Ces dernières années, le Web est devenu très centralisé. Pour restaurer la liberté et le contrôle sur les aspects numériques de nos vies, nous devons comprendre comment nous sommes arrivés à cet état et comment retourner sur la bonne voie. Cet article raconte l'histoire de la décentralisation du Web et le rôle de Tim Berners-Lee dans la lutte en cours pour un Internet libre et ouvert. Les problèmes et les solutions ne sont pas de nature purement technique, mais s'inscrivent plutôt dans un puzzle socio-économique plus vaste. Nous devons tous travailler ensemble pour le résoudre. Reprenons Internet pour toujours et utilisons tout le potentiel du Web, tel que fourni par son créateur.
Le pouvoir au peuple
L'inventeur peut deviner le but et le destin de sa création, mais au final ce sont les gens qui décident comment l'utiliser. John Pemberton était sur le point de soigner les toxicomanes à la morphine lorsqu'il a commencé à fabriquer la potion, maintenant connue sous le nom de Coca-Cola, et le jouet en pâte à modeler Play-Doh a été initialement créé comme agent de nettoyage des murs. Alfred Nobel a créé des prix annuels pour qu'il ne se souvienne pas de lui comme de l'inventeur de la dynamite.
Il est à noter que Tim Berners-Lee n'a jamais eu l'intention de contrôler sa propre invention: son ancien employeur, le CERN, a publié le logiciel World Wide Web pour un usage public, et le réseau lui-même a été
décentralisé afin que personne n'ait le pouvoir et le droit de fermer d'autres personnes. Cette ouverture sans précédent a conduit à
une innovation gratuite à grande échelle et à une créativité illimitée, et a donné le droit de vote à plus de la moitié de la population mondiale. Elle a révolutionné les communications, l'éducation et les affaires. Cependant, la conséquence de cette liberté a également été que tout le monde peut créer des choses contraires à l'esprit d'Internet, telles que du matériel illégal et, ironiquement, des plateformes dont le but principal est la
centralisation .
Le concept de centralisation n'est pas un problème en soi: il y a de bonnes raisons pour une association centralisée de personnes ou de choses. Mais le problème se pose lorsque nous sommes privés de choix, induits en erreur - nous sommes obligés de penser qu'il n'y a qu'une seule porte vers l'espace, que nous possédons en réalité collectivement. Il y a quelque temps, il semblait inimaginable qu'un Internet fondamentalement ouvert devienne la base de services fermés, où nous payons avec nos données personnelles pour une partie des libertés qui sont réellement les nôtres. Cependant, aujourd'hui, la plupart des utilisateurs avec des interactions quotidiennes sont enfermés dans les limites de plusieurs médias sociaux influents. Ces géants collectent des informations du monde entier et accumulent cette richesse dans leur espace clos, où ils agissent simultanément en tant que patron et juge.
Étant donné que le changement s'est produit si soudainement, vous devrez peut-être vous rappeler qu'il n'y a pas si longtemps, le paysage Web était complètement différent. En 2008, le blogueur iranien Hossein Derahshan a été condamné à 20 ans de prison pour blogging. Lui et beaucoup d'autres ont pu exprimer leur opinion critique, car ils avaient le Réseau comme plate-forme ouverte - ils n'ont demandé à personne la permission de publier. Il est important de noter que le mécanisme des hyperliens sur Internet permet aux blogs de se lier les uns aux autres, là encore sans avoir besoin d’autorisation sous quelque forme que ce soit. Cela vous permet de créer un réseau de valeurs décentralisé entre des personnes égales, où les lecteurs gardent un contrôle actif et conscient sur leurs actions. Lorsque Derakhshan a été libéré en 2014,
il est revenu sur un réseau complètement différent : au lieu de lecteurs avec une position active, il a vu des téléspectateurs passifs qui semblaient regarder la télévision. Bien sûr, les technologies du Web ont progressé, mais les principaux fondements du Web se sont dégradés: en seulement six ans, les gens ont commencé à utiliser Internet d'une manière complètement différente.
Bien sûr, les médias sociaux ne sont pas notre ennemi: grâce à eux, l'obstacle à la publication de courts textes et de photographies par toute personne a diminué. Néanmoins, ils travaillent dans le cadre de la stratégie du «gagnant obtient tout»: chacun des acteurs recherche la domination, et non l'interaction mutuelle, comme le reste d'Internet fonctionne. Contrairement aux blogs, nous ne pouvons généralement pas interagir avec les publications d'un réseau à partir d'un autre: nous devons déplacer des personnes ou des données. Le problème bien connu
des jardins clôturés dans les médias sociaux s'est considérablement aggravé depuis 2008. Certains "jardins" ont atteint une taille énorme, mais les murs sont restés.
