Le premier commentaire sur le merveilleux article
Subjective Vision of an Ideal Programming Language s'est avéré être une référence au
langage de programmation Zig . Naturellement, il est devenu intéressant de savoir quel type de langage il s'agit, qui prétend être une niche de C ++, D et Rust. J'ai regardé - la langue semblait jolie et quelque peu intéressante. Belle syntaxe si-like, approche originale de la gestion des erreurs, coroutines intégrées. Cet article est un bref aperçu de la
documentation officielle entrecoupée de leurs propres réflexions et impressions d'exemples de code en cours d'exécution.
Pour commencer
L'installation du compilateur est assez simple, pour Windows, décompressez simplement le package de distribution dans un dossier. Nous créons un fichier texte hello.zig dans le même dossier, y insérons le code de la documentation et l'enregistrons. L'assemblage se fait par la commande
zig build-exe hello.zig
après quoi hello.exe apparaît dans le même répertoire.
En plus de l'assemblage, le mode de test unitaire est disponible; pour cela, des blocs de test sont utilisés dans le code, et l'assemblage et le lancement des tests sont effectués par
zig test hello.zig
Premières bizarreries
Le compilateur ne prend pas en charge les sauts de ligne Windows (\ r \ n). Bien sûr, le fait même que les sauts de ligne dans chaque système (Win, Nix, Mac) soient les leurs est une folie et une relique du passé. Mais il n'y a rien à faire, il suffit donc de sélectionner, par exemple, dans Notepad ++ le format que vous souhaitez pour le compilateur.
La deuxième bizarrerie que j'ai rencontrée par accident - les onglets ne sont pas pris en charge dans le code! Seuls les espaces. Mais ça arrive :)
Cependant, cela est honnêtement écrit dans la documentation - la vérité est déjà à la toute fin.
Commentaires
Une autre bizarrerie est que Zig ne prend pas en charge les commentaires sur plusieurs lignes. Je me souviens que tout était fait correctement dans l'ancien turbo pascal - les commentaires multi-lignes imbriqués étaient pris en charge. Apparemment, depuis lors, aucun développeur de langage n'a maîtrisé une chose aussi simple :)
Mais il y a des commentaires documentaires. Commencez par ///. Doit être à certains endroits - devant les objets correspondants (variables, fonctions, classes ...). S'ils sont ailleurs - une erreur de compilation. Pas mal.
Déclaration de variable
Fait dans le style à la mode maintenant (et idéologiquement correct), lorsque le mot clé (const ou var) est écrit en premier, puis le nom, puis éventuellement le type, puis la valeur initiale. C'est-à-dire l'inférence de type automatique est disponible. Les variables doivent être initialisées - si vous ne spécifiez pas de valeur initiale, il y aura une erreur de compilation. Cependant, une valeur spéciale non définie est fournie, qui peut être utilisée explicitement pour spécifier des variables non initialisées.
var i:i32 = undefined;
Sortie console
Pour les expériences, nous avons besoin d'une sortie vers la console - dans tous les exemples, c'est la méthode utilisée. Dans le domaine des plug-ins
const warn = std.debug.warn;
et le code est écrit comme ceci:
warn("{}\n{}\n", false, "hi");
Le compilateur a quelques bugs, qu'il rapporte honnêtement en essayant de sortir un entier ou un nombre à virgule flottante de cette manière:
erreur: bogue du compilateur: les littéraux entiers et flottants dans la fonction var args doivent être transtypés. github.com/ziglang/zig/issues/557
Types de données
Types primitifs
Les noms de type sont apparemment tirés de Rust (i8, u8, ... i128, u128), il existe également des types spéciaux pour la compatibilité binaire C, 4 types de types à virgule flottante (f16, f32, f64, f128). Il y a un type bool. Il y a un type de vide de longueur nulle et un retour de nor spécial, dont je parlerai plus tard.
Vous pouvez également construire des types entiers de n'importe quelle longueur en bits de 1 à 65535. Le nom du type commence par la lettre i ou u, puis la longueur en bits est écrite.
