De nombreux projets sont confrontés au problème des tests floconneux, et ce sujet a été soulevé plus d'une fois sur Habré. Les tests qui n'ont pas décidé de leur condition prennent constamment non seulement le temps machine, mais aussi le temps des développeurs et des testeurs. Et si dans une entreprise commerciale vous pouvez allouer une certaine ressource pour résoudre ce problème et nommer des personnes responsables, alors dans la communauté opensource, ce n'est pas si simple. Surtout quand il s'agit de grands projets - par exemple, comme Apache Ignite, où il y a près de 60 000 tests différents.

Dans cet article, nous vous expliquerons en fait comment résoudre ce problème dans Apache Ignite. Nous sommes Dmitry Pavlov, ingénieur logiciel principal / gestionnaire de communauté chez GridGain, et Nikolai Kulagin, ingénieur informatique chez Sberbank Technologies.
Tout ce qui est écrit ci-dessous ne représente la position d'aucune entreprise, y compris Sberbank. Cette histoire provient exclusivement de membres de la communauté Apache Ignite.Apache Ignite et tests
L'histoire d'Apache Ignite commence en 2014, lorsque GridGain a fait don de la première version du produit interne à Apache Software Foundation. Plus de 4 ans se sont écoulés depuis lors, et pendant ce temps, le nombre de tests a approché la barre des 60 mille.
Nous utilisons JetBrains TeamCity comme serveur d'intégration continue - merci aux gars de JetBrains pour soutenir le mouvement open source. Tous nos tests sont répartis entre les suites, dont le nombre pour la branche master est proche de 140. Dans les suites, les tests sont regroupés par critère. Cela peut tester uniquement les fonctionnalités de Machine Learning [RunMl], uniquement le cache [RunCache] ou l'ensemble [RunAll]. À l'avenir, l'exécution des tests signifiera exactement [RunAll] - une vérification complète. Cela prend environ 55 heures de temps machine.
Junit est utilisé comme bibliothèque principale, mais il y a peu de tests unitaires. Pour la plupart, tous nos tests sont des tests d'intégration, car ils contiennent le lancement d'un ou plusieurs nœuds (et cela prend plusieurs secondes). Bien sûr, les tests d'intégration sont pratiques car l'un de ces tests couvre de nombreux aspects et interactions, ce qui est assez difficile à réaliser avec un seul test unitaire. Mais il y a aussi des inconvénients: dans notre cas, c'est un délai assez long, ainsi que la difficulté de trouver un problème.
Problèmes avec floconneux
Une partie de ces tests est floconneuse. Maintenant, selon la classification TeamCity, environ 1 700 tests sont marqués comme feuilletés, c'est-à-dire avec un changement d'état sans changer le code ou la configuration. De tels tests ne peuvent pas être ignorés, car il y a un risque de bogue en production. Par conséquent, ils doivent être revérifiés et redémarrés, parfois plusieurs fois, pour analyser les résultats des chutes - et cela prend un temps et des efforts précieux. Et si les membres existants de la communauté font face à cette tâche, alors pour les nouveaux contributeurs, cela peut devenir un véritable obstacle. Vous devez admettre que lorsque vous apportez des modifications au Java Doc, vous ne vous attendez pas à rencontrer un plantage, mais pas un, mais plusieurs dizaines.

Qui est à blâmer?
La moitié des problèmes avec les tests feuilletés sont dus à la configuration de l'équipement, à la taille de l'installation. Et la seconde moitié est directement liée aux personnes qui ont raté et n'ont pas corrigé leur bug.
Classiquement, tous les membres de la communauté peuvent être divisés en deux groupes:
- Les amateurs qui entrent dans la communauté de leur plein gré et contribuent à leur temps libre.
- Contributeurs à temps plein travaillant pour des entreprises qui utilisent ou sont associées à ce produit open source.
Un contributeur du premier groupe peut très bien faire une seule modification et quitter la communauté. Et l'atteindre en cas de détection d'un bug est presque impossible. Il est plus facile d'interagir avec les personnes du deuxième groupe, elles sont plus susceptibles de répondre à un test qu'elles réussissent. Mais il arrive qu'une entreprise qui était auparavant intéressée par un produit ait cessé d'en avoir besoin. Elle quitte la communauté et ses collaborateurs contribuent avec elle. Ou il est possible que le contributeur quitte l'entreprise, et avec elle la communauté. Bien sûr, après de tels changements, certains continuent de participer à la communauté. Mais pas tous.
