Expérience de pensée
Imaginez que vous vous réveilliez dans une pièce étrange. Ce n'est pas une chambre confortable dans laquelle vous vous êtes endormi, mais une cellule faiblement éclairée avec un sol frais et humide. Plâtre fissuré sur les murs. Et la seule entrée et sortie est censée être une porte en fer massive, verrouillée avec un cadenas de l'intérieur. Un peu plus haut sur le mur se trouve une fenêtre barrée qui laisse passer un peu de lumière. Si vous regardiez autour de vous, vous seriez parvenu à la conclusion que vous êtes pris au piège, ce serait parfaitement raisonnable. Ça a l'air horrible.
Mais cela vous satisfera-t-il? Probablement pas. Vous voudrez explorer la pièce un peu plus, peut-être tirer le cadenas pour tester sa fiabilité. Ou souhaitez tester la résistance de ces murs en plâtre. Peut-être quelques coups durs et vous faites un trou à travers lequel vous pouvez sortir? Ou peut-être que ces grilles sur la fenêtre ont de si grandes ouvertures que vous pouvez en sortir? L'interaction avec l'environnement vous donne beaucoup plus d'informations que son observation passive. La vision peut être une hypothèse, mais la tester nécessite une réelle interaction avec l'environnement.
Concept de concepts
Le contenu et la conclusion sont des concepts.
Le chien est aussi un concept. Ainsi que la
course , la
forêt , la
beauté , le
vert ou la
mort . Les concepts sont des abstractions que nous distinguons de l'interaction quotidienne avec le monde. Ils forment les blocs de connaissances réutilisables dont les gens ont besoin pour comprendre le monde.
Lorsque nous avons une compréhension conceptuelle de quelque chose, cela signifie que nous avons une certaine expérience avec cette chose, nous l'avons en quelque sorte maîtrisée. Dans le cas du contenu, cette expérience signifie que nous pouvons identifier des objets conteneurs dans le monde qui peuvent contenir quelque chose, les séparer des «non-conteneurs», mettre des choses à l'intérieur, les reprendre et anticiper ce qui se passera, si nous allons en quelque sorte interagir avec eux. Nous pouvons même regarder de nouvelles choses et comprendre si elles peuvent potentiellement contenir quelque chose en elles-mêmes ou vice versa - si elles peuvent être enfermées dans un autre sujet.
Les principales approches de la compréhension conceptuelle en IA, y compris les systèmes d'apprentissage profond formés sur des
ensembles de données comme
ImageNet , ont apparemment certaines de ces capacités, mais elles manquent d'une compréhension plus profonde - l'expérience qui vient de l'interaction. En percevant une image ou même une vidéo, ces approches peuvent être en mesure de déterminer s'il y a un type spécifique de «récipient» dessus, par exemple une tasse, une maison ou une bouteille, et également de déterminer où cet objet se trouve dans l'image. Mais ils échoueront certainement lorsqu'ils rencontreront un type inexploré d'un tel objet. Une demande de se placer quelque part n'aura qu'un malentendu complet dans un tel système, car elle corrèle le concept d'un objet conteneur avec un tableau de signes visuels, mais n'a pas une compréhension active du terme de contenu à l'intérieur de quelque chose.
Concepts de l'expérience sensorimotrice
Henri Poincaré a été l'un des premiers à souligner le rôle des représentations sensorimotrices dans la compréhension humaine. Dans son livre Science and Hypothesis, il a soutenu qu'un être immobile ne pourrait jamais maîtriser le concept d'espace tridimensionnel. Il n'y a pas si longtemps, plusieurs scientifiques cognitifs ont suggéré que les représentations conceptuelles découlent de l'intégration de la perception et de l'action. Par exemple,
O'Regan et Noë définissent l'expérience sensorimotrice comme «une structure de règles qui définit les changements sensoriels produits par diverses actions motrices», et l'observation passive comme «un mode d'exploration du monde qui repose sur la connaissance de l'expérience sensorimotrice».
Noë ajoute que «les concepts sont une sorte d'approche pour gérer ce qui nous entoure.»
Bien que l'importance de l'expérience sensorimotrice ait été appréciée au sein de la communauté cognitive, ces idées n'ont conduit qu'à quelques modèles de calcul spécifiques explorant son rôle dans l'élaboration des concepts. Dans l'
article que nous avons présenté à AAAI-18, nous avons montré un modèle informatique qui explore les concepts par l'interaction avec l'environnement.
