
The Guardian est l'un des plus grands journaux britanniques, il a été fondé en 1821. Pendant près de 200 ans d'existence, les archives ont accumulé une bonne quantité. Heureusement, tout n'est pas stocké sur le site - au cours des deux dernières décennies seulement. La base de données, que les Britanniques ont eux-mêmes qualifiée de "source de vérité" pour tout le contenu en ligne, contient environ 2,3 millions d'éléments. Et à un moment donné, ils ont réalisé la nécessité de migrer de Mongo vers Postgres SQL - après une chaude journée de juillet 2015, les procédures de basculement ont été sévèrement testées. La migration a pris près de 3 ans! ..
Nous avons traduit
un article qui décrit le déroulement du processus de migration et les difficultés rencontrées par les administrateurs. Le processus est long, mais le résumé est simple: passer à la grosse tâche, concilier que des erreurs seront nécessaires. Mais finalement, 3 ans plus tard, des collègues britanniques ont réussi à célébrer la fin de la migration. Et dors.
Première partie: le début
Chez Guardian, la plupart du contenu, y compris les articles, les blogs, les galeries de photos et les vidéos, est produit au sein de notre propre CMS, Composer. Jusqu'à récemment, Composer travaillait avec Mongo DB basé sur AWS. Cette base de données était essentiellement une "source de vérité" pour tout le contenu en ligne du Guardian - environ 2,3 millions d'éléments. Et nous venons de terminer la migration de Mongo vers Postgres SQL.
Composer et ses bases de données étaient initialement hébergés sur le Guardian Cloud, un centre de données situé au sous-sol de notre bureau près de Kings Cross, avec basculement ailleurs à Londres. Par une
chaude journée de juillet 2015, nos procédures de basculement ont été soumises à un test assez sévère.
 Chaleur: bon pour danser à la fontaine, désastreux pour le centre de données. Photo: Sarah Lee / Guardian
Chaleur: bon pour danser à la fontaine, désastreux pour le centre de données. Photo: Sarah Lee / GuardianDepuis lors, la migration de Guardian vers AWS est devenue une question de vie ou de mort. Pour migrer vers le cloud, nous avons décidé d'acheter
OpsManager , le logiciel de gestion Mongo DB, et avons signé un contrat de support technique Mongo. Nous avons utilisé OpsManager pour gérer les sauvegardes, orchestrer et surveiller notre cluster de bases de données.
En raison d'exigences éditoriales, nous devions démarrer le cluster de base de données et OpsManager sur notre propre infrastructure dans AWS, et ne pas utiliser la solution gérée Mongo. Nous avons dû transpirer, car Mongo ne fournissait aucun outil pour une configuration facile sur AWS: nous avons conçu manuellement toute l'infrastructure et écrit des
centaines de scripts Ruby pour installer des agents de surveillance / automatisation et orchestrer de nouvelles instances de base de données. En conséquence, nous avons dû organiser une équipe de programmes éducatifs sur la gestion des bases de données dans l'équipe - ce que nous espérions qu'OpsManager assumerait.
Depuis la transition vers AWS, nous avons eu deux pannes importantes en raison de problèmes de base de données, chacune n'ayant pas permis la publication sur theguardian.com pendant au moins une heure. Dans les deux cas, ni OpsManager ni le personnel de support technique de Mongo n'ont pu nous fournir une assistance suffisante, et nous avons résolu le problème nous-mêmes - dans un cas, grâce à un
membre de notre équipe qui a réussi à faire face à la situation par téléphone depuis le désert à la périphérie d'Abu Dhabi.
Chacune des questions problématiques mérite un article séparé, mais voici les points généraux:
- Faites très attention au temps - ne bloquez pas l'accès à votre VPC à un point tel que NTP cesse de fonctionner.
- La création automatique d'index de base de données au démarrage de l'application est une mauvaise idée.
- La gestion des bases de données est extrêmement importante et difficile - et nous ne voudrions pas le faire nous-mêmes.
