 Publié par Denis Tsyplakov , architecte de solutions, DataArt
Publié par Denis Tsyplakov , architecte de solutions, DataArtDans DataArt, je travaille de deux manières. Dans le premier, j'aide les gens à réparer des systèmes qui sont cassés d'une manière ou d'une autre et pour diverses raisons. Dans le second, j'aide à concevoir de nouveaux systèmes afin qu'ils ne soient pas cassés à l'avenir, ou, plus réaliste, les casser était plus difficile.
Si vous ne faites pas quelque chose de fondamentalement nouveau, par exemple le premier moteur de recherche Internet ou l'intelligence artificielle au monde pour contrôler le lancement de missiles nucléaires, la création d'une bonne conception de système est assez simple. Il suffit de prendre en compte toutes les exigences, d'examiner la conception de systèmes similaires et de faire à peu près la même chose, sans commettre de graves erreurs. Cela ressemble à une simplification excessive du problème, mais rappelons que dans le chantier est l'année 2019, et il existe des «recettes standard» pour la conception du système pour presque tout. Une entreprise peut s'attaquer à des tâches techniques complexes - par exemple, traiter un million de fichiers PDF hétérogènes et en supprimer des tableaux de dépenses - mais l'architecture du système est rarement très originale. L'essentiel ici n'est pas de se tromper en déterminant quel système nous construisons, et de ne pas rater le choix des technologies.
Des erreurs typiques se produisent régulièrement dans le dernier paragraphe, dont certaines dont je parlerai dans un article.
Quelle est la difficulté de choisir une pile technique? L'ajout de toute technologie au projet le rend plus difficile et apporte une sorte de limitations. Par conséquent, l'ajout d'un nouvel outil (framework, bibliothèque) ne doit être effectué que lorsque cet outil est plus utile que nuisible. Dans les conversations avec les membres de l'équipe sur l'ajout de bibliothèques et de frameworks, j'utilise souvent en plaisantant l'astuce suivante: «Si vous voulez ajouter une nouvelle dépendance au projet, vous mettez une boîte de bière pour l'équipe. Si vous pensez que cette dépendance d'une caisse de bière n'en vaut pas la peine, ne l'ajoutez pas. »
Supposons que nous créons une certaine application, disons, en Java et que nous ajoutions la bibliothèque TimeMagus au projet pour manipuler les dates (un exemple est fictif). La bibliothèque est excellente, elle nous offre de nombreuses fonctionnalités qui ne sont pas disponibles dans la bibliothèque de classes standard. Comment une telle décision peut-elle être nuisible? Regardons les scénarios possibles:
- Tous les développeurs ne connaissent pas une bibliothèque non standard, le seuil d'entrée pour les nouveaux développeurs sera plus élevé. Les chances augmentent qu'un nouveau développeur commettra une erreur lors de la manipulation d'une date à l'aide d'une bibliothèque inconnue.
- La taille de la distribution augmente. Lorsque la taille de l'application moyenne sur Spring Boot peut facilement atteindre 100 Mo, ce n'est en aucun cas une bagatelle. J'ai vu des cas où, pour le bien d'une méthode, une bibliothèque de 30 Mo a été tirée dans le kit de distribution. Ils l'ont justifié ainsi: "J'ai utilisé cette bibliothèque dans un projet précédent, et il y a là une méthode pratique."
- Selon la bibliothèque, l'heure de début peut augmenter considérablement.
- Le développeur de la bibliothèque peut abandonner son idée originale, puis la bibliothèque commencera à entrer en conflit avec la nouvelle version de Java, ou un bogue sera détecté (provoqué, par exemple, par un changement de fuseau horaire), et aucun correctif ne sera publié.
- À un moment donné, la licence de la bibliothèque entrera en conflit avec la licence de votre produit (vérifiez-vous les licences de tous les produits que vous utilisez?).
- Jar hell - La bibliothèque TimeMagus a besoin de la dernière version de la bibliothèque SuperCollections, puis après quelques mois, vous devez connecter la bibliothèque pour l'intégration avec une API tierce, qui ne fonctionne pas avec la dernière version de SuperCollections, et ne fonctionne qu'avec la version 2.x. Vous ne pouvez pas connecter une API. Il n'y a pas d'autre bibliothèque pour travailler avec cette API.
