La taille des caractéristiques des transistors diminue malgré les rumeurs constantes sur la mort de la loi de Moore et le fait que l'industrie est vraiment proche des limites physiques de la miniaturisation (ou même les a traversées avec des astuces technologiques intelligentes). La loi de Moore, cependant, a créé l'appétit des utilisateurs pour l'innovation, ce qui est difficile à gérer pour l'industrie. C'est pourquoi les produits microélectroniques modernes ne sont pas seulement mis à l'échelle de la taille des fonctionnalités, mais utilisent également un certain nombre d'autres fonctionnalités, souvent encore plus compliquées que la mise à l'échelle des puces.
Avertissement: Cet article est une traduction légèrement mise à jour de mon propre article publié sur ce site ici . Si vous êtes russophone, vous voudrez peut-être vérifier l'original. Si vous êtes anglophone, il convient de noter que l'anglais n'est pas ma langue maternelle, donc je serai très reconnaissant pour les commentaires si vous trouvez quelque chose de bizarre dans le texte. J'ai intentionnellement dit «produit microélectronique» au lieu de simplement «puce», car cet article concerne la technologie System in Package (SiP) permettant de connecter plusieurs puces à l'intérieur d'un même boîtier.
Le terme System in Package est un moyen moins populaire que le terme System on Chip (SoC), qui est couramment utilisé par toutes les sociétés de semi-conducteurs, et pour une bonne raison, car presque toute puce moderne est en quelque sorte un système avec de nombreuses fonctions fusionnées. L'époque des chipsets abondants est révolue depuis longtemps, car les avantages du SoC sont clairs: moins de boîtiers sur le PCB, moins de surface (lire "moins cher"), moins de capacités et d'inductances parasites (lire "plus vite"), plus faciles à mettre en œuvre et à utiliser, moins cher pour concevoir et fabriquer une puce complexe unique qu'un tas de puces plus spécifiques.
Mais rien n'est gratuit, et les SoC ont évidemment des inconvénients.
Tout d'abord, en essayant de rassembler toutes les pièces, vous risquez d'obtenir une puce trop grosse pour tenir dans n'importe quel emballage ou, pire encore, dans la fenêtre du photolithographe. Cette dernière restriction peut être dépassée, mais elle est presque toujours excessivement chère (les appareils photo étant l'exclusion la plus notable).
Voici le capteur d'image Kodak Kaf39000, il a une superficie de 2000 millimètres carrés et il utilise une couture de masque. La plus grande puce non cousue est la NVIDIA Volta de 815 millimètres carrés, ce qui représente à peine 20 millimètres de moins que la plus grande taille possible.
Deuxièmement, plus la puce est grande, plus le rendement est faible, car n'importe quel grain de poussière peut ruiner votre journée. Et devinez quoi? Un rendement inférieur signifie un prix plus élevé.
Troisièmement, si votre système contient des composants hétérogènes, comme le cœur du processeur, la DRAM et le module RF, leur combinaison peut être technologiquement impossible ou, encore une fois, excessivement coûteuse. Par exemple, les cellules DRAM nécessitent des condensateurs haute densité spécifiques, et les circuits RF à base de silicium peuvent être juste pires que leurs homologues produits sur divers matériaux A3B5 (GaAs et autres). Même une simple combinaison de traitement numérique et de conditionnement de signaux analogiques sur la même puce crée des problèmes de bruit importants. Et je ne dis même pas que le CAN 180 nm serait facilement deux ordres de grandeur moins cher que d'ajouter son analogique 14 nm à la puce MCU 14 nm.
La combinaison de tous les facteurs ci-dessus a conduit au changement de tendance de «nous allons tout emballer dans la puce unique» à une approche plus pragmatique - et au développement rapide de diverses technologies d'emballage.
Performance et rendement
Le premier exemple qui vient à l'esprit est la récente renaissance d'AMD, largement reconnu comme le résultat de leur succès avec les systèmes multi-puces (également aidé par les problèmes d'Intel avec le rendement sur d'énormes puces de 10 nm).
Sur la photo ci-dessus, le Xeon à 28 cœurs d'Intel. La surface de la puce de ces processeurs peut atteindre 456 millimètres carrés, alors que la taille maximale des puces AMD n'est que de 200 millimètres carrés pour huit cœurs, leurs nombreux produits de base sont en fait des PCB à deux couches avec jusqu'à quatre dés à l'intérieur de l'emballage.
Cette figure montre le PCB à l'intérieur des processeurs EPYC et Threadripper. Dans le cas de Threadripper à 16 cœurs, nous avons toujours quatre puces, mais la moitié des cœurs sont désactivés. Pourquoi ne pas simplement utiliser deux dés à la place? Ou utiliser des dés à quatre cœurs plus petits?
Tout d'abord, avoir une seule puce à toutes fins est évidemment beaucoup moins cher que de concevoir une famille.
Deuxièmement, il en va de même pour les PCB, les boîtiers, etc. Il est plus facile de désactiver un nombre excessif de pièces que de concevoir une famille de produits.