Le principal problème est que l'accès aux réseaux dominants implique nécessairement de renoncer au contrôle des données personnelles: nous pouvons nous connecter, mais nous payons avec notre propriété numérique. Ces données personnelles sont ensuite utilisées pour nous influencer discrètement à travers la publicité personnalisée de marques, de produits et même de programmes politiques. De plus, une fois à l'intérieur, les gens forment généralement de petites communautés - un effet qui est spécifiquement amplifié par les algorithmes de réseautage social visant à maximiser l'implication au détriment de la diversité. En conséquence,
une bulle de filtre nous isole dans des caméras d'écho distinctes, bien que le Web et les réseaux sociaux aient toujours voulu
rapprocher les gens.
Il n'est pas surprenant que cette situation se reflète dans
trois tâches mondiales que Tim Berners-Lee a formulées en 2017:
- reprendre le contrôle de nos données personnelles;
- empêcher la propagation de la désinformation;
- assurer la transparence de la publicité politique.
De toute évidence, il n'est pas souhaitable que ces problèmes soient résolus de manière centralisée par le biais d'une commission ou d'un comité. Cela crée à nouveau un point d'échec qui, même avec les meilleures intentions, est toujours vulnérable aux abus. En fin de compte, le problème principal n'est pas dans les réseaux sociaux spécifiques, mais dans l'hypercentralisation des données et des personnes, c'est-à-dire du pouvoir. Le contrôle est nécessaire, mais le pouvoir doit appartenir à tous - en tant que droit de posséder des données personnelles et du contenu créé.
Il devient clair que les
principaux obstacles ne sont pas technologiques ; par conséquent,
Tim Berners-Lee appelle à «réunir les scientifiques, les entreprises, la technologie, le gouvernement, la société civile et le monde de l'art pour faire face aux menaces qui pèsent sur Internet» . Dans le même temps, une
mission technologique a été confiée aux scientifiques et ingénieurs: prouver que les réseaux décentralisés avec des données personnelles peuvent être généralisés à l'échelle mondiale et seront aussi pratiques pour les personnes que les plateformes centralisées.
Par conséquent, nous commençons par les problèmes techniques de la décentralisation, en soulignant le rôle de Tim Berners-Lee dans la lutte en cours pour maintenir un réseau ouvert et décentralisé. Après l'excursion historique, nous nous concentrerons sur les changements nécessaires à la décentralisation et examinerons à quoi ressemble un écosystème sain. Concrètement, nous étudierons le projet Solid. En conclusion, nous discutons des questions non résolues et des perspectives d'avenir.
Une brève histoire de la (dé) centralisation du Web
Les réseaux sociaux n'ont pas toujours été la cause de la centralisation - et très probablement, à un moment donné à l'avenir, le problème deviendra différent. La cible se déplace constamment: chaque fois que nous commençons à voir une menace, elle est remplacée par une encore plus grande. La compréhension de ces menaces permet de mieux comprendre les différents aspects de la décentralisation.
La décentralisation comme hypothèse tacite
Au moment où WWW a été inventé, des systèmes décentralisés, y compris Internet, existaient déjà dans le monde. Le courrier électronique est devenu un service encore plus décentralisé que le service de courrier électronique traditionnel qu'il simulait, car différents serveurs de messagerie échangeaient directement des messages. Des protocoles oubliés depuis longtemps, comme le NNTP (Network News Transfer Protocol), ont décentralisé l'échange de nouvelles et d'articles. Bref, la décentralisation n'est pas une idée folle, mais plutôt l'esprit du temps.
Par conséquent, dès le début de la conception du nouveau système hypertexte en 1989, Tim Berners-Lee tenait pour acquis que le système serait décentralisé, contrairement aux systèmes de documentation de l'époque. La principale force du Web est devenue la
polyvalence - l'indépendance du matériel et des logiciels. La décentralisation était une propriété tellement évidente qu'elle n'était même pas mentionnée. Cela se reflète dans l'
article d'origine avec l'annonce WWW , qui met l'accent sur le support universel dans tous les systèmes d'exploitation, mais ne mentionne pas du tout le terme
«décentralisation» .
Le seul composant centralisé de l'architecture réseau est le DNS (Domain Name System). À cette époque, il y avait relativement peu de domaines, et les propriétaires ne changeaient pas, donc le problème n'était pas si aigu. Actuellement, des millions de noms de domaine changent souvent de mains, rompant ainsi les liens existants, éventuellement de manière malveillante. En manipulant le DNS, les gouvernements peuvent bloquer ou modifier l'accès aux sites existants. Tim Berners-Lee dit: Maintenant, il est clair qu'il était préférable de mettre en œuvre immédiatement un système DNS distribué. En dehors de cela, Internet avait tous les composants pour prospérer en tant que système décentralisé.
Bataille de bureau
La guerre des navigateurs dans les années 90 a été la première vague de centralisation, où les entreprises ont tenté d'acquérir une position de monopole et de devenir le seul fournisseur de logiciels pour accéder au Web. Le principe d'universalité de la conception Web exigeait une lisibilité sur n'importe quelle plate-forme, donc rien n'interférait avec le travail de plusieurs navigateurs en même temps - sauf qu'ils cherchaient à dominer le marché, et non à une coexistence mutuellement bénéfique. Les navigateurs Netscape et Microsoft Internet Explorer ont tenté d'attirer les utilisateurs en introduisant de nouvelles fonctionnalités, et la part d'Internet Explorer sur les ordinateurs de bureau à un moment donné a dépassé 90%.
