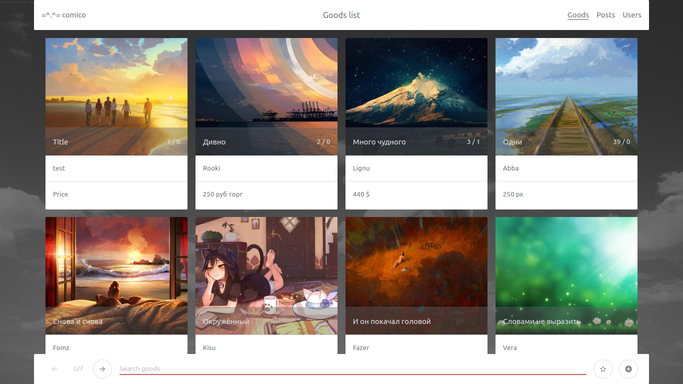
Bonjour à tous, je souhaite partager le résultat de mes réflexions sur ce que peut être une application web moderne. Par exemple, envisagez de concevoir un babillard pour les bandes dessinées. Dans un sens, le produit en question est conçu pour un public de geeks et sympathisants, ce qui vous permet de faire preuve de liberté dans l'interface. Dans la composante technique, au contraire, une attention aux détails est nécessaire.
En vérité, je ne comprends rien dans les bandes dessinées, mais j'adore les marchés aux puces, surtout au format forum, qui étaient populaires dans le zéro. Par conséquent, l'hypothèse (peut-être fausse), dont découlent les conclusions suivantes, n'est qu'une - le principal type d'interaction avec l'application est la visualisation, le secondaire - la publication d'annonces et de discussions.
Notre objectif sera de créer une application simple, sans savoir-faire technique des sifflets supplémentaires, cependant, conformes aux réalités modernes. Les principales exigences que j'aimerais atteindre sont:
Côté serveur:
a) Effectue les fonctions de stockage, de validation, d'envoi de données utilisateur au client
b) Les opérations ci-dessus consomment une quantité acceptable de ressources (temps, y compris)
c) L'application et les données sont protégées des vecteurs d'attaque populaires
d) Il dispose d'une API simple pour les clients tiers et l'interaction entre serveurs
e) Déploiement multiplateforme et simple
Côté client:
a) Fournit les fonctionnalités nécessaires pour créer et consommer du contenu
b) L'interface est pratique pour une utilisation régulière, le chemin minimum vers toute action, la quantité maximale de données par écran
c) Hors communication avec le serveur, toutes les fonctions disponibles dans cette situation sont disponibles
d) L'interface affiche la version actuelle de l'état et du contenu, sans redémarrage ni attente
d) Le redémarrage de l'application n'affecte pas son état
f) Si possible, réutilisez les éléments DOM et le code JS
g) Nous n'utiliserons pas de bibliothèques et de frameworks tiers lors de l'exécution
h) La mise en page est sémantique pour l'accessibilité, les analyseurs, etc.
i) La navigation du contenu principal est accessible via l'URL et le clavier
À mon avis, les exigences logiques et la plupart des applications modernes à un degré ou un autre remplissent ces conditions. Voyons ce qui se passe avec nous (lien vers la source et la démo à la fin du post).
Avertissements:- Je tiens à m'excuser auprès des auteurs inconnus des images utilisées dans la démo sans autorisation, ainsi qu'à Gösse G., Prozorovskaya B. D. et à la maison d'édition "Library of Florence Pavlenkov" pour avoir utilisé des extraits de l'ouvrage "Siddhartha".
- L'auteur n'est pas un vrai programmeur, je ne recommande pas d'utiliser le code ou les techniques utilisées dans ce projet si vous ne savez pas ce que vous faites.
- Je m'excuse pour le style du code; il aurait pu être écrit de manière plus lisible et évidente, mais ce n'est pas amusant. Un projet pour l'âme et pour un ami, comme on dit.
- Je m'excuse également pour le taux d'alphabétisation, en particulier dans le texte anglais. Les années parlent de May Hart.
- Les performances du prototype présenté ont été testées en [chrome 70; linux x86_64; 1366x768], je serai extrêmement reconnaissant aux utilisateurs d'autres plates-formes et appareils pour les messages d'erreur.
- Il s'agit d'un prototype et d'un sujet de discussion proposé - approches et principes, je demande que toutes les critiques de la mise en œuvre et du côté esthétique soient accompagnées d'arguments.
