Je suis un Lead DevOps Engineer chez Miro (ex-RealtimeBoard). Je partagerai comment notre équipe DevOps a résolu le problème des versions quotidiennes du serveur d'une application monolithique avec état et les a rendues automatiques, invisibles pour les utilisateurs et pratiques pour leurs propres développeurs.
Notre infrastructure
Notre équipe de développement est composée de 60 personnes réparties en équipes Scrum, parmi lesquelles se trouve également l'équipe DevOps. La plupart des commandes Scrum prennent en charge les fonctionnalités actuelles du produit et proposent de nouvelles fonctionnalités. La tâche de DevOps est de créer et de maintenir une infrastructure qui aide l'application à fonctionner rapidement et de manière fiable et permet aux équipes de fournir rapidement de nouvelles fonctionnalités aux utilisateurs.

Notre application est une carte en ligne sans fin. Il se compose de trois couches: un site, un client et un serveur en Java, qui est une application monolithique avec état. L'application conserve une connexion socket Web constante avec les clients et chaque serveur conserve en mémoire un cache de cartes ouvertes.
L'ensemble de l'infrastructure - plus de 70 serveurs - est situé sur Amazon: plus de 30 serveurs avec notre application Java, serveurs Web, serveurs de base de données, courtiers et bien plus encore. Avec la croissance des fonctionnalités, tout cela doit être mis à jour régulièrement, sans déranger les utilisateurs.
La mise à jour du site et du client est simple: nous remplaçons l'ancienne version par une nouvelle, et la prochaine fois que l'utilisateur accède à un nouveau site et à un nouveau client. Mais si nous le faisons lorsque le serveur est libéré, nous obtenons des temps d'arrêt. Pour nous, cela est inacceptable, car la valeur principale de notre produit est le travail conjoint des utilisateurs en temps réel.
À quoi ressemble notre processus CI / CD
Le processus CI / CD avec nous est git commit, git push, puis assemblage automatique, auto-test, déploiement, libération et surveillance.
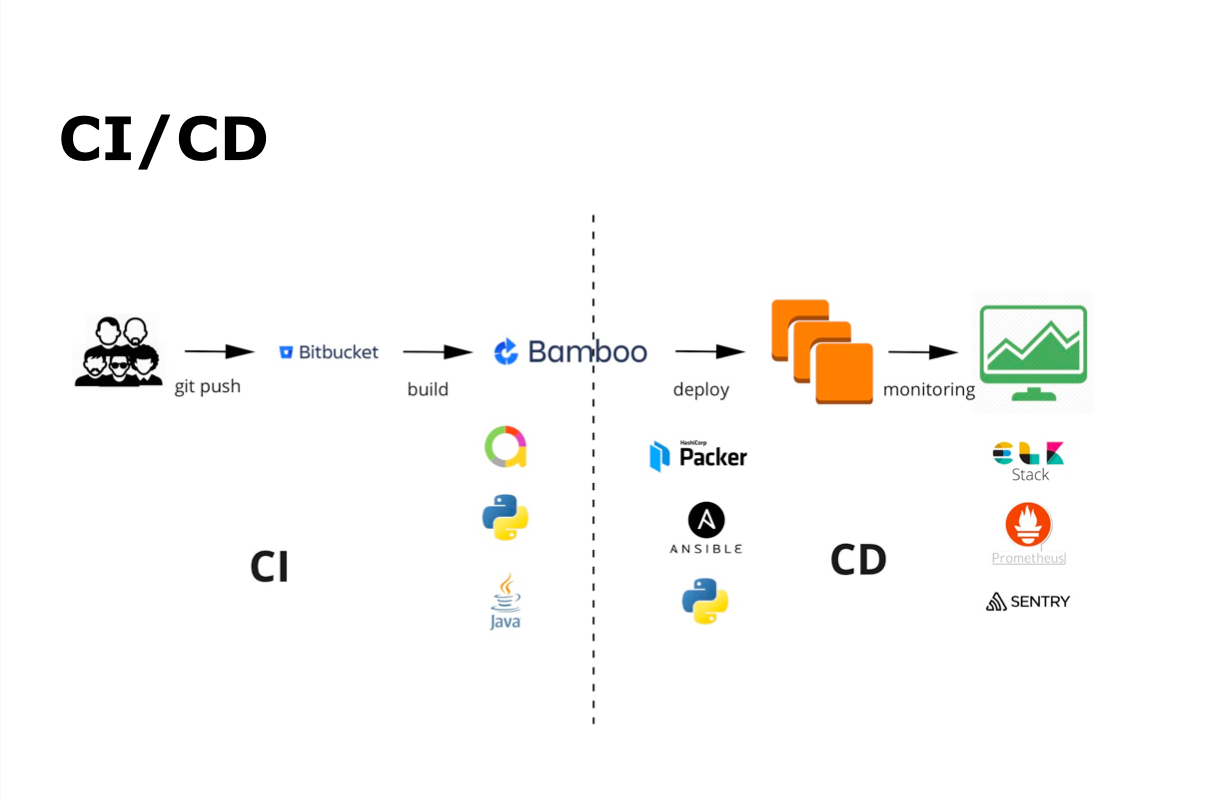
Pour une intégration continue, nous utilisons Bamboo et Bitbucket. Pour les tests automatiques - Java et Python et Allure - pour afficher les résultats des tests automatiques. Pour une livraison continue - Packer, Ansible et Python. Tous les contrôles sont effectués à l'aide d'ELK Stack, Prometheus et Sentry.