D'un autre côté, la bibliothèque standard nous fournit des outils pratiques pour manipuler les dates, et si vous n'avez pas besoin de maintenir, par exemple, un calendrier exotique ou de calculer le nombre de jours à partir d'aujourd'hui jusqu'au «deuxième jour de la troisième nouvelle lune de l'année précédente de l'aigle planeur», cela peut valoir la peine s'abstenir d'utiliser une bibliothèque tierce. Même si c'est complètement merveilleux et à l'échelle d'un projet, cela vous fera économiser jusqu'à 50 lignes de code.
L'exemple considéré est assez simple et je pense qu'il est facile de prendre une décision. Mais il existe un certain nombre de technologies qui sont répandues, à l'oreille de tous, et leur utilisation est évidente, ce qui rend le choix plus difficile - elles offrent vraiment de sérieux avantages au développeur. Mais cela ne doit pas toujours être l'occasion de les faire glisser dans votre projet. Regardons certains d'entre eux.
Docker
Avant l'émergence de cette technologie vraiment cool, lors du déploiement de systèmes, de nombreux problèmes désagréables et complexes étaient liés aux conflits de versions et aux dépendances obscures. Docker vous permet de créer un instantané de l'état du système, de le faire rouler en production et de l'exécuter là-bas. Cela permet d'éviter les conflits mentionnés, ce qui, bien sûr, est formidable.
Auparavant, cela se faisait de manière monstrueuse et certaines tâches n'étaient pas résolues du tout. Par exemple, vous avez une application PHP qui utilise la bibliothèque ImageMagick pour travailler avec des images, votre application a également besoin de paramètres php.ini spécifiques et l'application elle-même est hébergée à l'aide d'Apache httpd. Mais il y a un problème: certaines routines régulières sont implémentées en exécutant des scripts Python à partir de cron, et la bibliothèque utilisée par ces scripts entre en conflit avec les versions des bibliothèques utilisées dans votre application. Docker vous permet de regrouper l'intégralité de votre application, ainsi que les paramètres, les bibliothèques et un serveur HTTP, dans un conteneur qui sert les requêtes sur le port 80 et les routines dans un autre conteneur. Tous ensemble fonctionneront parfaitement et vous pouvez oublier le conflit des bibliothèques.
Dois-je utiliser Docker pour emballer chaque application? Mon avis: non, ça ne vaut pas le coup. L'image montre une composition typique d'une application dockée déployée dans AWS. Les rectangles ici indiquent les couches d'isolation que nous avons.
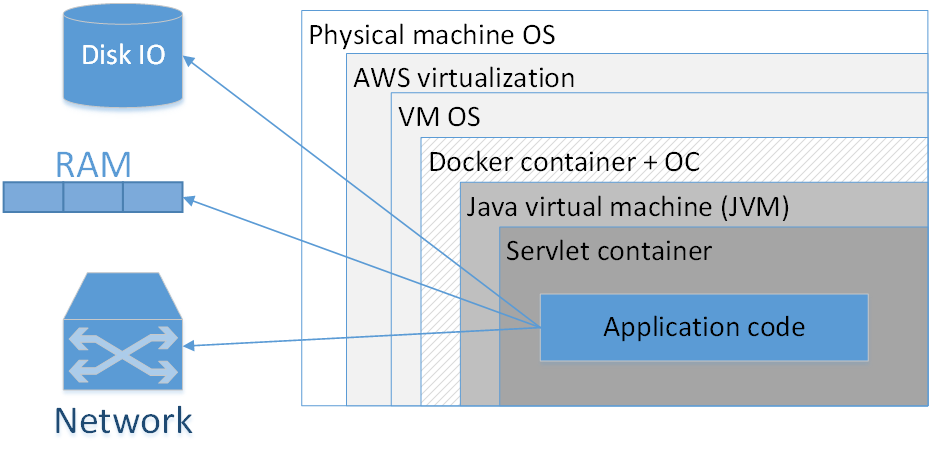
Le plus grand rectangle est la machine physique. Vient ensuite le système d'exploitation de la machine physique. Ensuite - le virtualiseur amazonien, puis le système d'exploitation de la machine virtuelle, puis le conteneur de docker, suivi du système d'exploitation du conteneur, de la JVM, puis du conteneur de servlet (s'il s'agit d'une application Web), et votre code d'application est déjà à l'intérieur. Autrement dit, nous voyons déjà quelques couches d'isolation.