Serveur
La langue du serveur est le golang. Un langage simple et rapide avec une excellente bibliothèque et documentation standard ... un peu ennuyeux. Le choix initial s'est porté sur elixir / erlang, mais comme je connaissais déjà go (relativement), il a été décidé de ne pas le compliquer (et les packages nécessaires n'étaient que pour go).
L'utilisation de cadres Web dans la communauté go n'est pas encouragée (à juste titre, cela vaut la peine d'être admis), nous choisissons un compromis et utilisons le microframework labstack / echo , réduisant ainsi la quantité de routine et, il me semble, ne perd pas beaucoup de performances.
Nous utilisons tidwall / buntdb comme base de données. Premièrement, la solution intégrée est plus pratique et réduit les frais généraux, et deuxièmement, en mémoire + clé / valeur - à la mode, élégant Rapide et sans cache nécessaire. Nous stockons et fournissons des données dans JSON, validant uniquement lors de la modification.
Sur l'i3 de deuxième génération, l'enregistreur intégré affiche le temps d'exécution pour différentes requêtes de 0,5 à 10 ms. L'exécution de wrk sur la même machine donne également des résultats suffisants pour nos besoins:
➜ comico git:(master) wrk -t2 -c500 -d60s http://localhost:9001/pub/mtimes Running 1m test @ http://localhost:9001/pub/mtimes 2 threads and 500 connections Thread Stats Avg Stdev Max +/- Stdev Latency 20.74ms 16.68ms 236.16ms 72.69% Req/Sec 13.19k 627.43 15.62k 73.58% 1575522 requests in 1.00m, 449.26MB read Requests/sec: 26231.85 Transfer/sec: 7.48MB
➜ comico git:(master) wrk -t2 -c500 -d60s http://localhost:9001/pub/goods Running 1m test @ http://localhost:9001/pub/goods 2 threads and 500 connections Thread Stats Avg Stdev Max +/- Stdev Latency 61.79ms 65.96ms 643.73ms 86.48% Req/Sec 5.26k 705.24 7.88k 70.31% 628215 requests in 1.00m, 8.44GB read Requests/sec: 10454.44 Transfer/sec: 143.89MB
Structure du projet
Le package comico / model est divisé en trois fichiers:
model.go - contient une description des types de données et des fonctions générales: création / mise à jour (buntdb ne fait pas de distinction entre ces opérations et nous vérifions la présence d'un enregistrement manuellement), validation, suppression, obtention d'un enregistrement et obtention d'une liste;
rules.go - contient des règles de validation pour un type spécifique et une fonction de journalisation;
files.go - travailler avec des images.
Le type Mtimes stocke des données sur le dernier changement des types restants dans la base de données, informant ainsi le client quelles données ont changé.
Le package comico / bd contient des fonctions généralisées pour interagir avec la base de données: création, suppression, sélection, etc. Buntdb enregistre toutes les modifications apportées à un fichier (dans notre cas, une fois par seconde), au format texte, ce qui est pratique dans certaines situations. Le fichier db n'est pas édité, les modifications en cas de succès de la transaction sont ajoutées à la fin. Toutes mes tentatives pour violer l'intégrité des données ont échoué, dans le pire des cas, les modifications de la dernière seconde sont perdues.
Dans notre implémentation, chaque type correspond à une base de données distincte dans un fichier séparé (à l'exception des journaux qui sont stockés exclusivement en mémoire et sont remis à zéro au redémarrage). Cela est en grande partie dû à la commodité de la sauvegarde et de l'administration, un petit plus - une transaction ouverte pour l'édition bloque l'accès à un seul type de données.
Ce package peut être facilement remplacé par un package similaire en utilisant une autre base de données, SQL, par exemple. Pour ce faire, il suffit d'implémenter les fonctions suivantes:
func Delete(db byte, key string) error func Exist(db byte, key string) bool func Insert(db byte, key, val string) error func ReadAll(db byte, pattern string) (str string, err error) func ReadOne(db byte, key string) (str string, err error) func Renew(db byte, key string) (err error, newId string)
Le package comico / cnst contient certaines constantes nécessaires dans tous les packages (types de données, types d'actions, types d'utilisateurs). De plus, ce paquet contient tous les messages lisibles par l'homme avec lesquels notre serveur répondra au monde extérieur.
