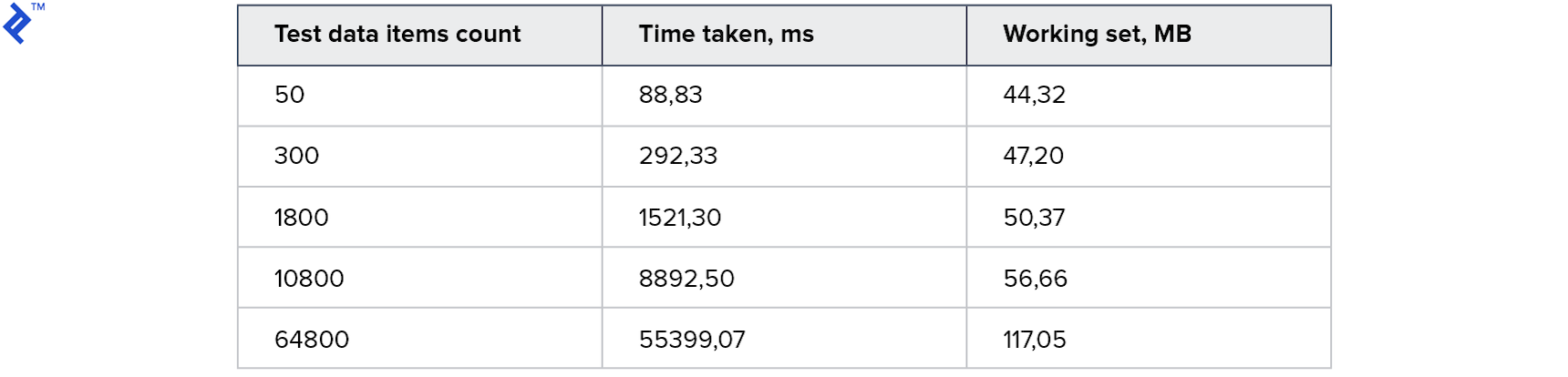
La consommation de mémoire est faible. Une grande collection prend 1 minute. Pour commencer, pas mal, mais je le veux plus vite.
Méthode 2: parallèle naïf
Essayons d'ajouter du parallélisme. L'idée est d'accéder à la base de données à partir de plusieurs threads.
Code pour la méthode 2 var result = new ConcurrentBag<Price>(); var partitioner = Partitioner.Create(0, TestData.Count); Parallel.ForEach(partitioner, range => { var subList = TestData.Skip(range.Item1) .Take(range.Item2 - range.Item1) .ToList(); using (var context = CreateContext()) { foreach (var testElement in subList) { var query = context.Prices.Where( x => x.Security.Ticker == testElement.Ticker && x.TradedOn == testElement.TradedOn && x.PriceSourceId == testElement.PriceSourceId); foreach (var el in query) { result.Add(el); } } } });
Résultat:
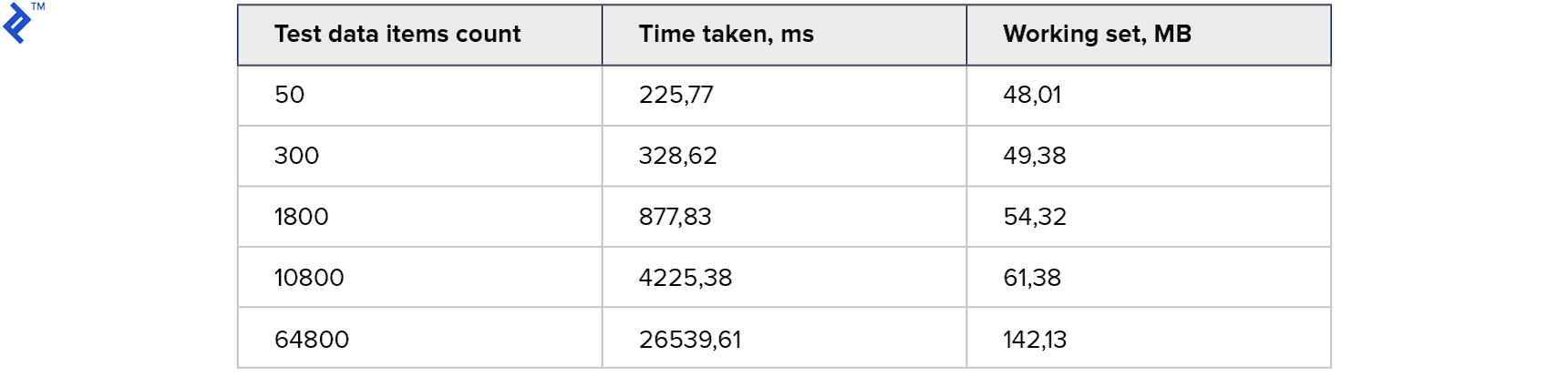
Pour les petites collections, cette approche est encore plus lente que la première méthode. Et pour le plus grand - 2 fois plus rapide. Fait intéressant, 4 threads ont été générés sur ma machine, mais cela n'a pas entraîné d'accélération 4x. Cela suggère que la surcharge de cette méthode est importante: à la fois côté client et côté serveur. La consommation de mémoire a augmenté, mais pas de manière significative.
Méthode 3: Contient plusieurs
