Ceci est la deuxième partie de mes
Kubernetes dans la série de publications
Enterprise . Comme je l'ai mentionné dans mon dernier article, il est très important de passer aux
«Guides de conception et d'implémentation» que tout le monde soit au même niveau de compréhension de Kubernetes (K8).
Je ne veux pas utiliser l'approche traditionnelle ici pour expliquer l'architecture et les technologies de Kubernetes, mais je vais tout expliquer à travers une comparaison avec la plate-forme vSphere, que vous, en tant qu'utilisateurs VMware, connaissez. Cela vous permettra de surmonter l'apparente confusion et la gravité de la compréhension de Kubernetes. J'ai utilisé cette approche dans VMware pour présenter Kubernetes à différents publics d'auditeurs, et cela a prouvé que cela fonctionne très bien et aide les gens à s'habituer plus rapidement aux concepts clés.
Remarque importante avant de commencer. Je n'utilise pas cette comparaison pour prouver des similitudes ou des différences entre vSphere et Kubernetes. Cela et un autre, en substance, sont des systèmes distribués et, par conséquent, devraient avoir des similitudes avec tout autre système similaire. Par conséquent, au final, j'essaie de présenter une technologie aussi merveilleuse que Kubernetes à une large communauté d'utilisateurs.

Un peu d'histoire
La lecture de cet article implique d'apprendre à connaître les conteneurs. Je ne décrirai pas les concepts de base des conteneurs, car il existe de nombreuses ressources qui en parlent. En discutant très souvent avec les clients, je constate qu'ils ne peuvent pas comprendre pourquoi les conteneurs ont saisi notre industrie et sont devenus très populaires en un temps record. Pour répondre à cette question, je vais vous parler de mon expérience pratique dans la compréhension des changements qui se produisent dans notre industrie.
Avant d'explorer le monde des télécommunications, j'étais développeur Web (2003).
C'était mon deuxième emploi rémunéré après avoir travaillé comme ingénieur / administrateur de réseau (je sais que j'étais un cric de tous les métiers). J'ai développé en PHP. J'ai développé toutes sortes d'applications, en commençant par les petites que mon employeur utilisait, pour finir par une application de vote professionnelle pour les programmes de télévision, et même des applications de télécommunication qui interagissent avec les concentrateurs VSAT et les systèmes satellites. La vie était belle, à l'exception d'un obstacle majeur que chaque développeur connaît, ce sont les dépendances.
Au début, j'ai développé l'application sur mon ordinateur portable, en utilisant quelque chose comme la pile LAMP, quand cela fonctionnait bien sur mon ordinateur portable, j'ai téléchargé le code source sur les serveurs hôtes (tout le monde se souvient de RackShack?) Ou sur les serveurs privés du client. Vous pouvez imaginer que dès que j'ai fait cela, l'application s'est bloquée et n'a pas fonctionné sur ces serveurs. La raison en est la dépendance. Les serveurs avaient d'autres versions du logiciel (Apache, PHP, MySQL, etc.) que celles que j'utilisais sur l'ordinateur portable. J'ai donc dû trouver un moyen de mettre à jour les versions du logiciel sur les serveurs distants (mauvaise idée) ou de réécrire le code sur mon ordinateur portable pour correspondre aux versions sur les serveurs distants (pire idée). C'était un cauchemar, parfois je me détestais et je me demandais pourquoi c'est ainsi que je gagne ma vie.
10 ans se sont écoulés, la société Docker est apparue. En tant que consultant VMware chez Professional Services (2013), j'ai entendu parler de Docker, et permettez-moi de dire que je ne pouvais pas comprendre cette technologie à l'époque. J'ai continué à dire quelque chose comme: pourquoi utiliser des conteneurs s'il y a des machines virtuelles. Pourquoi abandonner des technologies importantes comme vSphere HA, DRS ou vMotion en raison d'avantages étranges tels que le lancement instantané de conteneurs ou l'élimination de la surcharge d'hyperviseur. Après tout, tout le monde travaille avec des machines virtuelles et fonctionne parfaitement. Bref, je l'ai envisagé en termes d'infrastructure.
