
 Anton Chaynikov, développeur de Data Science, Redmadrobot
Anton Chaynikov, développeur de Data Science, Redmadrobot
Bonjour, Habr! Aujourd'hui, je vais parler des épines sur le chemin du chatbot, ce qui facilite le travail des opérateurs de chat de la compagnie d'assurance. Plus précisément, comment nous avons appris au bot à distinguer les demandes les unes des autres à l'aide de l'apprentissage automatique. Quels modèles ont été expérimentés et lesquels ont obtenu les résultats. Comment quatre approches pour nettoyer et enrichir les données de qualité décente et cinq tentatives pour nettoyer les données de qualité "indécente".
Défi
Le chat de la compagnie d'assurance reçoit + 100 500 appels clients par jour. La plupart des questions sont simples et répétitives, mais les opérateurs ne sont pas plus aisés et les clients doivent encore attendre cinq à dix minutes. Comment améliorer la qualité de service et optimiser les coûts de main-d'œuvre pour que les opérateurs aient moins de routine et que les utilisateurs aient des sensations plus agréables à résoudre rapidement leurs problèmes?
Et nous ferons un chatbot. Laissez-le lire les messages des utilisateurs, donner des instructions pour les cas simples et poser des questions standard pour les cas complexes afin d'obtenir les informations dont l'opérateur a besoin. Un opérateur en direct a une arborescence de scripts - un script (ou un organigramme) qui dit quelles questions les utilisateurs peuvent poser et comment y répondre. Nous prendrions ce schéma et le placerions dans un chatbot, mais c'est une malchance - le chatbot ne comprend pas humainement et ne sait pas comment relier la question de l'utilisateur à la branche de script.
Donc, nous allons lui apprendre à l'aide du bon vieux machine learning. Mais vous ne pouvez pas simplement prendre un morceau de données généré par les utilisateurs et lui apprendre un modèle de qualité décent. Pour ce faire, vous devez expérimenter l'architecture du modèle, les données - pour les nettoyer et parfois les collecter à nouveau.
Comment enseigner à un bot:
- Examinons les options des modèles: comment la taille de l'ensemble de données, les détails de la vectorisation des textes, l'abaissement de la dimension, le classificateur et la précision finale sont combinés.
- Nettoyons les données décentes: nous trouverons des classes qui peuvent être jetées en toute sécurité; nous découvrirons pourquoi les six derniers mois de majoration sont meilleurs que les trois précédents; déterminer où se trouve le modèle et où le balisage; Découvrez comment les fautes de frappe peuvent être utiles.
- Nous allons nettoyer les données «indécentes»: nous découvrirons quand le clustering est utile et inutile, car les utilisateurs et les opérateurs parlent quand il est temps d'arrêter de souffrir et d'aller collecter le balisage.
La texture
Nous avions deux clients - des compagnies d'assurance avec des chats en ligne - et des projets de formation de chatbot (nous ne les appellerons pas, ce n'est pas important), avec une qualité de données très différente. Eh bien, si la moitié des problèmes du deuxième projet pouvaient être résolus par des manipulations du premier. Les détails sont ci-dessous.
D'un point de vue technique, notre tâche est de classer les textes. Cela se fait en deux étapes: d'abord les textes sont vectorisés (à l'aide de tf-idf, doc2vec, etc.), puis le modèle de classification est formé sur les vecteurs (et classes) obtenus - forêt aléatoire, SVM, réseau de neurones, etc. et ainsi de suite.
D'où proviennent les données:
- Historique de chat Sql-upload. Champs de téléchargement pertinents: texte du message; auteur (client ou opérateur); regrouper les messages dans des dialogues; horodatage; catégorie de contact client (questions sur l'assurance responsabilité civile automobile obligatoire, l'assurance coque, l'assurance médicale volontaire; questions sur le site; questions sur les programmes de fidélisation; questions sur l'évolution des conditions d'assurance, etc.).
- Un arbre de scripts, ou des séquences de questions et réponses des opérateurs aux clients avec différentes demandes.