Qui va réparer?
Si nous parlons de personnes qui ont quitté la communauté, alors leurs bugs, bien sûr, vont aux contributeurs actuels. Il convient de noter que pour la révision qui a conduit au bogue, le réviseur est également responsable, mais il peut également être un passionné - c'est-à-dire qu'il ne sera pas toujours disponible.
Il se trouve que cela tend à tendre la main à une personne, dites-lui: c'est le problème. Mais il dit: non, ce n'est pas ma solution qui a introduit un bug. Comme une exécution complète de la branche principale est automatiquement effectuée avec une file d'attente relativement libre, cela se produit le plus souvent la nuit. Avant cela, plusieurs commits peuvent être versés dans la branche pour toute la journée.
Dans TeamCity, toute modification de code est considérée comme un journal des modifications. Si après trois changeurs nous avons une nouvelle chute, alors trois personnes diront que ce n'est pas dû à leur engagement. S'il y a cinq changeurs, alors nous l'entendrons de cinq personnes.
Autre problème: informer le contributeur que les tests doivent être exécutés avant chaque revue. Certains ne savent pas où, quoi et comment courir. Ou les tests ont été exécutés, mais le contributeur n'a pas écrit à ce sujet dans le ticket. Il y a aussi des problèmes à ce stade.
Allez-y. Supposons que les tests soient exécutés et que le ticket contienne un lien vers les résultats. Mais, il s'est avéré que cela ne donne aucune garantie de l'analyse des tests de passage. Le contributeur peut regarder sa course, y voir quelques gouttes, mais écrire «TeamCity Looks Good». Le réviseur - surtout s'il connaît le contributeur ou l'a déjà examiné avec succès - peut ne pas vraiment voir le résultat. Et nous obtenons ce "TeamCity Looks Good":
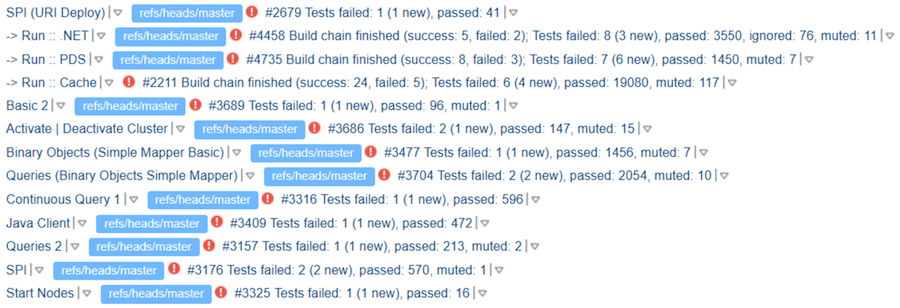
Où "bon" est ici n'est pas clair. Mais apparemment, les auteurs savent au moins que des tests doivent être exécutés.
Comment nous avons combattu cela
Méthode 1. Tests séparés
Nous avons divisé les tests en deux groupes. Dans le premier, "propre" - des tests stables. Dans le second - instable. L'approche est assez évidente, mais elle n'a pas fonctionné même avec deux tentatives. Pourquoi? Parce qu'une suite avec des tests instables se transforme en ghetto où quelque chose commence nécessairement à expirer, plante, etc. En conséquence, tout le monde commence simplement à ignorer ces tests toujours problématiques. En général, il est inutile de diviser les tests par grade.
Méthode 2. Séparation et notification
La deuxième option est similaire à la première - pour allouer des tests plus stables et exécuter les tests PR restants la nuit. Si quelque chose se casse dans un groupe stable, un message est envoyé au contributeur avec les outils TeamCity standard disant que quelque chose doit être corrigé.
... 0 personne a réagi à ces messages. Tous les ont ignorés.
Méthode 3. Surveillance quotidienne
Nous avons divisé les suites en plusieurs «observateurs», les membres les plus responsables de la communauté, et les avons signés pour des alertes de chutes. En conséquence, il a été confirmé dans la pratique que l'enthousiasme a tendance à cesser. Les contributeurs abandonnent cette entreprise et cessent de vérifier régulièrement. Puis je l'ai raté, j'ai regardé là-bas - et encore quelque chose a rampé dans le maître.