Mais alors j'ai commencé à regarder de près et cela m'est apparu. Tout ce qui concerne Docker est lié aux développeurs. En commençant à penser en tant que développeur, j'ai immédiatement réalisé que si j'avais cette technologie en 2003, je pourrais emballer toutes mes dépendances. Mes applications Web peuvent fonctionner quel que soit le serveur utilisé. De plus, il ne serait pas nécessaire de télécharger le code source ou de configurer quelque chose. Vous pouvez simplement «compresser» mon application dans une image et demander aux clients de télécharger et d'exécuter cette image. C'est le rêve de tout développeur Web!
Tout cela est super. Docker a résolu l'énorme problème d'interaction et d'emballage, mais que faire ensuite? Puis-je, en tant que client d'entreprise, gérer ces applications tout en évoluant? Je veux toujours utiliser HA, DRS, vMotion et DR. Docker a résolu les problèmes de mes développeurs et créé tout un tas de problèmes pour mes administrateurs (équipe DevOps). Ils ont besoin d'une plate-forme pour lancer des conteneurs, la même que celle pour lancer des machines virtuelles. Et nous sommes revenus au début.
Mais ensuite Google est apparu, expliquant au monde entier l'utilisation de conteneurs pendant de nombreuses années (en fait, les conteneurs ont été inventés par Google: cgroups) et la bonne méthode pour les utiliser, via une plateforme qu'ils appelaient Kubernetes. Ils ont ensuite ouvert le code source de Kubernetes. Présenté à la communauté Kubernetes. Et cela a encore tout changé.
Comprendre Kubernetes et vSphere
Alors qu'est-ce que Kubernetes? En termes simples, Kubernetes pour les conteneurs est identique à vSphere pour les machines virtuelles dans un centre de données moderne. Si vous avez utilisé VMware Workstation au début des années 2000, vous savez que cette solution a été sérieusement considérée comme une solution pour les centres de données. Lorsque VI / vSphere avec vCenter et hôtes ESXi est apparu, le monde des machines virtuelles a radicalement changé. Kubernetes fait la même chose aujourd'hui avec le monde des conteneurs, offrant la possibilité de lancer et de gérer des conteneurs en production. Et c'est pourquoi nous allons commencer à comparer vSphere côte à côte avec Kubernetes pour expliquer les détails de ce système distribué pour comprendre ses fonctions et technologies.

Présentation du système
Comme dans vSphere, il existe des hôtes vCenter et ESXi dans le concept de Kubernetes, il y a des maîtres et des nœuds. Dans ce contexte, Master in K8s est l'équivalent de vCenter, en ce sens qu'il s'agit du plan de gestion d'un système distribué. C'est également le point d'entrée de l'API avec laquelle vous interagissez lors de la gestion de votre charge de travail. De la même manière, les nœuds K8 fonctionnent comme des ressources informatiques, similaires aux hôtes ESXi. C'est sur eux que vous exécutez les charges de travail (dans le cas des K8, nous les appelons Pods). Les nœuds peuvent être des machines virtuelles ou des serveurs physiques. Bien sûr, avec vSphere ESXi, les hôtes doivent toujours être physiques.

Vous pouvez voir que K8s a un magasin de valeurs-clés appelé "etcd". Ce stockage est similaire à la base de données vCenter, où vous enregistrez la configuration de cluster souhaitée à laquelle vous souhaitez adhérer.
En ce qui concerne les différences: sur les Master K8, vous pouvez également exécuter des charges de travail, mais sur vCenter, vous ne pouvez pas. vCenter est une appliance virtuelle dédiée à la gestion uniquement. Dans le cas des K8, Master est considéré comme une ressource informatique, mais exécuter des applications d'entreprise dessus n'est pas une bonne idée.