Bien que la concurrence par l'innovation en soi soit merveilleuse, mais en raison de nouvelles fonctionnalités, les navigateurs sont devenus incompatibles entre eux et, par conséquent, ont commencé à menacer directement l'universalité d'Internet. Des icônes sont apparues sur les sites tels que
«Meilleur affichage dans Internet Explorer» , car les développeurs ne pouvaient pas garantir un travail cohérent sur toutes les plateformes. Si quelqu'un ne voulait pas ou ne pouvait pas installer un navigateur spécifique, il risquait de perdre complètement l'accès à ces sites. En conséquence, le monopole d'IE a influencé les choix des utilisateurs en ce qui concerne le navigateur et le système d'exploitation. Le pouvoir sur Internet était concentré entre les mains d'une entreprise, ce qui a ralenti l'innovation.
Le World Wide Web Consortium (W3C) a été fondé par Tim Berners-Lee afin d'assurer la compatibilité et la cohérence entre les navigateurs. Pour ce faire, des recommandations sont émises qui déterminent le bon fonctionnement des technologies Web. Bien que le W3C soit centralisé sur le plan administratif, l'adoption de normes représente le retour d'informations d'un réseau distribué de participants via un processus consensuel. Au début des années 2000, le problème était qu'Internet Explorer, à des moments critiques, s'écartait des recommandations du W3C, forçant les développeurs à suivre les normes réelles ou leur implémentation incorrecte dans le navigateur le plus populaire.
Heureusement, la pression de Firefox et de Safari pendant la deuxième guerre des navigateurs a
finalement forcé Microsoft à changer de cap et à se concentrer sur les normes . Depuis 2010, aucun navigateur ne possède plus des 2/3 du marché mondial, la compatibilité est donc désormais dans l'intérêt des développeurs de navigateurs et des développeurs Web. La balkanisation du réseau due au développement centralisé du navigateur a été largement évitée.
Bataille des moteurs de recherche
La victoire de courte durée de Microsoft était sans importance car la bataille pour la centralisation s'est déplacée vers d'autres domaines. Alors que chaque navigateur cherchait à devenir l'application par défaut, les moteurs de recherche rivalisaient pour devenir le principal point d'entrée sur le Web. Bientôt, peu importe le navigateur que vous utilisiez; L'important était de savoir qui vous a donné les instructions pour la recherche. Après tout, le développement de navigateur gratuit ne génère pas de revenus directs, tandis que les entreprises sont heureuses de payer la première place dans la recherche.
Parmi les moteurs de recherche, plusieurs concurrents sont immédiatement apparus, comme AltaVista et Lycos, mais après seulement quelques années, Google est devenu le leader. En centralisant la recherche, une entreprise a commencé à trop influencer le contenu accessible aux utilisateurs en modifiant les résultats de la recherche pour des conditions données. Même en supposant les meilleures intentions et en ignorant la publicité payante, la présence d'un algorithme unique qui prend des décisions pour un grand nombre de personnes affecte le champ de l'information. Après tout, il n'y a pas de moyen objectif unique de déterminer les
"meilleures" pages Web sur n'importe quel sujet. Des tentatives ont été faites pour manipuler en externe cet algorithme, d'abord à l'aide de mots-clés trompeurs, puis en utilisant des méthodes SEO avancées pour améliorer le classement des sites de diverses manières (parfois douteuses).
Avec l'avènement des moteurs de recherche, la monétisation des données des utilisateurs a commencé. Les requêtes de recherche d'une personne permettent de dresser un profil détaillé des intérêts dans la vie personnelle et professionnelle. Les moteurs de recherche peuvent en savoir plus sur certains aspects de la vie d'une personne que leurs amis proches. Ce profil vous aide à trouver des annonces et des résultats de recherche personnalisés, vous encourageant à visiter des sites et à acheter des choses que vous n'auriez peut-être pas achetées autrement. Bien que la personnalisation soit utile à beaucoup, le problème est le manque de choix et de contrôle. Nous nous concentrons sur les grands moteurs de recherche qui ont accumulé la plus grande quantité de données et affichent des résultats plus pertinents. Cependant, ces moteurs de recherche ne proposent pas d'options - la plupart d'entre eux n'acceptent que nos données personnelles comme moyen de paiement. De plus, nous ne savons pas exactement comment nos données affectent les résultats de recherche, sans parler de leur contrôle. La croissance de la personnalisation a conduit à l'apparition des premières
bulles de filtre , à l'intérieur desquelles nous sommes plus susceptibles de montrer des résultats similaires à ceux sur lesquels nous avons cliqué plus tôt.