Les développeurs écrivent du code, l'ajoutent au référentiel, après quoi l'assemblage automatique et les tests automatiques sont lancés. Dans le même temps, à l'intérieur de l'équipe, elle rassemble les autres développeurs et effectue la révision du code. Lorsque tous les processus requis, y compris les autotests, sont terminés, l'équipe conserve la génération dans la branche principale, et la génération de la construction de la branche principale commence et est envoyée pour des tests automatiques. L'ensemble du processus est débogué et exécuté par l'équipe seule.
Image AMI
Parallèlement à la génération de build et aux tests, la construction de l'image AMI pour Amazon démarre. Pour ce faire, nous utilisons Packer de HashiCorp, un excellent outil open source qui vous permet de créer une image d'une machine virtuelle. Tous les paramètres sont transmis à JSON avec un ensemble de clés de configuration. Le paramètre principal est les constructeurs, qui indiquent pour quel fournisseur nous créons l'image (dans notre cas, pour Amazon).
"builders": [{ "type": "amazon-ebs", "access_key": "{{user `aws_access_key`}}", "secret_key": "{{user `aws_secret_key`}}", "region": "{{user `aws_region`}}", "vpc_id": "{{user `aws_vpc`}}", "subnet_id": "{{user `aws_subnet`}}", "tags": { "releaseVersion": "{{user `release_version`}}" }, "instance_type": "t2.micro", "ssh_username": "ubuntu", "ami_name": "packer-board-ami_{{isotime \"2006-01-02_15-04\"}}" }],
Il est important non seulement de créer une image d'une machine virtuelle, mais de la configurer à l'avance à l'aide d'Ansible: installez les packages nécessaires et définissez les paramètres de configuration pour exécuter une application Java.
"provisioners": [{ "type": "ansible", "playbook_file": "./playbook.yml", "user": "ubuntu", "host_alias": "default", "extra_arguments": ["--extra_vars=vars"], "ansible_env_vars": ["ANSIBLE_HOST_KEY_CHECKING=False", "ANSIBLE_NOCOLOR=True"] }]
Ansible-roles
Nous avions l'habitude d'utiliser le playbook Ansible habituel, mais cela a conduit à beaucoup de code répétitif, qui est devenu difficile à tenir à jour. Nous avons changé quelque chose dans un playbook, oublié de le faire dans un autre, et en conséquence nous avons rencontré des problèmes. Nous avons donc commencé à utiliser des rôles Ansible. Nous les avons rendus aussi polyvalents que possible afin de pouvoir les réutiliser dans différentes parties du projet et ne pas surcharger le code en gros morceaux répétitifs. Par exemple, nous utilisons le rôle de surveillance pour tous les types de serveurs.