// ! var j:i65535 = 0x0123456789ABCDEF0123456789ABCDEF0123456789ABCDEF0123456789ABCDEF;
Cependant, je n'ai pas pu obtenir cette valeur sur la console - une erreur s'est produite dans le LLVM pendant le processus de compilation.
En général, c'est une solution intéressante, bien qu'ambiguë (à mon humble avis: prendre en charge des littéraux numériques exactement longs au niveau du compilateur, mais nommer les types de cette manière n'est pas très bon, il est préférable de le faire honnêtement via un type de modèle). Et pourquoi la limite est-elle de 65535? Des bibliothèques comme GMP ne semblent pas imposer de telles restrictions?
Littéraux de chaîne
Ce sont des tableaux de caractères (sans zéro à la fin). Pour les littéraux dont le zéro se termine, le préfixe «c» est utilisé.
const normal_bytes = "hello"; const null_terminated_bytes = c"hello";
Comme la plupart des langues, Zig prend en charge les séquences d'échappement standard et l'insertion de caractères Unicode via leurs codes (\ uNNNN, \ UNNNNNN où N est un chiffre hexadécimal).
Les littéraux multilignes sont formés à l'aide de deux barres obliques inverses au début de chaque ligne. Aucun guillemet n'est requis. Autrement dit, certains tentent de créer des lignes brutes, mais à mon humble avis - l'avantage des lignes brutes est que vous pouvez insérer n'importe quel morceau de texte de n'importe où dans le code - et, idéalement, ne change rien, mais ici, vous devez ajouter \\ au début de chaque ligne.
const multiline = \\#include <stdio.h> \\ \\int main(int argc, char **argv) { \\ printf("hello world\n"); \\ return 0; \\} ;
Littéraux entiers
Tout est dans des langues similaires. J'étais très heureux que pour les littéraux octaux, le préfixe 0o soit utilisé, et pas seulement zéro, comme en C. Les littéraux binaires avec le préfixe 0b sont également pris en charge. Les littéraux à virgule flottante peuvent être hexadécimaux (comme cela se fait dans
l'extension GCC ).
Les opérations
Bien sûr, il existe des opérations C arithmétiques, logiques et au niveau du bit standard. Les opérations abrégées sont prises en charge (+ = etc.). Au lieu de && et || les mots-clés et et ou sont utilisés. Un point intéressant est que les opérations avec une sémantique enveloppante garantie sont également prises en charge. Ils ressemblent à ceci:
a +% b a +%= b
Dans ce cas, les opérations arithmétiques ordinaires ne garantissent pas le débordement et leurs résultats pendant le débordement sont considérés comme indéfinis (et des erreurs de compilation sont générées pour les constantes). À mon humble avis, c'est un peu étrange, mais apparemment, il est fait à partir de certaines considérations profondes de compatibilité avec la sémantique du langage C.
Tableaux
Les littéraux de tableau ressemblent à ceci:
const msg = []u8{ 'h', 'e', 'l', 'l', 'o' }; const arr = []i32{ 1, 2, 3, 4 };
Les chaînes sont des tableaux de caractères, comme en C. Indexation classique avec crochets. Les opérations d'addition (concaténation) et de multiplication de tableaux sont fournies. C'est une chose très intéressante, et si tout est clair avec la concaténation, alors multiplication - j'ai continué d'attendre jusqu'à ce que quelqu'un implémente cela, et maintenant j'attends :) Dans Assembler (!) Il y a une telle opération de dup qui vous permet de générer des données en double. Maintenant à Zig:
const one = []i32{ 1, 2, 3, 4 }; const two = []i32{ 5, 6, 7, 8 }; const c = one ++ two; // { 1,2,3,4,5,6,7,8 } const pattern = "ab" ** 3; // "ababab"
Pointeurs
La syntaxe est similaire à C.
var x: i32 = 1234; // const x_ptr = &x; //
Pour le déréférencement (prise de valeurs par pointeur), une opération de suffixe inhabituelle est utilisée:
x_ptr.* == 5678; x_ptr.* += 1;
Le type de pointeur est défini explicitement en définissant un astérisque devant le nom du type
const x_ptr : *i32 = &x;
Tranches (tranches)
Une structure de données intégrée au langage qui vous permet de référencer un tableau ou une partie de celui-ci. Contient un pointeur sur le premier élément et le nombre d'éléments. Cela ressemble à ceci:
var array = []i32{ 1, 2, 3, 4 }; const slice = array[0..array.len];
Il semble provenir de Go, pas sûr. Et je ne sais pas non plus si cela valait la peine d'être incorporé dans une langue, alors que la mise en œuvre dans une langue OOP d'une telle chose est très élémentaire.