Il est temps d'essayer autre chose et de réduire la tâche à une seule requête. Cela peut être fait comme suit:
- Préparez 3 collections uniques de Ticker , PriceSourceId et Date
- Exécutez la demande et utilisez 3 Contient
- Revérifiez les résultats localement
Code pour la méthode 3 var result = new List<Price>(); using (var context = CreateContext()) {
Le problème ici est que le temps d'exécution et la quantité de données renvoyées dépendent fortement des données elles-mêmes (à la fois dans la requête et dans la base de données). Autrement dit, un ensemble de seules les données nécessaires peut renvoyer et des enregistrements supplémentaires peuvent être retournés (même 100 fois plus).
Cela peut être expliqué à l'aide de l'exemple suivant. Supposons qu'il existe le tableau suivant avec des données:

Supposons également que j'ai besoin des prix pour Ticker1 avec TradedOn = 2018-01-01 et pour Ticker2 avec TradedOn = 2018-01-02 .
Puis des valeurs uniques pour Ticker = ( Ticker1 , Ticker2 )
Et des valeurs uniques pour TradedOn = ( 2018-01-01 , 2018-01-02 )
Cependant, 4 enregistrements seront retournés en conséquence, car ils correspondent vraiment à ces combinaisons. La mauvaise chose est que plus les champs sont utilisés, plus les chances d'obtenir des enregistrements supplémentaires en conséquence.
Pour cette raison, les données obtenues par cette méthode doivent en outre être filtrées côté client. Et c'est le plus gros inconvénient.