- name: Install all board dependencies hosts: all user: ubuntu become: yes roles: - java - nginx - board-application - ssl-certificates - monitoring
Du côté des équipes Scrum, ce processus semble aussi simple que possible: l'équipe reçoit des notifications dans Slack que la construction et l'image AMI sont assemblées.
Pré-versions
Nous avons introduit des versions préliminaires pour apporter les modifications de produit aux utilisateurs le plus rapidement possible. En fait, ce sont des versions canaries qui vous permettent de tester en toute sécurité de nouvelles fonctionnalités sur un petit pourcentage d'utilisateurs.
Pourquoi les versions s'appellent-elles canaries? Auparavant, les mineurs, lorsqu'ils sont descendus dans la mine, ont pris un canari avec eux. S'il y avait du gaz dans la mine, le canari est mort et les mineurs sont rapidement remontés à la surface. Il en va de même pour nous: si quelque chose ne va pas avec le serveur, la version n'est pas prête et nous pouvons rapidement revenir en arrière et la plupart des utilisateurs ne remarqueront rien.
Comment commence la libération des canaris:- L'équipe de développement de Bamboo clique sur un bouton -> une application Python est appelée qui lance la pré-version.
- Il crée une nouvelle instance dans Amazon à partir d'une image AMI pré-préparée avec une nouvelle version de l'application.
- L'instance est ajoutée aux groupes cibles et aux équilibreurs de charge nécessaires.
- Avec Ansible, une configuration individuelle est configurée pour chaque instance.
- Les utilisateurs travaillent avec la nouvelle version de l'application Java.
Du côté des commandes Scrum, le processus de lancement pré-version semble à nouveau aussi simple que possible: l'équipe reçoit des notifications dans Slack que le processus a commencé, et après 7 minutes, le nouveau serveur est déjà en fonctionnement. De plus, l'application envoie à Slack l'intégralité du journal des modifications de la version.
Pour que cette barrière de protection et de vérification de la fiabilité fonctionne, les équipes Scrum surveillent les nouvelles erreurs dans Sentry. Il s'agit d'une application open source de suivi des bogues en temps réel. Sentry s'intègre parfaitement avec Java et dispose de connecteurs avec logback et log2j. Lorsque l'application démarre, nous transférons à Sentry la version sur laquelle elle s'exécute et lorsqu'une erreur se produit, nous voyons dans quelle version de l'application elle s'est produite. Cela aide les équipes Scrum à réagir rapidement aux erreurs et à les corriger rapidement.
La pré-version devrait fonctionner pendant au moins 4 heures. Pendant ce temps, l'équipe surveille son travail et décide de diffuser la version à tous les utilisateurs.
Plusieurs équipes peuvent libérer simultanément leurs sorties . Pour ce faire, ils conviennent entre eux de ce qui entre dans la pré-version et qui est responsable de la version finale. Après cela, les équipes combinent toutes les modifications en une seule pré-version ou lancent plusieurs pré-versions en même temps. Si toutes les versions préliminaires sont correctes, elles seront publiées en une seule version le lendemain.
Communiqués
Nous faisons une sortie quotidienne:
- Nous introduisons de nouveaux serveurs pour travailler.
- Nous surveillons l'activité des utilisateurs sur de nouveaux serveurs à l'aide de Prometheus.
- Fermer l'accès des nouveaux utilisateurs aux anciens serveurs.
- Nous transférons les utilisateurs d'anciens serveurs vers de nouveaux.
- Éteignez l'ancien serveur.
Tout est construit à l'aide des applications Bamboo et Python. L'application vérifie le nombre de serveurs en cours d'exécution et se prépare à lancer le même nombre de nouveaux serveurs. S'il n'y a pas suffisamment de serveurs, ils sont créés à partir de l'image AMI. Une nouvelle version y est déployée, une application Java est lancée et les serveurs sont mis en service.
