Tout avec les vacances passées!
Nous avons décidé de consacrer notre premier article après les vacances à Linux, c'est-à-dire à notre merveilleux cours
Administrateur Linux , que nous avons dans la cohorte des cours les plus dynamiques, c'est-à-dire avec le matériel et les pratiques les plus pertinents. Eh bien et, en conséquence, nous proposons des articles intéressants et
une leçon ouverte .
Publié par Matteo Croce
Titre original: débogage réseau avec eBPF (RHEL 8 Beta)PrésentationLe réseautage est une expérience passionnante, mais les problèmes ne sont pas toujours évités. Le dépannage peut être délicat, tout comme essayer de reproduire le mauvais comportement qui se produit «sur le terrain».
Heureusement, il existe des outils qui peuvent vous y aider: les espaces de noms réseau, les machines virtuelles,
tc et
netfilter . Les paramètres réseau simples peuvent être reproduits à l'aide d'espaces de noms réseau et de périphériques veth, tandis que les paramètres plus complexes nécessitent la connexion de machines virtuelles avec un pont logiciel et l'utilisation d'outils réseau standard, tels que
iptables ou
tc , pour simuler un comportement incorrect. En cas de problème avec les réponses ICMP générées lorsque le serveur SSH se
iptables -A INPUT -p tcp --dport 22 -j REJECT --reject-with icmp-host-unreachable ,
iptables -A INPUT -p tcp --dport 22 -j REJECT --reject-with icmp-host-unreachable dans le bon espace de noms peut aider à résoudre le problème.
Cet article décrit comment résoudre les problèmes réseau complexes avec
eBPF (BPF étendu) , une version avancée du filtre de paquets Berkeley. eBPF est une technologie relativement nouvelle, le projet est à un stade précoce, donc la documentation et le SDK ne sont pas encore prêts. Mais espérons des améliorations, d'autant plus que le XDP (eXpress Data Path) est livré avec
Red Hat Enterprise Linux 8 Beta , que vous pouvez télécharger et exécuter dès maintenant.
eBPF ne résoudra pas tous les problèmes, mais c'est toujours un puissant outil de débogage réseau qui mérite notre attention. Je suis sûr que cela jouera un rôle très important dans l'avenir des réseaux.
 Le problème
Le problèmeJe
déboguais un problème de réseau
Open vSwitch (OVS) qui impliquait une installation très compliquée: certains paquets TCP étaient dispersés et livrés dans le mauvais ordre, et la bande passante des machines virtuelles passait de 6 Gb / s stables à 2-4 Gb / s fluctuants. L'analyse a montré que le premier paquet TCP de chaque connexion avec l'indicateur PSH a été envoyé dans le mauvais ordre: uniquement le premier et un seul par connexion.
J'ai essayé de reproduire ce paramètre avec deux machines virtuelles et, après de nombreux articles d'aide et requêtes de recherche, j'ai constaté que ni
iptables ni
nftables ne peuvent manipuler les indicateurs TCP, tandis que
tc peut, mais uniquement en écrasant les indicateurs et en interrompant les nouvelles connexions et TCP en général.
Il pourrait être possible de résoudre le problème avec une combinaison d'
iptables , de
conntrack et de
tc , mais j'ai décidé que c'était un excellent travail pour eBPF.
Qu'est-ce que eBPF?eBPF est une version améliorée du filtre de paquets Berkeley. Elle apporte de nombreuses améliorations à BPF. En particulier, il vous permet d'écrire en mémoire, et pas seulement de lire, de sorte que les packages peuvent non seulement être filtrés, mais également modifiés.
Souvent, eBPF est simplement appelé BPF, et BPF lui-même est appelé cBPF (classique (classique) BPF), donc le mot «BPF» peut être utilisé pour désigner les deux versions, selon le contexte: dans cet article, je parle toujours de la version étendue.