La situation sera encore pire si nous regardons l'acronyme JVM. JVM est, curieusement, la machine virtuelle Java, c'est-à-dire qu'en fait, nous avons toujours au moins une machine virtuelle en Java. Ajouter ici un conteneur Docker supplémentaire, d'une part, ne donne souvent pas un tel avantage notable, car la JVM en elle-même nous isole déjà assez bien de l'environnement externe, et d'autre part, ce n'est pas sans coût.
J'ai pris des chiffres d'une étude IBM, si ce n'est par erreur, il y a deux ans. En bref, si nous parlons des opérations sur le disque, de l'utilisation du processeur ou de l'accès à la mémoire, Docker n'ajoute presque pas de surcharge (littéralement une fraction de pour cent), mais si nous parlons de latence du réseau, les retards sont assez visibles. Ils ne sont pas gigantesques, mais selon l'application que vous utilisez, ils peuvent vous surprendre désagréablement.
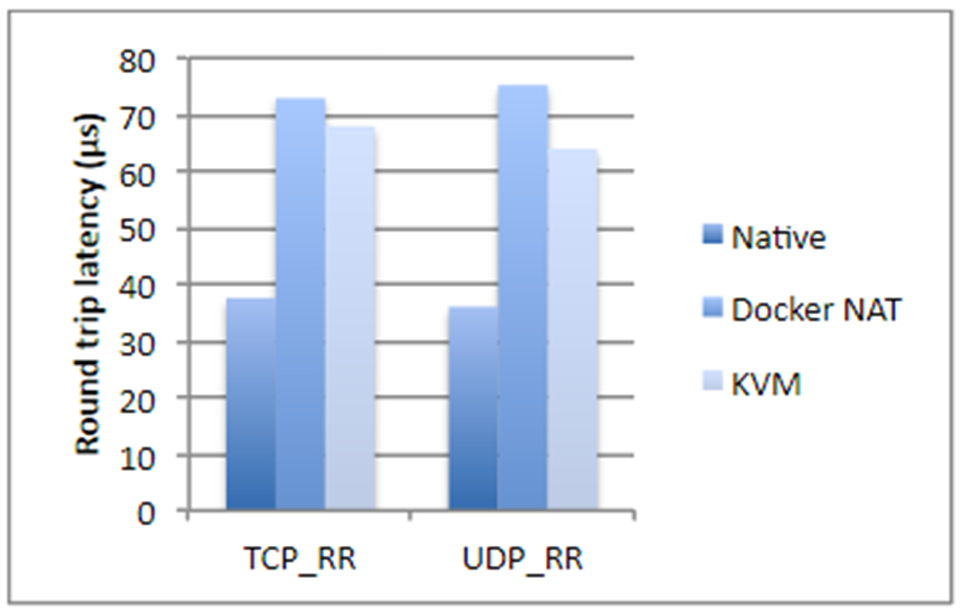
De plus, Docker consomme de l'espace disque supplémentaire, occupe une partie de la mémoire et ajoute du temps de démarrage. Ces trois points ne sont pas critiques pour la plupart des systèmes - il y a généralement beaucoup d'espace disque et de mémoire. Le temps de lancement, en règle générale, n'est pas non plus un problème critique, l'essentiel est que l'application démarre. Mais il existe encore des situations où la mémoire peut s'épuiser et l'heure de démarrage totale du système, composé de vingt services dépendants, est déjà assez grande. De plus, cela affecte le coût de l'hébergement. Et si vous êtes engagé dans un trading à haute fréquence, Docker ne vous convient absolument pas. Dans le cas général, il est préférable de ne pas ancrer une application sensible aux retards du réseau jusqu'à 250-500 ms.