Lors de la surveillance, l'application Python utilisant l'API Prometheus vérifie le nombre de cartes ouvertes sur les nouveaux serveurs. Lorsqu'il comprend que tout fonctionne correctement, il ferme l'accès aux anciens serveurs et transfère les utilisateurs aux nouveaux.
import requests PROMETHEUS_URL = 'https://prometheus' def get_spaces_count(): boards = {} try: params = { 'query': 'rtb_spaces_count{instance=~"board.*"}' } response = requests.get(PROMETHEUS_URL, params=params) for metric in response.json()['data']['result']: boards[metric['metric']['instance']] = metric['value'][1] except requests.exceptions.RequestException as e: print('requests.exceptions.RequestException: {}'.format(e)) finally: return boards
Le processus de transfert d'utilisateurs entre les serveurs est affiché dans Grafana. Dans la moitié gauche du graphique, les serveurs fonctionnant sur l'ancienne version sont affichés, à droite - sur la nouvelle. L'intersection des graphiques est le moment du transfert de l'utilisateur.

L'équipe supervise la sortie de Slack. Après la publication, l'intégralité du journal des modifications est publiée dans un canal distinct dans Slack et dans Jira, toutes les tâches associées à cette version sont automatiquement fermées.
Qu'est-ce que la migration des utilisateurs
Nous stockons l'état du tableau blanc sur lequel les utilisateurs travaillent, dans la mémoire de l'application et enregistrons en permanence toutes les modifications apportées à la base de données. Pour transférer la carte au niveau de l'interaction du cluster, nous la chargeons en mémoire sur le nouveau serveur et envoyons au client une commande pour se reconnecter. À ce stade, le client se déconnecte de l'ancien serveur et se connecte au nouveau. Après quelques secondes, les utilisateurs voient l'inscription - Connexion rétablie. Cependant, ils continuent de fonctionner et ne remarquent aucun inconvénient.
Ce que nous avons appris en rendant invisible le déploiement
Où en sommes-nous après une douzaine d'itérations:
- L'équipe Scrum vérifie elle-même son code.
- L'équipe Scrum décide quand lancer la pré-version et apporter certaines des modifications aux nouveaux utilisateurs.
- Scrum-team décide si sa sortie est prête à être envoyée à tous les utilisateurs.
- Les utilisateurs continuent de travailler et ne remarquent rien.
Ce n'était pas possible immédiatement, nous avons marché plusieurs fois sur le même râteau et rempli beaucoup de cônes. Je veux partager les leçons que nous avons reçues.
Tout d'abord, le processus manuel, puis seulement son automatisation. Les premières étapes n'ont pas besoin d'approfondir l'automatisation, car vous pouvez automatiser ce qui n'est finalement pas utile.
Ansible est bon, mais les rôles Ansible sont meilleurs. Nous avons rendu nos rôles aussi universels que possible: nous nous sommes débarrassés du code répétitif, donc ils ne portent que les fonctionnalités qu'ils devraient porter. Cela vous permet de gagner beaucoup de temps en réutilisant les rôles, dont nous avons déjà plus de 50.
Réutilisez le code en Python et divisez-le en bibliothèques et modules séparés. Cela vous aide à naviguer dans des projets complexes et à y plonger rapidement de nouvelles personnes.
Prochaines étapes
Le processus de déploiement invisible n'est pas encore terminé. Voici quelques-unes des étapes suivantes:
- Autorisez les équipes à terminer non seulement les versions préliminaires, mais également toutes les versions.
- Effectuez des restaurations automatiques en cas d'erreur. Par exemple, une pré-version doit automatiquement être annulée si des erreurs critiques sont détectées dans Sentry.
- Automatisez entièrement la publication en l'absence d'erreurs. S'il n'y a pas eu d'erreurs sur la pré-version, cela signifie qu'elle peut automatiquement être déployée davantage.
- Ajoutez une analyse automatique du code pour détecter d'éventuelles erreurs de sécurité.