La bataille pour nos données personnelles et notre identité
Bien que l'hégémonie de Google soit toujours en cours, les réseaux sociaux ont trouvé un moyen plus puissant de collecter et de monétiser nos données. La révolution des réseaux sociaux dans les années 2000 a poussé les internautes à se connecter, ce qui les a conduits à différentes plateformes pour échanger du texte sur des blogs, des signets, des photos, des vidéos et bien plus encore. Quelques années plus tard, les sociétés de médias sociaux ont créé des plateformes centralisées pour assumer de nombreuses fonctions qui étaient auparavant partagées entre plusieurs fournisseurs. En échange de leurs services, ces plateformes stockent nos données personnelles et demandent le droit de les utiliser. Chacun travaille dans son propre "jardin clôturé".
Comme les moteurs de recherche, les réseaux sociaux fournissent à l'utilisateur une liste linéaire de contenu, classés par facteurs et algorithmes que nous pouvons affecter le moins possible. Contrairement à la recherche, ici, le flux est généré sans aucune requête de recherche de notre côté - comme un téléviseur sans télécommande.
Le flux est soigneusement personnalisé en fonction des données que nous avons délibérément laissées sur le réseau social, combinées avec des traces de l'historique des pages vues
collectées sans notre consentement explicite à l' aide de trackers sur des sites tiers. Dans sa conférence en 2018, Tim Berners-Lee a noté que
la publicité politique était interdite depuis longtemps à la télévision britannique en raison de la crainte qu'un tel moyen direct d'influence ne touche indûment les masses. Selon cette logique, on devrait avoir bien plus peur de la publicité politique hautement personnalisée que les réseaux sociaux modernes admettent. Même si une personne s'abstient d'exprimer explicitement des préférences très personnelles, ces préférences sont
déterminées de manière fiable à partir de fragments apparemment insignifiants d'autres données . L'exploration de données révèle l'orientation sexuelle, l'origine ethnique, les opinions religieuses et politiques d'une personne. Par la suite, les informations sont utilisées pour une exposition ciblée.
Comme lors des batailles précédentes pour la centralisation, les gens se sentent obligés de rejoindre un grand réseau. Le refus d'adhérer signifie sortir du cercle de la communication virtuelle entre amis et proches. Souvent pour les grands-parents, la façon la plus simple de voir les dernières photos de petits-enfants est de créer un compte Facebook ou Instagram.
C'est ainsi que la mémoire numérique de la génération moderne est largement concentrée en un seul endroit, souvent hors du contrôle des utilisateurs eux-mêmes. La centralisation de l'activité en ligne a pris des formes si extrêmes que
certains utilisateurs de Facebook ne sont plus conscients de la possibilité d'accéder à Internet . Malheureusement, ce paradoxe est devenu une réalité dans de nombreux pays où, à l'initiative d'Internet.org, l'organisation [«caritative» fondée par Facebook est d'env. Per.] Une version strictement limitée d'Internet est fournie, ce qui constitue une violation flagrante de la neutralité du réseau.
Pendant ce temps, une autre bataille s'est déroulée en arrière-plan, cette fois pour devenir notre fournisseur d'identité. De plus en plus de sites remplacent leurs propres systèmes d'authentification par un service de grands fournisseurs tels que Google ou Facebook. Il est pratique pour les personnes possédant un compte de se connecter à l'aide du bouton Facebook. Le reste subit une pression supplémentaire pour rejoindre le réseau. Dans les deux cas, ces boutons sont un autre moyen de suivre l'activité en ligne. Cette centralisation nous prive de l'anonymat, c'est-à-dire de la liberté de cacher les données que nous considérons personnelles.
Séparation des données et des services
Dans toutes les batailles répertoriées pour la centralisation, le refrain a un thème: le manque de choix. Absence de choix de navigateur et de système d'exploitation, point d'accès Internet, emplacement de stockage de nos données personnelles. La décentralisation, c'est d'abord la création de conditions de choix favorables en refusant un lieu unique de stockage de données artificiellement lié au service. Ces deux systèmes doivent être séparés l'un de l'autre et offrir à l'utilisateur un choix. Tout comme nous sommes libres de choisir n'importe quelle combinaison de gadgets, de systèmes d'exploitation et de navigateurs pour accéder à Internet, nous devrions pouvoir interagir avec des sites et d'autres personnes sans obligation envers