De plus, avec le docker, l'analyse des problèmes dans les protocoles réseau est sensiblement compliquée, non seulement les retards augmentent, mais tous les timings deviennent différents.
Quand Docker est-il vraiment nécessaire?
Lorsque nous avons différentes versions du JRE, et ce serait bien de le faire glisser. Il y a des moments où vous devez exécuter une certaine version de Java (pas «la dernière Java 8», mais quelque chose de plus spécifique). Dans ce cas, il est bon d'emballer le JRE avec l'application et de l'exécuter en tant que conteneur. En principe, il est clair que différentes versions de Java peuvent être mises sur le système cible en raison de JAVA_HOME, etc. Mais Docker dans ce sens est beaucoup plus pratique, car vous connaissez la version exacte du JRE, tout est emballé et avec un autre JRE, l'application ne démarre même pas par accident .
Docker est également nécessaire si vous avez des dépendances sur certaines bibliothèques binaires, par exemple pour le traitement d'images. Dans ce cas, il peut être judicieux de regrouper toutes les bibliothèques nécessaires avec l'application Java elle-même.
Le cas suivant se réfère à un système qui est un composite complexe de divers services écrits dans différentes langues. Vous avez un morceau sur Node.js, une partie en Java, une bibliothèque en Go, et, en plus, une sorte de Machine Learning en Python. Tout ce zoo doit être soigneusement et soigneusement réglé afin d'apprendre à ses éléments à se voir. Dépendances, chemins, adresses IP - tout cela doit être peint et soigneusement relevé en production. Bien sûr, dans ce cas, Docker vous aidera beaucoup. De plus, le faire sans son aide est tout simplement douloureux.
Docker peut offrir une certaine commodité lorsque vous devez spécifier de nombreux paramètres différents sur la ligne de commande pour démarrer l'application. D'un autre côté, les scripts bash le font très bien, souvent à partir d'une seule ligne. Décidez lequel utiliser le mieux.
La dernière chose qui vous vient à l'esprit est la situation lorsque vous utilisez, disons, Kubernetes, et que vous devez faire une orchestration du système, c'est-à-dire augmenter un certain nombre de microservices différents qui évoluent automatiquement selon certaines règles.
Dans tous les autres cas, Spring Boot est suffisant pour tout regrouper dans un seul fichier jar. Et, en principe, le pot Springboot est une bonne métaphore pour le conteneur Docker. Bien sûr, ce n'est pas la même chose, mais en termes de facilité de déploiement, ils sont vraiment similaires.
Kubernetes
Et si nous utilisons Kubernetes? Pour commencer, cette technologie vous permet de déployer un grand nombre de microservices sur différentes machines, de les gérer, d'effectuer une mise à l'échelle automatique, etc. Cependant, il existe de nombreuses applications qui vous permettent de contrôler l'orchestration, par exemple, Puppet, CF engine, SaltStack, etc. Kubernetes lui-même est certainement bon, mais il peut ajouter des frais généraux importants, avec lesquels tous les projets ne sont pas prêts à vivre.
Mon outil préféré est Ansible, combiné avec Terraform là où vous en avez besoin. Ansible est un outil léger déclaratif assez simple. Il ne nécessite pas l'installation d'agents spéciaux et possède la syntaxe compréhensible des fichiers de configuration. Si vous connaissez Docker compose, vous verrez immédiatement des sections qui se chevauchent. Et si vous utilisez Ansible, il n'est pas nécessaire de pré-rezerez - vous pouvez déployer des systèmes en utilisant des moyens plus classiques.
Il est clair que tout de même, ce sont des technologies différentes, mais il y a un ensemble de tâches dans lesquelles elles sont interchangeables. Et une approche consciencieuse de la conception nécessite une analyse de la technologie qui convient le mieux au système en cours de développement. Et comment il vaudra mieux y correspondre dans quelques années.
Si le nombre de services différents sur votre système est petit et que leur configuration est relativement simple, par exemple, vous n'avez qu'un seul fichier jar et vous ne voyez pas de croissance soudaine et explosive de la complexité, vous pouvez probablement vous en tirer avec les mécanismes de déploiement classiques.
