TL; DR: GitHub: // PastorGL / AQLSelectEx .
Une fois, pas pendant la saison froide, mais déjà en hiver, et en particulier il y a quelques mois, pour un projet sur lequel je travaillais (quelque chose de géospatial basé sur le Big Data), j'avais besoin d'un stockage rapide NoSQL / Key-Value.
Nous mâchons des téraoctets de codes sources avec l'aide d'Apache Spark, mais le résultat final des calculs, réduit à une quantité ridicule (seulement des millions d'enregistrements), doit être stocké quelque part. Et il est très souhaitable de le stocker de telle manière qu'il puisse être rapidement trouvé et envoyé en utilisant des métadonnées associées à chaque ligne du résultat (c'est un chiffre) (mais il y en a beaucoup).
Les formats de la pile Khadupov dans ce sens sont de peu d'utilité, et les bases de données relationnelles sur des millions d'enregistrements ralentissent, et l'ensemble de métadonnées n'est pas suffisamment fixe pour s'insérer bien dans le schéma rigide d'un SGBDR ordinaire - PostgreSQL dans notre cas. Non, il prend normalement en charge JSON, mais il a toujours des problèmes avec les index sur des millions d'enregistrements. Les index gonflent, il devient nécessaire de partitionner la table, et un tel tracas avec l'administration commence que nafig-nafig.
Historiquement, MongoDB était utilisé comme NoSQL sur le projet, mais au fil du temps, la monga se montre de pire en pire (surtout en termes de stabilité), elle a donc été progressivement déclassée. Une recherche rapide pour une alternative plus moderne, plus rapide, moins buggy et généralement meilleure a conduit à Aerospike . Beaucoup de gars à grosse tête sont en faveur, et j'ai décidé de vérifier.
Les tests ont montré qu'en fait, les données sont stockées dans l'histoire directement à partir du travail Spark avec un sifflet, et la recherche dans plusieurs millions d'enregistrements est beaucoup plus rapide que dans le mong. Et elle mange moins de mémoire. Mais il s'est avéré un "mais". L'API client de la soudure aéro est purement fonctionnelle et non déclarative.
Pour l'enregistrement dans l'histoire, ce n'est pas important, car tout de même, tous les types de champs de chaque enregistrement résultant doivent être déterminés localement dans le travail lui-même - et le contexte n'est pas perdu. Le style fonctionnel est en place ici, d'autant plus que l'écriture d'un code d'une manière différente ne fonctionnera pas. Mais dans le museau Web, qui devrait télécharger le résultat dans le monde extérieur, et qui est une application Web ordinaire de printemps, il serait beaucoup plus logique de former un SQL SELECT standard à partir d'un formulaire utilisateur, dans lequel il serait rempli de ET et OU - c'est-à-dire de prédicats , - dans la clause WHERE.
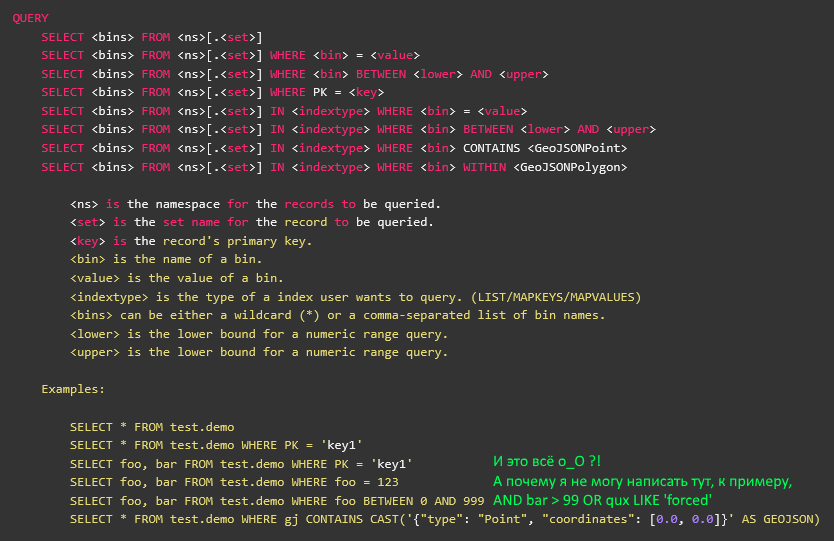
Je vais expliquer la différence avec un tel exemple synthétique:
SELECT foo, bar, baz, qux, quux FROM namespace.set WITH (baz!='a') WHERE (foo>2 AND (bar<=3 OR foo>5) AND quux LIKE '%force%') OR NOT (qux WITHIN CAST('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}' AS GEOJSON)
- les enregistrements que le client souhaite recevoir sont à la fois lisibles et relativement clairs. Si vous jetez une telle demande directement dans le journal, vous pouvez la retirer ultérieurement pour le débogage manuellement. Ce qui est très pratique pour analyser toutes sortes de situations étranges.
