Beaucoup se méfient de la perspective de bifurquer et d'écrire quelque chose par eux-mêmes. Souvent, le prix est trop élevé. Il est particulièrement étrange d'entendre parler de vos propres JDK, qui sont censés se trouver dans toutes les grandes entreprises. Que diable fait rage avec de la graisse? Cet article sera une histoire détaillée de l'entreprise, qui tout cela apporte de réels avantages commerciaux, et qui a fait un travail terrible, car ils:
- Développer une machine Java virtuelle multi-locataire;
- Ils ont mis au point un mécanisme pour le fonctionnement des objets qui n'entraînent pas de frais généraux pour la collecte des ordures;
- Ils ont fait quelque chose comme l'homologue ReadyNow d'Azul Zing;
- Ils ont arrosé leurs propres coroutines avec des rendements et des continuations (et sont même prêts à partager leur expérience avec Loom, dont j'ai écrit à l'automne );
- Ils ont vissé à tous ces miracles leur propre sous-système de diagnostic.
Comme toujours, la vidéo, le décryptage de texte intégral et les diapositives vous attendent sous la coupe. Bienvenue dans l'enfer de l'un des domaines les plus difficiles de l'adaptation des projets open source!

Docteur, où obtenez-vous de telles photos? O'Reilly Covers Corner: Le fond KDPV est fourni par Joshua Newton et représente la danse sacrée Sangyang Jaran à Ubud, Indonésie. Il s'agit d'une performance balinaise classique composée de danse feu et transe. Un homme à talons nus se déplace autour d'un feu de joie, élevé sur des coques de noix de coco, poussant des choses avec ses pieds et dansant dans un état de transe sous l'influence d'un esprit de cheval. Illustration parfaite pour votre propre JDK, non?
Diapositives et description du rapport (vous n'en avez pas besoin, ce habratopike a tout ce dont vous avez besoin).
Bonjour, je m'appelle Sanhong Lee, je travaille chez Alibaba et j'aimerais parler des changements que nous avons apportés à OpenJDK pour les besoins de notre entreprise. Le poste se compose de trois parties. Dans le premier, je parlerai de la façon dont Java est utilisé dans Alibaba. La deuxième partie, à mon avis, est la plus importante - nous y discuterons de la façon dont nous configurons OpenJDK pour les besoins de notre entreprise. La troisième partie portera sur les outils que nous avons créés pour le diagnostic.
Mais avant de passer à la première partie, je voudrais vous parler brièvement de notre entreprise.
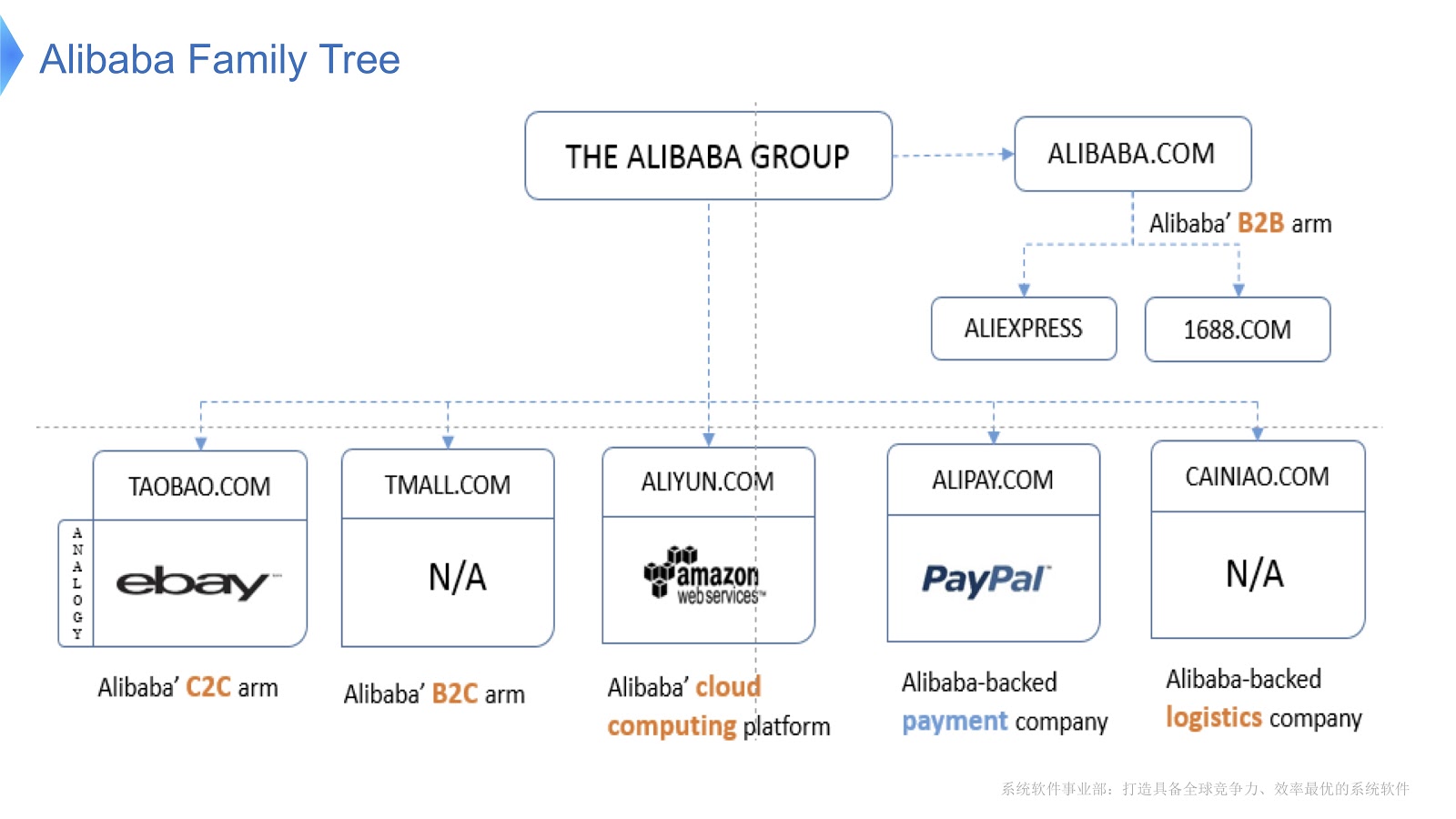
Le diagramme montre la structure interne d'Alibaba. Il est composé de différentes sociétés dont la principale spécialité est l'organisation du marché électronique et la mise à disposition de plateformes financières et logistiques. Je pense que la plupart des gens en Russie connaissent AliExpress. Alibaba dispose d'une équipe dédiée de programmeurs qui développent et prennent en charge l'intégralité de la pile distribuée, fournissant des services aux clients Aliexpress du monde entier.
Pour avoir une idée de l'ampleur du travail d'Alibaba, voyons ce qui se passe en Chine lors de la Journée des célibataires . Il est célébré chaque année le 11 novembre et ce jour-là, les gens achètent surtout de nombreux produits via Alibaba. Pour autant que je sache, parmi les vacances dans le monde, c'est celle qui fait le plus de shopping.
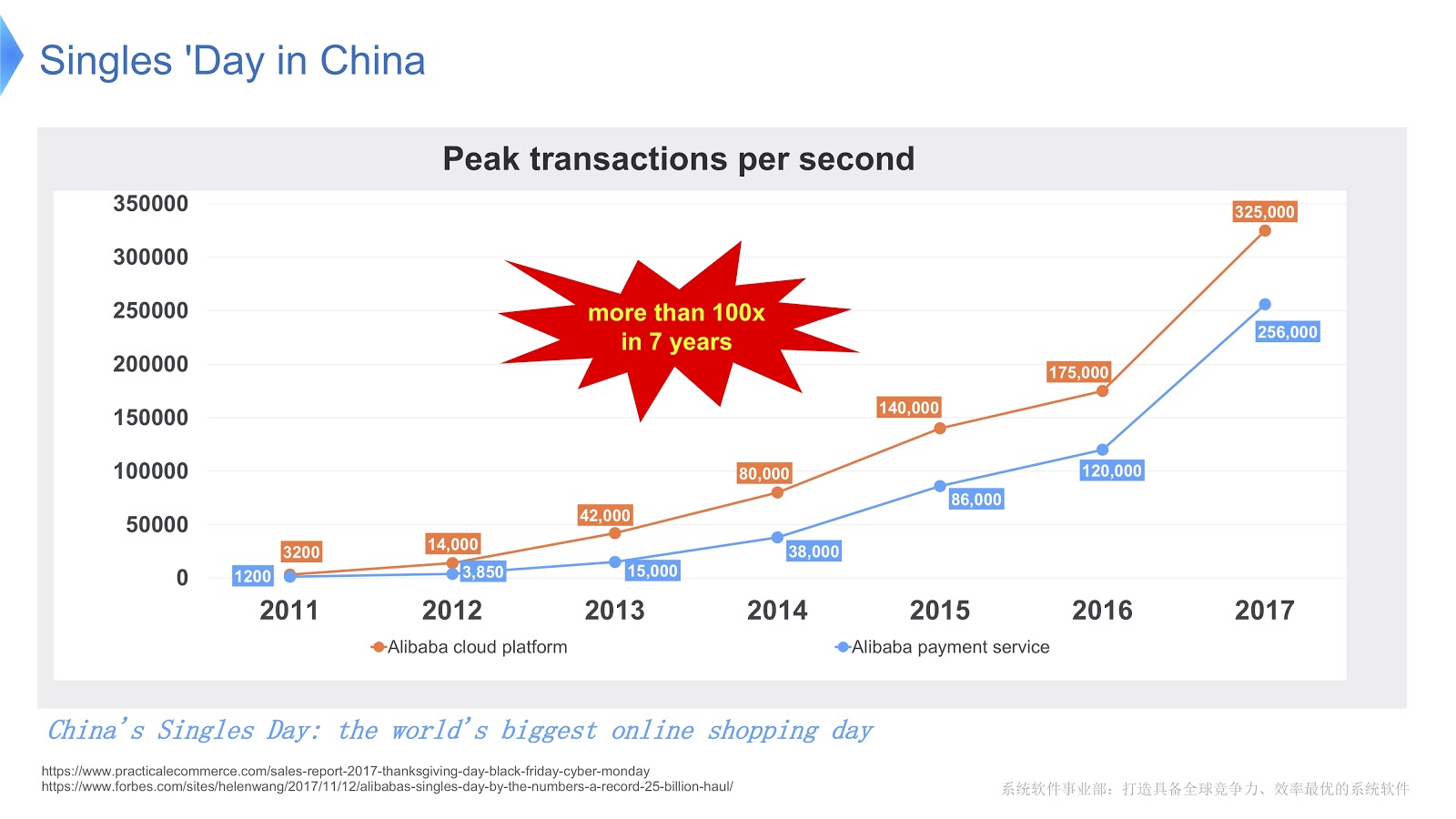
Dans l'image ci-dessus, vous voyez un diagramme qui montre la charge sur notre système de support. La ligne rouge montre le travail de notre service de commande et montre le nombre maximal de transactions par seconde, l'année dernière il s'élevait à 325 mille. La ligne bleue fait référence au service de paiement, et elle a ce chiffre de 256 mille. Je voudrais parler de la façon d'optimiser la pile desservant autant de transactions.