l'une ou l'autre plate-forme sociale.Le retour du contrôle de nos données personnelles, selon Tim Berners-Lee, est effectué parséparation du stockage des données des autres services . Cela signifie que les utilisateurs peuvent stocker leurs données où ils le souhaitent, tout en utilisant n'importe quel service. Pour stocker nos textes, photos et vidéos, nous pouvons choisir n'importe quel fournisseur - ou simplement les stocker sur notre propre ordinateur. Tout service tiers avec notre autorisation utilisera ces données, quel que soit l'emplacement de stockage. Un entrepôt de données peut, bien que non requis, fournir un service d'authentification des utilisateurs critiques.Cette logique donne naissance au concept d'un module de données personnelles.(pod de données personnelles), dans lequel nous stockons toutes les informations créées. Comme le montre la figure ci-dessous, cela peut être compris littéralement: même la partie apparemment insignifiante des données, comme les données fournies, est stockée dans un module privé. Bien que ce degré de décentralisation puisse sembler extrême, rappelez-vous que même des goûts prétendument triviaux révèlent des informations profondément personnelles , il est donc logique de les contrôler. De plus, si une personne ne dépend pas de la permission de quelqu'un d'autre pour publier des données dans son propre module, elle peut mettre des likes et des commentaires où elle veut, sans crainte de censure et de punition.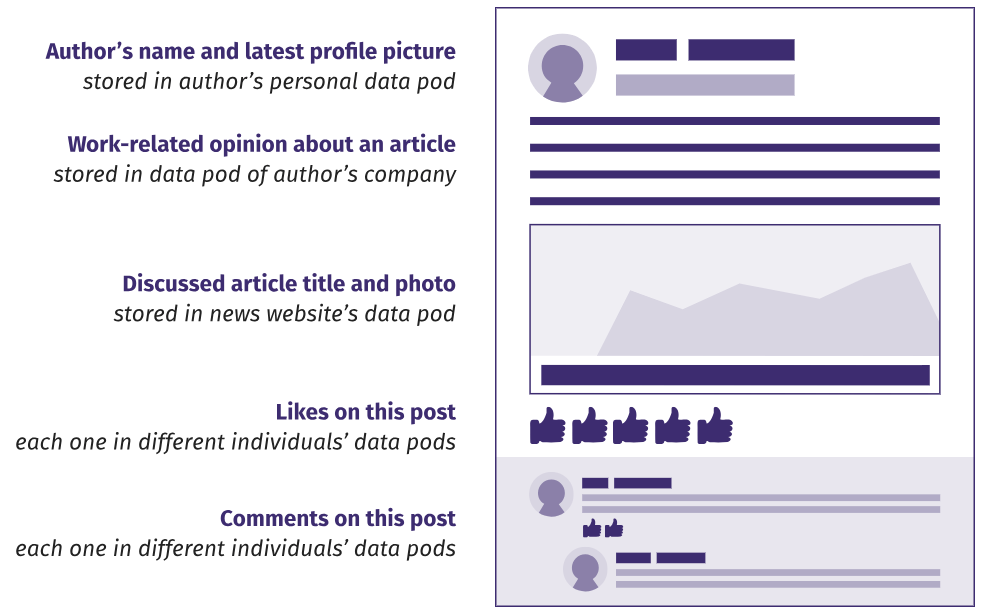 Dans un réseau décentralisé, chaque donnée est stockée dans un emplacement choisi par l'auteur.Cette pleine propriété des données fournit un contrôle d'accès très détaillé: les utilisateurs peuvent accorder sélectivement à des amis ou à des applications des autorisations pour lire ou écrire certains fragments. Par exemple, ils décident de publier leur photo et leur nom complet, qui verra les goûts et les commentaires, quelles applications modifieront les photos et les messages. Vous pouvez modifier ou révoquer une autorisation à tout moment. Plusieurs modules de données à des fins diverses sont autorisés: par exemple, un module pour les photos personnelles et familiales, un module avec des règles de stockage des données professionnelles pour le travail, un module universitaire avec du matériel pédagogique et des notes. Après avoir créé le module, une personne décide quelles données stocker.En choisissant un endroit pour stocker nos propres données, nous empêchons l'accès et l'exploitation non autorisés. Nous ne sommes plus tenus de payer avec nos données pour les services des sociétés Internet. De plus, nous pouvons protéger les parties les plus sensibles des données en les conservant pour nous, en restreignant l'accès uniquement aux personnes et aux services qui en ont vraiment besoin, et uniquement pendant un certain temps.
Dans un réseau décentralisé, chaque donnée est stockée dans un emplacement choisi par l'auteur.Cette pleine propriété des données fournit un contrôle d'accès très détaillé: les utilisateurs peuvent accorder sélectivement à des amis ou à des applications des autorisations pour lire ou écrire certains fragments. Par exemple, ils décident de publier leur photo et leur nom complet, qui verra les goûts et les commentaires, quelles applications modifieront les photos et les messages. Vous pouvez modifier ou révoquer une autorisation à tout moment. Plusieurs modules de données à des fins diverses sont autorisés: par exemple, un module pour les photos personnelles et familiales, un module avec des règles de stockage des données professionnelles pour le travail, un module universitaire avec du matériel pédagogique et des notes. Après avoir créé le module, une personne décide quelles données stocker.En choisissant un endroit pour stocker nos propres données, nous empêchons l'accès et l'exploitation non autorisés. Nous ne sommes plus tenus de payer avec nos données pour les services des sociétés Internet. De plus, nous pouvons protéger les parties les plus sensibles des données en les conservant pour nous, en restreignant l'accès uniquement aux personnes et aux services qui en ont vraiment besoin, et uniquement pendant un certain temps.Innovation indépendante après partage de données et de services
