Bonjour, Habr! Après avoir eu suffisamment de repos après de longues vacances, nous sommes à nouveau prêts à vous faire du bien de toutes les manières disponibles. Les collègues du service informatique ont toujours quelque chose à dire, et nous partageons aujourd'hui avec vous un rapport d'Alexander Prizov, administrateur système de Yandex.Money, de la réunion JavaJam.
Comment nous avons construit un flux de rétroaction pour détecter les versions problématiques en utilisant Graphite et Moira. Nous vous expliquerons comment collecter et analyser des statistiques sur le nombre d'erreurs dans l'application.
- Bonjour à tous, je m'appelle Alexander Prizov, je travaille dans le département d'automatisation des opérations de Yandex.Money, et aujourd'hui je vais vous expliquer comment nous collectons, traitons, analysons les informations sur notre système.
Vous vous êtes probablement demandé pourquoi le rapport s'appelait The Second Way (le nom du rapport sur la réunion est édité). Tout est assez simple. Au cœur de DevOps se trouve un certain nombre de principes qui sont conditionnellement divisés en trois groupes.
La première voie est le principe de l'écoulement. La deuxième manière implique le principe de rétroaction. La troisième voie est l'apprentissage et l'expérimentation continus.
En règle générale, en termes de développement et de fonctionnement des produits logiciels, le feedback signifie la télémétrie, que nous collectons sur notre système, et le cas le plus courant est la collecte et le traitement des métriques.
Pourquoi avons-nous besoin de ces mesures? À l'aide de mesures, nous obtenons des commentaires du système et nous pouvons savoir dans quel état se trouve notre système, si tout va bien, comment nos changements ont affecté son fonctionnement et si une intervention est nécessaire pour résoudre certains problèmes.
Quelles mesures collectons-nous?
Nous collectons des métriques sur trois niveaux.
Le niveau métier comprend des indicateurs intéressants du point de vue de toute tâche métier. Par exemple, nous pouvons obtenir des réponses à des questions telles que le nombre d'utilisateurs que nous avons enregistrés, la fréquence à laquelle les utilisateurs se connectent à notre système, le nombre d'utilisateurs actifs de notre application mobile.
Le niveau suivant est le niveau d'application . Les métriques de ce niveau sont le plus souvent vues par les développeurs, car ces indicateurs répondent à la question de savoir comment notre application fonctionne, à quelle vitesse elle traite les requêtes, y a-t-il des inconvénients de performances. Cela inclut le temps de réponse, le nombre de demandes, la longueur de la file d'attente et bien plus encore.
Et enfin, le niveau d'infrastructure . Tout est très clair ici. À l'aide de ces métriques, nous pouvons estimer la quantité de ressources consommées, comment les prévoir et identifier les problèmes liés à l'infrastructure.
Maintenant, en un mot, je vais décrire comment nous envoyons, traitons et où nous stockons ces métriques. À côté de l'application, nous avons un collecteur de métriques. Dans notre cas, il s'agit du service Heka, qui écoute le port UDP et attend que des métriques au format StatsD soient entrées.
Le format de StatsD est le suivant:

Autrement dit, nous déterminons le nom de la métrique, indiquons la valeur de cette métrique, elle est 1, 26, etc., et indiquons son type. Au total, StatsD a environ quatre ou cinq types. Si vous êtes soudain intéressé, vous pouvez voir en détail la description de ces types .