Discutons des principales technologies qui fonctionnent dans Alibaba avec Java. Tout d'abord, je dois dire que nous avons un certain nombre d'applications open source comme base. Pour le traitement des mégadonnées, nous utilisons HBase Hadoop. En tant que conteneur, nous utilisons Tomcat et OSGi. Java est utilisé à une échelle colossale - des millions d'instances JVM sont déployées dans notre centre de données. Il faut également dire que notre architecture est orientée services, c'est-à-dire que nous créons de nombreux services qui communiquent entre eux à l'aide d'appels RPC. Enfin, notre architecture est hétérogène. Pour améliorer les performances, de nombreux algorithmes sont écrits à l'aide de bibliothèques C et C ++, de sorte qu'ils communiquent avec Java à l'aide d'appels JNI.

L'histoire de notre travail avec OpenJDK a commencé en 2011, pendant OpenJDK 6. Il y a trois raisons importantes pour lesquelles nous avons choisi OpenJDK. Tout d'abord, nous pouvons directement changer son code en fonction des besoins de l'entreprise. Deuxièmement, lorsque des problèmes urgents surviennent, nous pouvons les résoudre nous-mêmes plus rapidement que d'attendre la publication officielle. C'est vital pour notre entreprise. Troisièmement, nos développeurs Java utilisent nos propres outils pour un débogage et des diagnostics rapides et de haute qualité.
Avant de passer aux questions techniques, je voudrais énumérer les principales difficultés que nous devons surmonter. Premièrement, nous avons lancé un grand nombre d'instances JVM - dans cette situation, la question de la réduction des coûts du matériel est un problème aigu. Deuxièmement, j'ai déjà dit que nous effectuons un grand nombre de transactions. Grâce au garbage collector, Java nous promet une «mémoire infinie». De plus, il gagne en performances à bas niveau grâce au compilateur JIT. Mais cela a aussi un revers: un temps d'arrêt du monde plus long pour la collecte des ordures. De plus, Java a besoin de cycles CPU supplémentaires pour compiler les méthodes Java. Cela signifie que les compilateurs se disputent les cycles CPU. Les deux problèmes s'aggravent à mesure que l'application devient plus complexe.
La troisième difficulté est que nous avons beaucoup d'applications en cours d'exécution. Je pense que tout le monde ici est familier avec les outils fournis avec OpenJDK, tels que JConsole ou VisualVM. Le problème est qu'ils ne nous donnent pas les informations exactes dont nous avons besoin pour configurer. De plus, lorsque nous utilisons ces outils (par exemple, JConsole ou VisualVM) en production, une surcharge faible n'est pas seulement un souhait, mais une exigence nécessaire. J'ai dû écrire mes propres outils de diagnostic.

L'image décrit les modifications que nous avons apportées à OpenJDK. Voyons comment nous avons surmonté les difficultés dont j'ai parlé plus haut.
JVM multi-locataire
Une solution que nous appelons une machine virtuelle Java multi-locataire. Il vous permet d'exécuter en toute sécurité plusieurs applications Web dans un seul conteneur. Une autre solution est appelée GCIH (GC Invisible Heap). Il s'agit d'un mécanisme qui vous fournit des objets Java à part entière, qui en même temps ne nécessitent pas le coût de la récupération de place. De plus, afin de réduire les coûts des contextes de threads, nous avons implémenté des coroutines sur notre plateforme Java. De plus, nous avons écrit un mécanisme appelé JWarmup - sa fonction est très similaire à ReadyNow. Douglas Hawkins semble l'avoir mentionné dans son rapport . Enfin, nous avons développé notre propre outil de profilage, ZProfiler.
Examinons de plus près comment nous implémentons la multi-location basée sur OpenJDK.
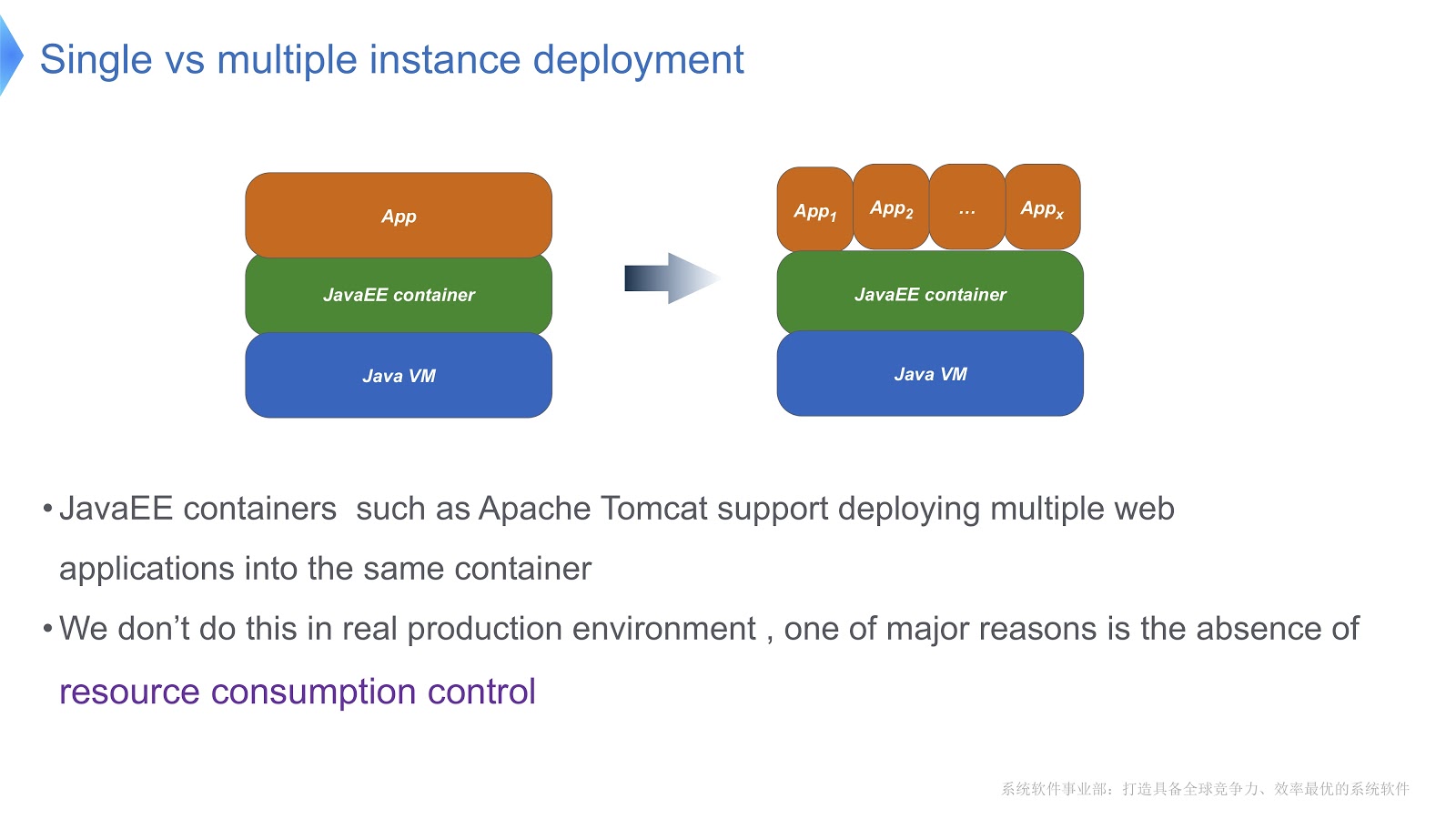
Jetez un oeil à l'image ci-dessus - je pense que la plupart d'entre vous connaissent ce modèle. Comparez l'approche traditionnelle avec le multi-locataire. Si votre application s'exécute à l'aide d'Apache Tomcat, vous pouvez également exécuter plusieurs instances dans le même conteneur. Mais Tomcat ne fournit pas de consommation de ressources stable pour chacun d'eux. Par exemple, si l'une des applications en cours d'exécution a besoin de plus de temps CPU que l'autre, comment contrôlerez-vous l'allocation du temps CPU? Comment s'assurer que cette application n'affecte pas le travail des autres? C'est principalement cette question qui nous a fait nous tourner vers la technologie multi-locataire.
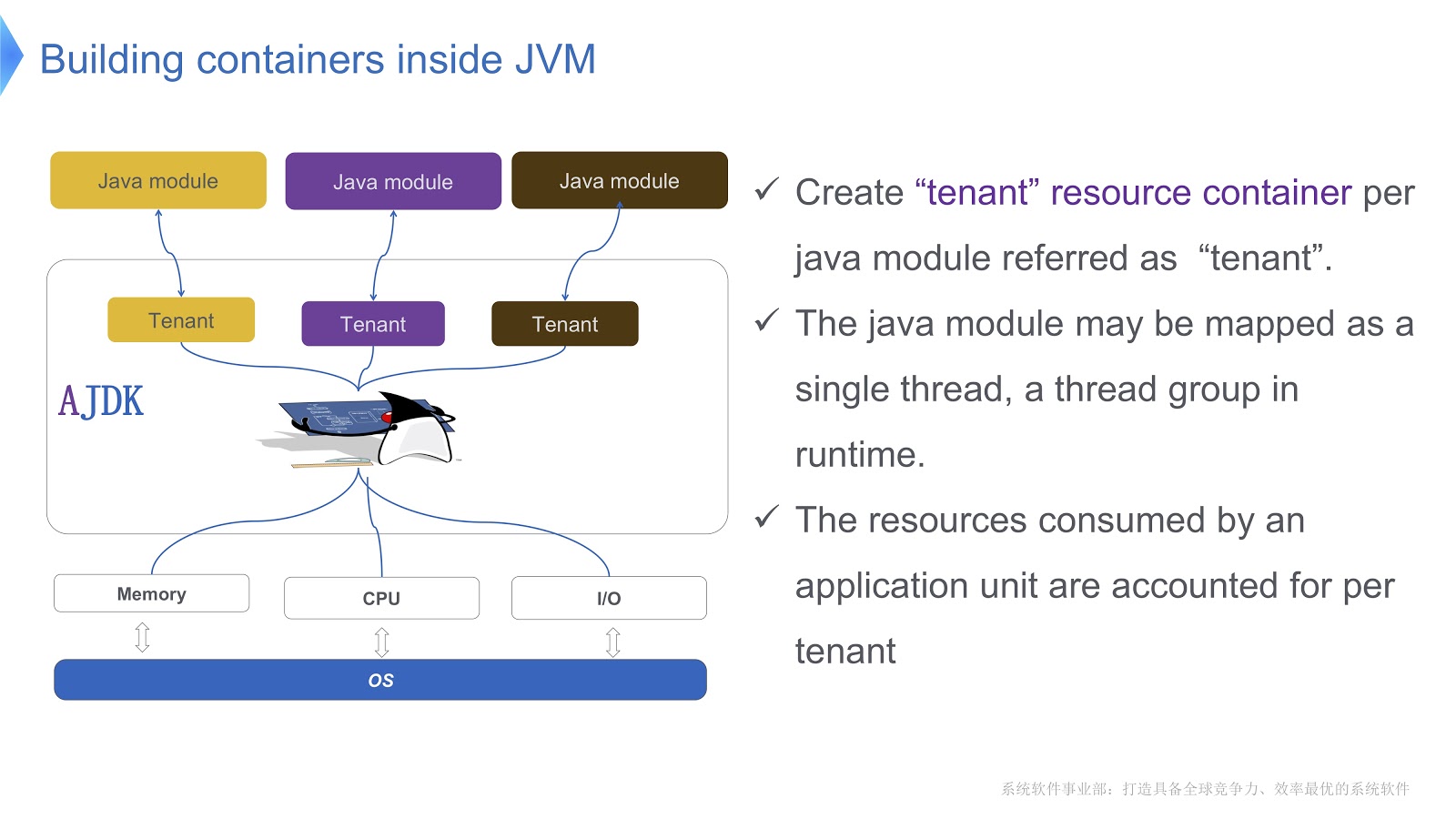
L'image montre schématiquement comment nous l'implémentons. Nous créons plusieurs conteneurs pour les locataires à l'intérieur de la JVM. Chacun de ces conteneurs fournit un contrôle fiable de la consommation des ressources pour chaque module Java. Plusieurs modules peuvent être déployés dans un seul conteneur. Chaque module peut être associé à un thread ou à un groupe de threads lors de l'exécution.