Lorsque les gens eux-mêmes stockent leurs données, il deviendra impossible de les utiliser. Ces changements économiques peuvent être accélérés par une législation telle que le RGPD et expliquant le danger de centralisation à la population, compte tenu des récents scandales avec fuite d'informations privées, comme l'histoire d'Equifax et Facebook. Par conséquent, de nouveaux modèles commerciaux sont nécessaires.La décentralisation nécessite d'éviter les applications isolées. Comme le montre la figure ci-dessous, les applications Web actuelles combinent données et service. En raison de cette connexion, nos contacts LinkedIn ne peuvent pas commenter nos photos Facebook et l'invitation à un événement sur Facebook ne peut pas être affichée sur le calendrier Doodle. D'un autre côté, les applications distribuées agissent comme des vues au-dessus de nos modules de données et d'autres. Après avoir reçu une autorisation spéciale, l'application du flux social peut prendre à partir du module des photos téléchargées par l'application de galerie de photos. Les événements du calendrier personnel avec le statut "visible par tous" sont ajoutés au même flux. Les amis ont accès à certains fragments de nos données via n'importe quelle application qu'ils souhaitent utiliser. Les applications Web centralisées agissent désormais comme des référentiels qui n'échangent pas de données entre elles. Les applications distribuées fonctionnent comme des vues générales au-dessus des modules de données personnelles.Comme le choix des données et du fournisseur de services ne dépend plus du stockage des données, des marchés distincts pour les données et les services. La figure ci-dessous montre que les applications centralisées sont désormais en concurrence pour la propriété des données. Ainsi, les gens ne peuvent pas facilement passer à une application plus pratique, et le transfert de données est une tâche techniquement difficile, si possible. De plus, de nouvelles applications potentiellement plus pratiques rencontrent des problèmes pour entrer sur le marché, car elles ne disposent pas encore de suffisamment de données. Avec les applications décentralisées, les gens choisissent leur fournisseur de services et leur emplacement de stockage séparément, et les entreprises se font concurrence indépendamment sur les deux marchés. Aux deux niveaux, la concurrence repose uniquement sur la qualité des services, le rapport fonctions / valeur.Une telle indépendance signifie que nous pouvons librement basculer entre les fournisseurs de données et de services sans obliger nos amis à faire le même choix. Cela détruit les murs entre les "jardins" car les services interagissent librement entre eux. Les fournisseurs de données et de services peuvent évoluer indépendamment, permettant un cycle d'innovation plus rapide et plus créatif. N'importe qui peut pénétrer n'importe quel marché et attirer des clients si son service est meilleur que les autres, sans avoir besoin de contrôler les données des utilisateurs.
Les applications Web centralisées agissent désormais comme des référentiels qui n'échangent pas de données entre elles. Les applications distribuées fonctionnent comme des vues générales au-dessus des modules de données personnelles.Comme le choix des données et du fournisseur de services ne dépend plus du stockage des données, des marchés distincts pour les données et les services. La figure ci-dessous montre que les applications centralisées sont désormais en concurrence pour la propriété des données. Ainsi, les gens ne peuvent pas facilement passer à une application plus pratique, et le transfert de données est une tâche techniquement difficile, si possible. De plus, de nouvelles applications potentiellement plus pratiques rencontrent des problèmes pour entrer sur le marché, car elles ne disposent pas encore de suffisamment de données. Avec les applications décentralisées, les gens choisissent leur fournisseur de services et leur emplacement de stockage séparément, et les entreprises se font concurrence indépendamment sur les deux marchés. Aux deux niveaux, la concurrence repose uniquement sur la qualité des services, le rapport fonctions / valeur.Une telle indépendance signifie que nous pouvons librement basculer entre les fournisseurs de données et de services sans obliger nos amis à faire le même choix. Cela détruit les murs entre les "jardins" car les services interagissent librement entre eux. Les fournisseurs de données et de services peuvent évoluer indépendamment, permettant un cycle d'innovation plus rapide et plus créatif. N'importe qui peut pénétrer n'importe quel marché et attirer des clients si son service est meilleur que les autres, sans avoir besoin de contrôler les données des utilisateurs.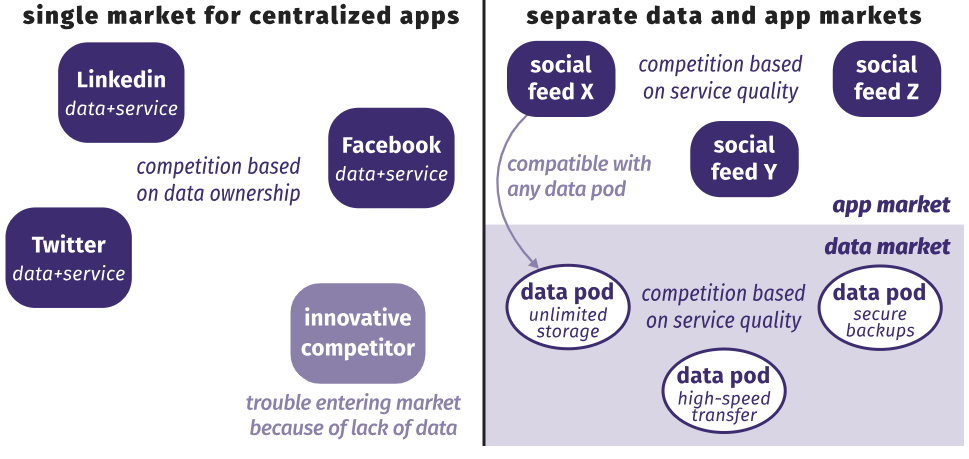 Les applications centralisées sont en concurrence sur un marché pour la propriété de nos données. Dans un réseau distribué, les fournisseurs de données et de services sont en concurrence sur différents marchés.