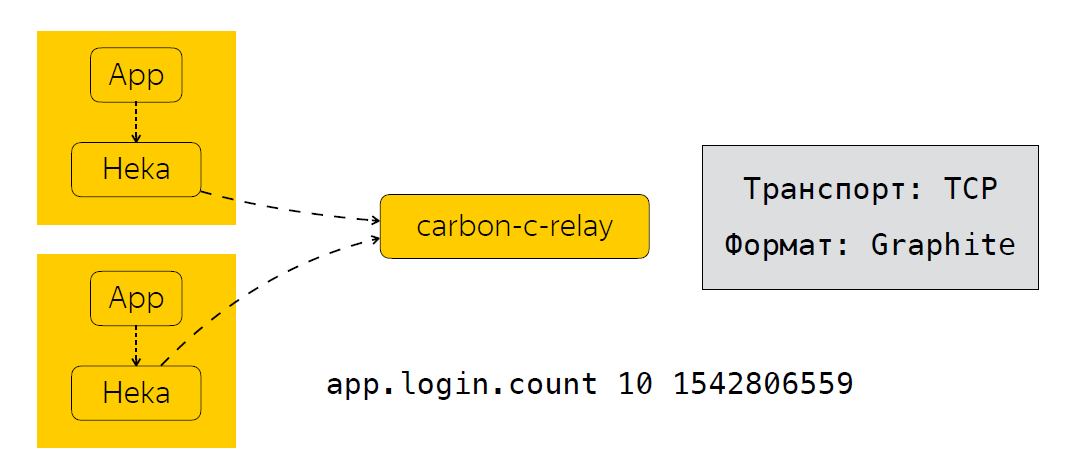
Une fois que l'application a envoyé les données Heka, les métriques sont agrégées pendant un certain temps. Dans notre cas, cela fait 30 secondes, après quoi Heka envoie des données à carbon-c-relay, qui remplit la fonction de filtrage, de routage, de mise à jour des métriques, qui, à son tour, envoie des métriques à notre stockage, nous utilisons clickhouse (oui, cela ne ralentit pas ), ainsi qu'à Moira. Si quelqu'un ne le sait pas, il s'agit d'un service qui vous permet de configurer certains déclencheurs pour les métriques. Je parlerai de Moira un peu plus tard. Nous avons donc examiné les mesures que nous collectons, comment nous les envoyons et les traitons. Et la prochaine étape logique est l'analyse de ces métriques.
Comment analysons-nous les métriques?
Je vais donner une situation réelle où l'analyse des métriques nous a donné des résultats tangibles. Prenez le processus de publication comme exemple. En termes généraux, il comprend les étapes suivantes.
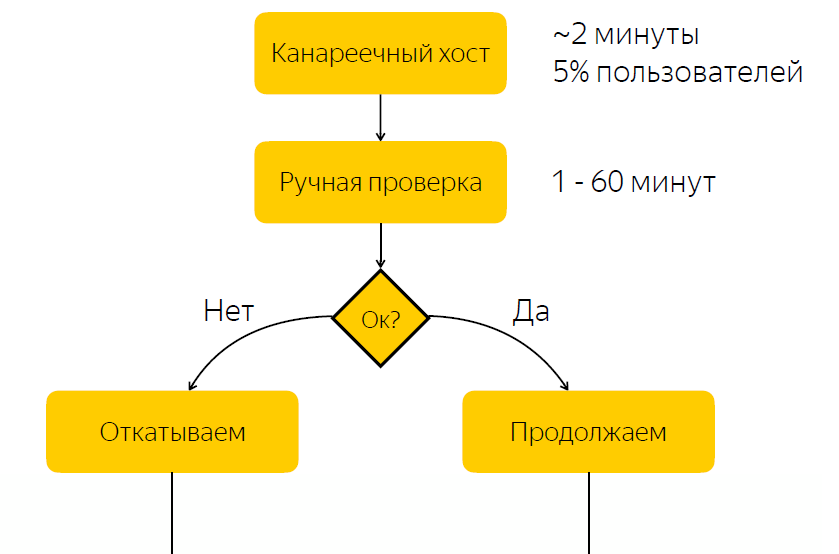
La libération est déployée sur l'hôte canari. Il représente environ cinq pour cent du trafic des utilisateurs. Après la libération de l'hôte canari, nous informons la personne responsable de la libération qu'elle doit vérifier si tout est en ordre avec la libération. Et il devrait donner une réaction, réagir à cette version et cliquer sur le bouton pour décider si cette version doit être poursuivie ou annulée.
Il n'est pas difficile de deviner qu'il y a un inconvénient important dans ce schéma, à savoir que nous attendons une réaction responsable. Si la personne responsable en ce moment pour une raison quelconque ne peut pas répondre rapidement, alors si nous avons une version de bogue, alors pendant un certain temps, cinq pour cent du trafic arrive au nœud problématique. Si tout est en ordre avec la sortie, alors nous passons simplement du temps à attendre, et ainsi ralentir le processus de sortie.