Cela soulève la question «attendez, comment est un fichier jar?». Le système doit comprendre autant de microservices atomiques que possible! Voyons qui et quoi le système devrait utiliser avec les microservices.
Microservices
Tout d'abord, les microservices permettent d'atteindre une plus grande flexibilité et évolutivité, et permettent un versionnage flexible des différentes parties du système. Supposons que nous ayons une sorte d'application qui est en production depuis de nombreuses années. La fonctionnalité est en croissance, mais nous ne pouvons pas la développer à l'infini de manière extensive. Par exemple.
Nous avons une application dans Spring Boot 1 et Java 8. Une merveilleuse combinaison stable. Mais l'année est 2019, et que cela nous plaise ou non, nous devons évoluer vers Spring Boot 2 et Java 12. Même la transition relativement simple d'un grand système vers la nouvelle version de Spring Boot peut être très laborieuse, mais il faut sauter par-dessus l'abîme de Java 8 à Java 12 Je ne veux pas parler. Autrement dit, en théorie, tout est simple: nous migrons, corrigeons les problèmes qui se sont posés, nous testons tout et l'exécutons en production. En pratique, cela peut signifier plusieurs mois de travail qui n'apportent pas de nouvelles fonctionnalités à l'entreprise. Un petit passage à Java 12, comme vous le savez, ne fonctionne pas non plus. Ici, l'architecture de microservices peut nous aider.
Nous pouvons allouer un groupe compact de fonctions de notre application dans un service distinct, migrer ce groupe de fonctions vers une nouvelle pile technique et le mettre en production en un temps relativement court. Répétez le processus pièce par pièce jusqu'à épuisement des anciennes technologies.
De plus, les microservices peuvent fournir une isolation des pannes, lorsqu'un composant tombé ne détruit pas le système entier.
Les microservices nous permettent d'avoir une pile technique flexible, c'est-à-dire de ne pas tout écrire en une seule pièce dans une langue et une version, et si nécessaire d'utiliser une pile technique différente pour les composants individuels. Bien sûr, c'est mieux lorsque vous utilisez une pile technique uniforme, mais ce n'est pas toujours possible, et dans ce cas, les microservices peuvent vous aider.
Les microservices permettent également de résoudre techniquement un certain nombre de problèmes de gestion. Par exemple, lorsque votre grande équipe se compose de groupes distincts travaillant dans différentes entreprises (assis dans des fuseaux horaires différents et parlant différentes langues). Les microservices aident à isoler cette diversité organisationnelle par des composants qui seront développés séparément. Les problèmes d'une partie de l'équipe resteront dans un même service et ne se propageront pas dans toute l'application.
Mais les microservices ne sont pas le seul moyen de résoudre ces problèmes. Curieusement, il y a quelques décennies, pour la moitié d'entre eux, les gens ont proposé des classes, et un peu plus tard - les composants et le modèle d'inversion de contrôle.
Si nous regardons Spring, nous voyons qu'il s'agit en fait d'une architecture de microservices à l'intérieur d'un processus Java. Nous pouvons déclarer un composant, qui, par essence, est un service. Nous avons la possibilité d'effectuer une recherche via @Autowired, il existe des outils pour gérer le cycle de vie des composants et la possibilité de configurer séparément les composants à partir d'une douzaine de sources différentes. En principe, nous obtenons presque tout ce que nous avons avec les microservices - uniquement dans un seul processus, ce qui réduit considérablement les coûts. Une classe Java standard est le même contrat d'API qui vous permet également d'isoler les détails de l'implémentation.
À strictement parler, dans le monde Java, les microservices sont les plus similaires à OSGi - nous avons là une copie presque exacte de tout ce qui est dans les microservices, sauf, en plus de la possibilité d'utiliser différents langages de programmation et l'exécution de code sur différents serveurs. Mais même en restant dans les capacités des classes Java, nous avons un outil assez puissant pour résoudre un grand nombre de problèmes d'isolement.
