
Le sujet de l'article est assez étroitement ciblé, mais il peut être utile à ceux qui développent leurs propres entrepôts de données et pensent à l'intégration avec Spring Framework.
Contexte
Les développeurs n'aiment généralement pas changer leurs habitudes (souvent, les cadres sont également inclus dans la liste des habitudes). Quand j'ai commencé à travailler avec CUBA , je n'avais pas à apprendre trop de nouvelles choses, il était possible de s'impliquer activement dans le travail sur le projet presque immédiatement. Mais il y avait une chose sur laquelle je devais m'asseoir plus longtemps - c'était de travailler avec des données.
Spring a plusieurs bibliothèques qui peuvent être utilisées pour travailler avec la base de données, l'une des plus populaires est spring-data-jpa , qui permet dans la plupart des cas de ne pas écrire SQL ou JPQL. Vous avez juste besoin de créer une interface spéciale avec des méthodes qui sont nommées d'une manière spéciale et Spring générera et fera le reste du travail pour vous sur la récupération des données de la base de données et la création d'instances d'objets d'entité.
Voici l'interface, avec une méthode pour compter les clients avec un nom de famille donné.
interface CustomerRepository extends CrudRepository<Customer, Long> { long countByLastName(String lastName); }
Cette interface peut être utilisée directement dans les services Spring sans créer d'implémentation, ce qui accélère considérablement le travail.
CUBA dispose d'une API pour travailler avec des données, qui comprend diverses fonctionnalités telles que des entités partiellement chargées ou un système de sécurité délicat avec contrôle d'accès aux attributs d'entité et aux lignes dans les tables de base de données. Mais cette API est légèrement différente de ce à quoi les développeurs sont habitués dans Spring Data ou JPA / Hibernate.
Pourquoi n'y a-t-il pas de référentiels JPA dans CUBA et puis-je les ajouter?
Utilisation de données dans CUBA
Dans CUBA, il existe trois classes principales responsables de l'utilisation des données: DataStore, EntityManager et DataManager.
DataStore est une abstraction de haut niveau pour tout stockage de données: base de données, système de fichiers ou stockage cloud. Cette API vous permet d'effectuer des opérations de base sur les données. Dans la plupart des cas, les développeurs n'ont pas besoin de travailler directement avec le DataStore, sauf lors du développement de leur propre référentiel ou si un accès très spécial aux données du référentiel est requis.
EntityManager est une copie du célèbre JPA EntityManager. Contrairement à l'implémentation standard, il dispose de méthodes spéciales pour travailler avec les représentations CUBA , pour la suppression «logique» (logique) des données, et aussi pour travailler avec les requêtes dans CUBA . Comme dans le cas du DataStore, dans 90% des projets, un développeur ordinaire n'aura pas à traiter avec EntityManager, sauf lorsqu'il est nécessaire de répondre à certaines demandes en contournant le système de restriction d'accès aux données.
DataManager est la classe principale pour travailler avec des données dans CUBA. Fournit une API pour la manipulation des données et prend en charge le contrôle d'accès aux données, y compris l'accès aux attributs et les restrictions au niveau des lignes. Le DataManager modifie implicitement toutes les requêtes qui s'exécutent dans CUBA. Par exemple, il peut exclure des champs de table auxquels l'utilisateur actuel n'a pas accès à partir de l'instruction select et ajouter des conditions where pour exclure des lignes de table de la sélection. Et cela facilite la vie des développeurs, car vous n'avez pas à réfléchir à la façon d'écrire correctement les requêtes en tenant compte des droits d'accès, CUBA le fait automatiquement en fonction des données des tables de service de base de données.
Vous trouverez ci-dessous un diagramme de l'interaction des composants CUBA impliqués dans la récupération des données via le DataManager.