Voyons à quoi ressemble l'API du conteneur de locataires. Nous avons une classe de configuration de locataire qui stocke des informations sur la consommation des ressources. Ensuite, il y a une classe du conteneur lui-même.
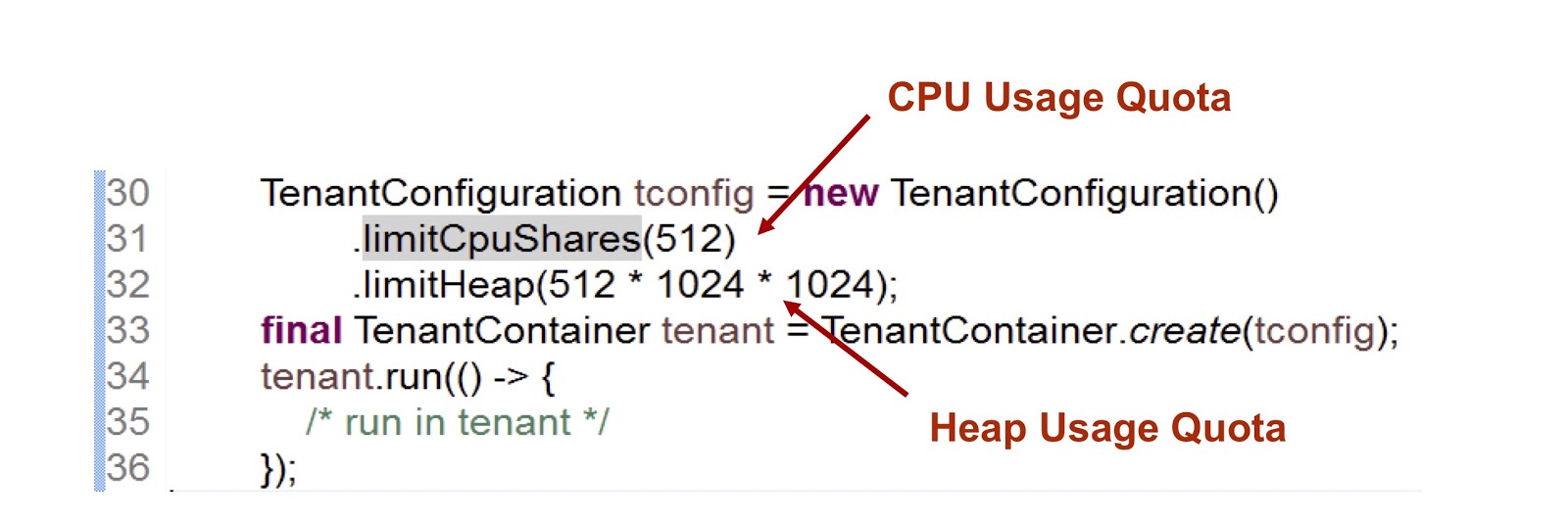
Dans l'extrait de code présenté, nous créons un locataire, puis indiquons combien de temps le processeur et la mémoire lui sont fournis. Le premier indicateur est un entier, ce qui signifie la part du temps CPU disponible pour le locataire, dans ce cas nous avons indiqué 512. Nous utilisons une approche très similaire dans le cas des cgroups, je m'attarderai là-dessus plus en détail. La deuxième mesure est la taille de segment de mémoire maximale que les locataires peuvent utiliser.
Considérez comment un locataire interagit avec un thread. La classe .run() fournit la méthode .run() et lorsqu'un thread y entre, il s'attache automatiquement au locataire et lorsqu'il le quitte, la procédure inverse se produit. Ainsi, tout le code est exécuté à l'intérieur de la méthode .run() . En outre, tout thread créé à l'intérieur de la méthode .run() est attaché au locataire du thread parent.
Nous sommes arrivés à une question très importante - comment le processeur est-il géré dans une machine virtuelle Java à locataires multiples? Notre solution vient d'être implémentée sur la plateforme Linux x64. Il existe un mécanisme de groupe de contrôle, cgroups. Il vous permet de sélectionner un processus dans un groupe distinct, puis d'indiquer votre mode de consommation de ressources pour chaque groupe. Essayons de transférer cette approche dans le contexte de la JVM Hotspot. Sur Hotstpot, les threads Java sont organisés en threads natifs.

Ceci est illustré dans le diagramme ci-dessus: chaque thread Java est en correspondance biunivoque avec le thread natif. Dans notre exemple, nous avons un conteneur TenantA , dans lequel il y a deux threads natifs. Afin de pouvoir contrôler la distribution du temps CPU, nous plaçons les deux threads natifs dans un groupe de contrôle. Pour cette raison, nous pouvons réguler la consommation des ressources, en nous appuyant uniquement sur la fonctionnalité des [groupes de contrôle] ( https://en.wikipedia.org/wiki/Cgroups ).
Jetons un coup d'œil à un exemple plus détaillé.
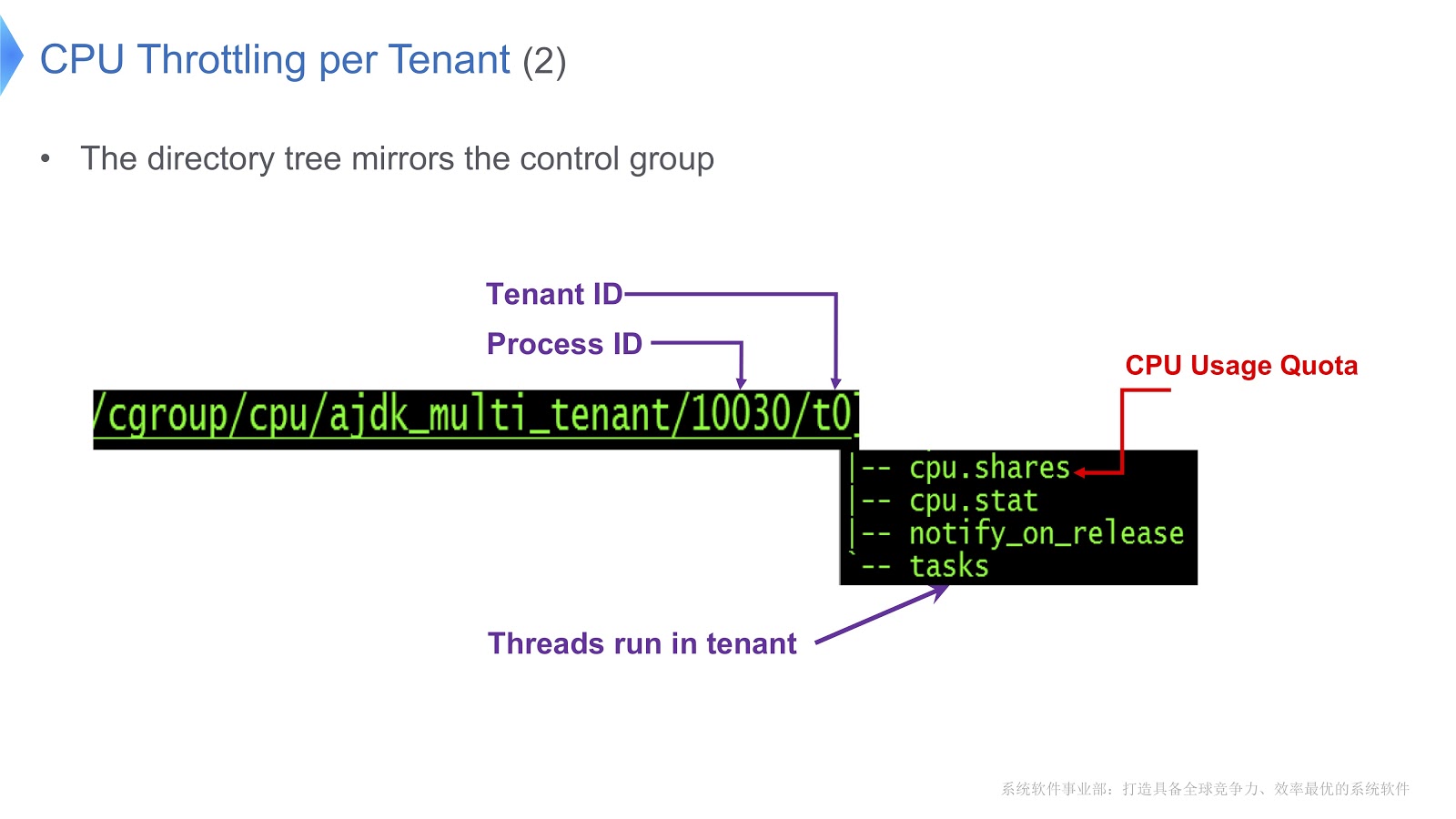
Les groupes de contrôle sous Linux sont mappés sur un répertoire. Dans notre exemple, nous avons créé le répertoire /t0 pour le locataire 0. Ce répertoire contient le répertoire /t0/tasks , tous les threads pour t0 seront situés ici. Un autre fichier important est /t0/cpu.shares . Il indique combien de temps le processeur sera accordé à ce locataire. Toute cette structure est héritée des groupes de contrôle - nous avons simplement assuré une correspondance directe entre le thread Java, le thread natif et le groupe de contrôle.
Un autre problème important concerne la gestion d'un groupe de chaque locataire.