Examinons maintenant l'appel à l'API de prédicat dans un style fonctionnel:
Statement reference = new Statement(); reference.setSetName("set"); reference.setNamespace("namespace"); reference.setBinNames("foo", "bar", "baz", "qux", "quux"); reference.setFillter(Filter.stringNotEqual("baz", "a")); reference.setPredExp(
Voici le mur de code, et même en notation polonaise inversée . Non, je comprends que la machine à empiler est simple et pratique à mettre en œuvre du point de vue du programmeur du moteur lui-même, mais pour énigmer et écrire des prédicats en RPN à partir de l'application cliente ... Personnellement, je ne veux pas penser au fournisseur, je me veux en tant que consommateur de cette API C'était pratique. Et les prédicats, même avec une extension client du fournisseur (conceptuellement similaire à l'API Java Persistence Criteria), ne sont pas pratiques à écrire. Et il n'y a toujours pas de SELECT lisible dans le journal des requêtes.
En général, SQL a été inventé pour y écrire des requêtes basées sur des critères dans un langage d'oiseau, proche du naturel. Alors, on se demande, c'est quoi ce bordel?
Attendez, quelque chose ne va pas ... Sur le KDPV, y a-t-il une capture d'écran de la documentation officielle de l'aérosol, sur laquelle SELECT est complètement décrit?
Oui, décrit. C'est juste AQL - il s'agit d'un utilitaire tiers écrit par le pied arrière gauche lors d'une nuit sombre, et abandonné par le fournisseur il y a trois ans lors de la version précédente de l'aérosol. Cela n'a rien à voir avec la bibliothèque cliente, bien qu'il soit écrit sur un crapaud - y compris.
La version d'il y a trois ans n'avait pas d'API de prédicat, et donc dans AQL il n'y a pas de support pour les prédicats, et tout cela après WHERE est en fait un appel à l'index (secondaire ou primaire). Eh bien, c'est plus proche de l'extension SQL comme USE ou WITH. Autrement dit, vous ne pouvez pas simplement prendre des sources AQL, les démonter en pièces détachées et les utiliser dans votre application pour les appels de prédicat.
De plus, comme je l'ai dit, il a été écrit dans la nuit noire avec le pied arrière gauche, et il est impossible de regarder la grammaire ANTLR4, pour laquelle AQL analyse la requête sans larmes. Eh bien, à mon goût. Pour une raison quelconque, j'adore quand la définition déclarative de la grammaire n'est pas mélangée avec des morceaux de code de crapaud et que des nouilles très cool y sont brassées.
Eh bien, heureusement, je semble aussi savoir comment faire ANTLR. Certes, pendant longtemps, je n'ai pas pris de vérificateur, et la dernière fois que je l'ai écrit sous la troisième version. Quatrièmement - c'est beaucoup plus agréable, car qui veut écrire une visite AST manuelle, si tout a été écrit avant nous, et qu'il y a un visiteur normal, alors commençons.