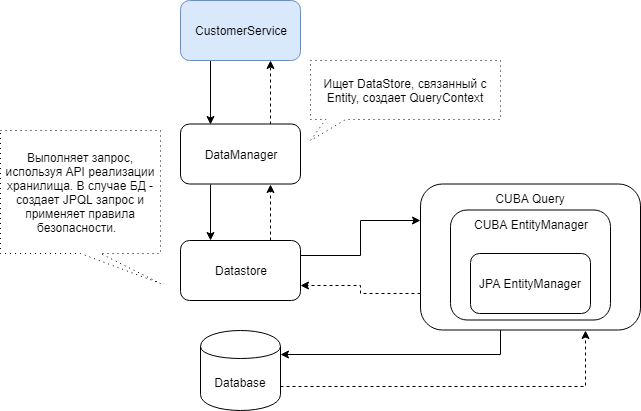
À l'aide du DataManager, vous pouvez relativement facilement charger des entités et des hiérarchies entières d'entités à l'aide des vues CUBA. Dans sa forme la plus simple, la requête ressemble à ceci:
dataManager.load(Customer.class).list();
Comme déjà mentionné, DataManager filtrera les enregistrements «supprimés logiquement», supprimera les attributs interdits de la demande et ouvrira et fermera automatiquement la transaction.
Mais, quand il s'agit de requêtes plus compliquées, vous devez écrire JPQL en CUBA.
Par exemple, si vous devez compter les clients avec un nom de famille donné, comme dans l'exemple de la section précédente, vous devez écrire quelque chose comme ce code:
public Long countByLastName(String lastName) { return dataManager .loadValue("select count(c) from sample$Customer c where c.lastName = :lastName", Long.class) .parameter("lastName", lastName) .one(); }
ou tel:
public Long countByLastName(String lastName) { LoadContext<Customer> loadContext = LoadContext.create(Customer.class); loadContext .setQueryString("select c from sample$Customer c where c.lastName = :lastName") .setParameter("lastName", lastName); return dataManager.getCount(loadContext); }
Dans l'API CUBA, vous devez passer une expression JPQL sous forme de chaîne (l'API Criteria n'est pas encore prise en charge), c'est une façon lisible et compréhensible de créer des requêtes, mais le débogage de telles requêtes peut apporter beaucoup de minutes amusantes. De plus, les chaînes JPQL ne sont ni vérifiées par le compilateur ni par Spring Framework lors de l'initialisation du conteneur, ce qui entraîne des erreurs uniquement dans le Runtime.
Comparez cela avec Spring JPA:
interface CustomerRepository extends CrudRepository<Customer, Long> { long countByLastName(String lastName); }
Le code est trois fois plus court et sans lignes. De plus, le nom de la méthode countByLastName vérifié lors de l'initialisation du conteneur Spring. S'il y a une faute de frappe et que vous avez écrit countByLastNsme , l'application se bloquera avec une erreur lors du déploiement:
Caused by: org.springframework.data.mapping.PropertyReferenceException: No property LastNsme found for type Customer!
CUBA est construit autour de Spring Framework, vous pouvez donc utiliser la bibliothèque spring-data-jpa dans une application écrite en utilisant CUBA, mais il y a un petit problème - le contrôle d'accès. L'implémentation Spring CrudRepository utilise son EntityManager. Ainsi, toutes les requêtes seront exécutées en contournant le DataManager. Ainsi, pour utiliser les référentiels JPA dans CUBA, vous devez remplacer tous les appels EntityManager par des appels DataManager et ajouter la prise en charge des vues CUBA.
Quelqu'un peut dire que spring-data-jpa est une boîte noire incontrôlée et il est toujours préférable d'écrire du JPQL pur ou même du SQL. C'est le problème éternel de l'équilibre entre la commodité et le niveau d'abstraction. Tout le monde choisit la méthode qu'il préfère, mais avoir un moyen supplémentaire de travailler avec des données dans l'arsenal ne fera jamais de mal. Et pour ceux qui ont besoin de plus de contrôle, Spring a un moyen de définir leur propre demande de méthodes de référentiel JPA.