Sans validation, bien sûr, nulle part. Tous les modèles ont été formés sur 70% des données et évalués en fonction des résultats sur les 30% restants.
Mesures de qualité pour les modèles que nous avons utilisés:
- En formation: logloss, pour la différenciabilité;
- Lors de la rédaction des rapports: précision de classification sur un échantillon de test, pour plus de simplicité et de clarté (y compris pour le client);
- Lors du choix de la direction pour d'autres actions: l'intuition d'un data scientist qui regarde attentivement les résultats.
Expériences de modèle
Il est rare que la tâche indique immédiatement quel modèle donnera les meilleurs résultats. Alors ici: sans expérimentation, nulle part.
Nous allons essayer des options de vectorisation:
- tf-idf en un seul mot;
- tf-idf sur des triplets de caractères (ci-après: 3 grammes);
- tf-idf sur 2, 3, 4, 5 grammes séparément;
- tf-idf sur 2, 3, 4, 5 grammes pris ensemble;
- Tout ce qui précède + réduction des mots dans le texte source sous forme de dictionnaire;
- Tout ce qui précède + diminution de dimension par la méthode SVD tronquée;
- Avec le nombre de mesures: 10, 30, 100, 300;
- doc2vec, formé sur le corps des textes de la tâche.
Les options de classification dans ce contexte semblent plutôt médiocres: SVM, XGBoost, LSTM, forêts aléatoires, bayés naïves, forêts aléatoires au-dessus des prédictions SVM et XGB.
Et bien que nous ayons vérifié la reproductibilité des résultats sur trois ensembles de données assemblés indépendamment et leurs fragments, nous ne pouvons que garantir leur large applicabilité.
Les résultats des expériences:
- Dans la chaîne «pré-traitement-vectorisation-abaissement dimension-classification», l'effet du choix à chaque étape est presque indépendant des autres étapes. Ce qui est très pratique, vous ne pouvez pas parcourir une douzaine d'options avec chaque nouvelle idée et utiliser l'option la plus connue à chaque étape.
- tf-idf en mots perd à 3 grammes (précision 0,72 vs 0,78). 2, 4, 5 grammes perdent à 3 grammes (0,75-0,76 vs 0,78). {2; 5} -grammes tous ensemble surpassent un peu les 3 grammes. Compte tenu de la forte augmentation de la mémoire requise, nous avons décidé de négliger la formation avec un gain de précision de 0,4%.
- Comparé à tf-idf de toutes les variétés, doc2vec était impuissant (précision 0,4 et inférieure). Il vaudrait la peine d'essayer de l'entraîner non pas sur le corps de la tâche (~ 250 000 textes), mais sur une tâche beaucoup plus importante (2,5 à 25 millions de textes), mais jusqu'à présent, hélas, vos mains ne sont pas parvenues.
- SVD tronqué n'a pas aidé. La précision augmente de façon monotone avec l'augmentation de la mesure, ce qui permet d'atteindre une précision sans TSVD.
- Parmi les classificateurs, XGBoost gagne par une marge notable (+ 5–10%). Les concurrents les plus proches sont SVM et les forêts aléatoires. Naive Bayes n'est pas un concurrent même pour les forêts aléatoires.
- Le succès de LSTM dépend fortement de la taille de l'ensemble de données: sur un échantillon de 100 000 objets, il est capable de rivaliser avec XGB. Sur un échantillon de 6000 - dans le retard avec Bayes.
- Une forêt aléatoire au-dessus de SVM et XGB est toujours d'accord avec XGB, ou se trompe davantage. C'est très triste, nous espérions que SVM trouverait dans les données au moins quelques schémas qui ne sont pas disponibles pour XGB, mais hélas.
- XGBoost est compliqué de stabilité. Par exemple, sa mise à niveau de la version 0,72 à 0,80 a inexplicablement réduit la précision des modèles entraînés de 5 à 10%. Et encore une chose: XGBoost prend en charge la modification des paramètres de formation pendant la formation et la compatibilité avec l'API scikit-learn standard, mais strictement séparément. Vous ne pouvez pas faire les deux ensemble. J'ai dû le réparer.