Aucun bogue - nous ralentissons le processus de publication
Avec des bugs - affection des utilisateurs
Avec une compréhension de ce problème, nous avons décidé de savoir s'il est possible d'automatiser le processus de prise de décision sur la question de savoir si une version est problématique ou non.
Bien sûr, nous nous sommes tournés vers nos développeurs pour comprendre comment la vérification des versions est effectuée. Il s'est avéré, et cela semble assez logique, que le principal indicateur que la publication est problématique est l'augmentation du nombre d'erreurs dans les journaux de cette application.
Qu'ont fait les développeurs? Ils ont ouvert Kibana, fait une sélection en fonction du niveau d'ERREUR du bloc d'application, et s'ils ont vu les listes, ils ont pensé que quelque chose n'allait pas avec l'application. Il convient de mentionner que les journaux de notre application sont stockés dans Elastic, et il semble que tout semble assez simple. Nous avons les journaux dans Elastic, il nous suffit de créer une demande dans Elastic, de faire une sélection et de comprendre en fonction de ces données si la version est problématique ou non. Mais cette décision ne nous a pas paru très bonne.
Pourquoi pas élastique?
Tout d'abord, nous craignions de ne pas pouvoir recevoir rapidement les données d'Elastic. Il y a de tels cas, par exemple, pendant les tests de résistance, lorsque nous avons un grand flux de données et que le cluster peut ne pas faire face, et, finalement, il y a un retard dans l'envoi des journaux pendant environ 10-15 minutes.
Il y avait aussi des raisons secondaires, par exemple, l'absence d'un nom uniforme pour les index. Cela devait être pris en compte dans l'outil d'automatisation. Et les applications sur différentes plates-formes peuvent également avoir différents formats de journal.
Nous avons pensé, pourquoi ne pas essayer de faire une sorte de métriques sur la base desquelles nous pouvons décider si la publication est problématique ou non. Dans le même temps, nous ne voulions pas inciter nos développeurs à apporter des modifications à la base de code. Et, comme il nous semble, nous avons trouvé une solution assez élégante en ajoutant un appender supplémentaire à log4j.
À quoi ça ressemble
<?xml version="1.0" encoding="UTF-8" ?> <Configuration status="warn" name="${sys:application.name}" > <Properties> <Property name="logsCountStatsDFormat">app_name.logs.%level:1|c</Property> </Properties> ... <Appenders> <Socket name="STATSD" host="127.0.0.1" port="8125" protocol="UDP"> <PatternLayout pattern="${logsCountStatsDFormat}"/> </Socket> </Appenders> <Loggers> <Root level="INFO"> <AppenderRef ref="STATSD"/> </Root> </Loggers> </Configuration>
Tout d'abord, nous déterminons le format de la métrique que nous envoyons. Ce qui suit est un appender supplémentaire qui envoie des enregistrements dans le format que nous avons ci-dessus au port 8125 via UDP, c'est-à-dire à Heka. Qu'est-ce que cela nous donne? Log4j envoie une métrique de type Counter à chaque entrée de journal avec le niveau d'enregistrement spécifié ERROR, INFO, WARN, etc.
Cependant, nous avons rapidement réalisé que l'envoi d'une métrique à chaque entrée de journal peut créer une charge assez importante, et nous avons écrit une bibliothèque qui agrège les métriques pendant un certain temps et envoie la métrique déjà agrégée au service Heka. En fait, nous ajoutons cet appender aux enregistreurs, et avec cette approche, nous savons maintenant combien notre application écrit des journaux pour le nivellement, nous avons un nom unifié pour les mesures, quelle que soit la plate-forme utilisée. Nous pouvons facilement comprendre le nombre d'erreurs dans le journal des applications. Et enfin, nous avons pu automatiser le processus de prise de décision pour une version problématique.