Méthode 4. Automatisation
Après une autre méthode infructueuse, les gars de GridGain se sont souvenus d'un utilitaire précédemment développé qui avait ajouté la fonctionnalité manquante à ce moment-là sur TeamCity. A savoir, la possibilité de visualiser des statistiques générales sur le nombre de chutes: combien et ce qui a chuté, détérioré ou amélioré le résultat le lendemain. Cet utilitaire a été progressivement développé, des rapports ont été ajoutés et renommés. Puis ils ont ajouté des notifications, renommées à nouveau. Il s'est donc avéré TeamCity Bot. Maintenant, il a près de 500 commits et 7 contributeurs et il est dans le dépôt supplémentaire d'Apache.
Que fait le bot? Ses capacités peuvent être combinées en deux groupes:
- Surveillance de projet - surveillance visuelle en affichant les résultats des exécutions, ainsi que la notification automatique dans les messageries instantanées (par exemple, mou)
- Vérification de succursale - analyse des tests de relations publiques et délivrance d'un visa sur un ticket.
Flux de travail TeamCity Bot
Avant Apache Ignite Teamcity Bot, le processus de «contribution» à la communauté était le suivant:
- Dans JIRA, l'un des tickets est sélectionné et corrigé;
- Une demande d'extraction est créée;
- Exécute des tests qui peuvent être affectés par les modifications apportées;
- Si les tests réussissent, la requête d'extraction peut être prévisualisée et tempérée par le committer.
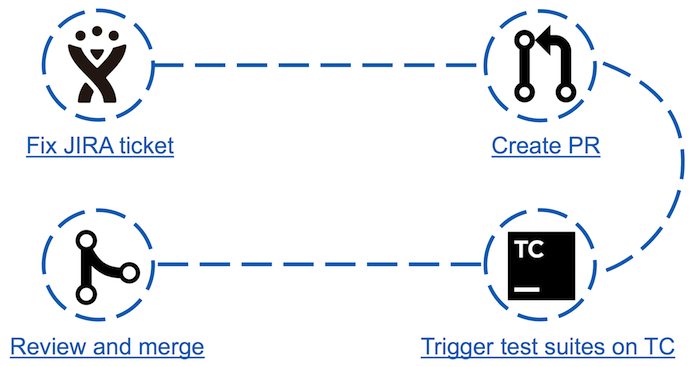
Cela semble simple, mais en fait, le troisième point peut être un obstacle pour certains contributeurs. Par exemple: un nouveau venu dans la communauté décide d'apporter sa première contribution en choisissant le ticket le plus simple. Cela peut être la modification d'un document Java ou la mise à jour de versions de dépendances maven. Analysant les résultats de la course dans sa petite correction, il découvre soudain qu'une trentaine de tests sont tombés. D'où vient le nombre d'échecs et comment les analyser - il ne sait pas. Il est fort probable que le contributeur ne reviendra plus jamais ici.
Les membres plus expérimentés de la communauté souffrent également de problèmes de qualité - ils passent du temps à analyser les tests qui sont tombés par hasard, et entravent ainsi le développement de produits.
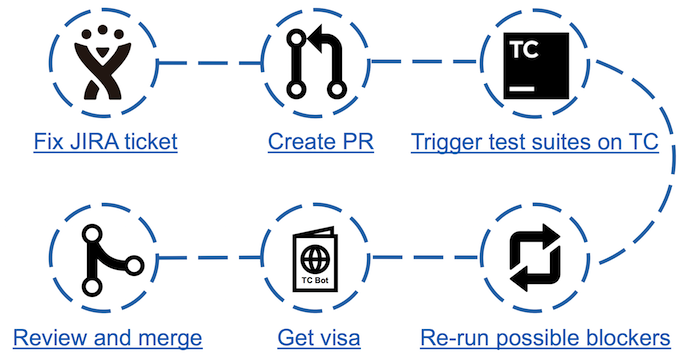 Plan de contribution avec TeamCity Bot
Plan de contribution avec TeamCity BotAvec l'avènement du bot, les étapes du contre-jeu ont augmenté, mais le temps passé à analyser les tests tombés a considérablement diminué. Il suffit maintenant de lancer le test et après l'avoir réussi, regardez la page du bot correspondante. S'il y a des bloqueurs possibles (tests abandonnés qui ne sont pas considérés comme feuilletés), il suffit d'effectuer un double contrôle, ce qui entraînera un visa sous la forme d'un commentaire dans JIRA avec les résultats du test.