Alors, à quoi cela ressemblera-t-il en réalité? Vous utiliserez principalement la CLI pour interagir avec Kubernetes (mais l'interface graphique est toujours une option très viable). La capture d'écran ci-dessous montre que j'utilise une machine Windows pour me connecter à mon cluster Kubernetes via la ligne de commande (j'utilise cmder si vous êtes intéressé). Dans la capture d'écran, j'ai un nœud maître et 4 nœuds. Ils fonctionnent sous le contrôle de K8s v1.6.5, et le système d'exploitation (OS) Ubuntu 16.04 est installé sur les nœuds. Au moment de la rédaction de cet article, nous vivons principalement dans le monde Linux, où Master et Node exécutent toujours une distribution Linux.
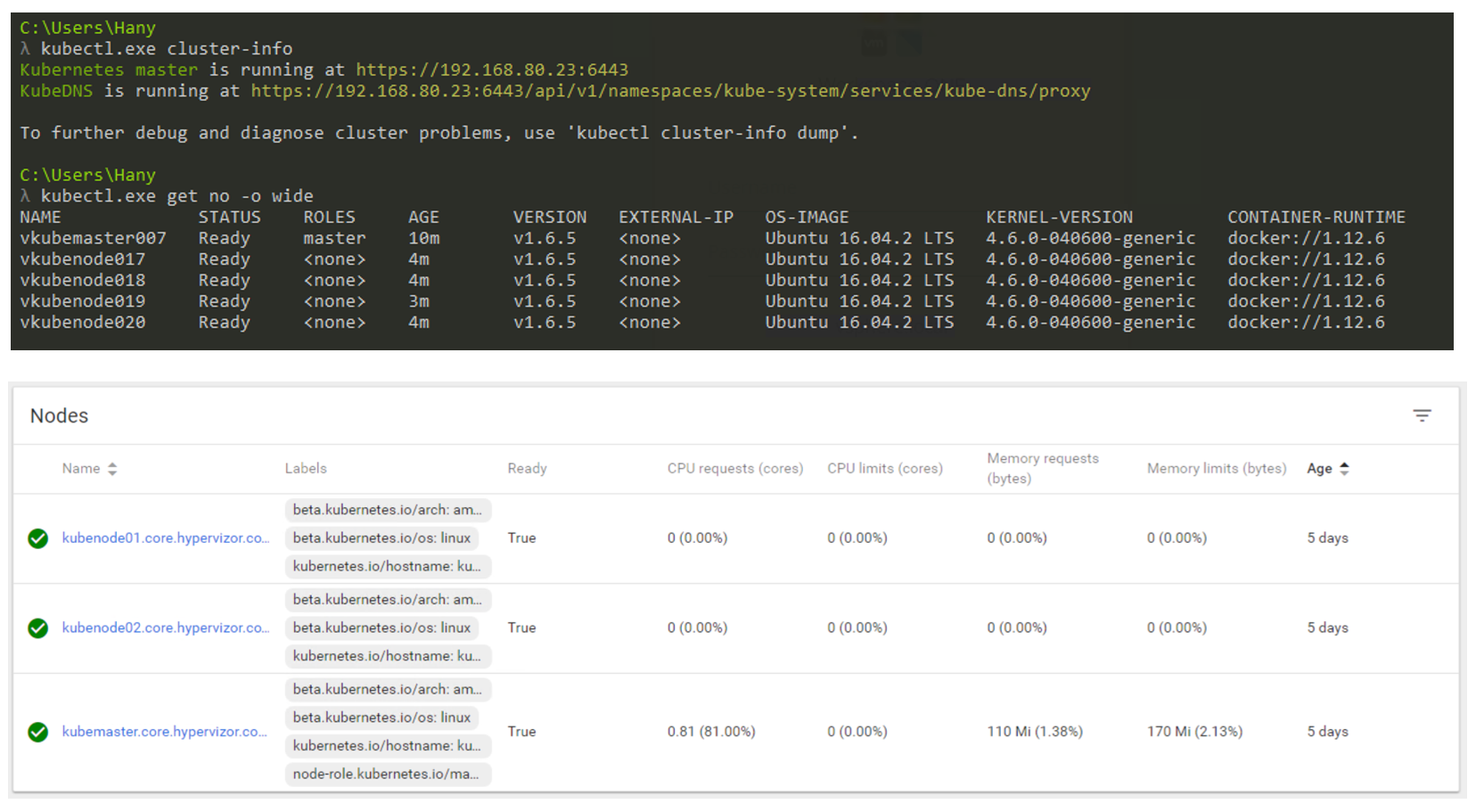 Gestion de cluster K8s via CLI et GUI.