Structures
Une façon intéressante de déclarer une structure: une constante est déclarée, dont le type est automatiquement affiché comme "type" (type), et c'est elle qui est utilisée comme nom de la structure. Et la structure elle-même (struct) est "sans nom".
const Point = struct { x: f32, y: f32, };
Il est impossible de spécifier un nom de la manière habituelle dans les langages de type C, cependant, le compilateur affiche le nom du type selon certaines règles - en particulier, dans le cas considéré ci-dessus, il coïncidera avec le nom de la constante "type".
En général, la langue ne garantit pas l'ordre des champs et leur alignement en mémoire. Si des garanties sont nécessaires, des structures «packagées» doivent être utilisées.
const Point2 = packed struct { x: f32, y: f32, };
Initialisation - dans le style des désignateurs Sishny:
const p = Point { .x = 0.12, .y = 0.34, };
Les structures peuvent avoir des méthodes. Cependant, placer une méthode dans une structure consiste simplement à utiliser la structure comme espace de noms; contrairement à C ++, aucun paramètre implicite n'est transmis.
Transferts
En général, la même chose qu'en C / C ++. Il existe des moyens intégrés pratiques d'accéder aux méta-informations, par exemple le nombre de champs et leurs noms, implémentés par des macros de syntaxe intégrées au langage (appelées fonctions intégrées dans la documentation).
Pour la "compatibilité binaire avec C", certaines énumérations externes sont fournies.
Pour indiquer le type qui devrait sous-tendre l'énumération, une construction du formulaire
packed enum(u8)
où u8 est le type de base.
Les énumérations peuvent avoir des méthodes similaires aux structures (c'est-à-dire utiliser un nom d'énumération comme espace de noms).
Les syndicats
Si je comprends bien, l'union de Zig est une somme de type algébrique, c'est-à-dire contient un champ de balise masqué qui détermine lequel des champs d'union est «actif». L '«activation» d'un autre champ est réalisée par une réaffectation complète de l'ensemble de l'association. Exemple de documentation
const assert = @import("std").debug.assert; const mem = @import("std").mem; const Payload = union { Int: i64, Float: f64, Bool: bool, }; test "simple union" { var payload = Payload {.Int = 1234}; // payload.Float = 12.34; // ! assert(payload.Int == 1234); // payload = Payload {.Float = 12.34}; assert(payload.Float == 12.34); }
Les syndicats peuvent également utiliser explicitement des énumérations pour la balise.
// Unions can be given an enum tag type: const ComplexTypeTag = enum { Ok, NotOk }; const ComplexType = union(ComplexTypeTag) { Ok: u8, NotOk: void, };
Les unions, comme les énumérations et les structures, peuvent également fournir leur propre espace de noms pour les méthodes.
Types optionnels
Zig a un support optionnel intégré. Un point d'interrogation est ajouté avant le nom du type:
const normal_int: i32 = 1234; // normal integer const optional_int: ?i32 = 5678; // optional integer
Fait intéressant, Zig met en œuvre une chose à propos de la possibilité dont je soupçonnais, mais je ne savais pas si c'était vrai ou non. Les pointeurs sont rendus compatibles avec les options sans ajouter de champ caché supplémentaire («tag»), qui stocke un signe de la validité de la valeur; et null est utilisé comme valeur non valide. Ainsi, les types de référence représentés dans Zig par des pointeurs ne nécessitent même pas de mémoire supplémentaire pour le «caractère facultatif». Dans le même temps, l'attribution de valeurs nulles à des pointeurs réguliers est interdite.