Les applications centralisées sont en concurrence sur un marché pour la propriété de nos données. Dans un réseau distribué, les fournisseurs de données et de services sont en concurrence sur différents marchés.Projet solide
Pour mettre en œuvre ce concept, Tim Berners-Lee a lancé le projet Solid . Il comprend des spécifications d'interopérabilité, la mise en œuvre de serveurs, clients et applications, ainsi qu'une communauté de développeurs. Ensuite, nous discutons de certaines des caractéristiques uniques de Solid.Relier et intégrer les données personnelles
Le but de Solid est de responsabiliser les gens grâce à la gestion des données personnelles en tant qu'analogue des systèmes de gestion des données personnelles d'entreprise. Le serveur ou module de données Solid est l'équivalent Web du disque dur, où nous stockons des documents arbitraires, et les applications Solid sont similaires aux programmes pour un ordinateur personnel, elles ouvrent uniquement les documents des serveurs Solid sur Internet. Contrairement aux vrais disques durs, les serveurs Solid sont généralement ouverts au monde entier, ils ont donc besoin de paramètres de contrôle d'accès détaillés. Ils déterminent qui et quels documents peuvent être consultés ou modifiés. Tim Berners-Lee lui-même a donné l'exemple en utilisant Solid dans sa vie personnelle et professionnelle pendant plusieurs années.Pour que cela fonctionne à l'échelle du réseau, les données des différents modules doivent être liées par des liens, comme des documents hypertextes. Pour ce faire, Solid utilise le format de données liées : chaque élément de données peut être associé à n'importe quel autre. Par exemple, un commentaire dans le module d'un utilisateur est attaché à une photo dans le module d'un autre, tandis que les deux utilisateurs restent propriétaires de leurs données. Au moment de l'exécution de l'application Solid, les données sont intégrées à partir de plusieurs sources et combinées en un seul ensemble.Les modules fournissent également une authentification décentralisée. Une personne choisit le soi-disant WebID - une adresse Web unique pour l'identification. Cette adresse pointe vers un profil commun et l'utilisateur se connecte à n'importe quel module avec son propre WebID sans avoir besoin d'une authentification distincte sur chaque site ou de l'utilisation d'une plateforme centralisée.Web en lecture-écriture
L'un des aspects les plus importants de Solid est qu'il fournit une plate-forme de lecture / écriture, ce qui était l'objectif initial du WWW . Bien que «l'enregistrement» ait toujours été techniquement possible, dans le sens où n'importe qui pouvait lancer son propre site Web, les révolutions du Web 2.0 et des réseaux sociaux auraient dû grandement simplifier le processus. Le succès de ces plateformes est en partie dû à leur interactivité: désormais tout le monde peut créer et publier du contenu à tout moment, notamment via des appareils mobiles.Solid devrait publier le contenu tout aussi facilement. La différence est que nous publions dans nos propres modules de données, et non dans l'application. Dans le même temps, la liberté d'expression est garantie sans risque de censure. Pour une compatibilité maximale, les données associées doivent être stockées à l'aide deTechnologies du Web sémantique qui lient des éléments de données à leur signification. Ainsi, les applications comprennent (des fragments) les données des autres sans se mettre d'accord sur un format.Nous avons également besoin d'un mécanisme de communication lorsque des objets dans des modules sont créés ou modifiés - en particulier en ce qui concerne les commentaires. Ceci est fourni par la technologie des notifications de données liées : de petits messages automatiques, comme des e-mails, que divers modules de données s'envoient. En combinant ces technologies, Solid met en œuvre le concept de données liées en lecture-écriture, garantissant à tous la participation au Web de données.Potentiel révolutionnaire
En transformant la propriété des données et le rôle des applications dans un écosystème distribué, Solid perturbera de nombreux processus centralisés sur Internet. Vous pouvez désormais exclure les intermédiaires qui contrôlent ces processus, ce qui stimule l'innovation dans de nombreux domaines.Le premier objectif évident est les relations sociales entre les gens. Grâce à Solid, un moyen simple et confidentiel de partager des fichiers multimédias avec des amis, des collègues et des proches apparaît. D'autres exemples sont le travail collaboratif sur divers documents avec un contrôle d'accès clair: organisation de réunions et d'événements - encore une fois avec la pleine propriété des données, le choix d'une application et du stockage, la synchronisation entre les applications, etc.De plus, Technologically Solid est capable de révolutionner des industries entières, telles que les publications scientifiques. Le processus actuel suppose que l'auteur télécharge le manuscrit sur une plateforme centralisée où il est évalué par un groupe de réviseurs fermé. Après approbation, le manuscrit est publié sous forme d'article, puis devient accessible au public, éventuellement moyennant des frais. C'est un processus assez long. La vaste communauté scientifique ne peut lire l'article qu'à la toute fin, s'il est accepté. Le processus est également opaque, car des détails précieux sont cachés au public: les révisions et l'édition d'articles. En règle générale, la rétroaction n'est possible que par un processus lent similaire. Au lieu de cela, une application de publication d'articles distribuée telle que dokieli, permet aux chercheurs de publier de manière indépendante des manuscrits dans leur propre module Solid. Les commentaires des collègues sont stockés dans leurs propres modules, garantissant la liberté d'expression à toute personne qui souhaite participer. Tous les résultats restent ouverts aux commentaires, même après leur publication sur le Web.Réseau décentralisé pour tous
La recentralisation du Web conformément au concept Solid aidera à surmonter les
trois défis posés par Tim Berners-Lee . Nous pouvons reprendre le contrôle des données personnelles en les stockant dans nos propres modules. La désinformation est bloquée car le libre choix des applications vous permet de contrôler votre fil d'actualité - et toute information peut être retracée à la source. La publicité politique devient plus transparente à mesure que chacun décide à qui et quels éléments de données ouvrir. De plus, la séparation des marchés des données et des services nous permet d'envisager d'autres options, généralement sans publicité. Bien que Solid ne résout pas entièrement tous les problèmes, la propriété des données et la liberté de choix sont l'essentiel.