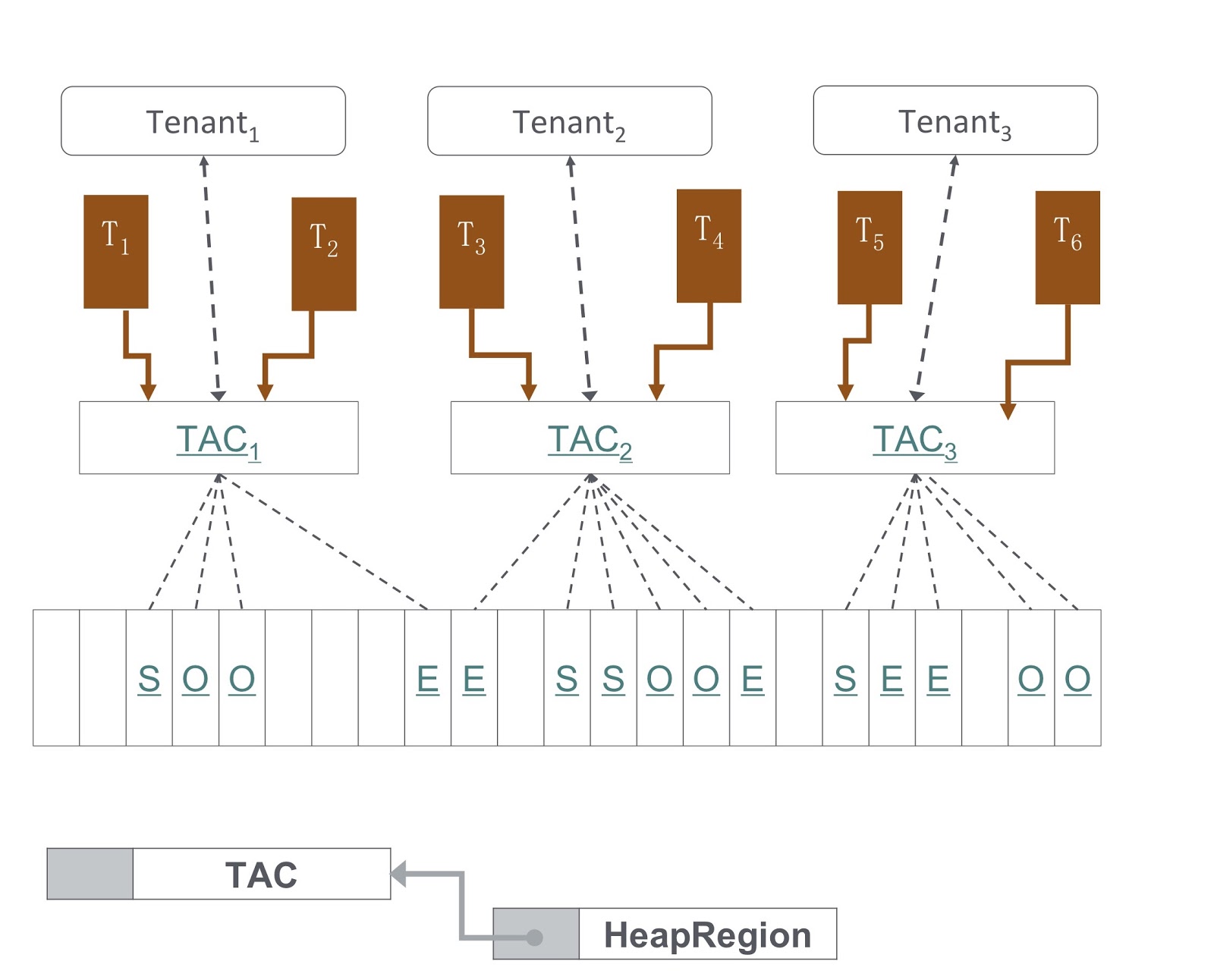
Dans l'image, vous voyez un diagramme de la façon dont il est mis en œuvre. Notre approche est basée sur le G1GC. Au bas de l'image, G1GC divise le tas en sections de même taille. Sur cette base, nous créons des contextes d'allocation de locataire, TAC, avec lesquels le locataire gère sa section de segment de mémoire. Grâce à TAC, nous limitons la taille de la portion de tas disponible pour le locataire. Ici, le principe s'applique, selon lequel chaque section du tas contient des objets d'un seul locataire. Pour l'implémenter, nous devions apporter des modifications au processus de copie d'un objet pendant le garbage collection - il était nécessaire de s'assurer que l'objet était copié dans la bonne section du tas.
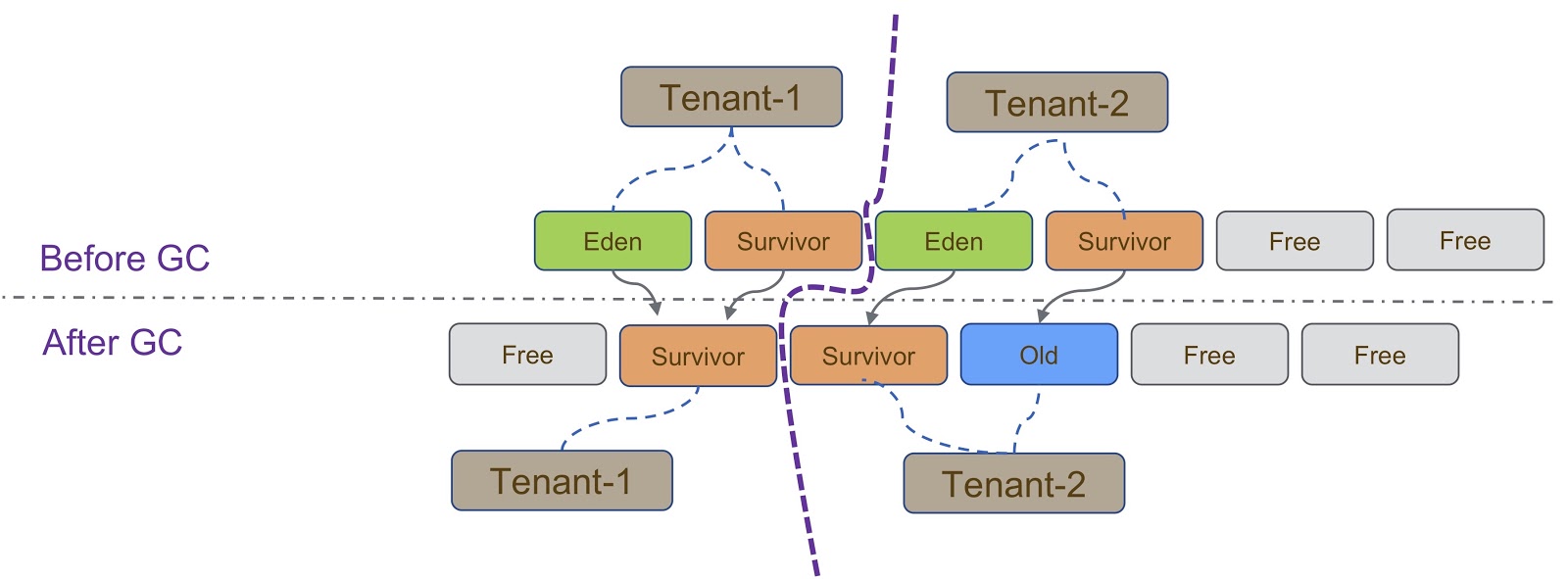
Schématiquement, ce processus est décrit dans le diagramme ci-dessus. Comme je l'ai dit, notre implémentation est basée sur G1GC. G1GC est un garbage collector de copie, donc pendant le garbage collection, nous devons nous assurer que l'objet est copié dans la bonne section du tas. Sur la diapositive, tous les objets créés par Tenant-1 doivent être copiés dans sa partie du segment de mémoire, similaire à Tenant-2 .
D'autres considérations surviennent lorsque les locataires sont isolés les uns des autres. Ici, je dois dire sur TLAB (Thread Local Allocation Buffer) - un mécanisme pour l'allocation rapide de la mémoire. L'espace TLAB dépend de la section de tas. Comme je l'ai dit, différents locataires ont différents groupes de sections de tas.

Les détails de l'utilisation de TLAB sont présentés sur la diapositive - lorsque le thread passe de Tenant 1 à Tenant 2 , nous devons nous assurer que la bonne section de segment de mémoire est utilisée pour l'espace TLAB. Cela peut être réalisé de deux manières. La première façon est lorsque le Thread A passe du Tenant 1 au Tenant 2 , nous nous débarrassons simplement de l'ancien et en créons un nouveau dans le Tenant 2 . Cette méthode est relativement facile à implémenter, mais elle gaspille de l'espace dans TLAB, ce qui n'est pas souhaitable. La deuxième façon est plus compliquée - pour informer TLAB des locataires. Cela signifie que nous aurons plusieurs tampons TLAB pour un thread. Lorsque le Thread A passe du Tenant 1 au Tenant 2 , nous devons modifier le tampon et utiliser celui qui a été créé dans le Tenant 2 .
Un autre mécanisme qui doit être dit dans le cadre de la délimitation des locataires est l'IHOP (Initiator Thread Occupancy Percent). Initialement, l'IHOP a été calculé sur la base du tas entier, mais dans le cas d'un mécanisme à plusieurs locataires, il doit être calculé sur la base d'une seule section du tas.
Examinons de plus près ce qu'est GCIH (GC Invisible Heap). Ce mécanisme crée une section sur le tas, cachée du garbage collector et, par conséquent, non affectée par le garbage collection. Ce site est géré par le locataire GCIH.

Il est important de dire ici que nous fournissons une API publique à nos développeurs Java. Un exemple de travail avec celui-ci peut être vu à l'écran. Il permet d'utiliser la méthode moveIn() pour déplacer des objets d'un tas normal vers une partie du tas GCIH. Son avantage est que vous pouvez toujours interagir avec ces objets comme avec les objets Java classiques, leur structure est très similaire. Mais en même temps, ils ne nécessitent pas le coût de la collecte des ordures. La conclusion, à mon avis, est que si vous souhaitez accélérer la collecte des ordures, vous devez personnaliser le comportement du garbage collector en fonction des besoins de votre application.
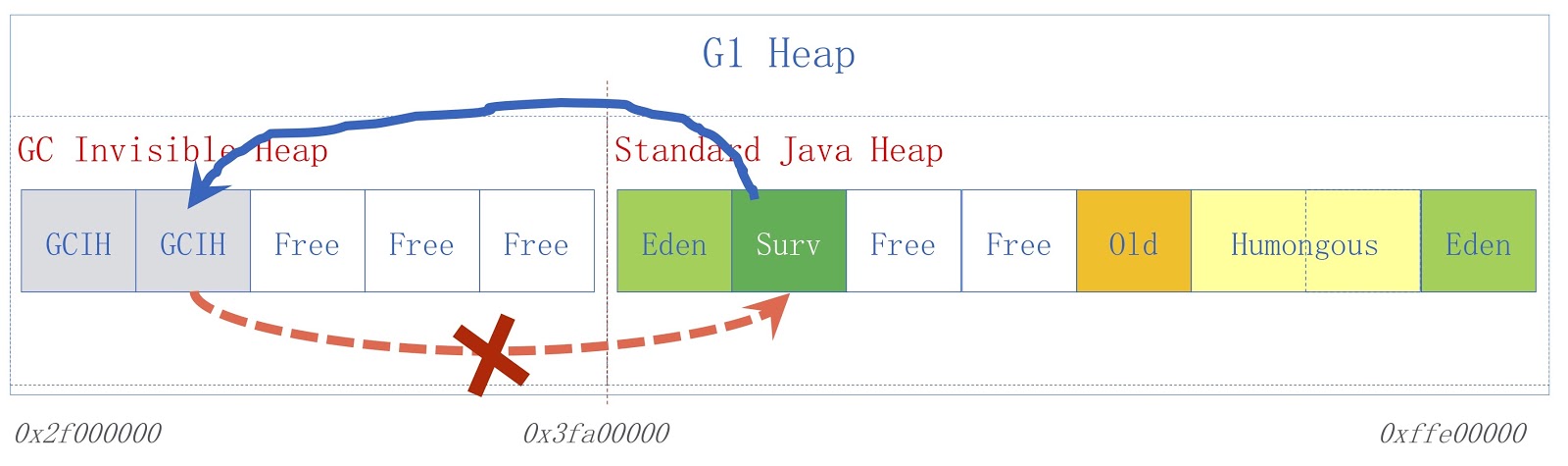
L'image montre un schéma GCIH de haut niveau. À droite, un tas Java standard, à gauche, l'espace alloué à GCIH. Les liens d'un tas régulier vers des objets dans GCIH sont valides, mais les liens de GCIH vers un tas normal ne le sont pas. Pour comprendre pourquoi il en est ainsi, considérons un exemple. Nous avons l'objet «A» dans GCIH, qui contient une référence à l'objet «B» dans un tas régulier. Le problème est que l'objet B peut être déplacé par le garbage collector. Comme je l'ai déjà dit, nous ne faisons pas de mises à jour dans GCIH, donc après que le garbage collector fonctionne, l'objet "A" peut contenir une référence invalide à l'objet "B". Ce problème peut être résolu en utilisant la barrière de pré-écriture - ils ont été discutés dans un rapport précédent. Par exemple, supposons que quelqu'un ait besoin d'enregistrer un lien à partir d'un tas Java ordinaire vers GCIH avant que l'enregistrement que nous supposions n'entraîne une exception de prédicteur avec un indicateur indiquant que la règle a été violée.