Types d'erreur
Ils sont similaires aux types facultatifs, mais au lieu de la balise booléenne («vraiment invalide»), un élément d'énumération correspondant au code d'erreur est utilisé. La syntaxe est similaire aux options, un point d'exclamation est ajouté au lieu d'un point d'interrogation. Ainsi, ces types peuvent être utilisés, par exemple, pour retourner à partir de fonctions: soit le résultat de l'objet de l'opération réussie de la fonction est renvoyé, soit une erreur avec le code correspondant est renvoyée. Les types d'erreur sont une partie importante du système de gestion des erreurs en langage Zig, pour plus de détails, voir la section Gestion des erreurs.
Tapez void
Des variables comme void et les opérations avec elles sont possibles dans Zig
var x: void = {}; var y: void = {}; x = y;
aucun code n'est généré pour de telles opérations; ce type est principalement utile pour la métaprogrammation.
Il existe également un type c_void pour la compatibilité C.
Opérateurs et fonctions de contrôle
Ceux-ci incluent: blocs, commutateur, tandis que, pour, si, sinon, casser, continuer. Pour regrouper le code, des accolades standard sont utilisées. Seuls les blocs, comme en C / C ++, sont utilisés pour limiter la portée des variables. Les blocs peuvent être considérés comme des expressions. Il n'y a pas de goto dans le langage, mais il existe des étiquettes qui peuvent être utilisées avec les instructions break et continue. Par défaut, ces opérateurs fonctionnent avec des boucles; cependant, si un bloc a une étiquette, vous pouvez l'utiliser.
var y: i32 = 123; const x = blk: { y += 1; break :blk y; // blk y };
L'instruction switch diffère de l'opérateur en ce qu'elle n'a pas de "fallthrough", c'est-à-dire une seule condition (cas) est exécutée et le commutateur se ferme. La syntaxe est plus compacte: au lieu de la casse, la flèche "=>" est utilisée. Switch peut également être considéré comme une expression.
Les instructions while et if sont généralement les mêmes que dans tous les langages de type C. L'instruction for ressemble plus à foreach. Tous peuvent être considérés comme des expressions. Parmi les nouvelles fonctionnalités, while et for, ainsi que if, peuvent avoir un bloc else qui s'exécute s'il n'y a pas d'itération de boucle.
Et ici, il est temps de parler d'une caractéristique commune pour le commutateur, tandis que, qui est en quelque sorte emprunté au concept de boucles foreach - «capture» de variables. Cela ressemble à ceci:
while (eventuallyNullSequence()) |value| { sum1 += value; } if (opt_arg) |value| { assert(value == 0); } for (items[0..1]) |value| { sum += value; }
Ici, l'argument while est une certaine «source» de données, qui peut être facultative, pour for, un tableau ou une tranche, et une variable située entre deux lignes verticales contient une valeur «étendue» - c'est-à-dire, l'élément actuel du tableau ou de la tranche (ou un pointeur vers celui-ci), la valeur interne du type facultatif (ou un pointeur vers celui-ci).
Déclarations de report et d'erreur
Le relevé d'exécution différé emprunté à Go. Il fonctionne de la même manière - l'argument de cet opérateur est exécuté en quittant la portée dans laquelle l'opérateur est utilisé. De plus, l'opérateur errdefer est fourni, qui est déclenché si un type d'erreur avec un code d'erreur actif est renvoyé par la fonction. Cela fait partie du système de gestion des erreurs Zig d'origine.
Opérateur inaccessible
L'élément de la programmation contractuelle. Un mot-clé spécial, qui est mis là où la direction ne doit en aucun cas venir. S'il y arrive, dans les modes Debug et ReleaseSafe, une panique est générée et dans ReleaseFast, l'optimiseur rejette complètement ces branches.
noreturn
Techniquement, c'est un type compatible dans les expressions avec tout autre type. Cela est possible car un objet de ce type ne reviendra jamais. Puisque les opérateurs sont des expressions en Zig, un type spécial est nécessaire pour les expressions qui ne seront jamais évaluées. Cela se produit lorsque le côté droit de l'expression transfère irrévocablement le contrôle quelque part à l'extérieur. Pour de telles instructions, les boucles et les fonctions infinies qui ne renvoient jamais le contrôle sont interrompues, poursuivies, renvoyées, inaccessibles. À titre de comparaison, un appel à une fonction régulière (retour de contrôle) n'est pas un opérateur noreturn, car bien que le contrôle soit transféré à l'extérieur, il sera renvoyé au point d'appel tôt ou tard.