Cependant, vous devez toujours payer pour la liberté: la victoire des droits personnels et de la liberté d'expression contribue en même temps à l'activité illégale, car les réseaux distribués rendent difficile le contrôle des informations. Bien sûr, c'est une question difficile, car dans certains pays, ils proclament des déclarations illégitimes qui sont tout à fait légales ailleurs. Un exemple intrigant est la
popularité croissante du réseau social décentralisé Mastodon au Japon : lorsque Twitter a commencé à supprimer des images douteuses selon les normes américaines, les utilisateurs japonais ont commencé à les publier sur des plateformes moins censurées.
Nous devrons accepter ce compromis entre liberté et contrôle. En l'absence de normes généralement acceptées, le filtrage centralisé des contenus interdits ne sera jamais une solution adéquate.
Cela nous amène à un autre aspect de la décentralisation, à savoir la contradiction entre la liberté et l'universalité. Le paradoxe de la liberté dit qu'une personne ne peut devenir libre que si elle obéit à certaines règles. Autrement dit, nous sommes libres de prendre un vélo et d'aller n'importe où - si seulement nous restons sur le côté droit de la route (dans plusieurs pays à gauche). Ne respectant pas cette règle, nous n'irons nulle part sans accident. Étant donné que la
polyvalence a toujours été la principale préoccupation du Web , les communautés réparties doivent s'entendre sur un cadre de base pour la décentralisation. Comme pour la polyvalence des navigateurs, le consortium W3C joue un rôle important dans la création de normes pour l'interaction des modules de données et des applications. Heureusement, il n'est pas nécessaire de s'entendre sur tous les détails. Le format de données liées vous permet de conclure des accords à plusieurs niveaux dans lesquels plusieurs règles s'appliquent à de nombreux participants, et des règles supplémentaires sont convenues par de plus petits groupes si nécessaire.
Il est important de noter que Solid n'est pas créé pour traiter avec des sociétés spécifiques telles que Google, Facebook ou Twitter. Le projet défie la centralisation dans son ensemble, car bon nombre des problèmes de ces entreprises sont causés par la centralisation et le modèle commercial de propriété des données. Nous sommes arrivés au fait que les entreprises disposent d'un tel volume de données
qu'elles ne peuvent plus prévoir les conséquences à long terme d'une telle centralisation . Par conséquent, il est déraisonnable de continuer à invoquer le
«consentement éclairé» comme excuse, car personne n'est en mesure de comprendre ce qui conduit finalement à l'abandon du contrôle sur des fragments petits ou grands de ses données. Ainsi, le stockage de vos données dans un endroit sûr avec la liberté de choix et un modèle d'autorisation détaillé est la seule option sûre.
Aucun de nous ne rêve du Web sans acteurs majeurs. Bien au contraire:
Tim Berners-Lee insiste sur le fait que le réseau devrait toujours évoluer de très petits à très grands membres. Le problème est que de très grands participants tentent actuellement de supprimer le reste, ce qui compromet les libertés que nous utilisons depuis de nombreuses années. Comme mentionné ci-dessus, la décentralisation est avant tout une liberté de choix: les gens devraient pouvoir entrer librement dans les grandes ou les petites communautés. Et bien que nous soyons confrontés à plusieurs problèmes techniques, notamment en garantissant la même commodité et rapidité que les plateformes centralisées, Solid représente la première solution technique viable. Nous devons maintenant consolider les progrès de la réalité socio-économique afin de décentraliser pleinement le Web. Ce n'est que lorsque nous parvenons à reprendre le contrôle et la liberté de choix pour les actifs numériques les plus précieux, que nous pouvons vraiment dire:
c'est le réseau pour tous .