Gestion de cluster K8s via CLI et GUI.Facteur de forme de charge de travail
Dans vSphere, la machine virtuelle est la limite logique du système d'exploitation. Dans Kubernetes, les pods sont des limites de conteneur, tout comme l'hôte ESXi, qui peut exécuter plusieurs machines virtuelles simultanément. Chaque nœud peut exécuter plusieurs pods. Chaque pod reçoit une adresse IP routable, comme les machines virtuelles, pour que les pods communiquent entre eux.
Dans vSphere, les applications s'exécutent à l'intérieur du système d'exploitation et dans Kubernetes, les applications s'exécutent à l'intérieur des conteneurs. Une machine virtuelle ne peut fonctionner qu'avec un seul système d'exploitation à la fois, et un pod peut exécuter plusieurs conteneurs.
C'est ainsi que vous pouvez lister les pods à l'intérieur du cluster K8 en utilisant l'outil kubectl via la CLI, vérifier la capacité de travail des pods, leur âge, leur adresse IP et les nœuds sur lesquels ils travaillent actuellement.

La gestion
Alors, comment gérons-nous nos maîtres, nœuds et pods? Chez vSphere, nous utilisons le client Web pour gérer la plupart (sinon la totalité) des composants de notre infrastructure virtuelle. Pour Kubernetes, de même, en utilisant Dashboard. Il s'agit d'un bon portail Web basé sur une interface graphique auquel vous pouvez accéder via votre navigateur de la même manière qu'avec le client Web vSphere. Dans les sections précédentes, vous pouvez voir que vous pouvez gérer votre cluster K8s à l'aide de la commande kubeclt de la CLI. Il est toujours discutable où vous passerez la plupart de votre temps dans la CLI ou dans le tableau de bord graphique. Depuis ce dernier devient chaque jour un outil de plus en plus puissant (vous pouvez voir cette vidéo pour en être sûr). Personnellement, je pense que le tableau de bord est très pratique pour surveiller rapidement l'état ou afficher les détails des différents composants des K8, sans avoir à entrer de longues commandes dans la CLI. Vous trouverez un équilibre entre eux de manière naturelle.
Configurations
L'un des concepts très importants de Kubernetes est l'état souhaité des configurations. Vous déclarez que vous voulez pour presque n'importe quel composant Kubernetes via un fichier YAML, et vous créez tout cela en utilisant kubectl (ou via un tableau de bord graphique) comme état souhaité. Désormais, Kubernetes s'efforcera toujours de maintenir votre environnement dans un état opérationnel donné. Par exemple, si vous souhaitez avoir 4 répliques d'un pod, les K8 continueront de surveiller ces pods, et si l'un d'eux est mort ou si le nœud sur lequel il a travaillé a eu des problèmes, les K8 se récupèrent automatiquement et le créent automatiquement Pod ailleurs.