Même dans un scénario «managérial» avec isolement d'équipe, nous pouvons créer un référentiel séparé qui contient un module Java distinct avec un contrat externe clair et un ensemble de tests. Cela réduira considérablement la capacité d'une équipe à compliquer par inadvertance la vie d'une autre équipe.
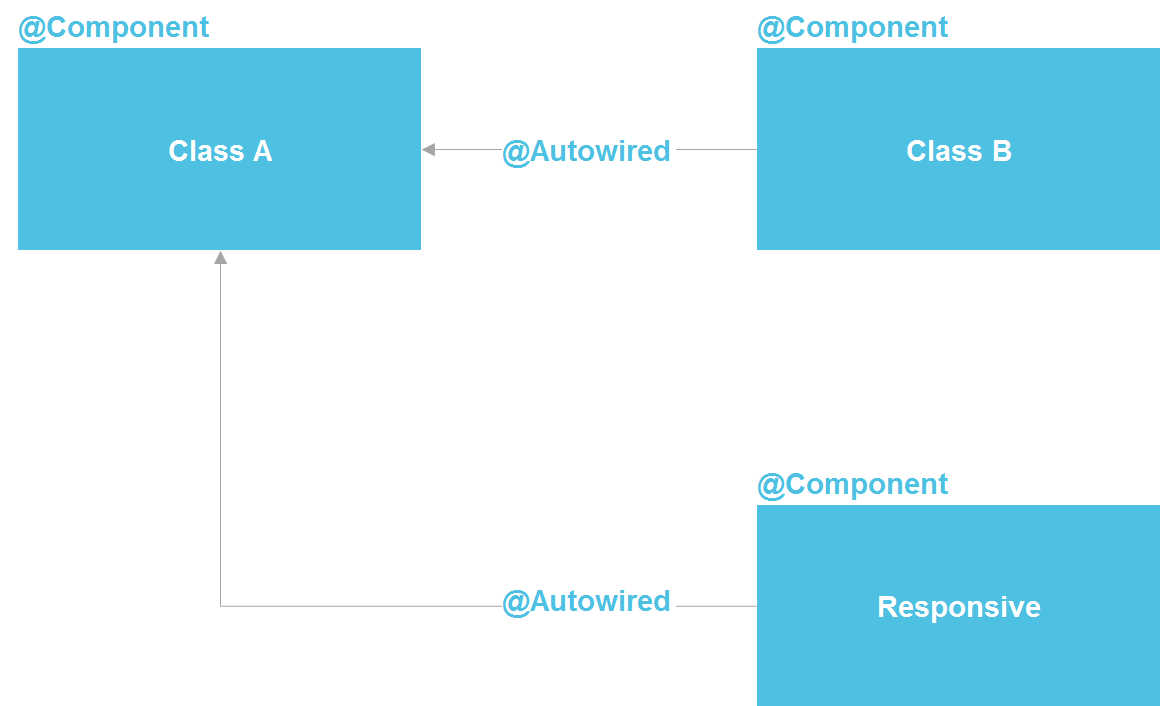
J'ai entendu à plusieurs reprises qu'il est impossible d'isoler les détails de mise en œuvre sans microservices. Mais je peux répondre que toute l'industrie du logiciel consiste à isoler la mise en œuvre. Pour cela, le sous-programme a d'abord été inventé (dans les années 50 du siècle dernier), puis les fonctions, les procédures, les classes et plus tard les microservices. Mais le fait que les microservices de cette série soient apparus en dernier ne fait pas d'eux le point de développement le plus élevé et ne nous oblige pas à toujours recourir à leur aide.
Lors de l'utilisation de microservices, il faut également tenir compte du fait que les appels entre eux prennent un certain temps. Ce n'est souvent pas important, mais j'ai vu un cas où le client devait adapter le temps de réponse du système de 3 secondes. Il s'agissait d'une obligation contractuelle de se connecter à un système tiers. La chaîne d'appels a traversé plusieurs dizaines de microservices atomiques, et le surcoût lié aux appels HTTP n'a pas permis de rétrécir en 3 secondes. En général, vous devez comprendre que toute division de code monolithique en un certain nombre de services affecte inévitablement les performances globales du système. Tout simplement parce que les données ne peuvent pas être téléportées entre les processus et les serveurs "gratuitement".