Présentation des fonctionnalités
 Inspect Contribution - une liste de tous les RP non divulgués avec un résumé de chaque information: la date de la dernière mise à jour, le numéro du PR, le nom, l'auteur et le ticket dans JIRA
Inspect Contribution - une liste de tous les RP non divulgués avec un résumé de chaque information: la date de la dernière mise à jour, le numéro du PR, le nom, l'auteur et le ticket dans JIRA .
 Pour chaque pull request, un onglet avec des informations plus détaillées est disponible: le nom correct du PR, sans lequel le bot ne pourra pas trouver le ticket souhaité dans JIRA; si des tests ont été effectués; si le résultat du test est prêt; a laissé un commentaire dans JIRA.
Pour chaque pull request, un onglet avec des informations plus détaillées est disponible: le nom correct du PR, sans lequel le bot ne pourra pas trouver le ticket souhaité dans JIRA; si des tests ont été effectués; si le résultat du test est prêt; a laissé un commentaire dans JIRA.Analyse des résultats des tests:


Voici deux rapports sur les tests du même PR. Le premier vient du bot. Le second est un rapport standard sur Teamcity. La différence dans la quantité d'informations est évidente, et cela ne tient pas compte du fait que pour afficher l'historique des exécutions de test TC, il sera également nécessaire d'effectuer plusieurs transitions vers des pages adjacentes.
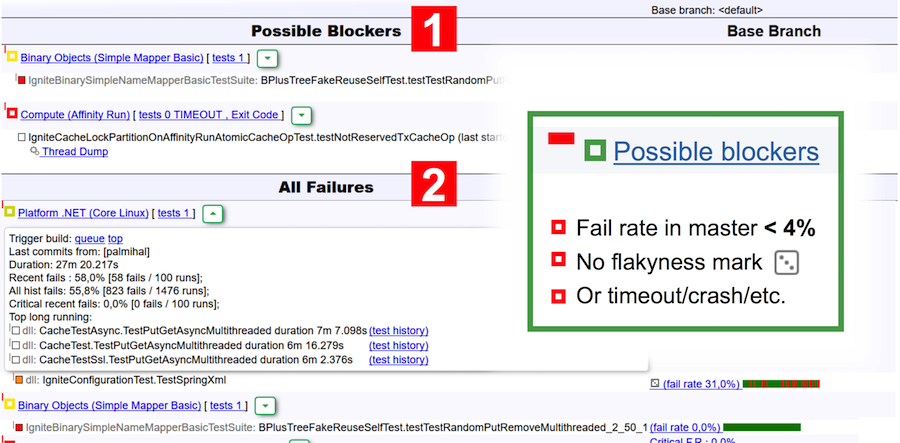
Revenons au rapport du bot. Ce rapport est visuellement divisé en deux tableaux: les bloqueurs possibles et tous les plantages. Les bloqueurs incluent des tests qui:
- avoir un taux d'échec dans le maître de moins de 4% (moins de 4 démarrages sur 100 ont échoué);
- ne sont pas feuilletés selon la classification de TeamCity;
- est tombé en raison d'un délai d'attente, de mémoire insuffisante, de code de sortie, d'une défaillance de la JVM.
Par exemple, dans la capture d'écran ci-dessus, deux suites sont indiquées comme bloqueurs possibles - dans la première, le test est tombé et dans la seconde, un délai d'attente a eu lieu.
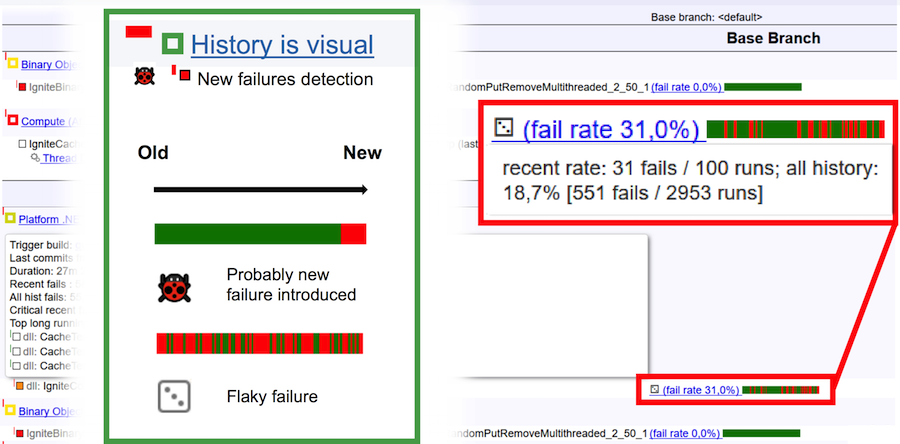
Pour enfin comprendre ce qu'est un test feuilleté et ce qu'est un bug, considérez l'image ci-dessus. La barre horizontale est de 100 pistes. Barre verte verticale - réussite au test, goutte rouge. Dans le cas d'un bug, l'historique de l'exécution semble naturel: une barre verte unie à la fin change de couleur en rouge. Cela signifie que c'est à cet endroit qu'un bug est apparu et que le test a commencé à tomber constamment. Si nous avons devant nous un test floconneux, alors son historique de course est une alternance continue de couleurs vertes et rouges.