- Si vous apportez des mots dans un dictionnaire, cela améliore un peu la qualité, en combinaison avec tf-idf dans les mots, mais cela est inutile dans tous les autres cas. Au final, nous l'avons désactivé pour gagner du temps.
Expérience 1. Nettoyage des données ou quoi faire avec le balisage
Les opérateurs de chat ne sont que des personnes. Lors de la définition des catégories de requêtes utilisateur, elles se trompent souvent et ont des interprétations différentes des limites entre les catégories. Par conséquent, les données source doivent être impitoyablement et intensivement nettoyées.
Nos données sur la formation des modèles sur le premier projet:
- Un historique des messages de chat en ligne sur plusieurs années. Il s'agit de 250 000 messages dans 60 000 conversations. À la fin du dialogue, l'opérateur a sélectionné la catégorie à laquelle appartient l'appel de l'utilisateur. Il y a environ 50 catégories dans cet ensemble de données.
- Arbre de script. Dans notre cas, les opérateurs n'avaient pas de scripts de travail.
Quelle est exactement la mauvaise donnée, nous avons formulé des hypothèses, puis vérifié et, si possible, corrigé. Voici ce qui s'est passé:
La première approche. De la grande liste complète des classes, vous pouvez en toute sécurité laisser 5-10.
Nous écartons les petites classes (<1% de l'échantillon): peu de données + petit impact. Nous réunissons des classes difficiles à distinguer, auxquelles les opérateurs réagissent toujours de la même manière. Par exemple:
'dms' + 'comment prendre rendez-vous avec un médecin' + 'question sur comment remplir le programme'
«annulation» + «statut d'annulation» + «annulation de la politique payée»
'question de renouvellement' + 'comment renouveler la politique?'
Ensuite, nous jetons des classes comme «autre», «autre» et similaires: pour un chatbot, elles sont inutiles (redirigées de toute façon vers l'opérateur), et en même temps, elles nuisent considérablement à la précision, puisque 20% des demandes (30, 50, 90) sont classées par les opérateurs et ici. Maintenant, nous jetons la classe avec laquelle le chatbot ne peut pas (encore) travailler.
Résultat: dans un cas, croissance d'une précision de 0,40 à 0,69, dans un autre, de 0,66 à 0,77.
La deuxième approche. Au début du chat, les opérateurs eux-mêmes comprennent mal comment choisir une classe à contacter par l'utilisateur, il y a donc beaucoup de «bruit» et d'erreurs dans les données.
Expérience: nous ne prenons que les deux (trois, six, ...) derniers mois de dialogues et formons le modèle
eux.
Résultat: dans un cas remarquable, la précision est passée de 0,40 à 0,60, dans un autre - de 0,69 à 0,78.
La troisième approche. Parfois, une précision de 0,70 ne signifie pas «le modèle se trompe dans 30% des cas», mais «dans 30% des cas, le balisage est faux et le modèle le corrige très raisonnablement».
Par des mesures telles que la précision ou la perte de journal, cette hypothèse ne peut pas être vérifiée. Aux fins de l'expérience, nous nous sommes limités au regard d'un data scientist, mais dans le cas idéal, vous devez réorganiser qualitativement l'ensemble de données, sans oublier la validation croisée.
Pour travailler avec de tels échantillons, nous avons imaginé le processus de "l'enrichissement itératif":
- Divisez l'ensemble de données en 3-4 fragments.
- Former le modèle sur le premier fragment.
- Prédisez les classes de la seconde par le modèle entraîné.
- Examinez attentivement les classes prévues et le degré de confiance du modèle, choisissez la valeur limite de confiance.
- Supprimez les textes (objets) prédits avec confiance en dessous de la limite du deuxième fragment, entraînez le modèle à ce sujet.
- Répétez jusqu'à ce que les fragments se fatiguent ou s'épuisent.
D'une part, les résultats sont excellents: le premier modèle d'itération a une précision de 70%, le second - 95%, le troisième - 99 +%. Un examen attentif des résultats des prédictions confirme pleinement cette précision.