Implémentation
Les référentiels JPA sont implémentés en tant que module CUBA à l'aide de la bibliothèque spring-data-commons . Nous avons abandonné l'idée de modifier spring-data-jpa, car la quantité de travail serait bien plus importante que d'écrire notre propre générateur de requêtes. D'autant plus que Spring-data-commons fait l'essentiel du travail. Par exemple, l'analyse d'un nom de méthode et l'association d'un nom à des classes et à des propriétés sont entièrement effectuées dans cette bibliothèque. Spring-data-commons contient toutes les classes de base nécessaires pour implémenter vos propres référentiels et cela ne prend pas beaucoup d'efforts pour l'implémenter. Par exemple, cette bibliothèque est utilisée dans spring-data-mongodb .
La chose la plus difficile a été d'implémenter avec précision la génération JPQL basée sur une hiérarchie d'objets - le résultat de l'analyse du nom de la méthode. Mais, heureusement, une tâche similaire a déjà été implémentée dans Apache Ignite, donc le code a été pris à partir de là et adapté un peu pour générer JPQL au lieu de SQL et prendre en charge l'opérateur de delete .
Spring-data-commons utilise le proxy pour créer dynamiquement des implémentations d'interface. Lorsque le contexte d'application CUBA est initialisé, tous les liens vers les interfaces sont remplacés par des liens vers des bacs proxy publiés dans le contexte. Lorsque la méthode d'interface est appelée, elle est interceptée par l'objet proxy correspondant. Cet objet génère ensuite une requête JPQL par le nom de la méthode, substitue les paramètres et envoie la requête avec paramètres au DataManager pour exécution. Le diagramme suivant montre un processus d'interaction simplifié entre les composants clés du module.

Utilisation de référentiels dans CUBA
Pour utiliser les référentiels dans CUBA, il vous suffit de connecter le module dans le fichier de construction du projet:
appComponent("com.haulmont.addons.cuba.jpa.repositories:cuba-jpa-repositories-global:0.1-SNAPSHOT")
Vous pouvez utiliser la configuration XML pour «activer» les référentiels:
<?xml version="1.0" encoding="UTF-8"?> <beans:beans xmlns:beans="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:repositories="http://www.cuba-platform.org/schema/data/jpa" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.3.xsd http://www.cuba-platform.org/schema/data/jpa http://www.cuba-platform.org/schema/data/jpa/cuba-repositories.xsd"> <context:component-scan base-package="com.company.sample"/> <repositories:repositories base-package="com.company.sample.core.repositories"/> </beans:beans>
Et vous pouvez utiliser les annotations:
@Configuration @EnableCubaRepositories public class AppConfig {
Une fois la prise en charge des référentiels activée, vous pouvez les créer sous la forme habituelle, par exemple:
public interface CustomerRepository extends CubaJpaRepository<Customer, UUID> { long countByLastName(String lastName); List<Customer> findByNameIsIn(List<String> names); @CubaView("_minimal") @JpqlQuery("select c from sample$Customer c where c.name like concat(:name, '%')") List<Customer> findByNameStartingWith(String name); }
Pour chaque méthode, vous pouvez utiliser des annotations:
@CubaView - pour définir la vue CUBA à utiliser dans le DataManager@JpqlQuery - pour spécifier la requête JPQL qui sera exécutée, quel que soit le nom de la méthode.
Ce module est utilisé dans le module global du framework CUBA, par conséquent, les référentiels peuvent être utilisés à la fois dans le module core et sur le web . La seule chose dont vous devez vous souvenir est d'activer les référentiels dans les fichiers de configuration des deux modules.
Un exemple d'utilisation du référentiel dans le service CUBA:
@Service(CustomerService.NAME) public class CustomerServiceBean implements PersonService { @Inject private CustomerRepository customerRepository; @Override public List<Date> getCustomersBirthDatesByLastName(String name) { return customerRepository.findByNameStartingWith(name) .stream().map(Customer::getBirthDate).collect(Collectors.toList()); } }
Conclusion
CUBA est un cadre flexible. Si vous souhaitez y ajouter quelque chose, il n'est pas nécessaire de réparer le noyau vous-même ou d'attendre une nouvelle version. J'espère que ce module rend le développement de CUBA plus efficace et plus rapide. La première version du module est disponible sur GitHub , testée sur CUBA version 6.10