Les mesures sont les suivantes:
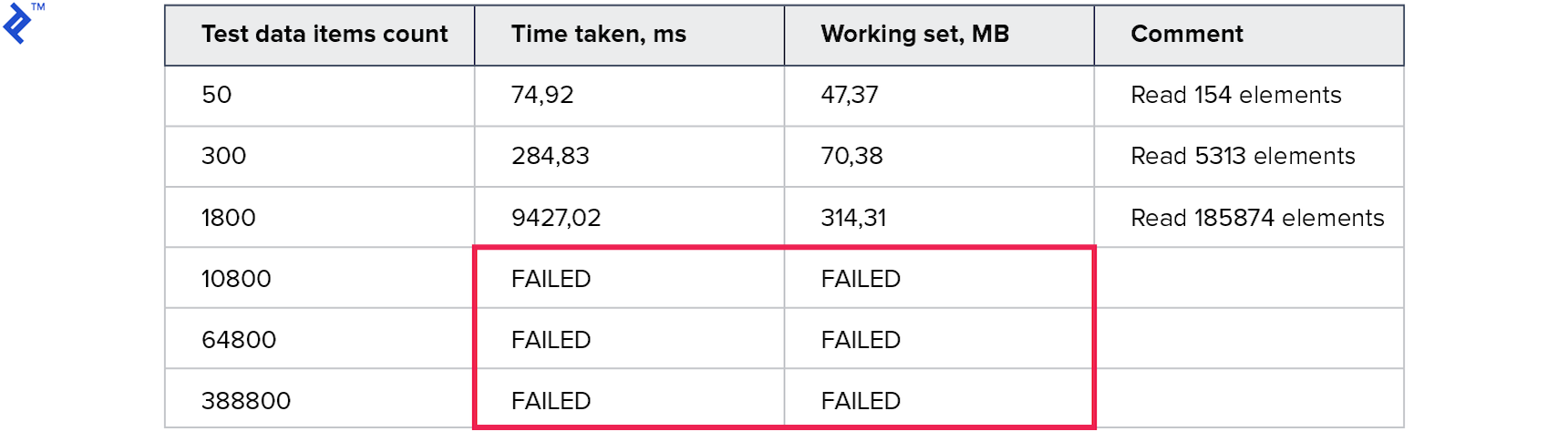
La consommation de mémoire est pire que toutes les méthodes précédentes. Le nombre de lignes lues est plusieurs fois supérieur au nombre demandé. Les tests pour les grandes collections ont été interrompus car ils ont fonctionné pendant plus de 10 minutes. Cette méthode n'est pas bonne.
Méthode 4. Générateur de prédicats
Essayons de l'autre côté: la bonne vieille expression . En les utilisant, vous pouvez créer 1 grande requête sous la forme suivante:
… (.. AND .. AND ..) OR (.. AND .. AND ..) OR (.. AND .. AND ..) …
Cela donne l'espoir qu'il sera possible de générer 1 demande et d'obtenir uniquement les données nécessaires pour 1 appel. Code:
Code pour la méthode 4 var result = new List<Price>(); using (var context = CreateContext()) { var baseQuery = from p in context.Prices join s in context.Securities on p.SecurityId equals s.SecurityId select new TestData() { Ticker = s.Ticker, TradedOn = p.TradedOn, PriceSourceId = p.PriceSourceId, PriceObject = p }; var tradedOnProperty = typeof(TestData).GetProperty("TradedOn"); var priceSourceIdProperty = typeof(TestData).GetProperty("PriceSourceId"); var tickerProperty = typeof(TestData).GetProperty("Ticker"); var paramExpression = Expression.Parameter(typeof(TestData)); Expression wholeClause = null; foreach (var td in TestData) { var elementClause = Expression.AndAlso( Expression.Equal( Expression.MakeMemberAccess( paramExpression, tradedOnProperty), Expression.Constant(td.TradedOn) ), Expression.AndAlso( Expression.Equal( Expression.MakeMemberAccess( paramExpression, priceSourceIdProperty), Expression.Constant(td.PriceSourceId) ), Expression.Equal( Expression.MakeMemberAccess( paramExpression, tickerProperty), Expression.Constant(td.Ticker)) )); if (wholeClause == null) wholeClause = elementClause; else wholeClause = Expression.OrElse(wholeClause, elementClause); } var query = baseQuery.Where( (Expression<Func<TestData, bool>>)Expression.Lambda( wholeClause, paramExpression)).Select(x => x.PriceObject); result.AddRange(query); }
Le code s'est avéré plus compliqué que dans les méthodes précédentes. Construire manuellement Expression n'est pas l'opération la plus simple et la plus rapide.