OpsManager n'a pas tenu sa promesse d'une gestion simple des bases de données. Par exemple, la gestion réelle d'OpsManager elle-même - en particulier, la mise à jour d'OpsManager version 1 vers la version 2 - a nécessité beaucoup de temps et des connaissances particulières sur notre configuration OpsManager. Il n'a pas non plus tenu sa promesse de «mises à jour en un clic» en raison de changements dans le schéma d'authentification entre les différentes versions de Mongo DB. Nous avons perdu au moins deux mois d'ingénieurs par an pour gérer la base de données.
Tous ces problèmes, combinés aux frais annuels importants que nous avons payés pour le contrat de support et OpsManager, nous ont obligés à rechercher une option de base de données alternative avec les caractéristiques suivantes:
- Effort minimal pour gérer la base de données.
- Chiffrement au repos.
- Un chemin de migration acceptable avec Mongo.
Étant donné que tous nos autres services exécutent AWS, le choix évident est Dynamo, la base de données NoSQL d'Amazon. Malheureusement, à l'époque, Dynamo ne prenait pas en charge le chiffrement au repos. Après avoir attendu environ neuf mois pour que cette fonctionnalité soit ajoutée, nous avons fini par abandonner cette idée en décidant d'utiliser Postgres sur AWS RDS.
"Mais Postgres n'est pas un référentiel de documents!" - vous êtes indigné ... Eh bien, oui, ce n'est pas un dépôt Dock, mais il a des tables similaires aux colonnes JSONB, avec un support pour les index dans les champs de l'outil JSON Blob. Nous espérions qu'avec JSONB, nous pourrions migrer de Mongo vers Postgres avec des changements minimes dans notre modèle de données. De plus, si nous voulions passer à un modèle plus relationnel à l'avenir, nous aurions une telle opportunité. Une autre grande chose à propos de Postgres est son bon fonctionnement: pour chaque question que nous avions, dans la plupart des cas, la réponse était déjà donnée dans Stack Overflow.
En termes de performances, nous étions sûrs que Postgres pouvait le faire: Composer est un outil exclusivement pour l'enregistrement de contenu (il écrit dans la base de données chaque fois qu'un journaliste arrête d'imprimer), et généralement le nombre d'utilisateurs simultanés ne dépasse pas plusieurs centaines - ce qui ne nécessite pas de système super haute puissance!
Deuxième partie: la migration de contenu de deux décennies s'est déroulée sans interruption
PlanLa plupart des migrations de bases de données impliquent les mêmes actions, et la nôtre ne fait pas exception. Voici ce que nous avons fait:
- Création d'une nouvelle base de données.
- Ils ont créé un moyen d'écrire dans une nouvelle base de données (nouvelle API).
- Nous avons créé un serveur proxy qui envoie du trafic à la fois à l'ancienne et à la nouvelle base de données, en utilisant l'ancienne comme principale.
- Enregistrements déplacés de l'ancienne base de données vers la nouvelle.
- Ils ont fait de la nouvelle base de données la principale.
- Suppression de l'ancienne base de données.
Étant donné que la base de données vers laquelle nous avons migré assurait le fonctionnement de notre CMS, il était essentiel que la migration cause le moins de problèmes possible à nos journalistes. En fin de compte, les nouvelles ne finissent jamais.
Nouvelle APILes travaux sur la nouvelle API basée sur Postgres ont commencé fin juillet 2017. Ce fut le début de notre voyage. Mais pour comprendre comment c'était, nous devons d'abord clarifier où nous avons commencé.
Notre architecture CMS simplifiée ressemblait à ceci: une base de données, une API et plusieurs applications qui y sont liées (comme une interface utilisateur). La pile a été construite et fonctionne depuis 4 ans sur la base de
Scala ,
Scalatra Framework et
Angular.js .
Après quelques analyses, nous sommes arrivés à la conclusion qu'avant de pouvoir migrer le contenu existant, nous avons besoin d'un moyen de contacter la nouvelle base de données PostgreSQL, en maintenant l'ancienne API opérationnelle. Après tout, Mongo DB est notre «source de vérité». Elle nous a servi de bouée de sauvetage pendant que nous expérimentions la nouvelle API.