Nous prenons la syntaxe SQLite comme base et essayons de supprimer tout ce qui n'est pas nécessaire. Nous n'avons besoin que de SELECT, et rien de plus.
grammar SQLite; simple_select_stmt : ( K_WITH K_RECURSIVE? common_table_expression ( ',' common_table_expression )* )? select_core ( K_ORDER K_BY ordering_term ( ',' ordering_term )* )? ( K_LIMIT expr ( ( K_OFFSET | ',' ) expr )? )? ; select_core : K_SELECT ( K_DISTINCT | K_ALL )? result_column ( ',' result_column )* ( K_FROM ( table_or_subquery ( ',' table_or_subquery )* | join_clause ) )? ( K_WHERE expr )? ( K_GROUP K_BY expr ( ',' expr )* ( K_HAVING expr )? )? | K_VALUES '(' expr ( ',' expr )* ')' ( ',' '(' expr ( ',' expr )* ')' )* ; expr : literal_value | BIND_PARAMETER | ( ( database_name '.' )? table_name '.' )? column_name | unary_operator expr | expr '||' expr | expr ( '*' | '/' | '%' ) expr | expr ( '+' | '-' ) expr | expr ( '<<' | '>>' | '&' | '|' ) expr | expr ( '<' | '<=' | '>' | '>=' ) expr | expr ( '=' | '==' | '!=' | '<>' | K_IS | K_IS K_NOT | K_IN | K_LIKE | K_GLOB | K_MATCH | K_REGEXP ) expr | expr K_AND expr | expr K_OR expr | function_name '(' ( K_DISTINCT? expr ( ',' expr )* | '*' )? ')' | '(' expr ')' | K_CAST '(' expr K_AS type_name ')' | expr K_COLLATE collation_name | expr K_NOT? ( K_LIKE | K_GLOB | K_REGEXP | K_MATCH ) expr ( K_ESCAPE expr )? | expr ( K_ISNULL | K_NOTNULL | K_NOT K_NULL ) | expr K_IS K_NOT? expr | expr K_NOT? K_BETWEEN expr K_AND expr | expr K_NOT? K_IN ( '(' ( select_stmt | expr ( ',' expr )* )? ')' | ( database_name '.' )? table_name ) | ( ( K_NOT )? K_EXISTS )? '(' select_stmt ')' | K_CASE expr? ( K_WHEN expr K_THEN expr )+ ( K_ELSE expr )? K_END | raise_function ;
Hmm ... Tant pis pour SELECT trop. Et s'il est assez facile de se débarrasser de l'excès, il y a une autre mauvaise chose concernant la structure même de la solution de contournement résultante.
Le but ultime est de traduire dans l'API prédicat avec son RPN et la machine de pile implicite. Et ici, l'expr atomique ne contribue en aucune façon à une telle transformation, car elle implique une analyse normale de gauche à droite. Oui, et récursivement défini.
Autrement dit, nous pouvons obtenir notre exemple synthétique, mais il sera lu exactement tel qu'il est écrit, de gauche à droite:
(foo>2 (bar<=3 foo>5) quux _ '%force%') (qux _('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}')
Il existe des crochets qui déterminent la priorité de l'analyse (ce qui signifie que vous devez faire des va-et-vient sur la pile), et certains opérateurs se comportent comme des appels de fonction.
Et nous avons besoin de cette séquence:
foo 2 > bar 3 <= foo 5 > quux ".*force.*" _ qux "{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}" _
Brr, étain, pauvre cerveau à lire. Mais sans crochets, il n'y a pas de retour en arrière et de malentendus avec l'ordre de l'appel. Et comment nous traduisons-nous l'un dans l'autre?
Et puis dans un cerveau pauvre, un choc arrive! - Bonjour, ceci est un chantier de triage classique de beaucoup. prof. Dijkstra! Habituellement, les chamans okolobigdatovskih comme moi n'ont pas besoin d'algorithmes, car nous transférons simplement les prototypes déjà écrits par les satanistes de données de python au crapaud, puis pour une performance longue et fastidieuse de la solution obtenue par des méthodes purement techniques (== chamaniques), et non scientifiques .