Qu'avons-nous fait
Nous avions prévu de réaliser et d'étudier les deux principales capacités qui composent la compréhension conceptuelle: la capacité de détecter activement un concept et la capacité de tirer des conclusions ou d'agir sur ce concept. De plus, nous avons voulu étudier des situations dans lesquelles les capacités interactives sont préférables aux approches passives, et comprendre comment l'utilisation de concepts simples déjà étudiés peut aider à étudier des concepts plus complexes.
Nous avons commencé par développer un terrain d'entraînement virtuel spécial pour explorer les concepts actifs, un environnement que nous appelons
PixelWorld (disponible sur
github ). Dans ce monde, les choses sont arrangées un peu plus facilement que dans le vrai. Il s'agit d'un champ bidimensionnel discret contenant un agent pixel et un ou plusieurs objets d'un autre type, également constitué de pixels (par exemple, des lignes, des points ou des conteneurs).
L'agent a une implémentation assez simple: il ne perçoit que l'espace de 3 × 3 cellules autour de lui et peut se déplacer vers le haut, le bas, la gauche, la droite ou s'arrêter et envoyer des informations. Une telle mise en œuvre nécessite l'étude même des idées les plus élémentaires sur le monde, à la fois le concept même d'objet et le concept de concepts d'interaction. Malgré le fait que cela puisse ressembler à une privation sensorielle excessive, l'élimination de la perception visuelle riche nous permet de nous concentrer sur le rôle de transformer un comportement multiforme en une vision significative du monde.
Nous avons formé des agents à deux types de tâches différents. La première tâche consistait à étudier l'environnement et à signaler si le concept nécessaire était présent dans l'environnement. Par exemple, un conteneur. Et c'était récompensé si la réponse était correcte. La deuxième tâche consistait à agir sur ce concept. Par exemple, mettez-vous dans ce récipient. Cela a été récompensé s'il a correctement rempli la tâche et l'a signalé. Pour cela, nous avons utilisé une formation de renforcement.
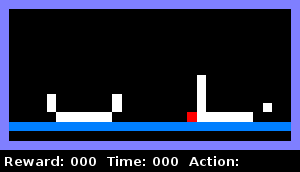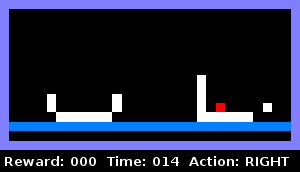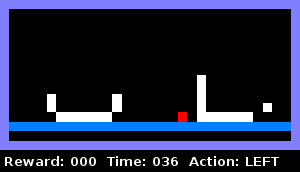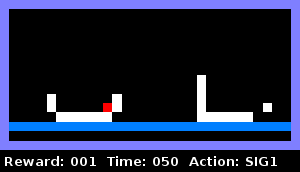
Par exemple, nous avons appris à l'agent à déterminer quand il était enfermé dans un objet dans un plan horizontal. L'animation ci-dessous illustre ce comportement: l'agent vérifie s'il y a un mur à droite, puis vérifie s'il y a un mur à gauche. Dès que les deux tests sont réussis, il signale qu'il est «en détention».

Nous avons formé le prochain agent à comprendre la même chose lorsqu'il est déjà entouré de deux objets sur les côtés: un conteneur solide et un conteneur avec un trou. L'animation montre que l'agent pénètre dans le bon objet, vérifiant s'il s'agit d'un conteneur solide. Il détecte un trou et monte ensuite dans le conteneur gauche, signalant à la fin qu'il est en détention.