Analyse des résultats des tests
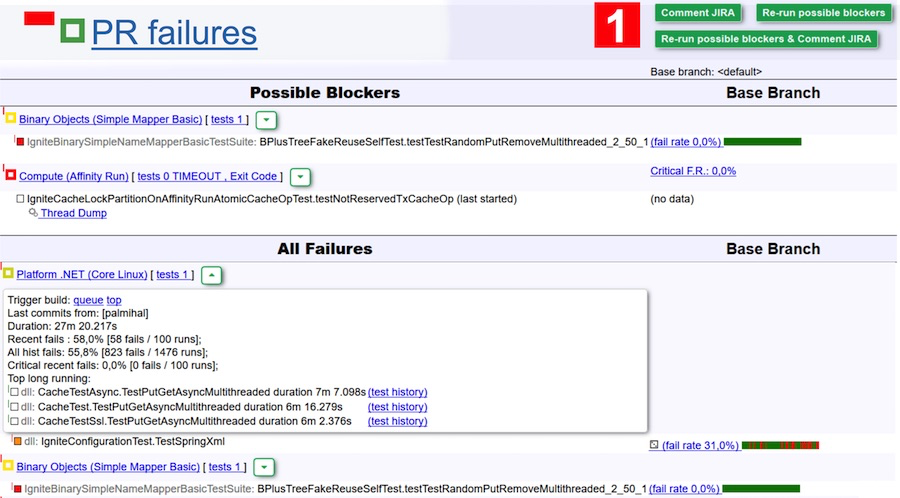
Par exemple, nous analysons les résultats de la réussite des tests dans la capture d'écran ci-dessus. Selon la version du bot, il peut y avoir deux plantages en raison d'un bogue - ils sont répertoriés dans le tableau des bloqueurs possibles. Mais il peut s'agir de tests irréguliers avec un faible taux d'échec. Pour exclure cette option, cliquez simplement sur le bouton Re-run possible blockers, et ces deux suites iront en double vérification. Pour rendre la tâche encore plus facile, vous pouvez cliquer sur Re-run possible blockers & comment JIRA, et obtenir un commentaire (et avec lui une notification par e-mail) du bot une fois la vérification terminée. Ensuite, entrez et voyez s'il y a un problème ou non.
Pour les critiques, c'est très cool. Vous pouvez oublier les modifications qui n'ont réussi aucun contrôle, mais cliquez simplement sur un certain nombre de modifications, cliquez sur le gros bouton vert de réexécution et attendez la lettre.
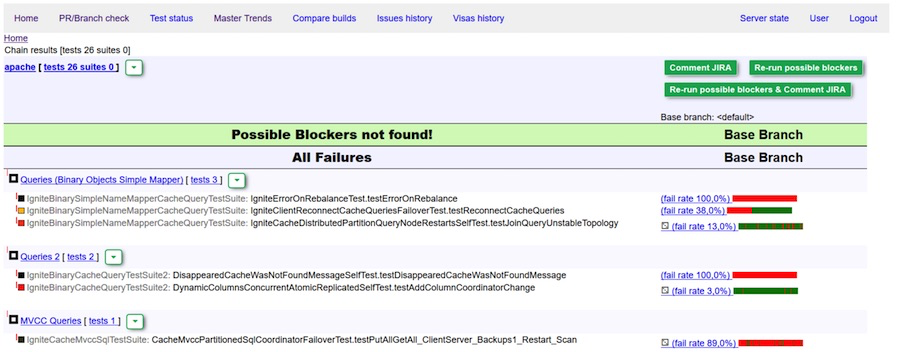 Rapport parfait: aucun bloqueur détecté
Rapport parfait: aucun bloqueur détecté

Visa vert (commentaire) du bot. Aucun bloqueur trouvé.