Pour une application spécifique, une machine virtuelle Java à locataires multiples est utilisée dans notre plateforme de personnalisation Taobao, en abrégé TPP. Il s'agit d'un système de recommandation pour notre application e-shopping. TPP peut déployer plusieurs microservices dans un seul conteneur, et avec l'aide de la JVM multi-locataire, nous contrôlons la mémoire et le temps CPU fournis à chaque microservice.
Quant à GCIH, il est utilisé dans notre autre système, UM Platform. Il s'agit d'une application de réduction en ligne. Le propriétaire de cette application utilise GCIH pour pré-mettre en cache les données GCIH sur la machine locale, afin de ne pas accéder aux objets sur le serveur de cache distant ou la base de données distante. En conséquence, nous allégons la charge sur le réseau et effectuons moins de sérialisation et de désérialisation.
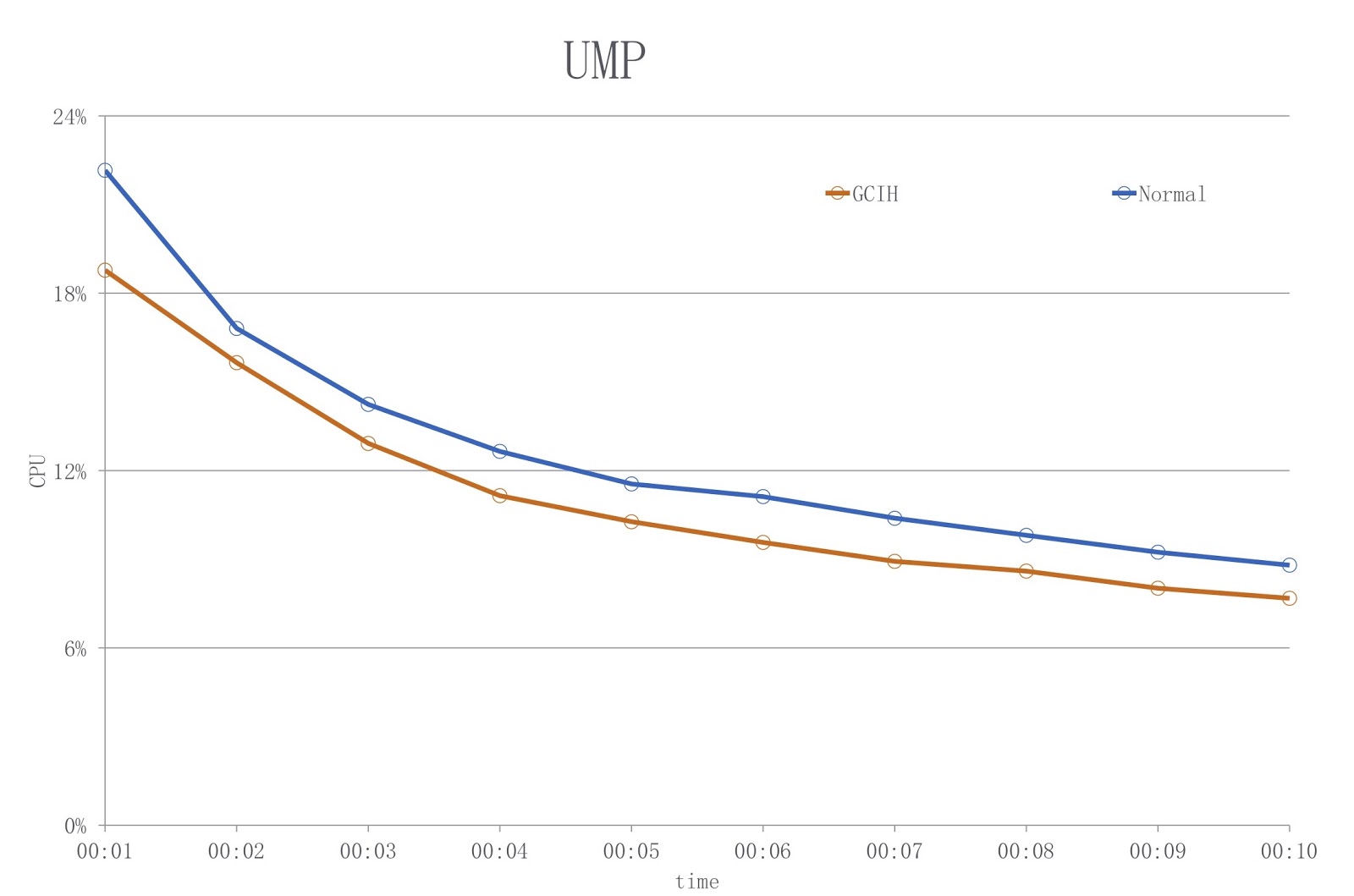
L'image montre un diagramme dans lequel la couleur bleue montre la charge lors de l'utilisation d'un JDK conventionnel et le rouge - GCIH. Comme vous pouvez le voir, nous réduisons l'utilisation du processeur de plus de 18%.
Pour autant que je sache, un problème similaire a été résolu par BellSoft , et leur solution était similaire à GCIH, mais ils ont utilisé une approche différente pour réduire les coûts de sérialisation et de désérialisation.
Coroutines en Java
Revenons à Alibaba et voyons comment les coroutines peuvent être implémentées en Java. Mais d'abord, parlons des origines, de la raison pour laquelle nous devons faire cela. En Java, il était toujours très facile d'écrire des applications multithreads. Mais le problème avec la création de telles applications est que, comme je l'ai dit, dans Hotspot, les threads Java sont déjà implémentés en tant que threads natifs. Par conséquent, lorsqu'il y a beaucoup de threads dans votre application, les coûts de modification du contexte du thread deviennent très élevés.

Prenons un exemple dans lequel nous aurons 4 threads d'E / S et 200 threads avec la logique de votre application. Le tableau à l'écran montre les résultats du démarrage de cette démonstration simple - vous pouvez voir combien de temps le processeur prend pour changer de contexte. La solution à ce problème peut être l'implémentation de la corutine en Java.
Pour le fournir, nous avions besoin de deux choses. Tout d'abord, Alibaba JDK devait ajouter un support de continuation. Ce travail était basé sur le patch JKU, nous y reviendrons plus en détail. Deuxièmement, nous avons ajouté un sheduler en mode utilisateur qui sera responsable de la suite dans le thread. Troisièmement, il y a beaucoup d'applications à Alibaba. Par conséquent, notre solution est très importante pour nos développeurs Java, et il était nécessaire de la rendre absolument transparente pour eux. Et cela signifie que dans notre application métier, il ne devrait y avoir pratiquement aucun changement dans le code. Nous avons appelé notre solution Wisp. Notre implémentation de coroutines en Java est largement utilisée dans Alibaba, il peut donc être considéré comme prouvé qu'elle fonctionne en Java. Apprenez à le connaître plus en détail.

Commençons par l'exemple, dont le code est présenté ci-dessus - il s'agit d'une application Java tout à fait ordinaire. Tout d'abord, un pool de threads est créé. Ensuite, une autre tâche exécutable est créée qui accepte le socket. Après cela, la lecture du flux est effectuée. Ensuite, nous créons une autre tâche exécutable, avec laquelle nous nous connectons au serveur et, enfin, écrivons des données dans le flux. Comme vous pouvez le voir, tout semble assez standard. Si vous exécutez le code sur un JDK standard, chacune de ces tâches exécutables sera exécutée dans un thread distinct. Mais dans notre décision, la mécanique sera complètement différente.
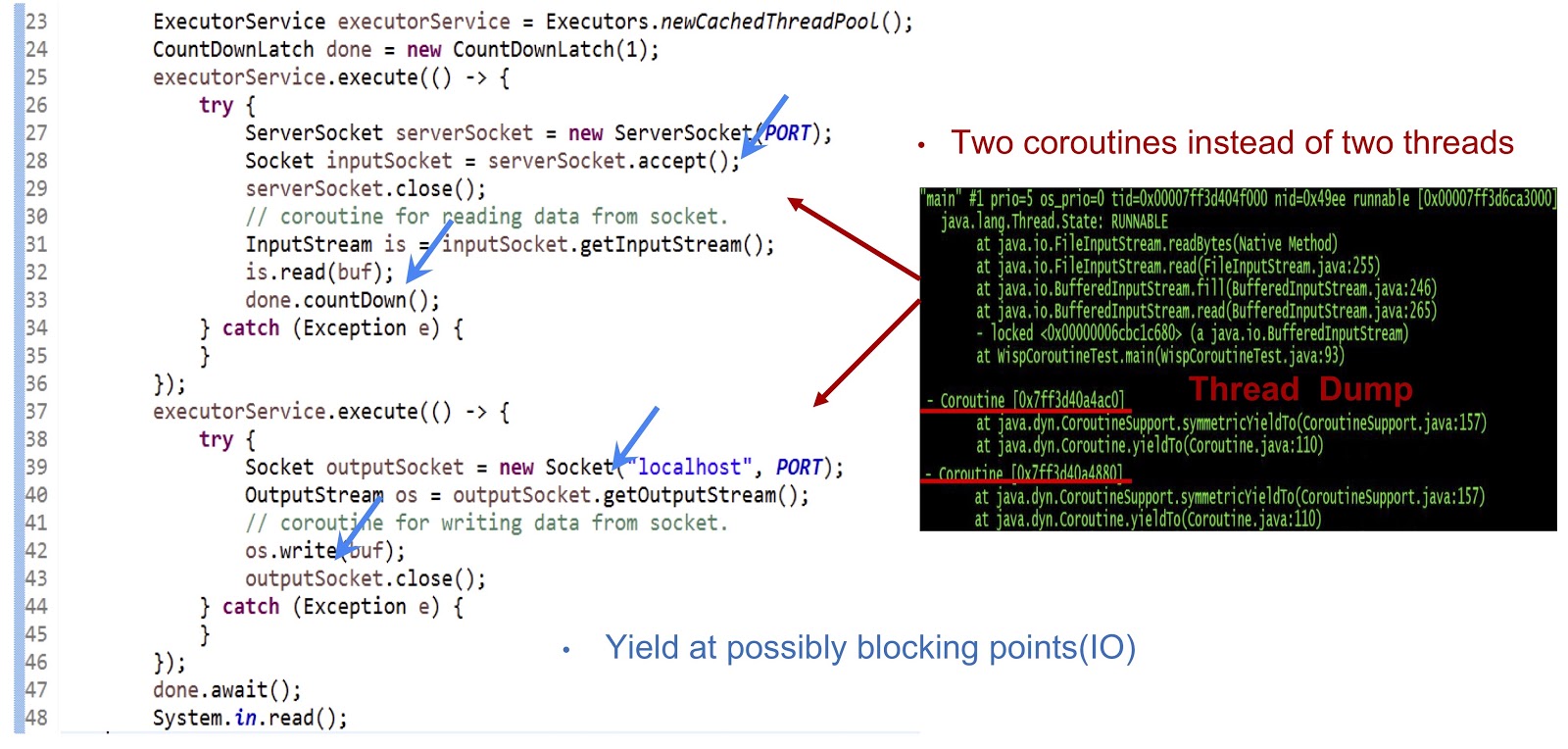
Comme vous pouvez le voir sur le vidage du fil montré sur la diapositive, nous créons deux coroutines dans un fil, et non deux fils. Vous devez maintenant faire fonctionner cette solution. L'essentiel ici est de générer des événements yieldTo à tous les points de blocage possibles. Dans notre exemple, ces points seront serverSocket.accept() , is.read(buf) , une connexion socket et os.write(buf) . Grâce aux événements de rendement à ces points, nous pourrons transférer le contrôle d'une coroutine à une autre dans le même thread. Pour résumer, notre approche est que nous obtenons des performances asynchrones en utilisant coroutine, mais nos programmeurs peuvent écrire du code dans un style synchrone, car un tel code est beaucoup plus simple et plus facile à maintenir et à déboguer.