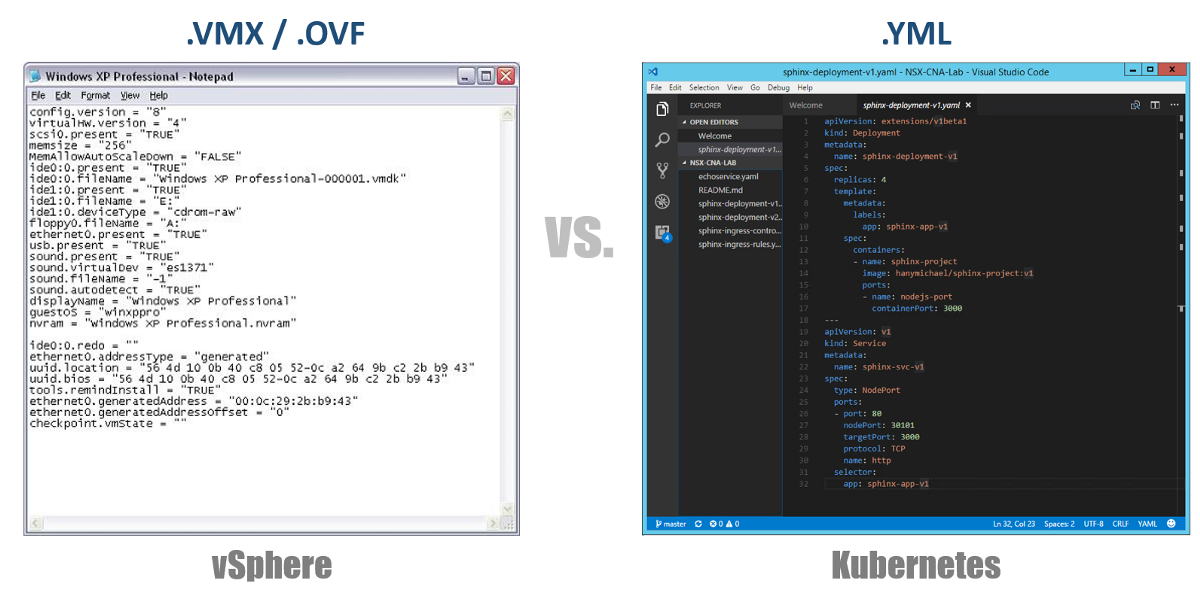
En revenant à nos fichiers de configuration YAML, vous pouvez les considérer comme un fichier .VMX pour une machine virtuelle ou un descripteur .OVF pour une appliance virtuelle que vous souhaitez déployer sur vSphere. Ces fichiers définissent la configuration de la charge de travail / composant que vous souhaitez exécuter. Contrairement aux fichiers VMX / OVF, qui sont exclusifs aux VM / Appliances virtuelles, les fichiers de configuration YAML sont utilisés pour définir n'importe quel composant K8, tels que ReplicaSets, Services, Deployments, etc. Considérez ceci dans les sections suivantes.
Clusters virtuels
Dans vSphere, nous avons des hôtes ESXi physiques qui sont logiquement regroupés en clusters. Ces clusters peuvent être divisés en d'autres clusters virtuels appelés «Pools de ressources». Ces «pools» sont principalement utilisés pour limiter les ressources. Chez Kubernetes, nous avons quelque chose de très similaire. Nous les appelons «espaces de noms», ils peuvent également être utilisés pour fournir des limites de ressources, qui seront reflétées dans la section suivante. Cependant, le plus souvent, les «espaces de noms» sont utilisés comme un outil d'hébergement multiclient pour les applications (ou les utilisateurs, si vous utilisez des clusters K8 courants). C'est également l'une des options avec lesquelles vous pouvez effectuer la segmentation du réseau à l'aide de NSX-T. Considérez ceci dans les publications suivantes.