Automatisation
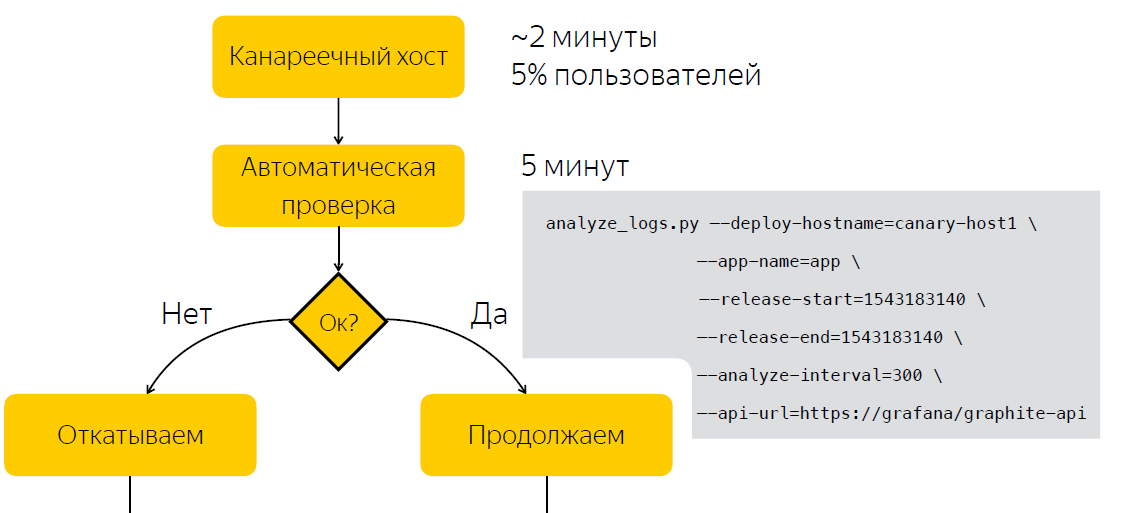
Au lieu de vérifier manuellement après la publication, nous attendons cinq minutes, après quoi nous collectons des données sur le nombre d'entrées dans les journaux d'application. Après avoir exécuté le script, qui, sur la base de deux échantillons, avant et après la sortie, décide si la sortie est problématique. Ainsi, nous avons réduit le temps que nous consacrons à prendre une décision à cinq minutes.
En plus du fait que les informations sur le nombre d'erreurs dans les journaux sont utiles lors de la publication, il s'est avéré être un bon bonus qu'elles soient également utiles pendant le fonctionnement. Ainsi, par exemple, nous pouvons visualiser le nombre d'erreurs dans les journaux de Grafana et enregistrer des surtensions anormales dans les journaux d'application.
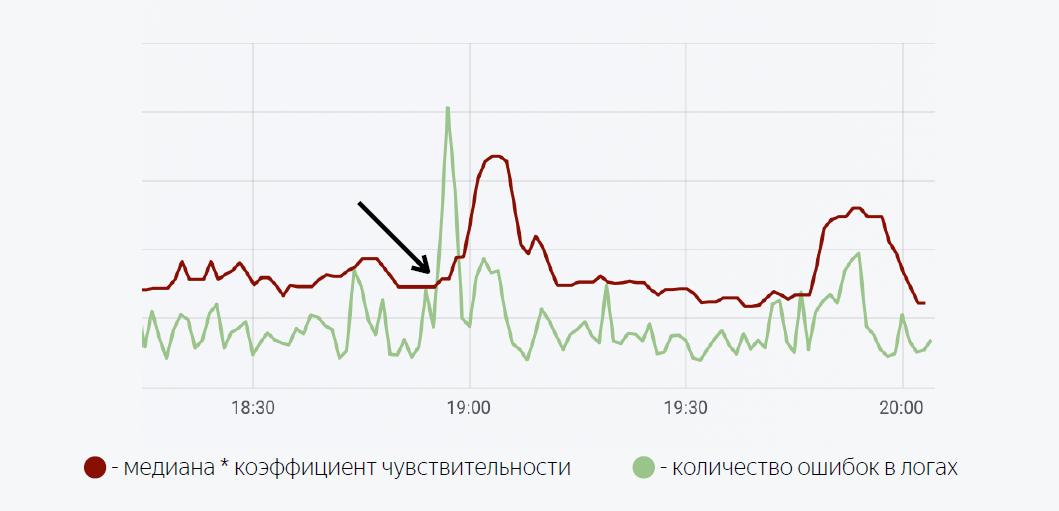
Un modèle mathématique assez simple est utilisé ici. La ligne verte est le nombre d'erreurs dans les journaux d'application. Le rouge foncé est le temps médian du facteur de sensibilité. Dans le cas où le nombre d'erreurs dans les journaux dépasse la médiane, un déclencheur est déclenché, lorsqu'il est déclenché, une notification est envoyée via Moira.