C'est l'une des raisons pour lesquelles la construction au-dessus de l'ancienne API ne faisait pas partie de nos plans. La séparation des fonctions dans l'API d'origine était minime, et les méthodes spécifiques nécessaires pour travailler spécifiquement avec Mongo DB pouvaient être trouvées même au niveau du contrôleur. En conséquence, la tâche d'ajouter un autre type de base de données à une API existante était trop risquée.
Nous sommes allés dans l'autre sens et avons dupliqué l'ancienne API. Ainsi naquit APIV2. C'était une copie plus ou moins exacte de l'ancienne API liée à Mongo, et comprenait les mêmes points de terminaison et fonctionnalités. Nous avons utilisé
doobie , la couche de fonctionnalités JDBC pure pour Scala, ajouté
Docker pour exécuter et tester localement, et amélioré la journalisation des opérations et le partage des responsabilités. APIV2 était censé être une version rapide et moderne de l'API.
Fin août 2017, nous avions déployé une nouvelle API utilisant PostgreSQL comme base de données. Mais ce n'était que le début. Il y a des articles dans Mongo DB qui ont été créés il y a plus de deux décennies, et ils ont tous dû migrer vers la base de données Postgres.
La migrationNous devrions être en mesure de modifier n'importe quel article sur le site, quel que soit le moment où il a été publié. Par conséquent, tous les articles existent dans notre base de données en tant que «source de vérité» unique.
Bien que tous les articles vivent dans l'
API Content Guardian (CAPI) , qui sert les applications et le site, il était extrêmement important pour nous de migrer sans aucun problème, car notre base de données est notre «source de vérité». Si quelque chose arrivait au cluster Elasticsearch CAPI, nous le réindexions à partir de la base de données Composer.
Par conséquent, avant de désactiver Mongo, nous devions nous assurer que la même demande pour l'API exécutée sur Postgres et l'API exécutée sur Mongo renverrait des réponses identiques.
Pour ce faire, nous devions copier tout le contenu dans la nouvelle base de données Postgres. Cela a été fait à l'aide d'un script qui interagissait directement avec l'ancienne et la nouvelle API. L'avantage de cette méthode était que les deux API fournissaient déjà une interface bien testée pour lire et écrire des articles dans et hors des bases de données, par opposition à écrire quelque chose qui accédait directement aux bases de données respectives.
L'ordre de migration de base était le suivant:
- Obtenez du contenu de Mongo.
- Publiez du contenu sur Postgres.
- Obtenez du contenu de Postgres.
- Assurez-vous que leurs réponses sont identiques.
La migration de base de données ne peut être considérée comme réussie que si les utilisateurs finaux n'ont pas remarqué que cela s'est produit, et un bon script de migration sera toujours la clé d'un tel succès. Nous avions besoin d'un script qui pourrait:
- Exécutez les requêtes HTTP.
- Assurez-vous qu'après la migration d'une partie du contenu, la réponse des deux API correspond.
- Arrêtez en cas d'erreur.
- Créez un journal des opérations détaillé pour diagnostiquer les problèmes.
- Redémarrez après une erreur du point correct.
Nous avons commencé par utiliser de l'
ammonite . Il vous permet d'écrire des scripts dans le langage Scala, qui est au cœur de notre équipe. C'était une bonne occasion d'expérimenter avec quelque chose que nous n'avions pas utilisé auparavant pour voir si cela nous serait utile. Bien que l'ammonite nous permette d'utiliser un langage familier, nous avons constaté plusieurs lacunes dans son travail. Intellij
prend actuellement en
charge Ammonite, mais il ne l'a pas fait lors de notre migration - et nous avons perdu l'auto-complétion et l'importation automatique. De plus, pendant une longue période, le script Ammonite n'a pas pu s'exécuter.
En fin de compte, Ammonite n'était pas le bon outil pour ce travail, et nous avons plutôt utilisé le projet sbt pour effectuer la migration. Cela nous a permis de travailler dans une langue dans laquelle nous avions confiance, ainsi que d'effectuer plusieurs «migrations de test» avant de se lancer dans l'environnement de travail principal.