Quand faut-il des microservices?
Dans quels cas une application monolithique doit-elle vraiment être divisée en plusieurs microservices? Premièrement, lorsqu'il y a une utilisation déséquilibrée des ressources dans les domaines fonctionnels.
Par exemple, nous avons un groupe d'appels d'API qui effectuent des calculs qui nécessitent beaucoup de temps processeur. Et il existe un groupe d'appels API qui sont exécutés très rapidement, mais nécessitent une structure de données encombrante de 64 Go pour être stockés en mémoire. Pour le premier groupe, nous avons besoin d'un groupe de machines avec un total de 32 processeurs, pour le second une machine suffit (OK, qu'il y ait deux machines pour la tolérance de panne) avec 64 Go de mémoire. Si nous avons une application monolithique, nous aurons alors besoin de 64 Go de mémoire sur chaque machine, ce qui augmente le coût de chaque machine. Si ces fonctions sont divisées en deux services distincts, nous pouvons économiser des ressources en optimisant le serveur pour une fonction spécifique. La configuration du serveur peut ressembler à ceci:

Des microservices sont nécessaires et si nous devons sérieusement mettre à l'échelle une zone fonctionnelle étroite. Par exemple, une centaine de méthodes API sont appelées 10 fois par seconde et, disons, quatre méthodes API sont appelées 10 000 fois par seconde. La mise à l'échelle de l'ensemble du système n'est souvent pas nécessaire, c'est-à-dire que nous pouvons bien sûr multiplier les 100 méthodes sur de nombreux serveurs, mais cela est généralement plus coûteux et plus compliqué que la mise à l'échelle d'un groupe restreint de méthodes. Nous pouvons séparer ces quatre appels dans un service distinct et ne l'adapter qu'à un grand nombre de serveurs.
Il est également clair que nous pouvons avoir besoin d'un microservice si nous avons écrit une zone fonctionnelle distincte, par exemple, en Python. Parce que certaines bibliothèques (par exemple, pour Machine Learning) se sont avérées disponibles uniquement en Python, et nous voulons la séparer en un service distinct. Il est également judicieux de créer un microservice si une partie du système est sujette à des défaillances. Bien sûr, il est bon d’écrire du code pour qu’il n’y ait pas d’échec en principe, mais les raisons peuvent être externes. Et personne n'est à l'abri de ses propres erreurs. Dans ce cas, le bogue peut être isolé dans un processus distinct.
Si votre application ne présente aucun des éléments ci-dessus et n'est pas attendue dans un avenir prévisible, il est fort probable qu'une application monolithique vous convienne le mieux. La seule chose - je recommande de l'écrire afin que les zones fonctionnelles qui ne sont pas liées les unes aux autres ne dépendent pas les unes des autres dans le code. De sorte que, si nécessaire, les zones fonctionnelles qui ne sont pas interconnectées peuvent être séparées les unes des autres. Cependant, c'est toujours une bonne recommandation, ce qui augmente la cohérence interne et vous apprend à formuler soigneusement les contrats de module.
Architecture réactive et programmation réactive
Une approche réactive est une chose relativement nouvelle. Le moment de son apparition peut être considéré comme l'année 2014, lorsque
le manifeste réactif a été publié. Deux ans après la publication du manifeste, il était bien connu de tous. Il s'agit d'une approche vraiment révolutionnaire de la conception de systèmes. , , , , .
, . , , : « , !?» , , , , «». , 100% , , .
— , — . .
? , .
- , - . - -, , HTTP-. , . , . , , , .
? , HTTP- , ( callback) ( ) . , - ( , HTTP-) .
— . . . . 3 Ghz , , . . . , Java-, HTTP- — 5-10%. , , , , 100 50 $/ — $500 . , , .
, ? .
, . , , , , , , . , , . .
- . , JDBC ( . ADA, R2DBC, ). 90 % , . — HTTP- , . , .