D'un autre côté, comment vérifier systématiquement dans ce processus que les modèles suivants n'apprennent pas les erreurs des précédents? Il existe une idée pour tester le processus sur un ensemble de données manuellement «bruyant» avec un balisage initial de haute qualité, tel que MNIST. Mais, hélas, il n'y avait pas assez de temps pour cela. Et sans vérification, nous n'avons pas osé lancer l'enrichissement itératif et les modèles résultants en production.
La quatrième approche. L'ensemble de données peut être étendu - et ainsi augmenter la précision et réduire le recyclage, en ajoutant de nombreuses fautes de frappe aux textes existants.
Les fautes de frappe sont des fautes de frappe - doubler une lettre, sauter une lettre, réorganiser les lettres voisines par endroits, remplacer une lettre par une lettre adjacente sur le clavier.
Expérience: La proportion de p lettres dans lesquelles une faute de frappe se produira: 2%, 4%, 6%, 8%, 10%, 12%. Augmentation de l'ensemble de données: généralement jusqu'à 60 000 répliques. Selon la taille initiale (après les filtres), cela signifiait une augmentation de 3 à 30 fois.
Résultat: dépend de l'ensemble de données. Sur un petit ensemble de données (~ 300 répliques), 4 à 6% des fautes de frappe donnent une augmentation stable et significative de la précision (0,40 → 0,60). Sur les grands ensembles de données, tout est pire. Avec une proportion de fautes de frappe de 8% ou plus, les textes deviennent insensés et la précision diminue. Avec un taux d'erreur de 2 à 8%, la précision varie de quelques pour cent, dépasse très rarement la précision sans fautes de frappe et, comme il semble, il n'est pas nécessaire d'augmenter le temps d'entraînement plusieurs fois.
En conséquence, nous obtenons un modèle qui distingue 5 classes d'appels avec une précision de 0,86. Nous coordonnons avec le client les textes des questions et réponses pour chacune des cinq fourchettes, attachons les textes au chatbot, les envoyons au QA.
Expérience 2. Jusqu'au genou dans les données, ou quoi faire sans balisage
Ayant obtenu de bons résultats sur le premier projet, nous avons abordé le second en toute confiance. Mais heureusement, nous n'avons pas oublié comment être surpris.
Ce que nous avons rencontré:
- Un arbre de script à cinq branches convenu avec le client il y a environ un an.
- Un échantillon balisé de 500 messages et 11 classes d'origine inconnue.
- Taggé par les opérateurs de chat à partir de 220 000 messages, 21 000 conversations et 50 autres classes.
- Le modèle SVM, formé sur le premier échantillon, avec une précision de 0,69, qui a été hérité de la précédente équipe de scientifiques des données. Pourquoi SVM, l'histoire est silencieuse.
Tout d'abord, nous regardons les classes: dans l'arborescence des scripts, dans l'exemple du modèle SVM, dans l'exemple principal. Et voici ce que nous voyons:
- Les classes du modèle SVM correspondent grosso modo aux branches des scripts, mais ne correspondent en aucun cas aux classes d'un large échantillon.
- L'arbre de script a été écrit sur les processus métier il y a un an et est obsolète presque inutile. Le modèle SVM en est déprécié.
- Les deux classes les plus importantes du grand échantillon sont les ventes (50%) et les autres (45%).
- Sur les cinq classes suivantes, trois sont aussi générales que les ventes.
- Les 45 classes restantes contiennent chacune moins de 30 dialogues. C'est-à-dire nous n'avons pas d'arborescence de script, il n'y a pas de liste de classes et pas de balisage.
Que faire dans de tels cas? Nous avons retroussé nos manches et sommes partis nous-mêmes pour obtenir des cours et du balisage à partir des données.
La première tentative. Essayons de regrouper les questions des utilisateurs, c'est-à-dire Les premiers messages du dialogue, à l'exception des salutations.