L'inattendu était son utilité pour vérifier la version de l'API exécutée sur Postgres. Nous avons trouvé plusieurs erreurs difficiles à trouver et des cas limites que nous n'avons pas trouvés plus tôt.
Avance rapide jusqu'en janvier 2018, quand il est temps de tester la migration complète dans notre environnement CODE pré-prod.
Comme la plupart de nos systèmes, la seule similitude entre CODE et PROD est la version de l'application lancée. L'infrastructure AWS prenant en charge CODE était beaucoup moins puissante que PROD, tout simplement parce qu'elle reçoit beaucoup moins de charge de travail.
Nous espérions que la migration de test dans l'environnement CODE nous aiderait à:
- Estimez la durée de la migration dans l'environnement PROD.
- Évaluez comment (le cas échéant) la migration affecte la productivité.
Afin d'obtenir des mesures précises de ces indicateurs, nous avons dû mettre les deux environnements en correspondance mutuelle complète. Cela comprenait la restauration d'une sauvegarde Mongo DB de PROD vers CODE et la mise à niveau de l'infrastructure prise en charge par AWS.
La migration d'un peu plus de 2 millions d'éléments de données aurait dû prendre beaucoup plus de temps qu'une journée de travail standard ne le permettrait. Par conséquent, nous avons exécuté le script à l'
écran pour la nuit.
Pour mesurer la progression de la migration, nous avons envoyé des requêtes structurées (à l'aide de jetons) à notre pile ELK (Elasticsearch, Logstash et Kibana). À partir de là, nous pourrions créer des tableaux de bord détaillés en suivant le nombre d'articles transférés avec succès, le nombre de plantages et la progression globale. De plus, tous les indicateurs étaient affichés sur grand écran afin que toute l'équipe puisse voir les détails.