Mesures:
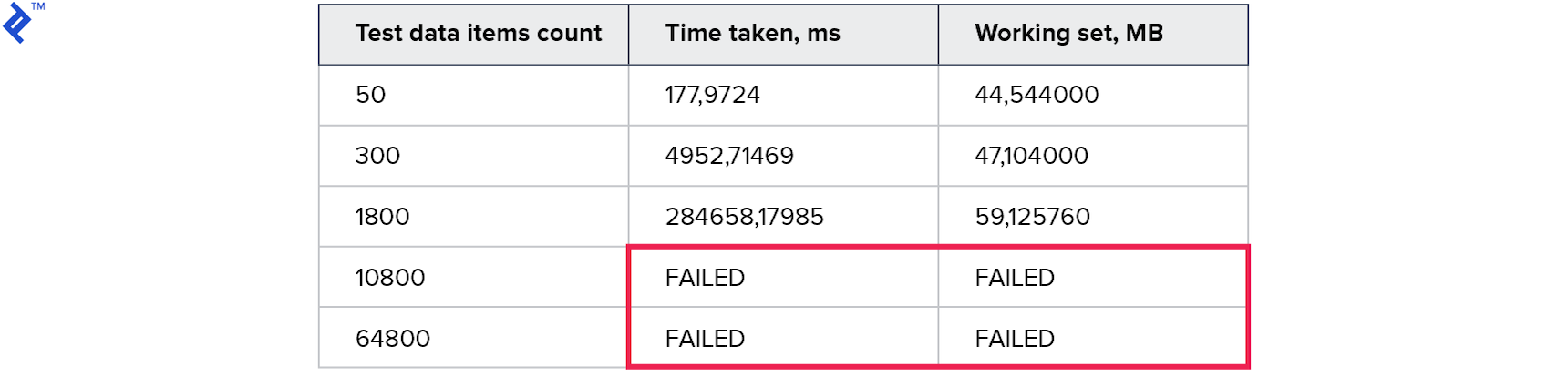
Les résultats temporaires étaient encore pires que dans la méthode précédente. Il semble que les frais généraux pendant la construction et lors de la marche dans l'arbre se soient avérés être bien plus que le gain lié à l'utilisation d'une seule demande.
Méthode 5: table de données de requête partagée
Essayons une autre option:
J'ai créé une nouvelle table dans la base de données dans laquelle j'écrirai les données nécessaires pour compléter la demande (implicitement j'ai besoin d'un nouveau DbSet dans le contexte).
Maintenant, pour obtenir le résultat dont vous avez besoin:
- Lancer la transaction
- Télécharger des données de requête dans une nouvelle table
- Exécutez la requête elle-même (en utilisant la nouvelle table)
- Annuler une transaction (pour effacer le tableau de données des requêtes)
Le code ressemble à ceci:
Code pour la méthode 5 var result = new List<Price>(); using (var context = CreateContext()) { context.Database.BeginTransaction(); var reducedData = TestData.Select(x => new SharedQueryModel() { PriceSourceId = x.PriceSourceId, Ticker = x.Ticker, TradedOn = x.TradedOn }).ToList();
Premières mesures:
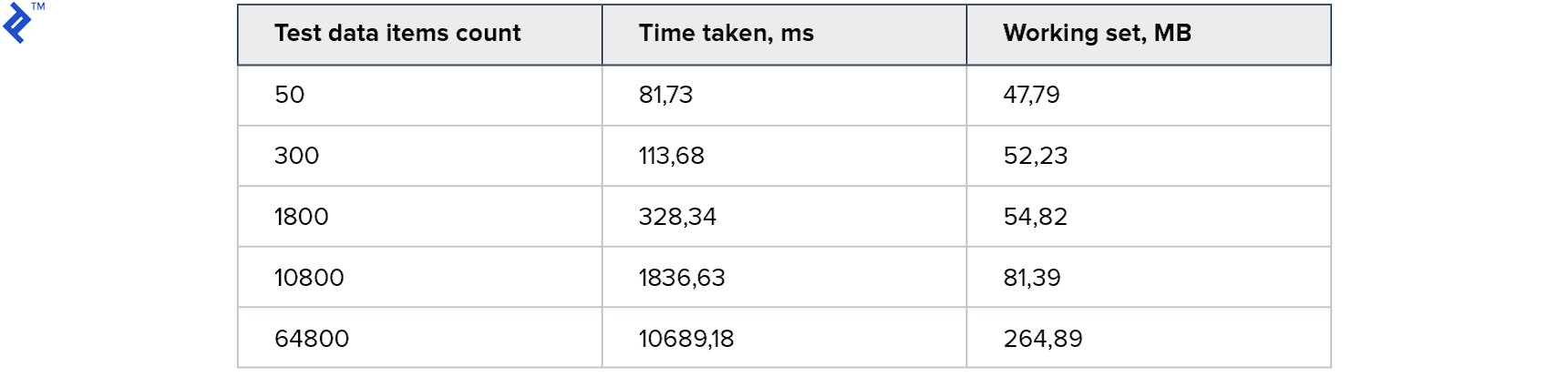
Tous les tests ont fonctionné et ont fonctionné rapidement! La consommation de mémoire est également acceptable.