Voyons exactement comment nous avons fourni un support de continuation dans Alibaba JDK. Comme je l'ai dit, ce travail est basé sur un projet de machine virtuelle multilingue créé par la communauté - il est dans le domaine public. Nous avons utilisé ce correctif dans Alibaba JDK et corrigé certains bogues qui se produisaient dans notre environnement de production.
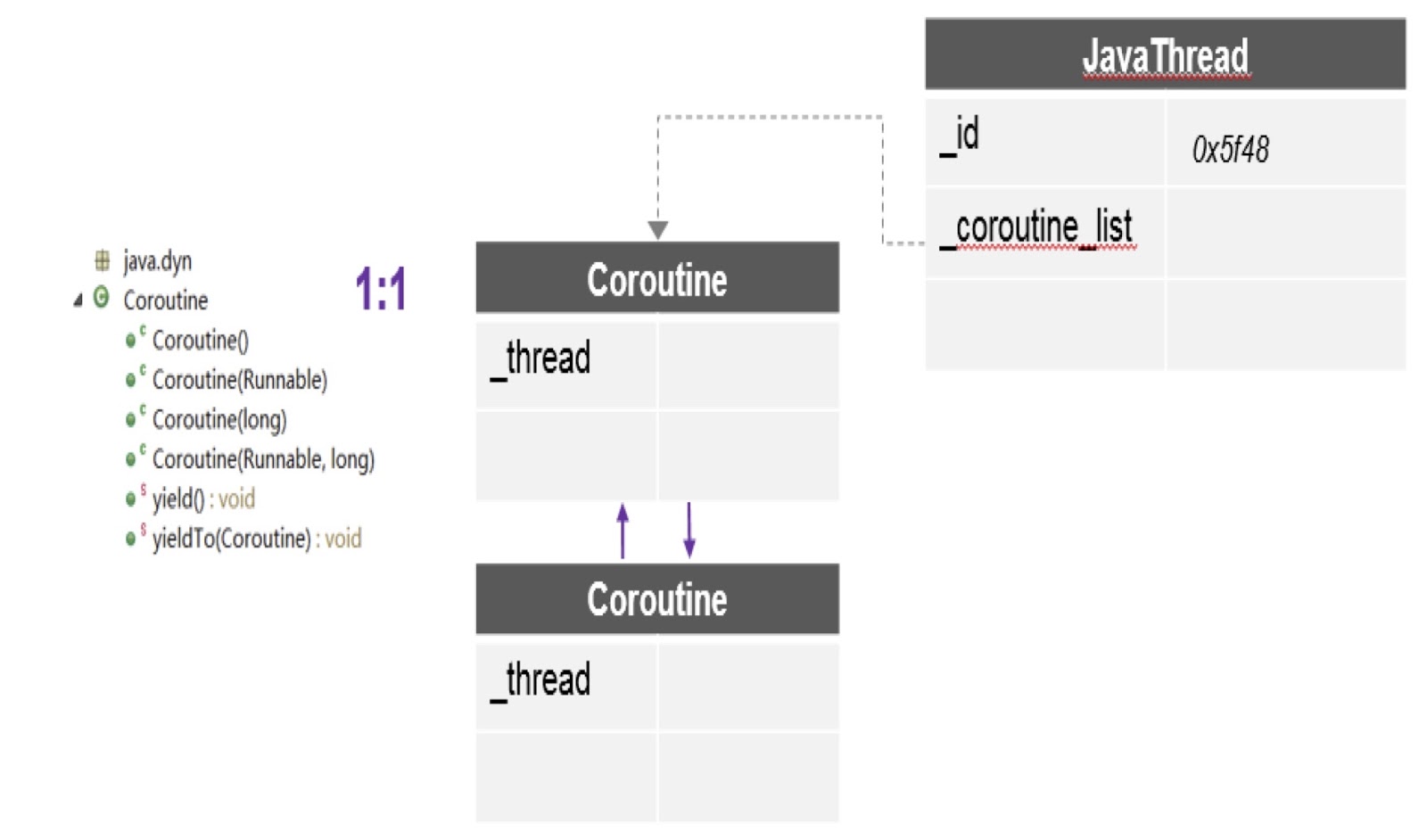
Comme vous pouvez le voir dans le diagramme, ici, dans un thread, il peut y avoir plusieurs coroutines, et pour chacune une pile distincte est créée. De plus, le patch dont j'ai parlé nous fournit ici l'API la plus importante - yieldTo, à l'aide de laquelle le contrôle est transféré d'une coroutine à une autre.
Passons à la façon dont nous avons implémenté le sheduler en mode utilisateur pour coroutine. Nous utilisons un sélecteur, et avec lui, nous enregistrons plusieurs canaux. Lorsqu'un événement d'E / S (lecture de socket, écriture de socket, connexion de socket ou acceptation de socket) se produit, il est écrit comme clé pour le sélecteur. Par conséquent, à la fin de cet événement, nous recevons une alerte du sélecteur. Ainsi, nous utilisons un sélecteur pour planifier les coroutines en cas de verrouillage d'E / S. Prenons un exemple de la façon dont cela fonctionnera.
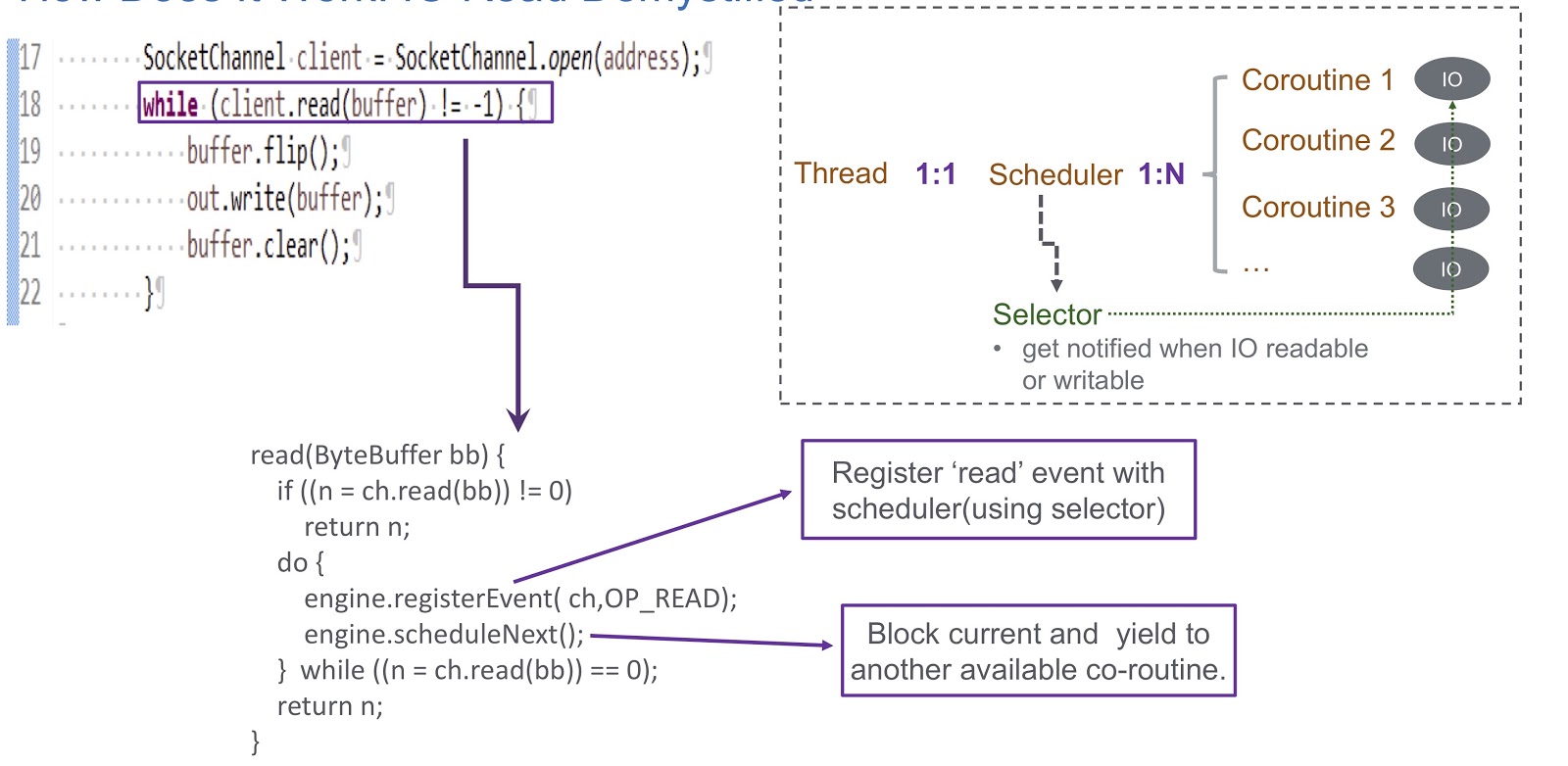
Dans l'image, nous voyons le socket et l'appel synchrone client.read(buffer) . Au bas de la diapositive, un code est écrit qui sera exécuté à l'intérieur de cet appel. Tout d'abord, il vérifie s'il est possible de lire à partir du canal ou non. Si c'est le cas, nous renvoyons le résultat. La chose la plus intéressante se produit si la lecture ne peut pas être effectuée. Ensuite, nous enregistrons l'événement de lecture dans notre planificateur avec sélecteur. Cela permet de planifier l'exécution de toute autre coroutine. Regardez comment cela se produit. Nous avons un fil dans lequel un ordonnanceur est créé. Le fil et notre coroutine sont en correspondance biunivoque. Sheduler nous permet de gérer les coroutines de ce fil. Que se passe-t-il si les E / S sont bloquées? Lorsque des événements d'E / S se produisent, le sheduler reçoit une alerte et, dans cette situation, il dépend entièrement du sélecteur. Après un tel événement, le sheduler a la possibilité de planifier la prochaine coroutine disponible.