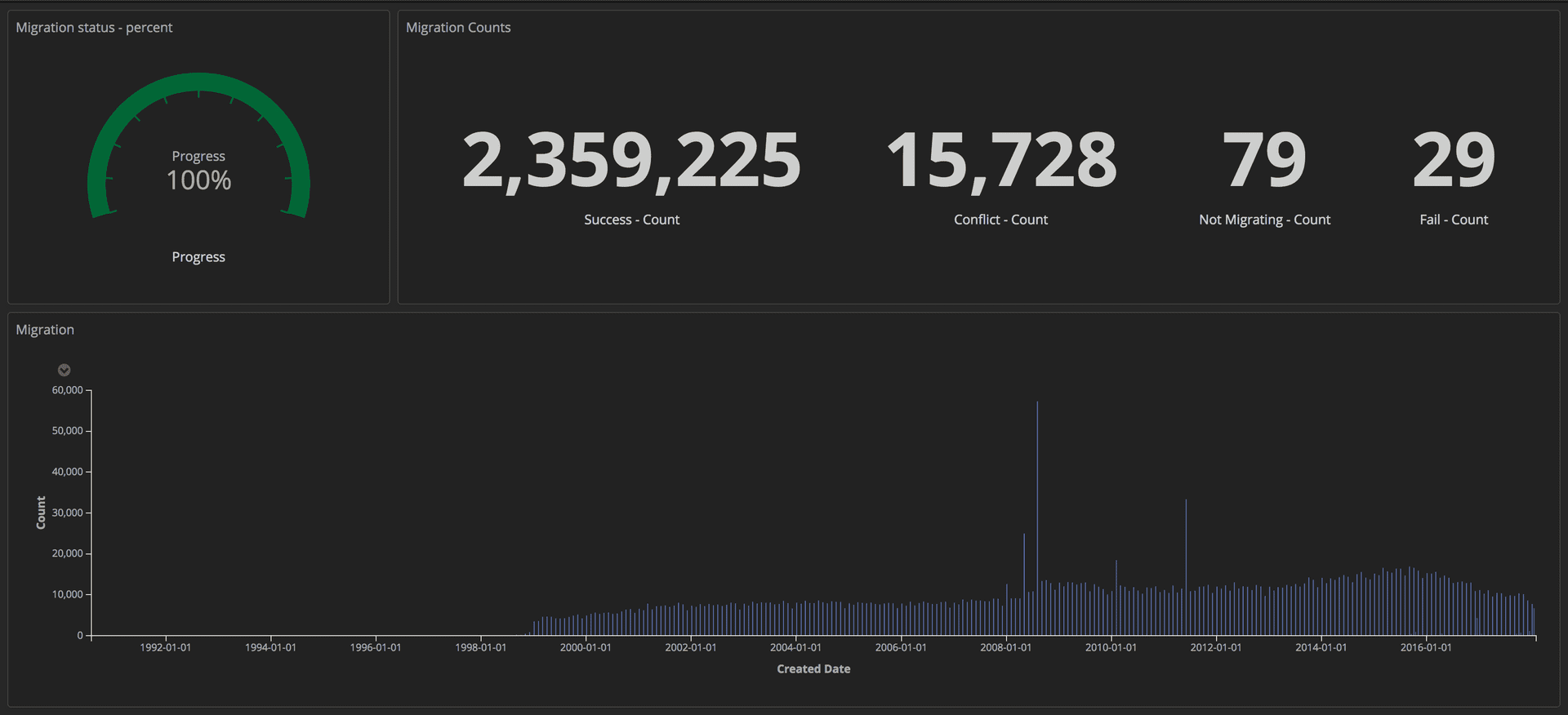 Tableau de bord montrant la progression de la migration: Outils éditoriaux / Guardian
Tableau de bord montrant la progression de la migration: Outils éditoriaux / GuardianUne fois la migration terminée, nous avons vérifié une correspondance pour chaque document dans Postgres et dans Mongo.
Troisième partie: procurations et lancement sur Prod
ProcurationsMaintenant que la nouvelle API fonctionnant sur Postgres a été lancée, nous devions la tester avec des modèles de trafic et d'accès aux données réels pour garantir sa fiabilité et sa stabilité. Il y avait deux façons possibles de procéder: mettre à jour chaque client qui accède à l'API Mongo pour qu'il accède aux deux API; ou exécutez un proxy qui le fera pour nous. Nous avons écrit des procurations sur Scala en utilisant
Akka Streams .
Le proxy était assez simple:
- Recevez le trafic de l'équilibreur de charge.
- Redirigez le trafic vers l'API principale et vice versa.
- Transférez le même trafic de manière asynchrone vers une API supplémentaire.
- Calculez les écarts entre les deux réponses et enregistrez-les dans un journal.
Initialement, le proxy a enregistré de nombreuses divergences, y compris certaines différences de comportement difficiles à trouver mais importantes dans les deux API qui devaient être corrigées.
Journalisation structuréeChez Guardian, nous nous
connectons à l'aide de la pile
ELK (Elasticsearch, Logstash et Kibana). L'utilisation de Kibana nous a permis de visualiser le magazine de la manière la plus pratique pour nous. Kibana utilise
la syntaxe de requête de Lucene , qui est assez facile à apprendre. Mais nous nous sommes vite rendu compte qu'il était impossible de filtrer ou de regrouper les entrées de journal dans la configuration actuelle. Par exemple, nous n'avons pas pu filtrer ceux qui ont été envoyés à la suite de demandes GET.