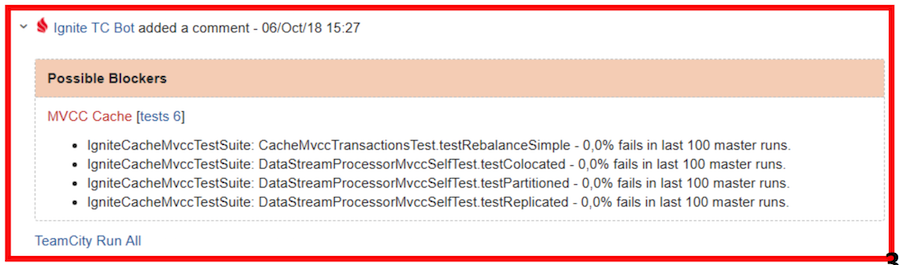
Visa rouge - double vérification et / ou modification des bogues requiseIl arrive que certains bugs fuient encore dans le «maître». Comme nous l'avons dit, avant cela a été combattu grâce à des notifications personnelles. Ou quelqu'un s'est assuré que rien ne tombait. Maintenant, nous utilisons une solution plus simple:

Lorsqu'un nouveau bogue est détecté, un message est envoyé à la liste de développement, qui indique les contributeurs et leurs changeurs, ce qui peut être la cause de l'erreur. Ainsi, toute la communauté découvrira qui a causé tout.
Ainsi, nous avons pu augmenter le nombre de correctifs et réduire considérablement le temps nécessaire pour résoudre le problème.
Surveillance de l'état de l'assistant
Une autre des fonctions du bot est de surveiller l'état de l'assistant avec les statistiques sur les derniers lancements.

Maîtriser les tendances

La page Tendances principales compare deux sélections «principales» pour des périodes spécifiques. Pour chaque élément du tableau affiche la valeur maximale, minimale et la médiane.

En plus des résultats généraux pour l'ensemble de l'échantillon, le tableau contient des graphiques pour chaque indicateur avec l'affichage des valeurs de chaque build. En cliquant sur un point, vous pouvez accéder aux résultats de la course sur TeamCity. De plus, il est possible de supprimer le résultat des statistiques. Cela est utile lorsque des valeurs anormales se produisent en raison de graves pannes, ce que le contributeur n'est probablement pas à blâmer. Ces résultats doivent être exclus afin qu'ils ne soient pas pris en compte lors du calcul des mêmes tests feuilletés. En outre, la génération peut également être distinguée pour suivre les résultats de chaque indicateur.
Apache Ignite Teamcity Bot compte désormais plus de 65 membres inscrits. Sur toute la période d'utilisation du bot, les visas ont reçu plus de 400 demandes de retrait, et en moyenne cinq visas sont délivrés par jour.
Structure de TeamCity Bot
Le bot est hébergé sur un serveur séparé, va sur ignite.apache.org pour les données, informe publiquement tout le monde sur la liste de développement - c'est notre principale plate-forme pour les développeurs Ignite - et écrit des visas sur les tickets via l'API JIRA.
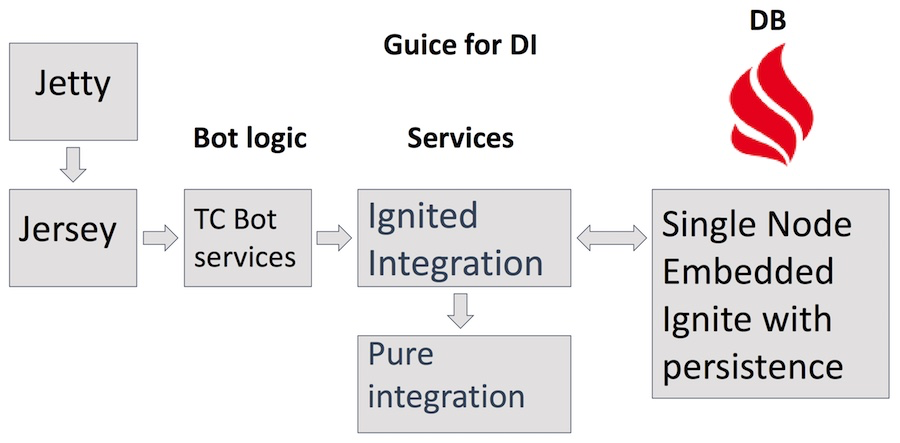
Il utilise le serveur Jetty, les servlets Jersey, un certain nombre de services avec une logique métier complexe du bot lui-même, y compris les services Teamcity, JIRA et GitHub qui accèdent au service Ignited Integration. En plus de cette intégration pure pour les requêtes http. En tant que stockage - propre produit d'Apache Ignite en mode intégré de configuration à nœud unique avec persistance active. En plus des avantages évidents de l'utilisation d'Ignite comme base de données, cela nous aide également à trouver divers domaines d'application d'Ignite et à comprendre ce qui est pratique et ce qui ne l'est pas.