Nous vérifions. Nous vectorisons des répliques en comptant 3 grammes. Nous abaissons la dimension aux dix premières mesures de TSVD. Nous nous regroupons par regroupement aggloméré avec la distance euclidienne et la fonction Ward cible. Baissez à nouveau la dimension à l'aide de t-SNE (jusqu'à deux mesures pour que vous puissiez regarder les résultats avec vos yeux). Nous dessinons des répliques de points sur le plan, en peignant aux couleurs des grappes.
Résultat: peur et horreur. Grappes saines, on peut supposer qu'il n'y a pas:
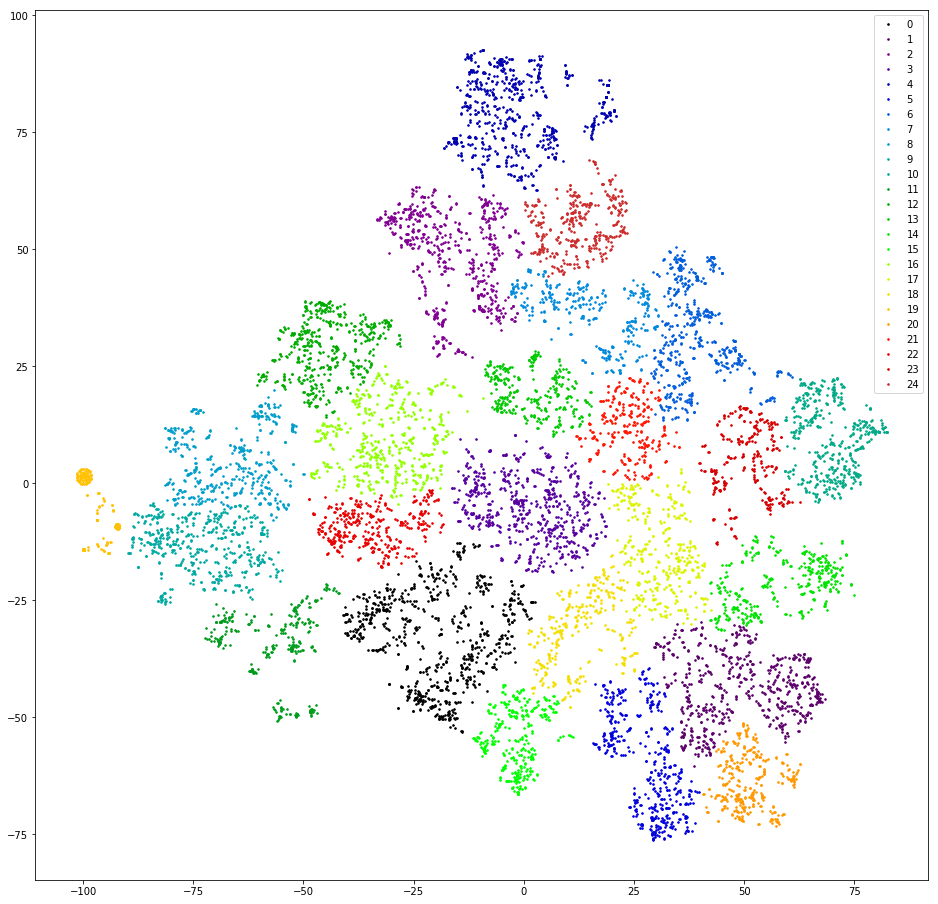
Presque pas - il y en a un, orange à gauche, car tous les messages contiennent le «@» de 3 grammes. Ce 3 grammes est un artefact de prétraitement. Quelque part dans le processus de filtrage des signes de ponctuation, «@» était non seulement non filtré, mais aussi envahi par des espaces. Mais l'artefact est utile. Ce cluster comprend les utilisateurs qui écrivent d'abord leur e-mail. Malheureusement, ce n'est que par la disponibilité du courrier que la demande de l'utilisateur n'est pas claire. Nous continuons.
La deuxième tentative. Et si les opérateurs répondent souvent avec des liaisons plus ou moins standard?