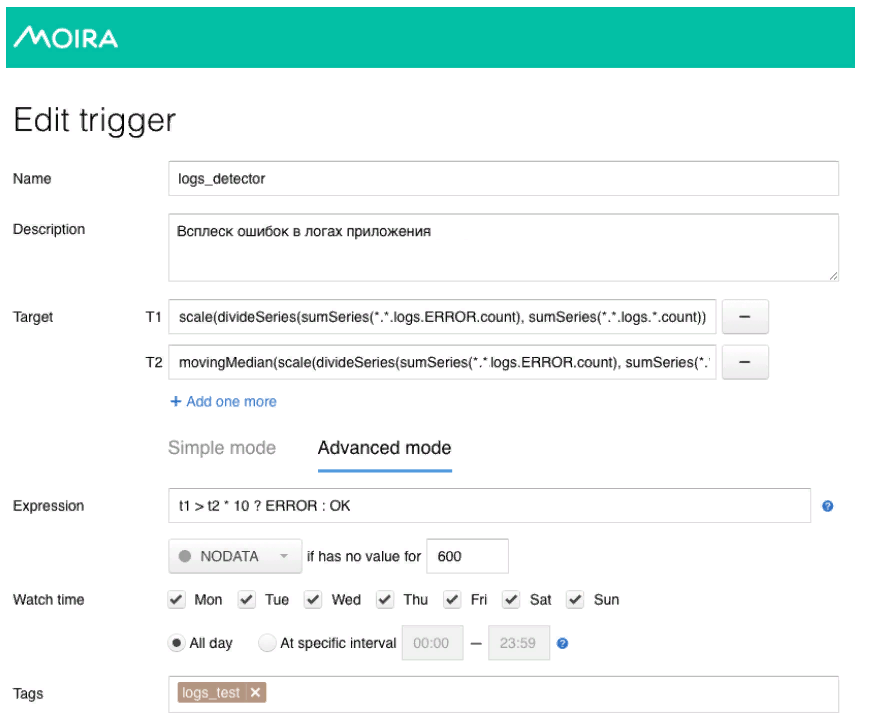
Comme je l'ai promis, je vais vous parler un peu de Moira, de son fonctionnement. Nous définissons les métriques cibles que nous voulons observer. Il s'agit du nombre d'erreurs et de la médiane mobile, ainsi que des conditions dans lesquelles ce déclencheur fonctionnera, c'est-à-dire lorsque le nombre d'erreurs dans les journaux dépasse la médiane multipliée par le coefficient de sensibilité. Lorsque le déclencheur est déclenché, le développeur reçoit une notification indiquant qu'une rafale anormale d'erreurs a été enregistrée dans l'application et certaines actions doivent être entreprises.

Qu'avons-nous finalement? Nous avons développé un mécanisme commun pour toutes nos applications backend, qui nous permet d'obtenir des informations sur le nombre d'entrées dans les journaux d'un niveau donné. De plus, en utilisant des mesures sur le nombre d'erreurs dans les journaux d'application, nous avons pu automatiser le processus de prise de décision sur la question de savoir si la publication est problématique ou non. Ils ont également écrit une bibliothèque pour log4j, que vous pouvez utiliser si vous voulez essayer l'approche que j'ai décrite. Lien vers la bibliothèque ci-dessous.
C’est probablement tout pour moi. Je vous remercie
Liens utiles
Log4j-count-appender
Moira