Ainsi, les expressions suivantes deviennent possibles:
fn foo(condition: bool, b: u32) void { const a = if (condition) b else return; @panic("do something with a"); }
La variable a obtient la valeur renvoyée par l'instruction if / else. Pour cela, les parties (à la fois if et else) doivent renvoyer une expression du même type. La partie if renvoie bool, la partie else est le type noreturn, qui est techniquement compatible avec n'importe quel type, par conséquent, le code se compile sans erreur.
Les fonctions
La syntaxe est classique pour les langues de ce type:
fn add(a: i8, b: i8) i8 { return a + b; }
En général, les fonctions semblent assez standard. Jusqu'à présent, je n'ai pas remarqué de signes de fonctions de première classe, mais ma connaissance du langage est très superficielle, je peux me tromper. Bien que cela n'ait peut-être pas encore été fait.
Une autre caractéristique intéressante est que dans Zig, ignorer les valeurs renvoyées ne peut être fait explicitement qu'en utilisant le trait de soulignement _
_ = foo();
Il y a une réflexion qui vous permet d'obtenir diverses informations sur la fonction
const assert = @import("std").debug.assert; test "fn reflection" { assert(@typeOf(assert).ReturnType == void); // assert(@typeOf(assert).is_var_args == false); // }
Exécution de code au moment de la compilation
Zig fournit une fonctionnalité puissante - exécutant du code écrit en zig au moment de la compilation. Pour que le code soit exécuté au moment de la compilation, enveloppez-le simplement dans un bloc avec le mot clé comptime. La même fonction peut être appelée à la fois au moment de la compilation et au moment de l'exécution, ce qui vous permet d'écrire du code universel. Bien sûr, il existe certaines limitations associées aux différents contextes du code. Par exemple, dans la documentation de nombreux exemples, comptime est utilisé pour vérifier le temps de compilation:
// array literal const message = []u8{ 'h', 'e', 'l', 'l', 'o' }; // get the size of an array comptime { assert(message.len == 5); }
Mais bien sûr, la puissance de cet opérateur est loin d'être pleinement dévoilée ici. Ainsi, dans la description du langage, un exemple classique de l'utilisation efficace des macros syntaxiques est donné - la mise en œuvre d'une fonction similaire à printf, mais en analysant la chaîne de format et en effectuant tous les types de vérification d'arguments nécessaires au stade de la compilation.
En outre, le mot comptime est utilisé pour indiquer les paramètres des fonctions de compilation, qui est similaire aux fonctions de modèle C ++.
fn max(comptime T: type, a: T, b: T) T { return if (a > b) a else b; }
Gestion des erreurs
Zig a inventé un système de gestion des erreurs original qui ne ressemblait pas aux autres langues. Cela peut être appelé «exceptions explicites» (dans cette langue, l'explicitness est généralement l'un des idiomes). Il ressemble également aux codes de retour Go, mais il fonctionne différemment.
Le système de traitement des erreurs Zig est basé sur des énumérations spéciales pour implémenter ses propres codes d'erreur (erreur) et construit sur leur base des «types d'erreur» (somme de type algébrique, combinant le type de fonction retourné et le code d'erreur).
Les énumérations d'erreur sont déclarées de la même manière que les énumérations régulières:
const FileOpenError = error { AccessDenied, OutOfMemory, FileNotFound, }; const AllocationError = error { OutOfMemory, };
Cependant, tous les codes d'erreur reçoivent des valeurs supérieures à zéro; en outre, si vous déclarez un code du même nom dans deux énumérations, il recevra la même valeur. Cependant, les conversions implicites entre différentes énumérations d'erreurs sont interdites.
Le mot-clé anyerror signifie une énumération qui inclut tous les codes d'erreur.