Ainsi, grâce à l'utilisation d'une transaction, cette table peut être utilisée simultanément par plusieurs processus. Et comme il s'agit d'une véritable table existante, toutes les fonctionnalités d' Entity Framework sont à notre disposition: il vous suffit de charger les données dans la table, de créer une requête à l'aide de JOIN et de l'exécuter. À première vue, c'est ce dont vous avez besoin, mais il y a des inconvénients importants:
- Vous devez créer une table pour un type de requête spécifique
- Il est nécessaire d'utiliser des transactions (et de gaspiller des ressources SGBD sur celles-ci)
- Et l'idée même que vous devez ÉCRIRE quelque chose, quand vous avez besoin de LIRE, semble étrange. Et sur Read Replica, cela ne fonctionnera tout simplement pas.
Et le reste est une solution plus ou moins fonctionnelle qui peut déjà être utilisée.
Méthode 6. Extension MemoryJoin
Vous pouvez maintenant essayer d'améliorer l'approche précédente. Les pensées sont:
- Au lieu d'utiliser une table spécifique à un type de requête, vous pouvez utiliser une option généralisée. À savoir, créez une table avec un nom comme shared_query_data et ajoutez-y plusieurs champs Guid , plusieurs Long , plusieurs String , etc. Des noms simples peuvent être pris: Guid1 , Guid2 , String1 , Long1 , Date2 , etc. Ensuite, ce tableau peut être utilisé pour 95% des types de requête. Les noms de propriété peuvent être «ajustés» ultérieurement à l'aide de la perspective Sélectionner .
- Vous devez ensuite ajouter un DbSet pour shared_query_data .
- Mais que se passe-t-il si, au lieu d'écrire des données dans la base de données, en passant des valeurs à l'aide de la construction VALUES ? Autrement dit, il est nécessaire que dans la requête SQL finale, au lieu d'accéder à shared_query_data, il y ait un appel à VALUES . Comment faire
- Dans Entity Framework Core - en utilisant simplement FromSql .
- Dans Entity Framework 6 - vous devez utiliser DbInterception - c'est-à-dire, changez le SQL généré en ajoutant la construction VALUES juste avant l'exécution. Cela entraînera une limitation: dans une seule demande, pas plus d'une construction VALUES . Mais ça va marcher!
- Puisque nous n'allons pas écrire dans la base de données, nous obtenons alors la table shared_query_data créée à la première étape, n'est-elle pas nécessaire du tout? Réponse: oui, ce n'est pas nécessaire, mais DbSet est toujours nécessaire, car Entity Framework doit connaître le schéma de données afin de générer des requêtes. Il s'avère que nous avons besoin d'un DbSet pour un modèle généralisé qui n'existe pas dans la base de données et n'est utilisé que pour inspirer Entity Framework, qu'il sait ce qu'il fait.
Convertir IEnumerable en exemple IQueryable- L'entrée a reçu une collection d'objets du type suivant:
class SomeQueryData { public string Ticker {get; set;} public DateTimeTradedOn {get; set;} public int PriceSourceId {get; set;} }
- Nous avons à notre disposition DbSet avec les champs String1 , String2 , Date1 , Long1 , etc.