Nous avons décidé d'envoyer des données plus structurées à Kibana, pas seulement des messages. Une entrée de journal contient plusieurs champs, par exemple, l'horodatage et le nom de la pile ou de l'application qui a envoyé la demande. L'ajout de nouveaux champs est très simple. Ces champs structurés sont appelés marqueurs et peuvent être implémentés à l'aide de la
bibliothèque logstash-logback-encoder . Pour chaque demande, nous avons extrait des informations utiles (par exemple, itinéraire, méthode, code d'état) et créé une carte avec les informations supplémentaires nécessaires pour le journal. Voici un exemple:
import akka.http.scaladsl.model.HttpRequest import ch.qos.logback.classic.{Logger => LogbackLogger} import net.logstash.logback.marker.Markers import org.slf4j.{LoggerFactory, Logger => SLFLogger} import scala.collection.JavaConverters._ object Logging { val rootLogger: LogbackLogger = LoggerFactory.getLogger(SLFLogger.ROOT_LOGGER_NAME).asInstanceOf[LogbackLogger] private def setMarkers(request: HttpRequest) = { val markers = Map( "path" -> request.uri.path.toString(), "method" -> request.method.value ) Markers.appendEntries(markers.asJava) } def infoWithMarkers(message: String, akkaRequest: HttpRequest) = rootLogger.info(setMarkers(akkaRequest), message) }
Des champs supplémentaires dans nos journaux nous ont permis de créer des tableaux de bord informatifs et d'ajouter plus de contexte aux écarts, ce qui nous a aidés à identifier quelques incohérences mineures entre les deux API.
Réplication du trafic et refactoring du proxyAprès avoir transféré le contenu dans la base de données CODE, nous avons obtenu une copie presque exacte de la base de données PROD. La principale différence était que CODE n'avait pas de trafic. Pour répliquer le trafic réel vers l'environnement CODE, nous avons utilisé l'outil open source
GoReplay (ci
- après
dénommé gor). Il est très facile à installer et flexible à personnaliser selon vos besoins.
Étant donné que tout le trafic provenant de nos API est d'abord allé vers des proxy, il était logique d'installer gor sur des conteneurs proxy. Voir ci-dessous comment charger gor dans votre conteneur et comment commencer à surveiller le trafic sur le port 80 et à l'envoyer à un autre serveur.
wget https://github.com/buger/goreplay/releases/download/v0.16.0.2/gor_0.16.0_x64.tar.gz tar -xzf gor_0.16.0_x64.tar.gz gor sudo gor --input-raw :80 --output-http http://apiv2.code.co.uk
Pendant un moment, tout a bien fonctionné, mais très vite il y a eu un dysfonctionnement lorsque le proxy est devenu indisponible pendant plusieurs minutes. Dans l'analyse, nous avons constaté que les trois conteneurs proxy se bloquaient périodiquement en même temps. Au début, nous pensions que le proxy plantait parce que gor utilisait trop de ressources. Après une analyse plus approfondie de la console AWS, nous avons constaté que les conteneurs proxy se bloquaient régulièrement, mais pas en même temps.
Avant d'approfondir le problème, nous avons essayé de trouver un moyen d'exécuter gor, mais cette fois sans charge supplémentaire sur le proxy. La solution est venue de notre pile secondaire pour Composer. Cette pile n'est utilisée qu'en cas d'urgence, et notre
outil de surveillance de travail la teste en permanence. Cette fois, la lecture du trafic de cette pile vers CODE à double vitesse a fonctionné sans aucun problème.
De nouveaux résultats ont soulevé de nombreuses questions. Le proxy a été conçu comme un outil temporaire, il se peut donc qu'il n'ait pas été conçu avec autant de soin que d'autres applications. De plus, il a été construit en utilisant
Akka Http , qu'aucune de nos équipes ne connaissait. Le code était désordonné et plein de correctifs rapides. Nous avons décidé de commencer beaucoup de refactoring pour améliorer la lisibilité. Cette fois, nous avons utilisé des générateurs pour au lieu de la logique imbriquée croissante que nous utilisions auparavant. Et ajouté encore plus de marqueurs de journalisation.
Nous espérions pouvoir empêcher le gel des conteneurs proxy si nous approfondissons ce qui se passe à l'intérieur du système et simplifions la logique de son fonctionnement. Mais cela n'a pas fonctionné. Après deux semaines à essayer de rendre le proxy plus fiable, nous nous sommes sentis piégés. Il fallait prendre une décision. Nous avons décidé de prendre le risque et de laisser le proxy tel quel, car il vaut mieux passer du temps sur la migration elle-même que d'essayer de réparer un logiciel qui deviendra inutile dans un mois. Nous avons payé pour cette solution avec deux autres échecs - presque deux minutes chacun - mais cela devait être fait.