Mais soudain, il est devenu nécessaire de connaître l'algorithme. Ou du moins une idée de cela. Heureusement, tout le cursus universitaire n'a pas été oublié au cours des dernières années, et depuis que je me souviens des machines empilées, je peux aussi découvrir autre chose sur les algorithmes associés.
Ok Dans une grammaire aiguisée par Shunting Yard, un SELECT au niveau supérieur ressemblerait à ceci:
select_stmt : K_SELECT ( STAR | column_name ( COMMA column_name )* ) ( K_FROM from_set )? ( (K_USE | K_WITH) index_expr )? ( K_WHERE where_expr )? ; where_expr : ( atomic_expr | OPEN_PAR | CLOSE_PAR | logic_op )+ ; logic_op : K_NOT | K_AND | K_OR ; atomic_expr : column_name ( equality_op | regex_op ) STRING_LITERAL | ( column_name | meta_name ) ( equality_op | comparison_op ) NUMERIC_LITERAL | column_name map_op iter_expr | column_name list_op iter_expr | column_name geo_op cast_expr ;
Autrement dit, les jetons correspondant aux crochets sont importants et il ne devrait pas y avoir d'expr récursive. Au lieu de cela, il y aura un tas de tous les private_expr, et tous sont finis.
Dans le code sur le crapaud, qui implémente le visiteur pour cet arbre, les choses sont un peu plus addictives - en stricte conformité avec l'algorithme, qui traite lui-même le logic_op suspendu et équilibre les crochets. Je ne donnerai pas d'extrait ( regardez le CG vous-même), mais je donnerai la considération suivante.
Il devient clair pourquoi les auteurs de la pointe aérodynamique ne se sont pas souciés de la prise en charge des prédicats dans AQL, et l'ont abandonné il y a trois ans. Parce qu'il est strictement typé, et le pic aéro lui-même est présenté comme une histoire sans schéma. Et il est donc impossible de prendre et de vider une requête de SQL nu sans un schéma prédéterminé. Oups
Mais nous, les gars, sommes brûlés et, surtout, arrogants. Nous avons besoin d'un schéma avec des types de champs, donc il y aura un schéma avec des types de champs. De plus, la bibliothèque cliente possède déjà toutes les définitions nécessaires, il suffit de les récupérer. Bien que je devais écrire beaucoup de code pour chaque type (voir le même lien, à partir de la ligne 56).
Maintenant, initialisez ...
final HashMap FOO_BAR_BAZ = new HashMap() {{ put("namespace.set0", new HashMap() {{ put("foo", ParticleType.INTEGER); put("bar", ParticleType.DOUBLE); put("baz", ParticleType.STRING); put("qux", ParticleType.GEOJSON); put("quux", ParticleType.STRING); put("quuux", ParticleType.LIST); put("corge", ParticleType.MAP); put("corge.uier", ParticleType.INTEGER); }}); put("namespace.set1", new HashMap() {{ put("grault", ParticleType.INTEGER); put("garply", ParticleType.STRING); }}); }}; AQLSelectEx selectEx = AQLSelectEx.forSchema(FOO_BAR_BAZ);
... et le tour est joué, notre requête synthétique se contente simplement et clairement de l'aérosol:
Statement statement = selectEx.fromString("SELECT foo,bar,baz,qux,quux FROM namespace.set WITH (baz='a') WHERE (foo>2 AND (bar <=3 OR foo>5) AND quux LIKE '%force%') OR NOT (qux WITHIN CAST('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}' AS GEOJSON)");
Et pour convertir le formulaire du museau Web en demande elle-même, nous récupérons une tonne de code écrit il y a longtemps dans le museau Web ... quand il arrive enfin au projet, sinon le client l'a mis sur l'étagère pour l'instant. C'est dommage, bon sang, j'ai passé presque une semaine de temps.
J'espère que je l'ai dépensé avec avantage, et la bibliothèque AQLSelectEx sera utile à quelqu'un, et l'approche elle-même sera un tutoriel un peu plus réaliste que d'autres articles du hub traitant d'ANTLR.