- Laissez Ticker être stocké dans String1 , TradedOn dans Date1 et PriceSourceId dans Long1 ( int mapps en long , afin de ne pas séparer les champs pour int et long )
- Alors FromSql + VALUES sera comme ceci:
var query = context.QuerySharedData.FromSql( "SELECT * FROM ( VALUES (1, 'Ticker1', @date1, @id1), (2, 'Ticker2', @date2, @id2) ) AS __gen_query_data__ (id, string1, date1, long1)")
- Vous pouvez maintenant faire une projection et renvoyer un IQueryable pratique en utilisant le même type qui était à l'entrée:
return query.Select(x => new SomeQueryData() { Ticker = x.String1, TradedOn = x.Date1, PriceSourceId = (int)x.Long1 });
J'ai réussi à implémenter cette approche et même à la concevoir comme un package NuGet EntityFrameworkCore.MemoryJoin (le code est également disponible). Malgré le fait que le nom contient le mot Core , Entity Framework 6 est également pris en charge. Je l'ai appelé MemoryJoin , mais en fait, il envoie des données locales au SGBD dans la construction VALUES et tout le travail est fait dessus.
Le code est le suivant:
Code pour la méthode 6 var result = new List<Price>(); using (var context = CreateContext()) {
Mesures:
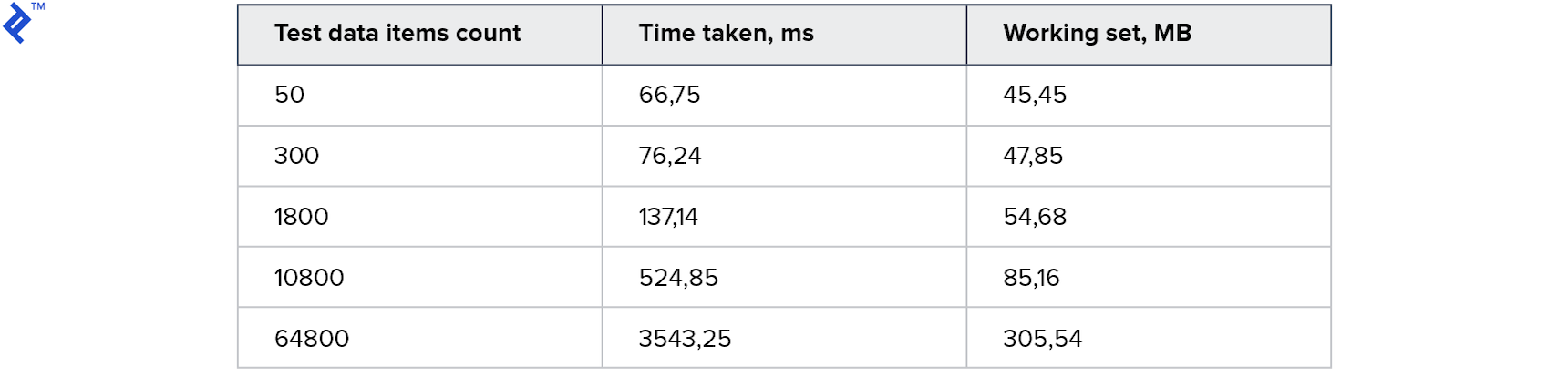
C'est le meilleur résultat que j'aie jamais essayé. Le code était très simple et direct, et fonctionnait en même temps pour Read Replica.