Troisième et probablement le plus important, un rendement de 200 m². le dé est encore loin de 100%, et la désactivation de certains cœurs déjà non fonctionnels est un bon moyen d'utiliser ces dés défectueux. Intel fait de même avec leurs dés défectueux, mais leurs problèmes de rendement sont plus graves en raison de la plus grande surface de la puce.
Ici, nous avons un exemple encore plus intéressant, encore une fois d'AMD. Les Fidji sont un GPU avec une mémoire haute vitesse intégrée placée à l'intérieur du package. Parce que des lignes de signaux plus courtes permettent d'atteindre une vitesse plus élevée et donc des performances plus élevées. Assembler différentes puces fait la différence entre cet exemple et l'exemple précédent. Ce n'est d'ailleurs pas cinq dés à l'intérieur comme on aurait pu le suggérer, mais vingt-deux! Regardons la coupe transversale:
Le niveau supérieur est la puce GPU elle-même et une pile de quatre dés de mémoire connectés par des soi-disant TSV (travers-silicium-vias) - des contacts conducteurs perçant la puce entière.
Voilà à quoi ressemble TSV.
La technologie TSV a été créée pour la mémoire (on ne peut pas avoir trop de mémoire, non?), Mais elle est maintenant répandue, en partie grâce à la matrice sous GPU et mémoire.
La puce est appelée Silicon Interposer et est un substitut aux PCB en silicium avec quelques (ou plusieurs) niveaux de métallisation et avec TSV. Ces intercalaires existent pour connecter plusieurs puces au-dessus d'eux avec un substrat de boîtier. La technologie au silicium permet d'avoir une taille de fonctionnalité plus petite que n'importe quel PCB (jusqu'à quelques microns), mais elle serait considérée comme très simple et bon marché pour une technologie au silicium. Une taille de fonction plus petite et un TSV signifient de meilleures performances que tout PCB peut fournir, tandis que le rendement sera très élevé. Les interposeurs (aux côtés des MEMS) sont un marché très intéressant et important, d'autant plus qu'ils permettent également la réutilisation d'anciens équipements pour des plaquettes de 200, 150, voire 100 mm.
Au fait, pouvez-vous repérer une erreur dans la figure ci-dessus?Xilinx est un autre pionnier de l'intégration 3D. Leurs produits sont proches de ceux d'AMD (en particulier les produits porteurs de quantités importantes de mémoire), et pour la même raison. Le FPGA est un marché où le passage précoce à un nœud de processus plus petit peut fournir un énorme avantage sur la concurrence. Une diminution de trois à quatre fois de la taille de la puce entraînerait une augmentation du rendement de deux à trois fois aux premiers stades de la durée de vie du nœud de processus, de 20% à plus de la moitié. De plus, le FPGA est une structure complexe mais régulière, presque idéale pour étudier un large éventail de problèmes de fabrication. Cela fait des fournisseurs FPGA les meilleurs clients hâtifs pour les fabs, car une telle collaboration est fructueuse pour les deux parties. Fab obtient une excellente puce de test tandis que le fournisseur est capable de dépasser la concurrence pendant quelques mois.

Ici, nous pouvons voir un FPGA de Xilinx. La matrice supérieure est une partie FPGA avec des tonnes de contacts de 40 micromètres vers la matrice intermédiaire appelée interposeur. Le plus bas est un emballage, qui a une douzaine de ses propres couches métalliques.
Énorme matrice FPGA Altera pour la comparaison. Cinq cent soixante millimètres carrés! Si vous voyez des ingénieurs des procédés autour de vous, prenez soin d'eux, il y a un risque d'accident cardiaque.
Intel / Altera ne regarde évidemment pas seulement les progrès de ses concurrents. Voici leur nouvelle solution SiP appelée EMIB (Embedded Multi-Chip Interconnect Bridge). Un bon exemple est Intel Stratix 10 FPGA.
EMIB connecte un dé FPGA (toujours un seul), des dés de mémoire et des dés de périphérie. Qu'est-ce que EMIB? L'interposeur typique est beaucoup moins cher que la matrice «de calcul» de la même taille que l'interposeur utilise un nœud de processus beaucoup plus grand; cependant, l'interposeur est toujours énorme et donc il est raisonnablement cher. Peut-on le rendre plus petit?
La réponse d'Intel est «oui, nous le pouvons». L'idée derrière EMIB est d'utiliser quelques petits intercalaires au lieu d'un seul grand et de les intégrer dans le package.
Voici une petite galerie de produits créés avec des intercalaires. Regardez à quel point ils sont énormes et comment Xilinx est créé à partir de pièces.
Plus que de simples performances
La figure ci-dessous représente le CAN de Analog Devices et un diagramme schématique. Ressemble à votre PCB typique, juste plus petit, non? Oui, c'est un PCB, mais l'utilisation de dés nus au lieu de packages permet de diminuer les parasites et leur influence sur les performances. Le fait que la carte entière ait été conçue dans Analog Devices ajoute également une couche de protection contre les erreurs de conception du système et conduit à une meilleure expérience utilisateur.