Comme les types facultatifs, le langage prend en charge la génération de types d'erreur à l'aide d'une syntaxe spéciale. Type! U64 est une forme abrégée de anyerror! U64, qui à son tour signifie une union (option), qui comprend le type u64 et le type anyerror (si je comprends bien, le code 0 est réservé pour indiquer l'absence d'erreur et la validité du champ de données, le reste des codes sont en fait des codes d'erreur).
Le mot clé catch vous permet de détecter l'erreur et de la transformer en valeur par défaut:
const number = parseU64(str, 10) catch 13;
Par conséquent, si une erreur se produit dans la fonction parseU64 renvoyant le type! U64, alors catch "l'interceptera" et renverra la valeur par défaut de 13.
Le mot-clé try vous permet de "transmettre" l'erreur au niveau supérieur (c'est-à-dire au niveau de la fonction appelante). Afficher le code
fn doAThing(str: []u8) !void { const number = try parseU64(str, 10); // ... }
équivalent à ceci:
fn doAThing(str: []u8) !void { const number = parseU64(str, 10) catch |err| return err; // ... }
Voici ce qui se produit: parseU64 est appelé, si une erreur en est renvoyée - il est intercepté par l'instruction catch, dans laquelle le code d'erreur est extrait à l'aide de la syntaxe "capture", placée dans la variable err, qui est renvoyée via! Void à la fonction appelante.
L'opérateur errdefer décrit précédemment fait également référence à la gestion des erreurs. Le code qui est un argument errdefer n'est exécuté que si la fonction renvoie une erreur.
Encore plus de possibilités. Utilisation du || vous pouvez fusionner des ensembles d'erreurs
const A = error{ NotDir, PathNotFound, }; const B = error{ OutOfMemory, PathNotFound, }; const C = A || B;
Zig fournit également des fonctionnalités telles que le suivi des erreurs. C'est quelque chose de similaire à une trace de pile, mais contenant des informations détaillées sur l'erreur qui s'est produite et sur la façon dont elle s'est propagée le long de la chaîne d'essai du lieu d'occurrence à la fonction principale du programme.
Ainsi, le système de gestion des erreurs dans Zig est une solution très originale, qui ne ressemble pas à des exceptions en C ++ ou à des codes de retour dans Go. Nous pouvons dire qu'une telle solution a un certain prix - 4 octets supplémentaires, qui doivent être retournés avec chaque valeur retournée; les avantages évidents sont une visibilité et une transparence absolues. Contrairement à C ++, ici, la fonction ne peut pas lever d'exception inconnue quelque part dans la profondeur de la chaîne d'appel. Tout ce que la fonction retourne - elle retourne explicitement et seulement explicitement.Coroutines
Zig a des coroutines intégrées. Ce sont des fonctions qui sont créées avec le mot-clé async, à l'aide desquelles les fonctions de l'allocateur et du désallocateur sont transférées (si je comprends bien, pour une pile supplémentaire). test "create a coroutine and cancel it" { const p = try async<std.debug.global_allocator> simpleAsyncFn(); comptime assert(@typeOf(p) == promise->void); cancel p; assert(x == 2); } async<*std.mem.Allocator> fn simpleAsyncFn() void { x += 1; }