Un exemple de requête générée pour recevoir 3 éléments SELECT "p"."PriceId", "p"."ClosePrice", "p"."OpenPrice", "p"."PriceSourceId", "p"."SecurityId", "p"."TradedOn", "t"."Ticker", "t"."TradedOn", "t"."PriceSourceId" FROM "Price" AS "p" INNER JOIN "Security" AS "s" ON "p"."SecurityId" = "s"."SecurityId" INNER JOIN ( SELECT "x"."string1" AS "Ticker", "x"."date1" AS "TradedOn", CAST("x"."long1" AS int4) AS "PriceSourceId" FROM ( SELECT * FROM ( VALUES (1, @__gen_q_p0, @__gen_q_p1, @__gen_q_p2), (2, @__gen_q_p3, @__gen_q_p4, @__gen_q_p5), (3, @__gen_q_p6, @__gen_q_p7, @__gen_q_p8) ) AS __gen_query_data__ (id, string1, date1, long1) ) AS "x" ) AS "t" ON (("s"."Ticker" = "t"."Ticker") AND ("p"."PriceSourceId" = "t"."PriceSourceId")
Ici, vous pouvez également voir comment le modèle généralisé (avec les champs String1 , Date1 , Long1 ) utilisant Select se transforme en celui qui est utilisé dans le code (avec les champs Ticker , TradedOn , PriceSourceId ).
Tout le travail est effectué en 1 requête sur le serveur SQL. Et c'est une petite fin heureuse, dont j'ai parlé au début. Néanmoins, l'utilisation de cette méthode nécessite une compréhension et les étapes suivantes:
- Vous devez ajouter un DbSet supplémentaire à votre contexte (bien que la table elle-même puisse être omise )
- Dans le modèle généralisé, utilisé par défaut, 3 champs de types Guid , String , Double , Long , Date , etc. sont déclarés. Cela devrait suffire pour 95% des types de demandes. Et si vous passez une collection d'objets avec 20 champs à FromLocalList , une exception sera levée, disant que l'objet est trop complexe. Il s'agit d'une restriction souple et peut être contournée - vous pouvez déclarer votre type et y ajouter au moins 100 champs. Cependant, plus de champs sont plus lents à travailler.
- Plus de détails techniques sont décrits dans mon article .
Conclusion
Dans cet article, j'ai présenté mes réflexions sur le sujet de la collection locale JOIN et de DbSet. Il me semblait que mon développement à l'aide de VALUES pouvait intéresser la communauté. Au moins, je n'ai pas rencontré une telle approche lorsque j'ai résolu ce problème moi-même. Personnellement, cette méthode m'a aidé à surmonter un certain nombre de problèmes de performances dans mes projets en cours, peut-être qu'elle vous aidera également.
Quelqu'un dira que l'utilisation de MemoryJoin est trop "abstraite" et doit être développée davantage, et jusque-là, elle ne devrait pas être utilisée. C'est exactement la raison pour laquelle j'étais très douteux et pendant près d'un an, je n'ai pas écrit cet article. Je suis d'accord pour que cela fonctionne plus facilement (j'espère qu'un jour ça le sera), mais je dirai aussi que l'optimisation n'a jamais été la tâche des Juniors. L'optimisation nécessite toujours une compréhension du fonctionnement de l'outil. Et s'il est possible d'obtenir une accélération d'environ 8 fois ( Naive Parallel vs MemoryJoin ), je maîtriserais 2 points et la documentation.
