 La classification de texte
La classification de texte est l'une des tâches les plus courantes dans la
PNL et la formation des enseignants, lorsque l'ensemble de données contient des documents texte et des étiquettes sont utilisées pour former le classificateur de texte.
Du point de vue de la PNL, la tâche de classification du texte est accomplie en entraînant la représentation au niveau des mots à l'aide de l'incorporation de mots, puis en formant la représentation au niveau du texte, qui est utilisée comme fonction de classification.
Le type de méthodes basées sur le codage ignore les petits détails et les clés de classification (car la représentation générale au niveau du texte est étudiée en compressant les représentations au niveau des mots).
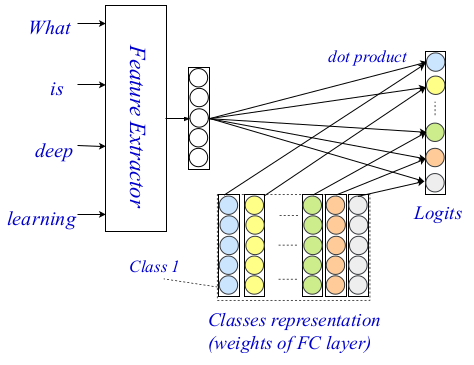 Méthodes basées sur l'encodage pour classer le texte avec une correspondance au niveau du texte
Méthodes basées sur l'encodage pour classer le texte avec une correspondance au niveau du texteEXAM - Nouvelle méthode de classification des textes
Des chercheurs de l'Université du Shandong et de l'Université nationale de Singapour ont
proposé un nouveau modèle de classification de texte qui intègre des signaux de correspondance au niveau des mots dans la tâche de classification de texte. Leur méthode utilise un mécanisme d'interaction pour introduire des conseils détaillés au niveau des mots dans le processus de classification.
Pour résoudre le problème de l'inclusion de signaux de correspondance au niveau des mots plus précis, les chercheurs ont proposé de
calculer explicitement les estimations de correspondance entre les mots et les classes .
L'idée principale est de calculer la matrice d'interaction à partir d'une représentation au niveau du mot qui portera les clés correspondantes au niveau du mot. Chaque entrée de cette matrice est une évaluation de la correspondance entre un mot et une classe spécifique.
La structure de classification de texte proposée, appelée EXAM - EXplicit interAction Model (
GitHub ), contient trois éléments principaux:
- encodeur de niveau de mot,
- couche d'interaction et
- couche d'agrégation.
Cette architecture à trois niveaux vous permet d'encoder et de classer du texte à l'aide de signaux et d'indications petits et généralisés. L'architecture entière est montrée dans l'image ci-dessous.
 EXAM Architecture
EXAM ArchitectureDans le passé, les encodeurs au niveau des mots ont été largement étudiés dans la communauté NLP, et des encodeurs très puissants sont apparus. Les auteurs utilisent la méthode sovermenny comme encodeur au niveau des mots, et dans leur travail ils décrivent en détail deux autres composantes de leur architecture: le niveau d'interaction et d'agrégation.
La couche d'interaction, la contribution principale et la nouveauté de la méthode proposée sont basées sur le mécanisme d'interaction bien connu. Les chercheurs utilisent une
matrice de présentation expérimentée pour coder chacune des classes afin de pouvoir ensuite calculer les estimations d'interaction entre les classes. Les notes finales sont apposées à l'aide d'un produit ponctuel en fonction de l'interaction entre le mot cible et chaque classe. Des fonctions plus complexes n'ont pas été prises en compte en raison de la complexité accrue des calculs.
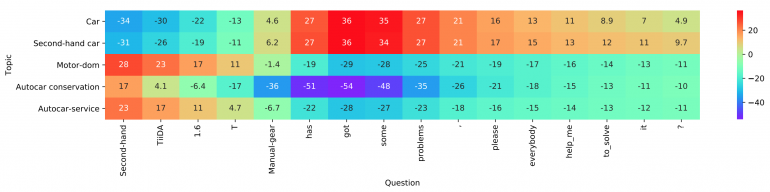 Visualisation des couches
Visualisation des couchesEnfin, ils utilisent un MLP à deux couches simple et entièrement connecté comme couche d'agrégation. Ils mentionnent également qu'un niveau d'agrégation plus complexe, y compris CNN ou LSTM, peut être utilisé ici. MLP est utilisé pour calculer les logits de classification finale à l'aide de la matrice d'interaction et des codages au niveau des mots. L'entropie croisée est utilisée en fonction de la perte pour l'optimisation.
Grades
Pour évaluer le cadre proposé pour la classification de texte, les chercheurs ont mené des expériences approfondies dans des conditions à la fois multi-classes et multi-tags. Ils montrent que leur méthode est de loin supérieure aux méthodes modernes pertinentes pertinentes.
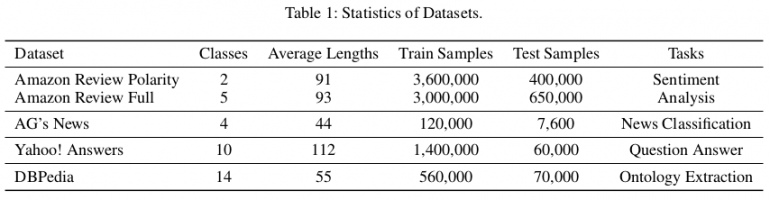 Statistiques des jeux de données utilisés pour l'évaluation
Statistiques des jeux de données utilisés pour l'évaluationPour l'évaluation, ils établissent trois types de modèles de base différents:
- Modèles basés sur le développement d'attributs;
- Modèles profonds basés sur les personnages
- Modèles basés sur des mots profonds.
Les auteurs ont utilisé des ensembles de données de référence accessibles au public (Zhang, Zhao et LeCun 2015) pour évaluer la méthode proposée. Au total, il existe six ensembles de données de texte de classification qui correspondent aux tâches d'analyse des humeurs, de classification des nouvelles, des questions et réponses et d'extraction des ontologies, respectivement. Dans l'article, ils montrent qu'EXAM obtient les meilleures performances parmi trois ensembles de données: AG, Yah. A. et DBP. L'évaluation et la comparaison avec d'autres méthodes sont visibles dans les tableaux ci-dessous.
![Précision de l'ensemble de tests [%] sur les tâches de classification de documents multi-classes et comparaison avec d'autres méthodes](https://habrastorage.org/getpro/habr/post_images/de7/8d8/b60/de78d8b6017c9624c347b0fb645ae0ae.png)

Conclusions
Ce travail est une contribution importante au domaine du traitement du langage naturel (PNL). Il s'agit du premier travail qui introduit des indices de correspondance au niveau des mots plus précis dans la classification de texte dans les modèles de réseaux de neurones profonds. Le modèle proposé fournit des indicateurs de pointe pour plusieurs ensembles de données.
Traduction - Stanislav Litvinov