Le package comico / server contient des informations de routage. De plus, seulement quelques lignes (grâce aux développeurs Echo), l'autorisation utilisant JWT, CORS, les en-têtes CSP, l'enregistreur, la distribution statique, gzip, le certificat automatique ACME, etc. sont configurées.
Points d'entrée API
| URL | Les données | La description |
|---|
| get / pub / (marchandises | messages | utilisateurs | cmnts | fichiers) | - | Obtention d'un éventail d'annonces, de publications, d'utilisateurs, de commentaires et de fichiers pertinents |
| get / pub / mtimes | - | Obtention de la dernière heure de modification pour chaque type de données |
| poste / pub / connexion | {id *: login, pass *: mot de passe} | Renvoie le jeton JWT et sa durée |
| poste / pub / pass | {id *, pass *} | Crée un nouvel utilisateur si les données sont correctes |
| mettre / api / passer | {id *, pass *} | Mise à jour du mot de passe |
| post | put / api / goods | {id *, auth *, title *, type *, price *, text *, images: [], Table: {key: value}} | Créer / mettre à jour l'annonce |
| post | put / api / posts | {id *, auth *, title *, type *, text *} | Créer / mettre à jour le message du forum |
| post | put / api / utilisateurs | {id *, titre, type, statut, scribes: [], ignore: [], Table: {clé: valeur}} | Créer / mettre à jour un utilisateur |
| post / api / cmnts | {id *, auth *, propriétaire *, tapez *, à, texte *} | Création de commentaire |
| supprimer / api / (marchandises | messages | utilisateurs | cmnts) / [id] | - | Supprime une entrée avec id |
| obtenir / api / activité | - | Met à jour la dernière heure de lecture des commentaires entrants pour l'utilisateur actuel |
| obtenir / api / (s'abonner | ignorer) / [tag] | - | Ajoute ou supprime (le cas échéant) une balise à l'utilisateur dans la liste des abonnements / ignore |
| post / api / upload / (marchandises | utilisateurs) | multipart (nom, fichier) | Télécharge des annonces photo / avatar d'utilisateur |
* - champs obligatoires
api - nécessite une autorisation, pub - non
Avec une requête get qui ne correspond pas à ce qui précède, le serveur recherche un fichier dans le répertoire pour la statique (par exemple, / img / * - images, /index.html - le client).
Tout point API renverra un code de réponse 200 en cas de succès, 400 ou 404 pour une erreur et un court message si nécessaire.
Les droits d'accès sont simples: la création d'une entrée est disponible pour un utilisateur autorisé, la modification pour l'auteur et le modérateur, l'administrateur peut modifier et nommer des modérateurs.
L'API est équipée de l'anti-vandalisme le plus simple: les actions sont enregistrées avec l'ID utilisateur et l'IP, et, en cas d'accès fréquent, une erreur est renvoyée vous demandant d'attendre un peu (utile contre la devinette du mot de passe).
Client
J'aime le concept de web'a réactif, je pense que la plupart des sites / applications modernes doivent se faire soit dans le cadre de ce concept, soit complètement statiques. D'un autre côté, un simple site avec des mégaoctets de code JS ne peut que déprimer. À mon avis, ce problème (et pas seulement) peut être résolu par Svelte. Ce framework (ou plutôt le langage pour construire des interfaces réactives) n'est pas inférieur à Vue dans la fonctionnalité nécessaire, mais il a un avantage indéniable - les composants sont compilés dans vanilla JS, ce qui réduit à la fois la taille du bundle et la charge sur la machine virtuelle (bundle.min.js.gz notre marché aux puces est modeste, selon les normes actuelles, 24 Ko). Les détails peuvent être trouvés dans la documentation officielle.
Nous choisissons le marché aux puces SvelteJS pour le côté client du marché aux puces, nous souhaitons tout le meilleur à Rich Harris et la poursuite du développement du projet!
PS Je ne veux offenser personne. Je suis sûr que chaque spécialiste et chaque projet a ses propres outils.
Client / Données
URL
Nous utilisons pour la navigation. Nous ne simulerons pas un document de plusieurs pages; nous utilisons plutôt des pages de hachage avec des paramètres de requête. Pour les transitions, vous pouvez utiliser le <a> habituel sans js.
Les sections correspondent aux types de données: / # marchandises , / # publications , / # utilisateurs .
Paramètres :? Id = record_id,? Page = page_number,? Search = search_query .