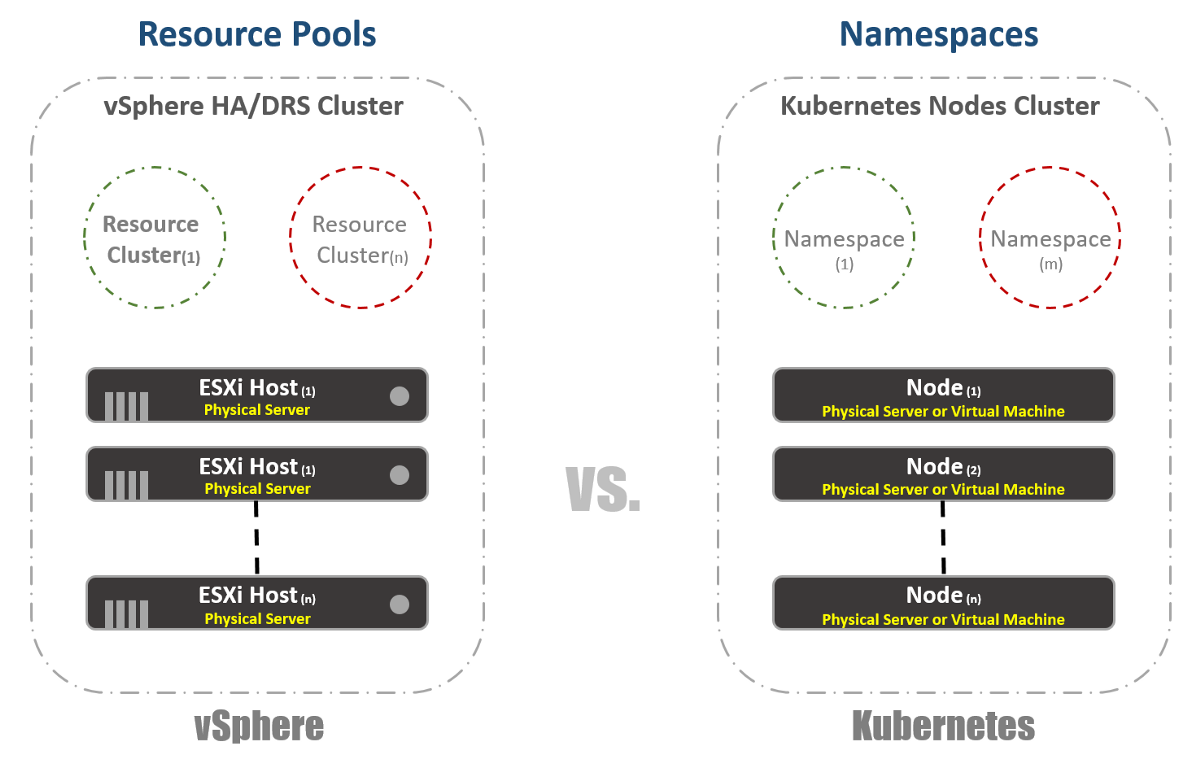
Gestion des ressources
Comme je l'ai mentionné dans la section précédente, les espaces de noms dans Kubernetes sont couramment utilisés comme moyen de segmentation. Une autre utilisation des espaces de noms est l'allocation des ressources. Cette option est appelée «Quotas de ressources». Comme indiqué dans les sections précédentes, la définition de cela se produit dans les fichiers de configuration YAML, dans lesquels l'état souhaité est déclaré. Dans vSphere, comme le montre la capture d'écran ci-dessous, nous le déterminons à partir des paramètres des pools de ressources.

Identification de la charge de travail
C'est assez simple et presque le même pour vSphere et Kubernetes. Dans le premier cas, nous utilisons les concepts de balises pour définir (ou grouper) des charges de travail similaires, et dans le second, nous utilisons le terme «étiquettes». Dans le cas de Kubernetes, l'identification de la charge de travail est obligatoire.

Réservation
Maintenant pour le vrai plaisir. Si vous étiez ou êtes un grand fan de vSphere FT, comme moi, vous allez adorer cette fonctionnalité dans Kubernetes, malgré quelques différences dans les deux technologies. Dans vSphere, il s'agit d'une machine virtuelle avec une instance fantôme en cours d'exécution exécutée sur un hôte différent. Nous enregistrons les instructions sur la machine virtuelle principale et les rejouons sur la machine virtuelle fantôme. Si la machine principale cesse de fonctionner, la machine virtuelle fantôme s'active immédiatement. Ensuite, vSphere essaie de trouver un autre hôte ESXi pour créer une nouvelle instance fantôme de la machine virtuelle pour maintenir la même redondance. Chez Kubernetes, nous avons quelque chose de très similaire. ReplicaSets est le montant que vous spécifiez pour exécuter plusieurs instances de pods. Si un pod échoue, d'autres instances sont disponibles pour traiter le trafic. Dans le même temps, les K8 essaieront de lancer un nouveau pod sur n'importe quel nœud disponible afin de maintenir l'état de configuration souhaité. La principale différence, comme vous l'avez peut-être déjà remarqué, est que dans le cas des K8, les pods fonctionnent et servent toujours le trafic. Ce ne sont pas des charges de travail fantômes.