Avance rapide jusqu'en mars 2018, lorsque nous avons déjà terminé la migration vers CODE sans sacrifier les performances de l'API ou l'expérience client dans CMS. Maintenant, nous pourrions commencer à penser à annuler les procurations de CODE.
La première étape a été de modifier les priorités de l'API afin que le proxy interagisse d'abord avec Postgres. Comme nous l'avons dit plus haut, cela a été décidé par une modification des paramètres. Cependant, il y avait une difficulté.
Composer envoie des messages au flux Kinesis après la mise à jour du document. Une seule API nécessaire pour envoyer des messages pour éviter la duplication. Pour cela, les API ont un indicateur dans la configuration: true pour l'API prise en charge par Mongo et false pour les Postgres pris en charge. Changer simplement le proxy pour interagir avec Postgres en premier n'était pas suffisant, car le message ne serait pas envoyé au flux Kinesis avant que la demande n'atteigne Mongo. Cela fait trop longtemps.
Pour résoudre ce problème, nous avons créé des points de terminaison HTTP pour modifier instantanément la configuration de toutes les instances de l'équilibreur de charge à la volée. Cela nous a permis de connecter l'API principale très rapidement sans avoir à modifier le fichier de configuration et à le redéployer. De plus, cela peut être automatisé, réduisant ainsi l'interaction humaine et la probabilité d'erreurs.
Maintenant, toutes les demandes ont d'abord été envoyées à Postgres et API2 a interagi avec Kinesis. Les remplacements pourraient être rendus permanents avec des changements de configuration et un redéploiement.
L'étape suivante consistait à supprimer complètement le proxy et à forcer les clients à accéder exclusivement à l'API Postgres. Comme nous avons de nombreux clients, la mise à jour de chacun d'eux n'était pas possible. Par conséquent, nous avons élevé cette tâche au niveau du DNS. Autrement dit, nous avons créé un CNAME dans DNS qui pointait d'abord vers le proxy ELB et changerait pour pointer vers l'API ELB. Cela a permis une seule modification au lieu de mettre à jour chaque client API individuel.