Quelques exemples:
- / # posts? id = 1542309643 & page = 999 & search = {auth: anon} - section posts , id poste - 1542309643 , page de commentaires - 999 , requête de recherche - {auth: anon}
- / # goods? page = 2 & search = siddhartha - section articles , section page - 2 , requête de recherche - siddhartha
- / # goods? search = wer {key: value} t - marchandises de section, requête de recherche - consiste à rechercher la sous-chaîne wert dans l'en-tête ou le texte de l'annonce et la valeur de la sous-chaîne dans la propriété key de la partie tabulaire de l'annonce
- / # goods? search = {model: 100, display: 256} - Je pense que tout est clair ici par analogie
Les fonctions d'analyse et de génération d'URL dans notre implémentation ressemblent à ceci:
window.addEventListener('hashchange', function() { const hash = location.hash.slice(1).split('?'), result = {} if (!!hash[1]) hash[1].split('&').forEach(str => { str = str.split('=') if (!!str[0] && !!str[1]) result[decodeURI(str[0]).toLowerCase()] = decodeURI(str[1]).toLowerCase() }) result.type = hash[0] || 'goods' store.set({ hash: result }) }) function goto({ type, id, page, search }) { const { hash } = store.get(), args = arguments[0], query = [] new Array('id', 'page', 'search').forEach(key => { const value = args[key] !== undefined ? args[key] : hash[key] || null if (value !== null) query.push(key + '=' + value) }) location.hash = (type || hash.type || 'goods') + (!!query.length ? '?' + query.join('&') : '') }
API
Pour échanger des données avec le serveur, nous utiliserons l'api fetch. Pour télécharger des enregistrements mis à jour à de courts intervalles, nous faisons une demande à / pub / mtimes , si l'heure de la dernière modification pour n'importe quel type diffère de celle locale, nous chargeons une liste de ce type. Oui, il était possible d'implémenter la notification des mises à jour via SSE ou WebSockets et le chargement incrémentiel, mais dans ce cas, nous pouvons nous en passer. Qu'avons-nous obtenu:
async function GET(type) { const response = await fetch(location.origin + '/pub/' + type) .catch(() => ({ ok: false })) if (type === 'mtimes') store.set({ online: response.ok }) return response.ok ? await response.json() : [] } async function checkUpdate(type, mtimes, updates = {}) { const local = store.get()._mtimes, net = mtimes || await GET('mtimes') if (!net[type] || local[type] === net[type]) return const value = updates['_' + type] = await GET(type) local[type] = net[type]; updates._mtimes = local if (!!value && !!value.sort) store.set(updates) } async function checkUpdates() { setTimeout(() => checkUpdates(), 30000) const mtimes = await store.GET('mtimes') new Array('users', 'goods', 'posts', 'cmnts', 'files') .forEach(type => checkUpdate(type, mtimes)) }
Pour le filtrage et la pagination, nous utilisons les propriétés calculées de Svelte, basées sur les données de navigation. La direction des valeurs calculées est la suivante: items (tableaux d'enregistrements provenant du serveur) => ignoredItems (enregistrements filtrés en fonction de la liste d' ignorance de l'utilisateur actuel) => scribedItems (filtre les enregistrements en fonction de la liste des abonnements, si activés) => curItem et curItems (calcule les enregistrements actuels selon la section) => filterItems (filtre les enregistrements en fonction de la requête de recherche, s'il n'y a qu'un seul enregistrement - filtre les commentaires) => maxPage (calcule le nombre de pages au taux de 12 enregistrements / commentaires par page) => pagedItem (renvoie le tableau final avec messages / commentaires basés sur le numéro de page actuel).
Les commentaires et les images ( commentaires et _images ) sont calculés séparément, regroupés par type et enregistrement de propriétaire.
Les calculs se produisent automatiquement et uniquement lorsque les données associées changent, les données intermédiaires sont constamment en mémoire. À cet égard, nous tirons une conclusion désagréable - pour une grande quantité d'informations et / ou sa mise à jour fréquente, une grande quantité de ressources peut être dépensée.