Équilibrage de charge
Bien que cela ne soit pas une fonction intégrée dans vSphere, il est très, très souvent nécessaire d'exécuter des équilibreurs de charge sur la plate-forme. Dans le monde vSphere, il existe des équilibreurs de charge virtuels ou physiques pour distribuer le trafic réseau entre plusieurs machines virtuelles. Il peut y avoir de nombreux modes de configuration différents, mais supposons que nous entendons une configuration à un bras. Dans ce cas, vous équilibrez la charge du trafic Est-Ouest sur vos machines virtuelles.
De même, Kubernetes a le concept de «Services». Le service dans les K8 peut également être utilisé dans différents modes de configuration. Choisissons la configuration «ClusterIP» pour la comparer avec l'équilibreur de charge à un bras. Dans ce cas, le service dans les K8 aura une adresse IP virtuelle (VIP), qui est toujours statique et ne change pas. Ce VIP répartira le trafic entre plusieurs pods. Ceci est particulièrement important dans le monde Kubernetes, où par nature les pods sont éphémères, vous perdez l'adresse IP du pod au moment où il meurt ou est supprimé. Par conséquent, vous devez toujours fournir un VIP statique.
Comme je l'ai déjà mentionné, le service a de nombreuses autres configurations, par exemple, «NodePort», où vous attribuez un port au niveau du nœud, puis effectuez la traduction de la traduction d'adresse de port pour les pods. Il existe également un «LoadBalancer» dans lequel vous exécutez une instance de Load Balancer à partir d'un fournisseur tiers ou cloud.

Kuberentes dispose d'un autre mécanisme d'équilibrage de charge très important appelé «contrôleur d'entrée». Vous pouvez le considérer comme un équilibreur de charge d'application en ligne. L'idée principale est que le contrôleur d'entrée (sous la forme d'un pod) sera lancé avec une adresse IP visible de l'extérieur. Cette adresse IP peut avoir quelque chose comme des enregistrements DNS génériques. Lorsque le trafic arrive au contrôleur d'entrée à l'aide d'une adresse IP externe, il vérifie les en-têtes et détermine à l'aide de l'ensemble de règles que vous avez précédemment défini à quel pod ce nom appartient. Par exemple: sphinx-v1.esxcloud.net sera dirigé vers le service sphinx-svc-1, et sphinx-v2.esxcloud.net sera dirigé vers le service sphinx-svc2, etc.

Stockage et réseau
Le stockage et la mise en réseau sont des sujets très, très larges quand il s'agit de Kubernetes. Il est presque impossible de parler brièvement de ces deux sujets dans un billet d'introduction, mais je parlerai bientôt en détail des différents concepts et options pour chacun de ces sujets. En attendant, regardons rapidement comment fonctionne la pile réseau dans Kubernetes, car nous en aurons besoin dans la section suivante.
Kubernetes propose différents «plugins» réseau que vous pouvez utiliser pour configurer le réseau de vos nœuds et pods. Un plugin commun est «kubenet», qui est actuellement utilisé dans les méga-nuages tels que GCP et AWS. Ici, je vais parler brièvement de la mise en œuvre de GCP, puis montrer un exemple pratique de mise en œuvre dans GKE.