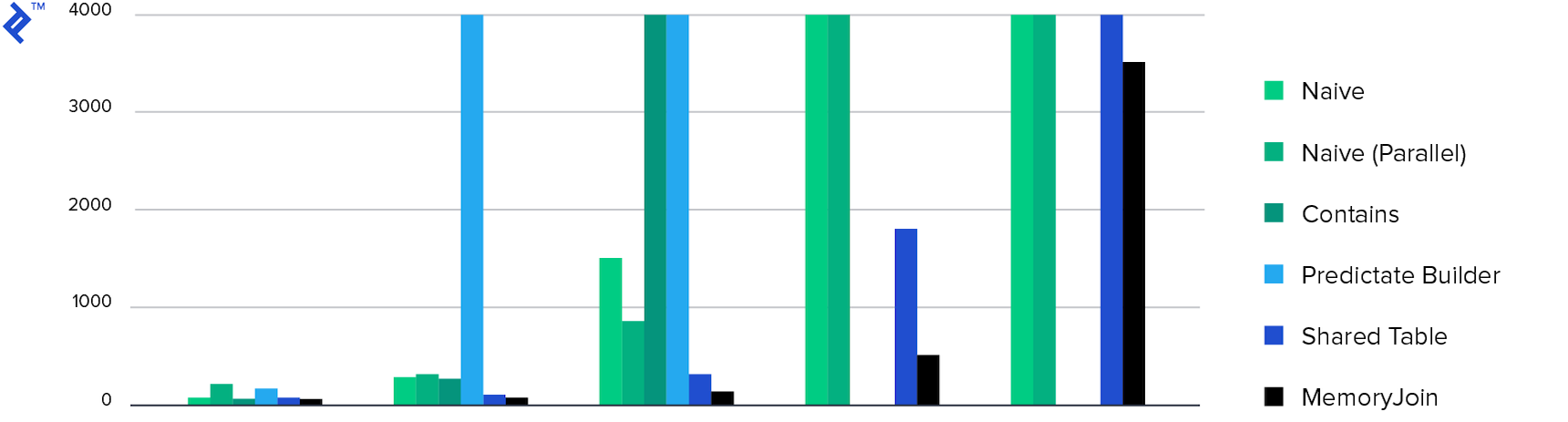
Et enfin, les diagrammes:
Le temps passé. Seules 4 méthodes ont terminé la tâche en moins de 10 minutes, et MemoryJoin est le seul moyen qui a terminé la tâche en moins de 10 secondes.
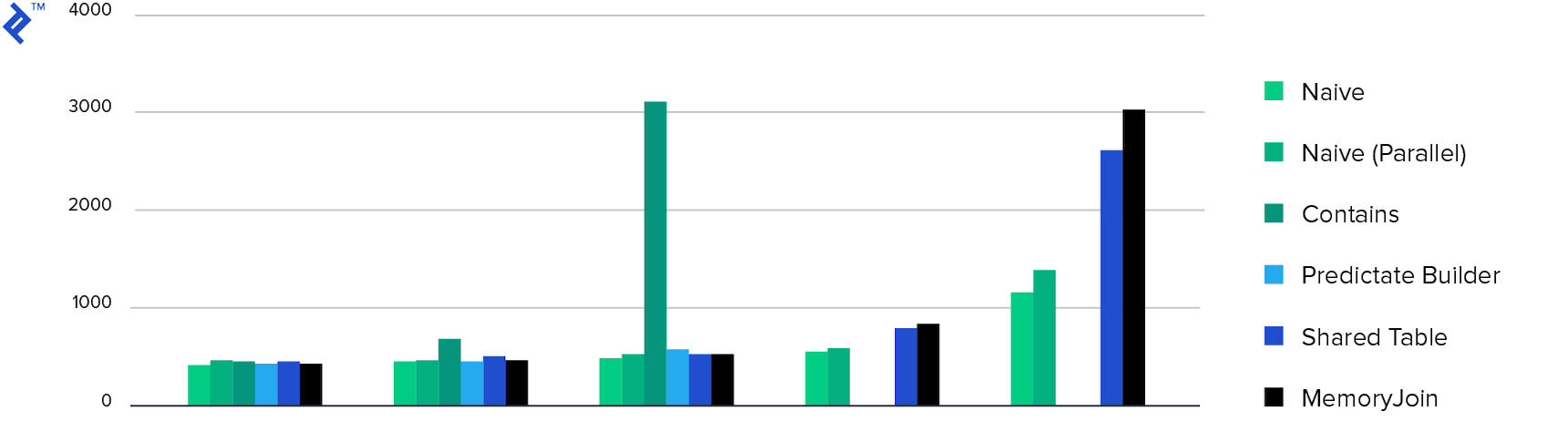
Consommation de mémoire. Toutes les méthodes ont montré approximativement la même consommation de mémoire, à l'exception de Contient plusieurs . Cela est dû à la quantité de données retournées.
Merci d'avoir lu!