Cache
Conformément à la décision de faire une application hors ligne, nous implémentons le stockage des enregistrements et certains aspects de l'état dans localStorage, les fichiers image dans CacheStorage. Travailler avec localStorage est extrêmement simple, nous convenons que les propriétés avec le préfixe "_" sont automatiquement enregistrées et restaurées au redémarrage lorsqu'elles sont modifiées. Ensuite, notre solution peut ressembler à ceci:
store.on('state', ({ changed, current }) => { Object.keys(changed).forEach(prop => { if (!prop.indexOf('_')) localStorage.setItem(prop, JSON.stringify(current[prop])) }) }) function loadState(state = {}) { for (let i = 0; i < localStorage.length; i++) { const prop = localStorage.key(i) const value = JSON.parse(localStorage.getItem(prop) || 'null') if (!!value && !prop.indexOf('_')) state[prop] = value } store.set(state) }
Les fichiers sont un peu plus compliqués. Tout d'abord, nous utiliserons la liste de tous les fichiers pertinents (avec l'heure de création) provenant du serveur. Lors de la mise à jour de cette liste, nous la comparons avec les anciennes valeurs, mettons les nouveaux fichiers dans CacheStorage, supprimons ceux qui sont obsolètes à partir de là:
async function cacheImages(newFiles) { const oldFiles = JSON.parse(localStorage.getItem('_files') || '[]') const cache = await caches.open('comico') oldFiles.forEach(file => { if (!~newFiles.indexOf(file)) { const [ id, type ] = file.split(':') cache.delete(`/img/${type}_${id}_sm.jpg`) }}) newFiles.forEach(file => { if (!~oldFiles.indexOf(file)) { const [ id, type ] = file.split(':'), src = `/img/${type}_${id}_sm.jpg` cache.add(new Request(src, { cache: 'no-cache' })) }}) }
Ensuite, vous devez redéfinir le comportement de récupération afin que le fichier soit extrait de CacheStorage sans se connecter au serveur. Pour ce faire, vous devez utiliser ServiceWorker. Dans le même temps, nous allons configurer d'autres fichiers à mettre en cache pour un fonctionnement en dehors du serveur:
const CACHE = 'comico', FILES = [ '/', '/bundle.css', '/bundle.js' ] self.addEventListener('install', (e) => { e.waitUntil(caches.open(CACHE).then(cache => cache.addAll(FILES)) .then(() => self.skipWaiting())) }) self.addEventListener('fetch', (e) => { const r = e.request if (r.method !== 'GET' || !!~r.url.indexOf('/pub/') || !!~r.url.indexOf('/api/')) return if (!!~r.url.lastIndexOf('_sm.jpg') && e.request.cache !== 'no-cache') return e.respondWith(fromCache(r)) e.respondWith(toCache(r)) }) async function fromCache(request) { return await (await caches.open(CACHE)).match(request) || new Response(null, { status: 404 }) } async function toCache(request) { const response = await fetch(request).catch(() => fromCache(request)) if (!!response && response.ok) (await caches.open(CACHE)).put(request, response.clone()) return response }
Il semble un peu maladroit, mais remplit ses fonctions.
Client / Interface
Structure des composants:
index.html | main.js
== header.html - contient un logo, une barre d'état, un menu principal, un menu de navigation inférieur, un formulaire de soumission de commentaires
== côté.html - est un conteneur pour tous les composants modaux
==== goodForm.html - formulaire pour ajouter et modifier une annonce
==== userForm.html - modifie le formulaire de l'utilisateur actuel
====== tableForm.html - un fragment du formulaire pour saisir des données tabulaires
==== postForm.html - formulaire pour publication sur le forum
==== login.html - formulaire de connexion / inscription
==== activity.html - affiche les commentaires adressés à l'utilisateur actuel
==== goodImage.html - afficher les annonces photo principales et supplémentaires
== main.html - conteneur pour le contenu principal
==== goods.html - liste ou cartes d'annonce uniques
==== users.html - idem pour les utilisateurs
==== posts.html - Je pense que c'est clair
==== cmnts.html - liste des commentaires sur le post actuel
====== cmntsPager.html - pagination pour les commentaires
- Dans chaque composant, nous essayons de minimiser le nombre de balises html.
- Nous utilisons les classes uniquement comme indicateur d'état.
- Nous supprimons des fonctions similaires au magasin (les propriétés et méthodes du magasin svelte peuvent être utilisées directement à partir des composants en leur ajoutant le préfixe '$').
- La plupart des fonctions attendent un événement utilisateur ou un changement de certaines propriétés, manipulent les données d'état, sauvegardent le résultat de leur travail à l'état et terminent. Ainsi, une petite cohérence et extensibilité du code est obtenue.
- Pour la vitesse apparente des transitions et autres événements d'interface utilisateur, nous séparons, dans la mesure du possible, les manipulations avec des données se produisant en arrière-plan et les actions associées à l'interface, qui à son tour utilise le résultat du calcul actuel, reconstruisant si nécessaire, le reste sera aimablement effectué par le framework.