Il est temps de déplacer le PROD. Même si c'était un peu effrayant, eh bien, parce que c'est le principal environnement de travail. Le processus a été relativement simple, car tout a été décidé en modifiant les paramètres. De plus, comme un marqueur d'étape a été ajouté aux journaux, il est devenu possible de re-profiler les tableaux de bord précédemment construits en mettant simplement à jour le filtre Kibana.
Désactiver les proxys et Mongo DBAprès 10 mois et 2,4 millions d'articles migrés, nous avons enfin pu désactiver toutes les infrastructures liées à Mongo. Mais d'abord, nous devions faire ce que nous attendions tous: tuer le proxy.
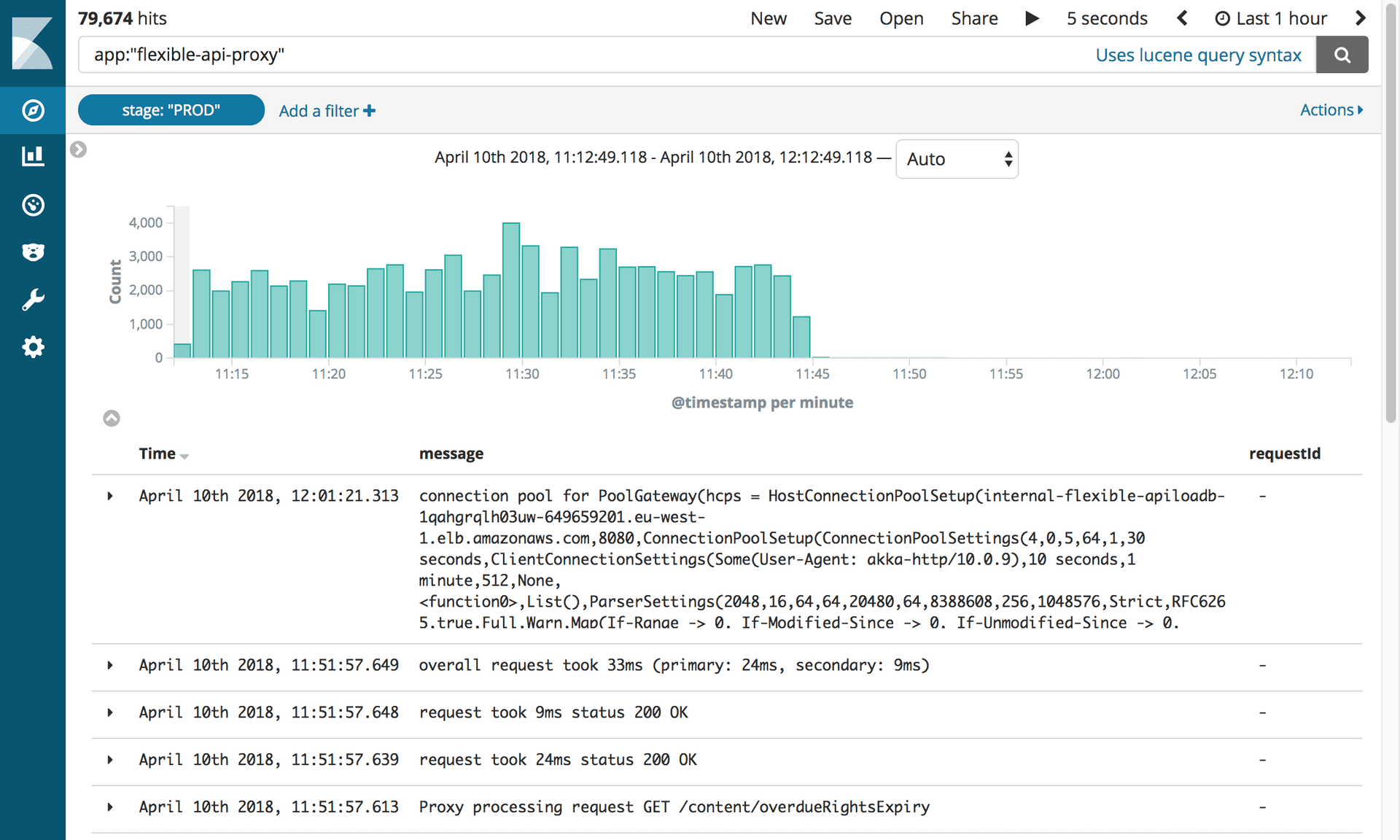 Journaux montrant la désactivation du proxy API flexible. Photographie: Outils éditoriaux / Guardian
Journaux montrant la désactivation du proxy API flexible. Photographie: Outils éditoriaux / GuardianCe petit logiciel nous a causé tellement de problèmes que nous avons eu hâte de le déconnecter bientôt! Tout ce que nous avions à faire était de mettre à jour l'enregistrement CNAME pour pointer directement vers l'équilibreur de charge APIV2.
Toute l'équipe s'est réunie autour d'un ordinateur. Il fallait faire une seule frappe. Tout le monde a retenu son souffle! Silence complet ... Cliquez! Le travail est terminé. Et rien n'a volé! Nous avons tous exhalé joyeusement.
Cependant, la suppression de l'ancienne API Mongo DB était lourde d'un autre test. Désespéré de supprimer l'ancien code, nous avons constaté que nos tests d'intégration n'ont jamais été ajustés pour utiliser la nouvelle API. Tout est rapidement devenu rouge. Heureusement, la plupart des problèmes étaient liés à la configuration et nous les avons facilement résolus. Il y a eu plusieurs problèmes avec les requêtes PostgreSQL qui ont été détectés par les tests. En réfléchissant à ce qui pourrait être fait pour éviter cette erreur, nous avons appris une leçon: lors du démarrage d'une grosse tâche, conciliez qu'il y aura des erreurs.
Après cela, tout s'est bien passé. Nous avons déconnecté toutes les instances de Mongo d'OpsManager, puis les avons déconnectées. Il ne restait plus qu'à célébrer. Et dors.