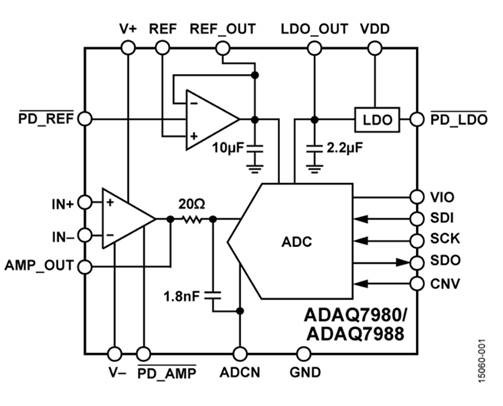
Il y a aussi une astuce: voyez-vous deux dés emballés l'un sur l'autre? Le supérieur intègre des composants actifs (transistors) de l'ADC et probablement d'un double amplificateur opérationnel, tandis que le dé inférieur se compose de passifs (résistances et condensateurs). Placer des passifs sur des matrices séparées permet de les rendre beaucoup plus gros et donc de diminuer la variation des paramètres sans rendre la matrice principale plus grande et plus chère. La diminution de la variation des paramètres est un gros problème pour les circuits analogiques, et elle est réalisée à moindre coût ici.
Tout pourrait être fait sur une seule matrice (et cela se fait souvent, en particulier sur les ADC intégrés), mais une telle matrice sera plus grande (ce qui pourrait signifier «plus cher» et «avec un rendement inférieur»), et la technologie doit prendre en charge tous les les options nécessaires (ce qui signifie également «plus cher» en raison du plus grand nombre de masques). De plus, lorsque vous combinez plusieurs blocs hétérogènes sur la même puce, vous devez gérer leur influence croisée. L'influence du bruit numérique sur les parties analogiques est probablement la plus importante, mais pas la seule.
Fonctionnalité supplémentaire du package
Comme nous l'avons vu auparavant, l'emballage peut rendre le produit moins cher et même l'améliorer. Mais que se passe-t-il si nous utilisons le package comme une partie significative du produit?
Intel a implémenté ce qu'on appelle FIVR (Fully Integrated Voltage Regulator) dans leurs microprocesseurs Haswell. L'objectif de FIVR est de convertir une tension d'entrée relativement élevée (1,8 V) en une tension d'alimentation de base contrôlable basse et en temps réel. Les composants actifs sont intégrés, tandis que les composants passifs (condensateurs et inductances) sont intégrés au boîtier du processeur.
L'inductance intégrée est un casse-tête pour les concepteurs de puces, car elle est mauvaise, grande et avec une faible inductance. Il est utilisé dans les puces radiofréquence, mais il n'y a presque aucune possibilité de transfert de puissance. Intel a résolu le problème en intégrant des dizaines de petits inducteurs dans le boîtier du processeur. Ces inductances fonctionnent à 160 MHz sans noyaux ferromagnétiques. Ce faisant, Intel a considérablement simplifié les exigences d'approvisionnement de son appareil.
Cependant, Intel a finalement mis au rebut le FIVR et est revenu à une approche d'approvisionnement plus traditionnelle pour les nouvelles générations. Il y avait des rumeurs selon lesquelles le FIVR pourrait être de retour, mais au final, ce n'étaient que des rumeurs.
L'une des autres options d'intégration des composants passifs dans le boîtier est le LTCC (céramique cuite à basse température). Il existe certaines limitations et problèmes (comme des valeurs nominales et une précision limitées), mais cette technologie est activement développée. Le package LTCC multicouche ressemble à ceci:
Tous les types de composants passifs sont représentés ici, même le dissipateur de chaleur en métal (c'est un package pour l'alimentation RF IC). On peut dire que ce n'est pas seulement un boîtier, mais un mélange de boîtier et de PCB en céramique, ces choses sont très populaires pour les circuits RF et relativement bon marché en petites quantités.
Quoi d'autre?
Il existe de nombreuses applications potentielles pour les systèmes en package, et il est impossible de toutes les énumérer. Il convient également de noter qu'ils sont nettement moins chers que les nouveaux nœuds de processus, ce qui stimule leur attractivité commerciale.
Les systèmes optoélectroniques sont le dernier mais non le moindre exemple de cet article. La capacité de combiner un récepteur / émetteur optique (souvent construit sur un semi-conducteur composé) avec des puces de contrôle et d'alimentation en silicium est très prometteuse. L'image ci-dessous est un prototype de liaison optique 400 Gbit / s (et 1 Tbit / s est promis pour l'avenir) conçu dans IMEC.
Il existe également d'innombrables autres applications comme les interposeurs avec capillaires intégrés pour le refroidissement par eau (non seulement pour les jeux et l'exploitation minière, mais aussi pour les interrupteurs d'alimentation et les lasers), les MEMS intégrés et seul Dieu sait quoi d'autre. Et évidemment, nous ne pouvons pas échapper à l'internet des objets omniprésent, où la petite taille, les faibles pertes et la capacité d'intégrer la radio et les blocs de calcul ensemble sont tous importants.
Le paquet de puces est considéré par beaucoup comme la prochaine grande étape de la microélectronique, et nous verrons probablement beaucoup d'idées brillantes dans un avenir proche.