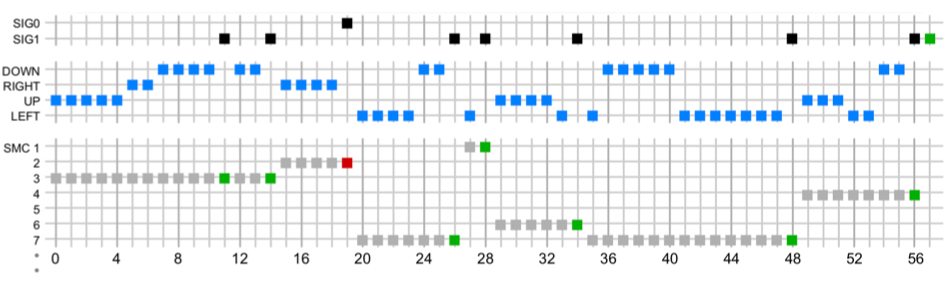
Nous pouvons comprendre plus en détail ce que fait l'agent en analysant les enregistrements de ses actions:
La figure ci-dessus montre chaque action effectuée par l'agent dans l'animation ci-dessus. Chaque case représente une action, le temps augmente de gauche à droite. «DOWN», «RIGHT», «UP» et «LEFT» sont les principales actions de l'agent, et chaque ligne de «SMC» représente un cas particulier d'interaction sensorimotrice que l'agent peut effectuer. SMC (
contingences sensorimotrices - environ transl. ) Peut être représenté comme de petits programmes qui, lorsqu'ils sont exécutés, utilisent une séquence d'actions de base jusqu'à ce que l'agent décide d'arrêter et d'envoyer l'un des deux signaux qui signifient le succès ("SIG1", vert) ou la défaite ("SIG0", rouge). Chacun de ces SMC est né comme un agent formé pour résoudre un problème conceptuel plus simple. Par exemple, «SMC 3» a été formé pour monter dans un conteneur s'il était initialement sur le sol à sa gauche. Et c'est la première chose que fait l'agent dans l'animation de l'étape 0 à 11. Ainsi, l'agent peut effectuer des tâches complexes, telles que faire une conclusion finale sur la conclusion, effectuer une séquence de SMC de bas niveau correspondants.
Après cela, nous avons élargi nos concepts au-delà du terme de la conclusion et inclus des concepts tels que le fait d'être au-dessus d'un objet ou d'être à gauche de deux objets:


La formation de ces agents dans un seul environnement ne serait pas suffisante, car pour comprendre quels aspects de l'environnement sont liés aux concepts et lesquels ne le sont pas, de nombreux environnements différents sont nécessaires. La présence de nombreux types d'environnements nous permet également de déterminer les types dans lesquels une approche active et la réutilisation de comportements développés précédemment bénéficieraient d'approches passives.
Pour répondre à ce besoin, nous avons appliqué un type spécial d'enregistrement basé sur une logique de premier ordre pour préparer des tableaux de données pour des expériences utilisant des expressions logiques à la fois pour générer des médias et pour les marquer en fonction du concept qui y est représenté. Nous avons créé 96 tableaux de ce type organisés en blocs de formation, de concepts simples à complexes. Le système d'enregistrement et les environnements mentionnés ci-dessus sont contenus dans la version PixelWorld.
Ce que nous avons
Nous avons comparé notre approche active avec celle passive, en utilisant un réseau de neurones convolutionnels, formé pour déterminer si un concept est présent, basé sur une perception statique de l'environnement entier. Pour les concepts qui utilisent la «conclusion», l'approche interactive est clairement supérieure au réseau convolutionnel. Pour les concepts impliquant divers objets de nombreuses formes et relations spatiales, nous avons constaté que le réseau de convolution fonctionnait mieux dans certains cas, mais pire dans d'autres. Il convient de noter que les approches passives, par définition, ne peuvent pas interagir avec l'environnement, dans ce cas, la seule chose à laquelle on pouvait s'attendre était une détection statique du concept. Seule notre approche proactive peut réussir dans des environnements qui nécessitent une compréhension d'une sorte d'interaction ou de relation avec le concept.
Nous avons également constaté que la réutilisation du comportement améliorait les résultats pour les deux tâches (détection et interaction), avec les résultats les plus évidents dans les cas où les concepts incluaient plusieurs objets ou nécessitaient des séquences complexes dans le comportement.
Conclusions
Nos travaux montrent que les représentations conceptuelles sensorimotrices interactives peuvent être formalisées et assimilées. Bien que les expériences reflétées dans cet article aient aidé à identifier le rôle de l'interaction d'une manière générale, leur combinaison avec l'approche du
système de vision générative pourrait être utile pour étudier les concepts du monde réel. De plus, combiner des représentations sensorimotrices avec des techniques comme les «
réseaux de schémas » permettrait à l'agent d'avoir une représentation interne du monde extérieur qu'il pourra utiliser pour la simulation et la planification.
Bien que l'intelligence artificielle galopante soit un sujet qu'il vaut mieux laisser pour les films de science-fiction, nous pensons que l'extraction des concepts de l'interaction sensorimotrice est l'une des clés pour aller au-delà des techniques modernes d'intelligence artificielle passive.