La première version de l'implémentation du bot a été inspirée par un article sur la mise en cache REST et était un cache REST et des services GitHub et Teamcity. Teamcity xml et json renvoyés par le serveur ont été analysés par Pure Java Objects, qui ont ensuite été mis en cache. Au début, cela a fonctionné, et assez rapidement. Mais avec une augmentation de la quantité de données, les résultats ont commencé à se détériorer.
Il convient de noter que TeamCity supprime une histoire de plus de ~ 2 semaines, mais pas le bot. En fin de compte, avec cette approche, des tonnes de données sont apparues qui sont très difficiles à gérer.
Développement TeamCity Bot
La nouvelle approche implémente une option de stockage de données compacte et opte pour un petit nombre de partitions de cache. Un grand nombre de partitions sur un nœud affecte négativement la vitesse de synchronisation des données sur le disque et augmente l'heure de démarrage du cluster.
Toutes les mises à jour de données majeures sont effectuées de manière asynchrone, car sinon nous risquons d'obtenir une mauvaise UX en raison du retour lent des données TeamCity.
Pour les chaînes qui changent rarement leurs valeurs (par exemple, les noms des tests), un mappage simple est effectué dans id, qui est généré par Atomic Sequence. Voici un exemple d'une telle entrée:

Le nom de test long correspond au numéro int, qui est stocké dans toutes les générations. Cela économise une énorme quantité de ressources. En plus des méthodes qui retournent cette ligne se trouve l'intercepteur de cache en mémoire de Guava. Grâce à l'annotation du cache, même en tas, nous ne sélectionnons pas les lignes en les lisant dans Ignite by id. Et par id, nous obtenons toujours la même ligne, ce qui est bon pour les performances.
Pour les lignes "imprévisibles", par exemple, les journaux de trace de pile, différents types de compression sont utilisés - compression gzip, compression instantanée ou non compressée, selon la meilleure solution. Toutes ces méthodes aident à tenir un maximum de données en mémoire et à donner rapidement une réponse au client.
Pourquoi TeamCity Bot est meilleur
Cela ne veut pas dire que TeamCity ne possède pas les fonctionnalités énumérées ci-dessus. Ils le sont, mais dispersés sur un tas d'endroits différents. Dans le bot, tout est rassemblé sur une seule page et vous pouvez rapidement comprendre quel est le problème.
Un bon ajout est la lettre que le bot envoie sur la feuille de développement lorsqu'il détecte un problème. Immédiatement dans la communauté, il y a une occasion d'entamer une discussion: «Allons, peut-être, maintenant nous allons inverser?». Cela ajoute de la confiance aux examinateurs.
Avec le bot, il est beaucoup plus facile pour les nouveaux contributeurs de rejoindre le processus de développement. Lorsque vous effectuez votre premier correctif, vous ne savez pas toujours ce que les modifications apportées peuvent impliquer. Et en plongeant tête baissée dans l'analyse des résultats des tests sur TeamCity, vous pouvez facilement perdre votre enthousiasme pour un développement ultérieur. Apache Ignite TeamCity Bot vous aidera à comprendre rapidement s'il y a un problème et à maintenir votre enthousiasme.
Nous espérons que le bot simplifiera la vie des contributeurs actuels et attirera de nouvelles personnes dans la communauté. Enfin, nous conseillons, bien sûr, d'éviter l'apparition d'un grand nombre de tests feuilletés, car il est difficile de les gérer. Et faites confiance aux robots - ils n'ont aucune préférence et ne prennent pas la parole des gens pour cela.