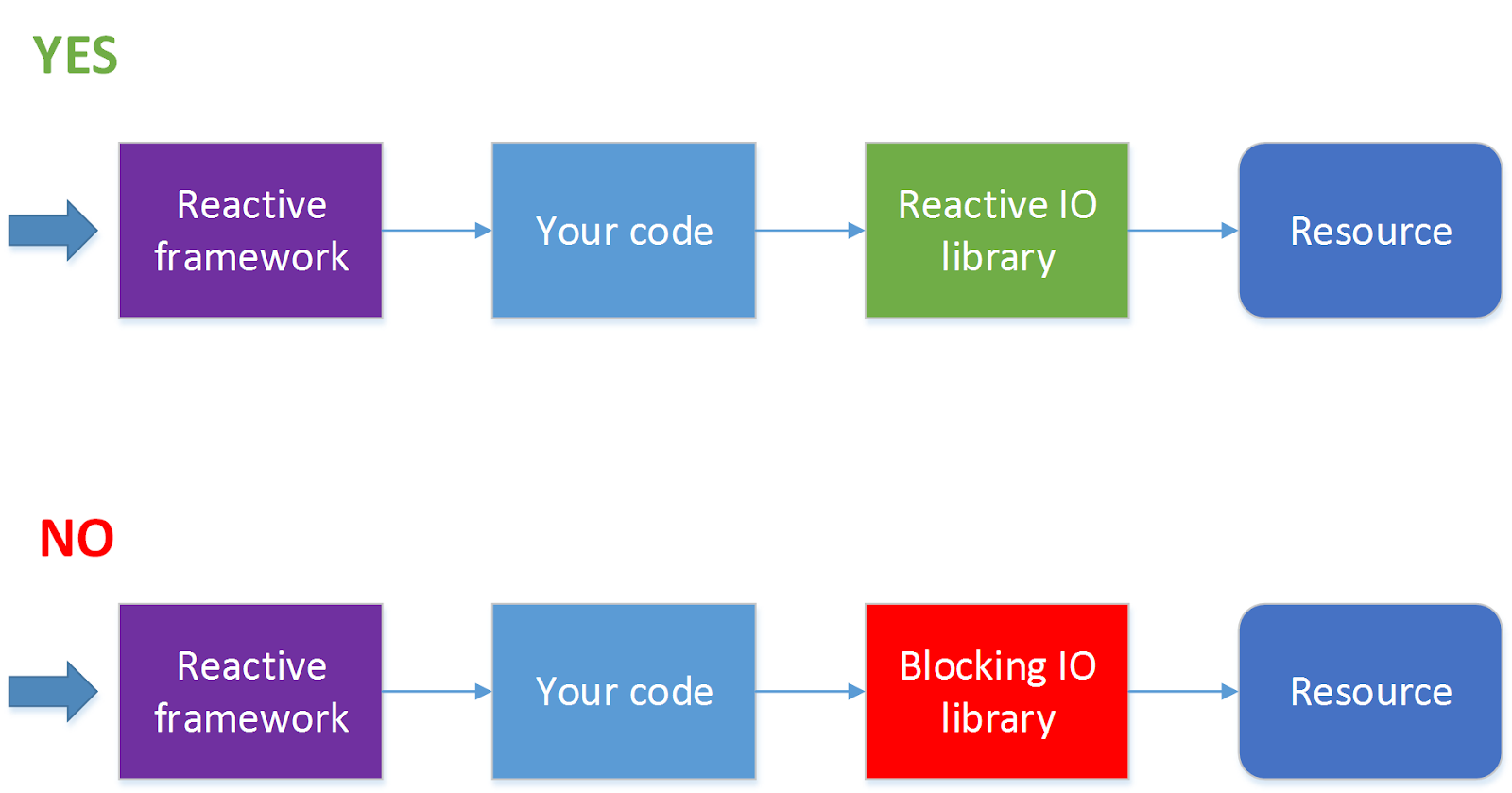
?
, , , ( ) . — - , . , , , HTTP.
, , , , , , .
. , « , » , , , . , , , 10 11 , , , .
Conclusion
, . , , , .