Nous vérifions. Nous extrayons des sous-chaînes de type lien à partir des messages de l'opérateur, modifions légèrement les liens, d'orthographe différente, mais de même signification (http / https, / search? City =% city%), considérons les fréquences des liens.
Résultat: peu prometteur. Premièrement, les opérateurs ne répondent qu'à une petite fraction des demandes (<10%) avec des liens. Deuxièmement, même après le nettoyage et le filtrage manuels des liens qui se sont produits une fois, il y en a plus de trente. Troisièmement, dans le comportement des utilisateurs qui terminent le dialogue par un lien, il n'y a pas de similitude particulière.
La troisième tentative. Cherchons les réponses standard des opérateurs - que se passe-t-il s'ils seront des indicateurs de toute classification des messages?
Nous vérifions. Dans chaque dialogue, nous prenons la dernière réplique de l'opérateur (à part les adieux: «Je peux aider autre chose», etc.) et considérons la fréquence des répliques uniques.
Résultat: prometteur, mais peu pratique. 50% des réponses des opérateurs sont uniques, 10 à 20% supplémentaires sont trouvées deux fois, les 30 à 40% restants sont couverts par un nombre relativement restreint de modèles populaires. Relativement petit - environ trois cents. Un examen attentif de ces modèles révèle que beaucoup d'entre eux sont des variantes de la même réponse en termes de signification - ils diffèrent où par une lettre, où par un mot, où par un paragraphe. Je voudrais regrouper ces réponses qui ont un sens proche.
La quatrième tentative. Regroupement des dernières répliques de déclarations. Celles-ci sont bien mieux regroupées:
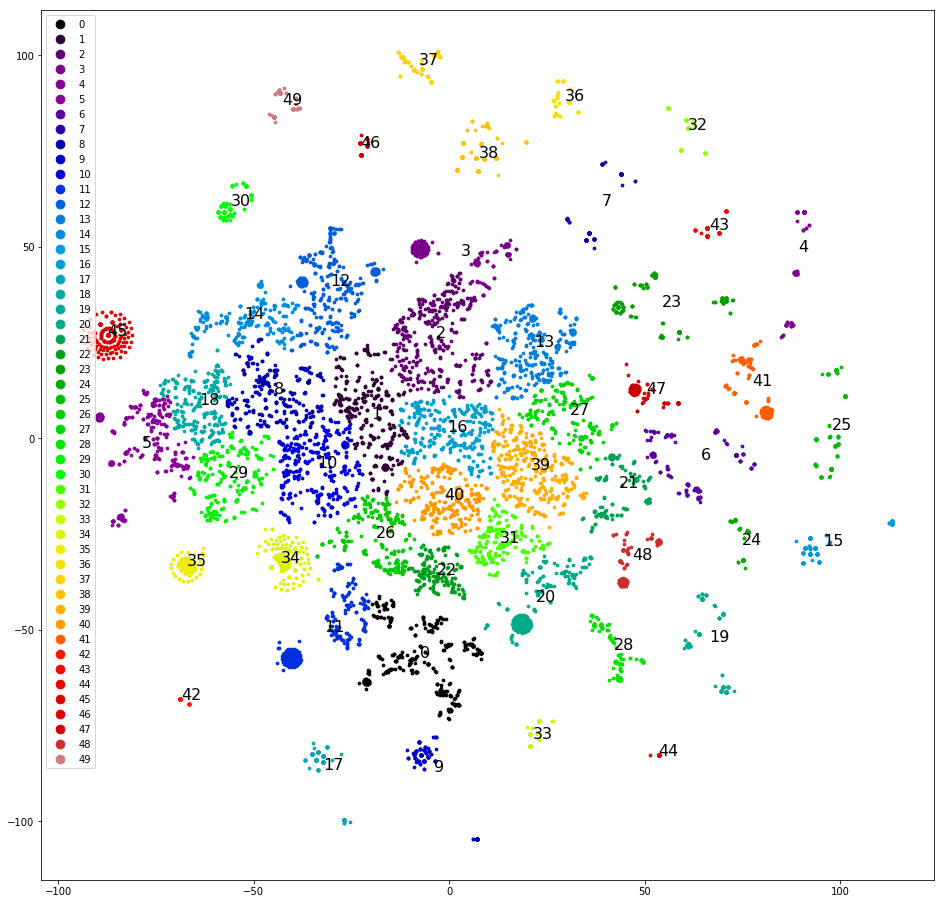
Vous pouvez déjà travailler avec cela.