- Les données du formulaire à remplir sont stockées dans localStorage pour chaque entrée afin d'éviter leur perte.
- Dans tous les composants, nous utilisons le mode immuable dans lequel la propriété-objet n'est considérée comme modifiée que lorsqu'un nouveau lien est reçu, quel que soit le changement dans les champs, accélérant ainsi un peu nos applications, bien qu'en raison d'une légère augmentation de la quantité de code.
Client / Gestion
Pour contrôler à l'aide du clavier, nous utilisons les combinaisons suivantes:
Alt + s / Alt + a - fait basculer la page des enregistrements vers l'avant / vers l'arrière, car un enregistrement fait basculer la page des commentaires.
Alt + w / Alt + q - passe à l'enregistrement suivant / précédent (le cas échéant), fonctionne en mode liste, enregistrement unique et vue d'image
Alt + x / Alt + z - fait défiler la page vers le haut / bas. Dans la vue d'image, fait basculer les images vers l'avant / l'arrière
Echap - ferme la fenêtre modale, si ouverte, revient à la liste, si une seule entrée est ouverte, annule la requête de recherche en mode liste
Alt + c - se concentre sur le champ de recherche ou de commentaire, selon le mode actuel
Alt + v - activer / désactiver le mode d'affichage des photos pour une seule annonce
Alt + r - ouvre / ferme la liste des commentaires entrants pour un utilisateur autorisé
Alt + t - Bascule les thèmes clair / sombre
Alt + g - Liste des annonces
Alt + u - Utilisateurs
Alt + p - forum
Je sais que dans de nombreux navigateurs, ces combinaisons sont utilisées par le navigateur lui-même, mais pour mon chrome, je n'ai pas pu trouver quelque chose de plus pratique. Je serai heureux de vos suggestions.
En plus du clavier, vous pouvez bien sûr utiliser la console du navigateur. Par exemple, store.goBack () , store.nextPage () , store.prevPage () , store.nextItem () , store.prevItem () , store.search (stringValue) , store.checkUpdate ('goods' || ' utilisateurs || 'messages' || 'fichiers' || 'cmnts') - faites ce que le nom implique; store.get (). comments et store.get () ._ images - retourne les fichiers groupés et les commentaires; store.get (). ignoredItems et store.get (). scribedItems sont des listes d'enregistrements que vous ignorez et suivez. Une liste complète de toutes les données intermédiaires et calculées est disponible sur store.get () . Je ne pense pas que quiconque puisse en avoir besoin sérieusement, mais, par exemple, le filtrage des enregistrements par utilisateur et la suppression me paraissent assez pratiques depuis la console.
Conclusion
C'est ici que vous pouvez mettre fin à votre connaissance du projet; vous pouvez trouver plus de détails dans le code source. En conséquence, nous avons obtenu une application assez rapide et compacte, dans la plupart des validateurs, vérificateurs de sécurité, de vitesse, de disponibilité, etc., elle montre de bons résultats sans optimisation ciblée.
Je voudrais connaître l'opinion de la communauté sur la justification des approches d'organisation des applications utilisées dans le prototype, quels pièges pourraient être, que mettriez-vous en œuvre d'une manière fondamentalement différente?
Code source, exemples d'instructions d'installation et démonstration ici (veuillez vandaliser à tester dans le cadre du code pénal).
Postscript. Un peu mercantile en conclusion. Dites-moi, avec un tel niveau, est-il vraiment possible de commencer à programmer pour de l'argent? Sinon, que chercher avant tout, si oui, dites-moi où ils recherchent un travail intéressant sur une pile similaire maintenant. Je vous remercie
Postscript. Un peu plus sur l'argent et le travail. Comment aimez-vous cette idée: supposons qu'une personne soit prête à travailler sur un projet intéressant pour n'importe quel salaire, cependant, les données sur les tâches et leur paiement seront disponibles publiquement (la disponibilité et un code pour évaluer la qualité des performances sont souhaitables), si le paiement est nettement inférieur au marché, les concurrents de l'employeur peut offrir beaucoup d'argent pour effectuer ses tâches, s'il est plus élevé - de nombreux artistes pourront offrir leurs services à un prix inférieur. Un tel système, dans certaines situations, équilibrera-t-il le marché (TI) de manière plus optimale et plus équitable?