async renvoie un objet spécial de type promesse-> T (où T est le type de retour de la fonction). En utilisant cet objet, vous pouvez contrôler la coroutine.Les niveaux les plus bas incluent les mots-clés suspendre, reprendre et annuler. En utilisant suspend, l'exécution de la coroutine est suspendue et transmise au programme appelant. La syntaxe du bloc suspendu est possible, tout à l'intérieur du bloc est exécuté jusqu'à ce que la coroutine soit réellement suspendue.resume prend un argument de type promise-> T et reprend l'exécution de la coroutine d'où elle a été suspendue.annuler libère la mémoire coroutine.Cette image montre le transfert de contrôle entre le programme principal (sous forme de test) et la coroutine. Tout est assez simple: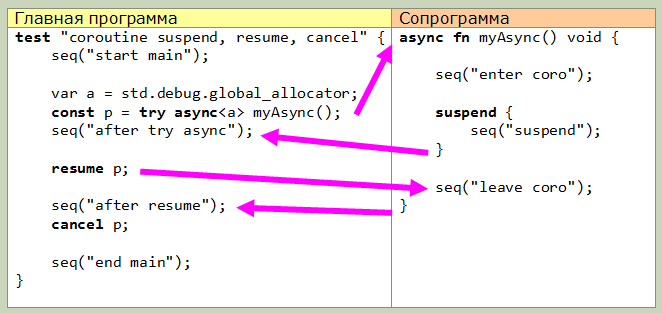 La deuxième caractéristique (niveau supérieur) est l'utilisation de l'attente. C'est la seule chose que, franchement, je n'ai pas compris (hélas, la documentation est encore très rare). Voici le schéma de transfert de contrôle réel d'un exemple légèrement modifié de la documentation, peut-être que cela vous expliquera quelque chose:
La deuxième caractéristique (niveau supérieur) est l'utilisation de l'attente. C'est la seule chose que, franchement, je n'ai pas compris (hélas, la documentation est encore très rare). Voici le schéma de transfert de contrôle réel d'un exemple légèrement modifié de la documentation, peut-être que cela vous expliquera quelque chose: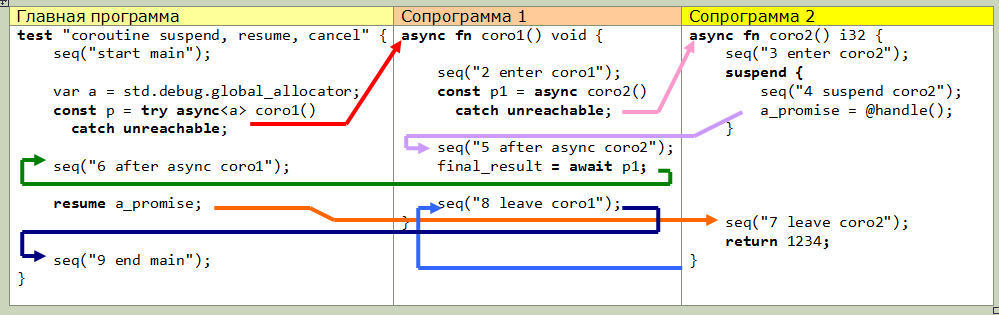
Fonctions intégrées
fonctions intégrées - un ensemble assez important de fonctions qui sont intégrées dans le langage et ne nécessitent la connexion d'aucun module. Il est peut-être plus correct d'appeler certaines d'entre elles des «macros syntaxiques intégrées», car les capacités de beaucoup vont bien au-delà des fonctions. les fonctions intégrées permettent d'accéder aux outils de réflexion (sizeOf, tagName, TagType, typeInfo, typeName, typeOf), avec leurs modules d'aide (importation) connectés. D'autres ressemblent davantage au C / C ++ intégré classique - ils implémentent des conversions de type bas niveau, diverses opérations telles que sqrt, popCount, slhExact, etc. Il est très probable que la liste des fonctions intégrées change au fur et à mesure que le langage se développe.En conclusion
Il est très agréable que de tels projets apparaissent et se développent. Bien que le langage C soit pratique, concis et familier à beaucoup, il est toujours dépassé et, pour des raisons architecturales, ne peut pas prendre en charge de nombreux concepts de programmation modernes. Le C ++ se développe, mais objectivement repensé, il devient de plus en plus difficile avec chaque nouvelle version, et pour les mêmes raisons architecturales et en raison du besoin de compatibilité descendante, rien ne peut être fait à ce sujet. La rouille est intéressante, mais avec un seuil d'entrée très élevé, ce qui n'est pas toujours justifié. D est une bonne tentative, mais il y a quelques failles mineures, il semble qu'au départ le langage a été créé plus probablement sous l'influence de Java, et les fonctionnalités suivantes ont été introduites d'une manière ou d'une autre pas comme elles le devraient. De toute évidence, Zig est une autre de ces tentatives. La langue est intéressante, et c'est intéressant de voir ce qui en sort.