Résumons l'aperçu de notre sheduler, que nous avons appelé WispEngine. Pour chacun de nos threads, nous allouons un WispEngine distinct. Lorsqu'un verrouillage coroutine se produit, nous enregistrons certains événements (lecture / écriture de socket, etc.) à l'aide de WispEngine. Certains événements sont liés au stationnement des threads, par exemple, si vous appelez thread.sleep() avec un délai de 100 millisecondes. Dans ce cas, un événement de stationnement de thread sera généré pour vous, qui sera ensuite enregistré dans le sélecteur. Un autre problème important est le moment où le sheduler nomme la prochaine coroutine disponible. Il y a deux conditions principales. Le premier est lorsque certains événements sont générés, tels que des événements d'E / S ou des événements d'expiration. Tout est assez simple ici: supposons que vous thread.sleep() avec un retard de 200 millisecondes. A leur expiration, le sheduler a la possibilité d'exécuter la prochaine coroutine disponible. Ou ici, nous pouvons parler de certains événements de décompression qui sont générés, par exemple, en appelant object.notify() ou object.notifyAll() La deuxième condition est lorsque l'utilisateur soumet de nouvelles demandes, et nous créons une coroutine pour répondre à ces demandes, puis le sheduler attribue sa mise en œuvre.
Ici, vous devez également parler du service que nous avons créé, WispThreadExecutor.

Un exemple de code est présenté à l'écran, et nous voyons qu'il s'agit d'un ExecutorService normal, créé de la même manière. Les .execute() et submit() sont disponibles pour les tâches Runnable, mais le problème est que toutes les tâches Runnable qui passent par la méthode submit() seront exécutées dans corutin, et non dans le thread. Cette solution est totalement transparente pour ceux qui vont implémenter notre application, ils pourront utiliser notre API pour les coroutines.

J'en viens à la dernière partie difficile de l'article - comment résoudre le problème de la synchronisation dans les coroutines. C'est une question complexe, alors regardons-la avec un exemple simplifié. Nous avons ici la coroutine A ( test::foo ) et la corutine test::bar ). Tout d'abord, nous attribuons l'exécution du test:foo à la coroutine wait() . Si rien n'est fait, le thread actuel sera bloqué par l'appel à wait() . Comme on peut le voir à partir de ce vidage du thread, un blocage se produira et nous ne pourrons pas planifier la prochaine coroutine à exécuter.
Comment résoudre ce problème? Hotspot propose trois types de verrous. Le premier est le verrouillage rapide. Ici, le propriétaire du verrou est déterminé par l'adresse sur la pile. Comme je l'ai dit, chacune de nos coroutines a une pile distincte. Par conséquent, dans le cas d'un verrouillage rapide, nous n'avons pas besoin d'effectuer de travail supplémentaire. Il n'y a pas de support similaire pour le verrouillage biaisé dans notre système. Nous l'avons essayé sur notre production et il s'est avéré qu'en l'absence d'un verrou biaisé, les performances ne diminuent pas. Pour nous, c'est tout à fait approprié.
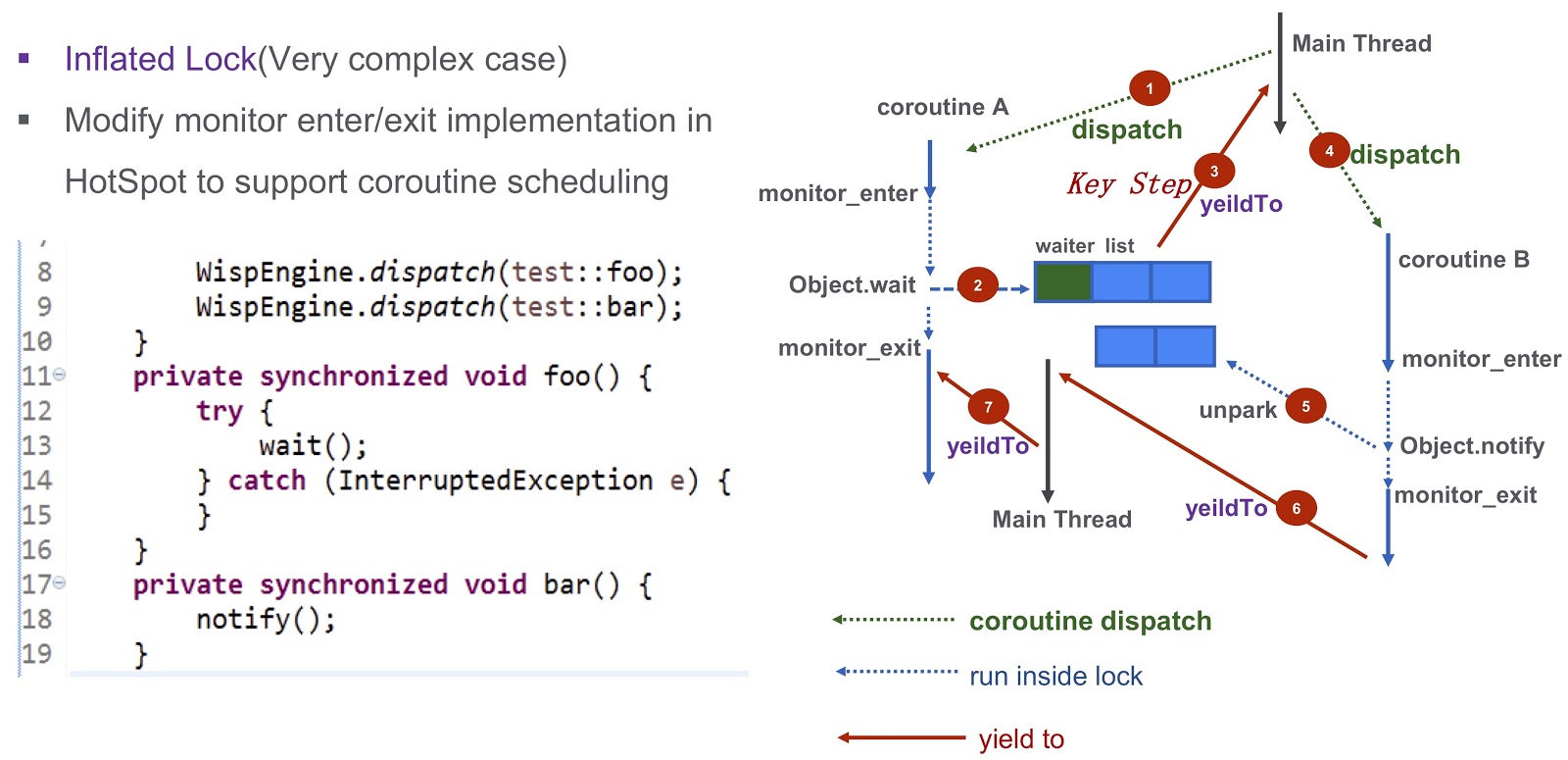
Parlons d'un cas plus compliqué - verrou gonflé. Reprenons l'exemple que j'ai cité plus haut. Nous avons Corutin .foo() ) et Corutin B ( .bar() ). Tout d'abord, nous attribuons l'exécution de la coroutine Object.wait , après quoi il entre dans la liste d'attente. Après cela, nous prenons une étape très importante: nous générons l'événement yieldTo , qui transfère le contrôle au thread principal. Ensuite, nous commençons Corutin B Il appelle Object.notify et les événements d' Object.notify correspondants sont unpark . Ils réveilleront éventuellement la coroutine bar() , il sera possible de transférer le contrôle à la coroutine
Parlons maintenant des performances. Nous utilisons des coroutines dans l'une de nos applications en ligne Carts. Sur cette base, nous pouvons comparer le travail de la corutine avec le travail d'un JDK régulier.
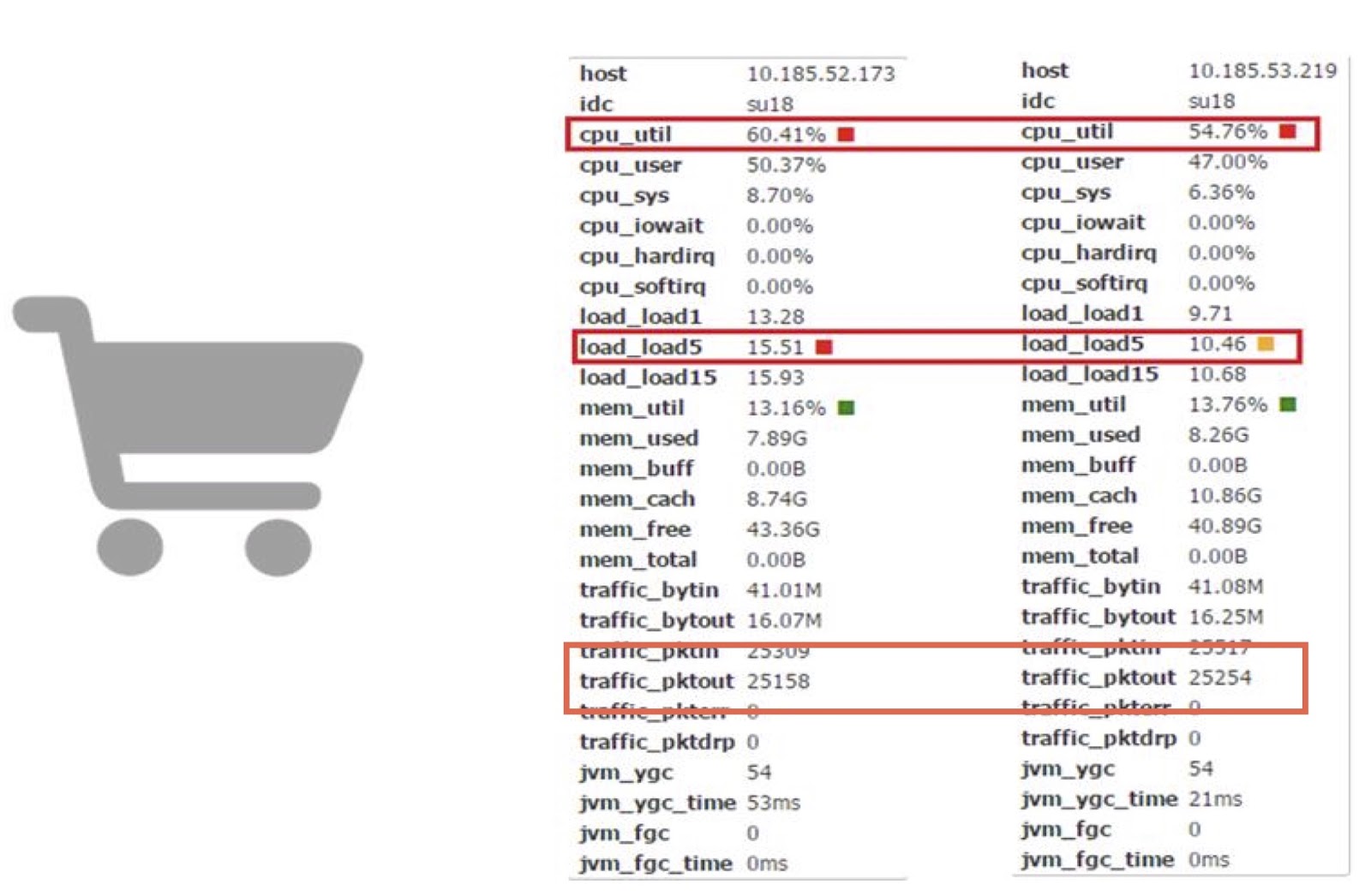
Comme vous pouvez le voir, ils nous permettent de réduire la consommation de temps processeur de près de 10%. Je comprends que la plupart d'entre vous n'ont probablement pas la possibilité d'apporter directement des modifications aussi complexes au code JDK. Mais la principale conclusion ici, à mon avis, est que si les pertes de performances coûtent de l'argent et que le montant résultant est suffisamment important, vous pouvez essayer d'améliorer les performances en utilisant la bibliothèque coroutine.