Nous regroupons et dessinons des répliques sur le plan, comme lors de la première tentative, déterminons manuellement les clusters les plus clairement séparés, les supprimons de l'ensemble de données et clusters à nouveau. Après avoir séparé environ la moitié de l'ensemble de données, les clusters clairs se terminent et nous commençons à réfléchir aux classes à leur affecter. Nous dispersons les grappes selon les cinq classes d'origine - l'échantillon est «asymétrique», et trois des cinq classes d'origine ne reçoivent pas une seule grappe. Dommage. Nous répartissons les grappes en cinq classes, que nous désignons au hasard, sur: «appeler», «venir», «attendre un jour une réponse», «problèmes avec captcha», «autre». L'inclinaison est moindre, mais la précision n'est que de 0,4 à 0,5. Encore mal. Attribuez à chacun des 30+ clusters sa propre classe. L'échantillon est de nouveau biaisé et la précision est de nouveau de 0,5, bien qu'environ cinq classes sélectionnées aient une précision et une exhaustivité décentes (0,8 et plus). Mais le résultat n'est toujours pas impressionnant.
La cinquième tentative. Nous avons besoin de tous les tenants et aboutissants du clustering. Nous récupérons le dendrogramme de clustering complet au lieu des trente premiers clusters. Nous l'enregistrons dans un format accessible aux analystes clients et les aidons à faire du balisage - nous esquissons la liste des classes.
Pour chaque message, nous calculons une chaîne de clusters, qui inclut chaque message, à partir de la racine. Nous construisons une table avec des colonnes: texte, id du premier cluster de la chaîne, id du deuxième cluster de la chaîne, ..., id du cluster correspondant au texte. Nous enregistrons la table en csv / xls. De plus, vous pouvez travailler avec des outils de bureau.
Nous donnons les données et un croquis de la liste des classes à baliser au client. Les analystes clients ont re-marqué ~ 10 000 premiers messages d'utilisateurs. Nous, déjà enseignés par l'expérience, avons demandé de marquer chaque message au moins deux fois. Et pas en vain - 4 000 de ces 10 000 doivent être jetés, car les deux analystes ont marqué différemment. Sur les 6 000 restants, nous avons assez rapidement répété les succès du premier projet:
- Référence: pas de filtrage du tout - précision 0,66.
- Nous combinons les classes qui sont les mêmes du point de vue de l'opérateur. Nous obtenons une précision de 0,73.
- Nous supprimons la classe «Autre» - la précision augmente à 0,79.
Le modèle est prêt, vous devez maintenant dessiner une arborescence de scripts. Pour des raisons que nous ne pouvons pas expliquer, nous n'avions pas accès aux scripts pour les réponses des opérateurs. Nous n'avons pas été surpris, nous avons fait semblant d'être des utilisateurs et pendant quelques heures sur le terrain, nous avons collecté des modèles de réponse et clarifié les questions des opérateurs pour toutes les occasions. Ils les ont décorés dans un arbre, les ont emballés dans un bot et sont allés tester. Approuvé par le client.
Conclusions ou quelle expérience a montré:
- Vous pouvez expérimenter avec des parties du modèle (prétraitement, vectorisation, classification, etc.) individuellement.
- XGBoost gouverne toujours la balle, bien que si vous avez besoin de quelque chose d'inhabituel, vous avez des problèmes.
- L'utilisateur est un périphérique d'entrée chaotique, vous devez donc nettoyer les données utilisateur.
- L'enrichissement itératif est cool, bien que dangereux.
- Parfois, il vaut la peine de rendre les données au client pour le balisage. Mais n'oubliez pas de l'aider à obtenir un résultat de qualité.
À conclure.