À première vue, cela peut sembler trop compliqué, mais j'espère que vous comprendrez tout cela d'ici la fin de ce post. Tout d'abord, nous voyons que nous avons deux nœuds Kubernetes: le nœud 1 et le nœud (m). Chaque nœud a une interface eth0, comme n'importe quelle machine Linux. Cette interface a une adresse IP pour le monde extérieur, dans notre cas, sur le sous-réseau 10.140.0.0/24. Le périphérique Upstream L3 sert de passerelle par défaut pour acheminer notre trafic. Il peut s'agir d'un commutateur L3 dans votre centre de données ou d'un routeur VPC dans le cloud, tel que GCP, comme nous le verrons plus tard. Tout va bien?
De plus, nous voyons que nous avons l'interface Bridge cbr0 à l'intérieur du nœud. Cette interface est la passerelle par défaut pour le sous-réseau IP 10.40.1.0/24 dans le cas du nœud 1. Ce sous-réseau est attribué par Kubernetes à chaque nœud. Les nœuds obtiennent généralement un sous-réseau / 24, mais vous pouvez le changer en utilisant NSX-T (nous couvrirons cela dans les articles suivants). Pour le moment, ce sous-réseau est celui à partir duquel nous émettrons des adresses IP pour les pods. De cette façon, tout pod à l'intérieur du nœud 1 obtiendra une adresse IP de ce sous-réseau. Dans notre cas, le Pod 1 a une adresse IP de 10.40.1.10. Cependant, vous remarquez qu'il existe deux conteneurs imbriqués dans ce pod. Nous avons déjà dit qu'au sein d'un Pod, un ou plusieurs conteneurs peuvent être lancés, qui sont étroitement liés les uns aux autres en termes de fonctionnalité. C'est ce que nous voyons sur la figure. Le conteneur 1 écoute sur le port 80 et le conteneur 2 écoute sur le port 90. Les deux conteneurs ont la même adresse IP 10.40.1.10, mais ils ne possèdent pas l'espace de noms de mise en réseau. OK, alors à qui appartient cette pile réseau? En fait, il existe un conteneur spécial appelé «Pause Container». Le diagramme montre que son adresse IP est l'adresse IP de Pod pour la communication avec le monde extérieur. Ainsi, Pause Container possède cette pile réseau, y compris l'adresse IP 10.40.1.10 elle-même, et, bien sûr, il redirige le trafic vers le conteneur 1 vers le port 80, et redirige également le trafic vers le conteneur 2 vers le port 90.
Vous devez maintenant vous demander comment le trafic est redirigé vers le monde extérieur? Nous avons le transfert IP Linux standard activé pour transférer le trafic de cbr0 vers eth0. C'est très bien, mais alors on ne sait pas comment l'appareil L3 peut apprendre à transférer du trafic vers sa destination? Dans cet exemple spécifique, nous n'avons pas de routage dynamique pour l'annonce de ce réseau. Par conséquent, nous devons avoir une sorte de routes statiques sur le périphérique L3. Afin d'atteindre le sous-réseau 10.40.1.0/24, vous devez transférer le trafic vers l'adresse IP du nœud 1 (10.140.0.11) et pour atteindre le sous-réseau 10.40.2.0/24, le prochain espoir - Node (m) avec l'adresse IP 10.140.0.12.
Tout cela est génial, mais c'est une façon très peu pratique de gérer vos réseaux. La prise en charge de toutes ces routes lors de la mise à l'échelle de votre cluster sera un cauchemar absolu pour les administrateurs réseau. C'est pourquoi certaines solutions, telles que CNI (Container Network Interface) à Kuberentes, sont nécessaires pour gérer la connectivité réseau. NSX-T est l'une de ces solutions avec une très large fonctionnalité pour l'interaction réseau et la sécurité.
N'oubliez pas que nous avons regardé le plugin kubenet, pas CNI. Le plugin kubenet est ce que le Google Container Engine (GKE) utilise, et la façon dont ils le font est assez amusant car il est entièrement défini et automatisé par logiciel dans leur cloud. , GCP. .
Et ensuite?
Kuberentes. ,
.
La deuxième partie.. .
.