Jarmarm
Passons à notre autre outil - JWarmup. Il est très similaire à un autre outil, ReadyNow. Comme nous le savons, en Java il y a un problème d'échauffement - le compilateur à ce stade nécessite des cycles CPU supplémentaires. Cela nous a causé des problèmes - par exemple, une erreur TimeOut s'est produite. Lors de la mise à l'échelle, ces problèmes ne font qu'empirer, et dans notre cas, nous parlons d'une application très complexe - plus de 20 000 classes et plus de 50 000 méthodes.
Avant de commencer à utiliser JWarmup, les propriétaires de notre application utilisaient des données simulées pour se réchauffer. Sur ces données, le compilateur JIT a précompilé avant la réception des demandes. Mais les données simulées sont différentes des vraies; par conséquent, elles ne sont pas représentatives pour le compilateur. Dans certains cas, une désoptimisation inattendue s'est produite, les performances ont souffert. La solution à ce problème était JWarmup. Il a deux étapes principales de travail - l'enregistrement et la compilation. Alibaba a deux types d'environnements, bêta et production. Les deux reçoivent des demandes réelles des utilisateurs, après quoi la même version de l'application est déployée dans ces deux environnements. Dans l'environnement bêta, seules les données de profilage sont collectées, sur la base desquelles une compilation préliminaire en production est ensuite effectuée.

Voyons plus en détail le type d'informations que nous collectons. Nous devons écrire exactement quelles classes sont initialisées, quelles méthodes sont compilées, puis ces données sont vidées dans le journal sur le disque dur, qui est accessible au compilateur. Le moment le plus difficile est l'initialisation des classes. Son ordre dépend entièrement de la logique d'application.La diapositive montre un exemple - l'initialisation de la classe Bardoit se produire après l'exécution Foo.test(), comme elle l'utilise foo.count. Dans cette situation, nous effectuons l'initialisation au moment où toute la logique nécessaire est déjà terminée.
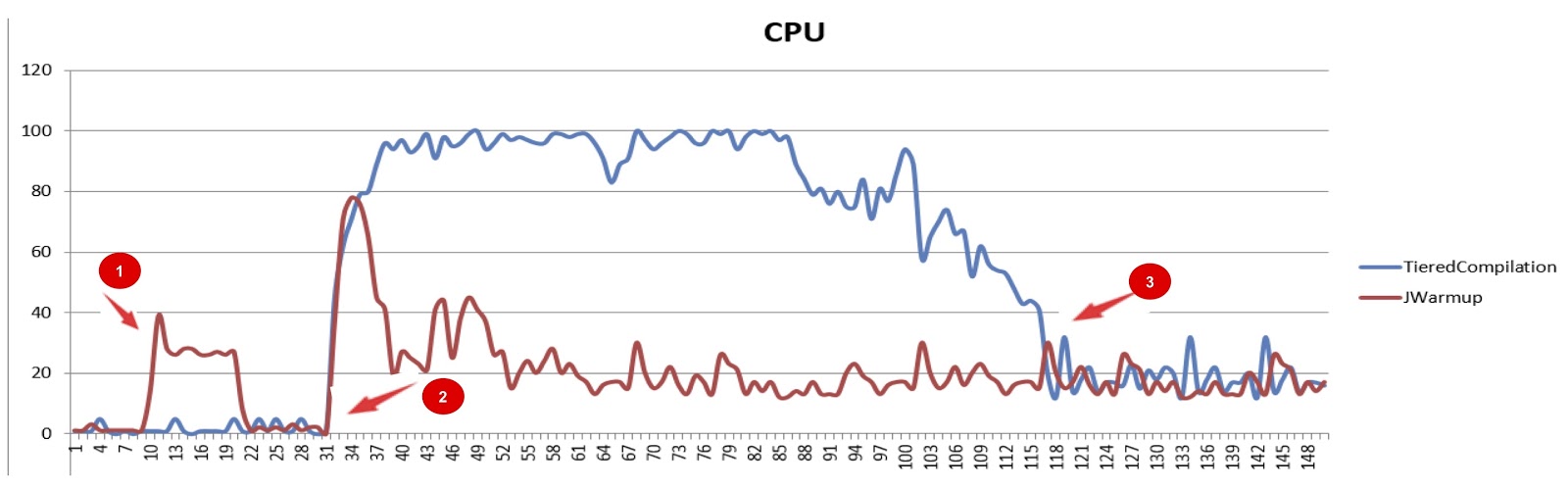
JWarmup (tiered compilation), . , — CPU. JWarmup , CPU, JDK. , , JDK. , , .
JWarmup. , , , groovy-, Java-, . . , , «null check elimination». . , JWarmup , JWarmup, .
, Alibaba.
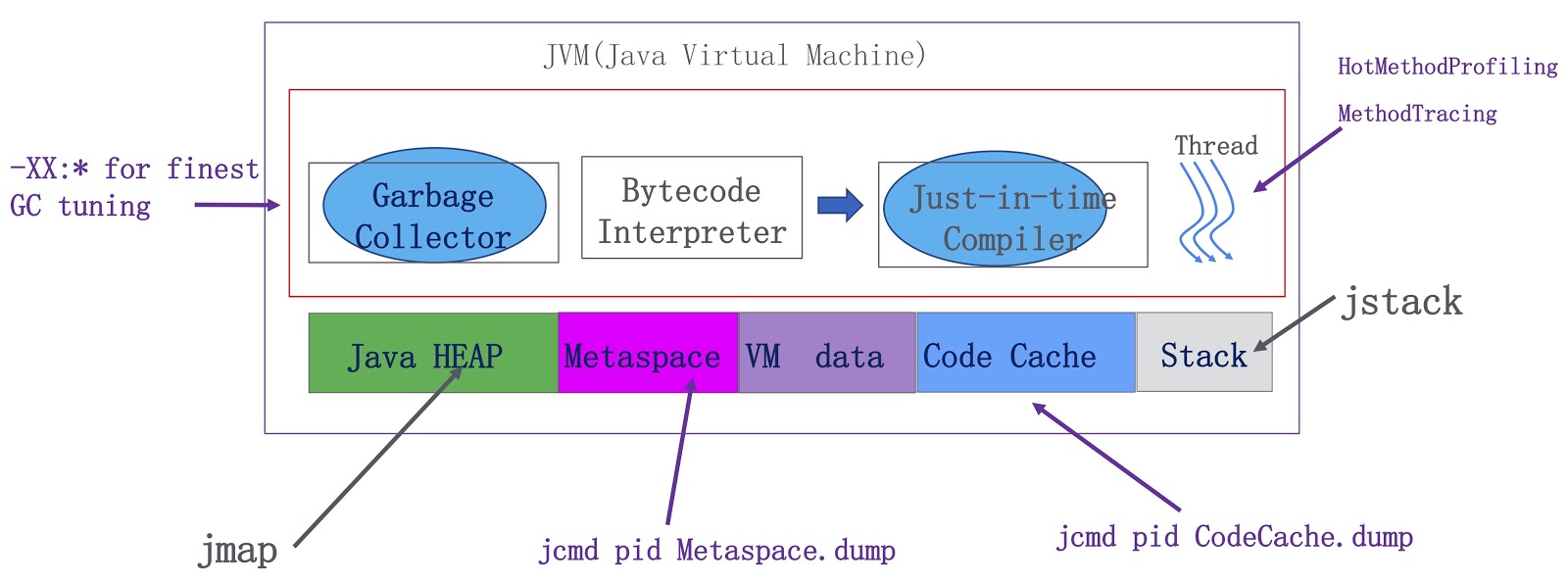
. JVM — , , . Java-, metaspace, VM ( VM) JIT-. OpenJDK. -, , . -, . HotMethodProfiling, , CPU. , , Honest Profiler , , , HotMethodProfiling. MethodTracing. , , . , metaspace . Java-, . metaspace , . Java.
, , ZProfiler.
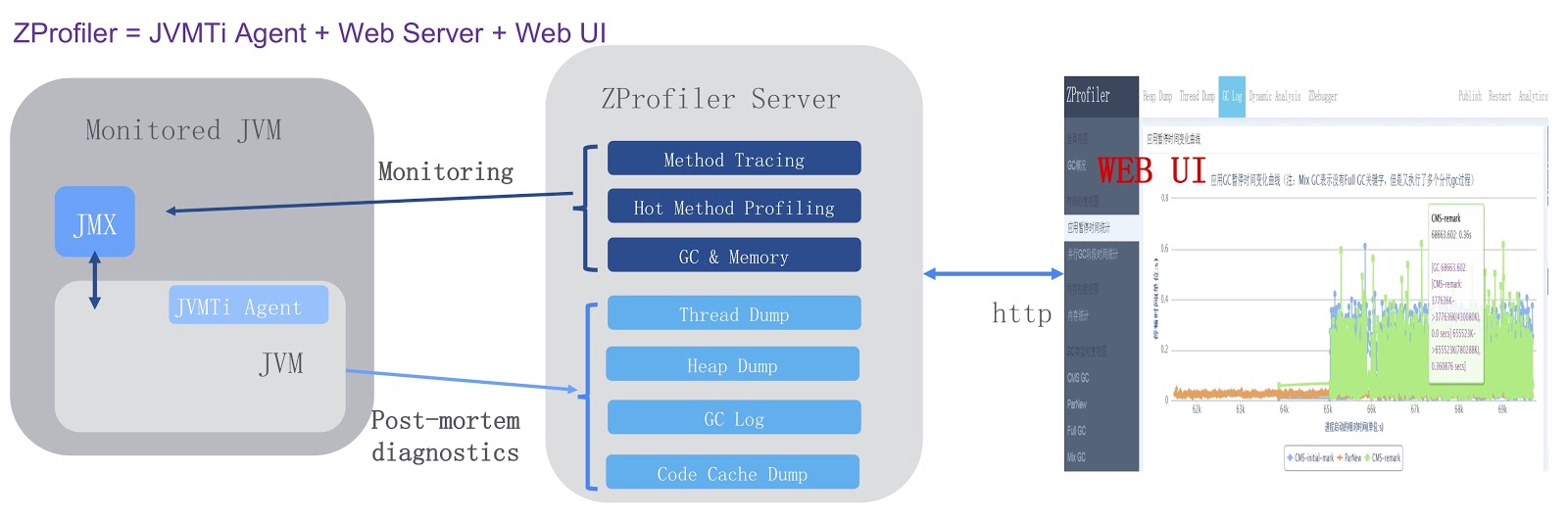
. JVMTi, JVM ( ). , ZProfiler Apache Tomcat. -. ZProfiler JVM. , ZProfiler -UI, . ZProfiler . -, UI JVM. -, ZProfiler post-mortem . , OutOfMemoryError, , JVM ZProfiler, . , , , Eclipse MAT.
. . JVM, GCIH, Alibaba JDK, JWarmup — , ReadyNow Zing JVM. , ZProfiler. , , OpenJDK. , , JWarmup OpenJDK. , OpenJDK Loom, Java. , .
. , , JPoint 2018 . 2019 , JPoint , 5-6 . , Rafael Winterhalter Sebastian Daschner. . , YouTube . JPoint!