«Sous le capot» eBPF a une machine virtuelle très simple qui peut exécuter de petits fragments de bytecode et éditer quelques tampons de mémoire. Il existe des limitations dans eBPF qui le protègent contre toute utilisation malveillante:
- Les cycles sont interdits afin que le programme se termine toujours à un moment précis;
- Il ne peut accéder à la mémoire que via la pile et le tampon de travail;
- Seules les fonctions de noyau autorisées peuvent être appelées.
Un programme peut être chargé dans le noyau de différentes manières à l'aide du
débogage et du traçage . Dans notre cas, eBPF souhaite travailler avec des sous-systèmes réseau. Il existe deux façons d'utiliser le programme eBPF:
- Connecté via XDP au début du chemin RX d'une carte réseau physique ou virtuelle;
- Connecté via
tc à qdisc en entrée ou en sortie.
Pour créer un programme eBPF pour la connexion, il suffit d'écrire du code C et de le convertir en bytecode. Voici un exemple simple utilisant XDP:
SEC("prog") int xdp_main(struct xdp_md *ctx) { void *data_end = (void *)(uintptr_t)ctx->data_end; void *data = (void *)(uintptr_t)ctx->data; struct ethhdr *eth = data; struct iphdr *iph = (struct iphdr *)(eth + 1); struct icmphdr *icmph = (struct icmphdr *)(iph + 1); if (icmph + 1 > data_end) return XDP_PASS; if (eth->h_proto != ntohs(ETH_P_IP) || iph->protocol != IPPROTO_ICMP || icmph->type != ICMP_ECHOREPLY) return XDP_PASS; if (iph->ttl) { uint16_t *ttlproto = (uint16_t *)&iph->ttl; uint16_t old_ttlproto = *ttlproto; iph->ttl = bpf_get_prandom_u32() % iph->ttl + 1; csum_replace2(&iph->check, old_ttlproto, *ttlproto); } return XDP_PASS; } char _license[] SEC("license") = "GPL";
L'extrait ci-dessus, sans expressions, assistants et code facultatif, est un programme XDP qui modifie le TTL des réponses d'écho ICMP reçues, à savoir les pongs, par un nombre aléatoire. La fonction principale obtient la structure
xdp_md , qui contient deux pointeurs vers le début et la fin du package.
Pour compiler notre code en bytecode eBPF, un compilateur avec un support approprié est requis. Clang le prend en charge et crée un bytecode eBPF en spécifiant bpf comme cible au moment de la compilation:
$ clang -O2 -target bpf -c xdp_manglepong.c -o xdp_manglepong.o
La commande ci-dessus crée un fichier qui, à première vue, ressemble à un fichier objet normal, mais en y regardant de plus près, il s'avère que le type d'ordinateur spécifié est Linux eBPF, et non le type natif de système d'exploitation:
$ readelf -h xdp_manglepong.o ELF Header: Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Class: ELF64 Data: 2's complement, little endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: REL (Relocatable file) Machine: Linux BPF <--- HERE [...]
Ayant reçu le wrapper d'un fichier objet normal, le programme eBPF est prêt à télécharger et à se connecter à l'appareil via XDP. Cela peut être fait en utilisant
ip du package
iproute2 avec la syntaxe suivante:
Cette commande spécifie l'interface wlan0 cible et, grâce à l'option -force, écrase tout code eBPF existant qui a déjà été chargé. Après avoir chargé le bytecode eBPF, le système se comporte comme suit:
$ ping -c10 192.168.85.1 PING 192.168.85.1 (192.168.85.1) 56(84) bytes of data. 64 bytes from 192.168.85.1: icmp_seq=1 ttl=41 time=0.929 ms 64 bytes from 192.168.85.1: icmp_seq=2 ttl=7 time=0.954 ms 64 bytes from 192.168.85.1: icmp_seq=3 ttl=17 time=0.944 ms 64 bytes from 192.168.85.1: icmp_seq=4 ttl=64 time=0.948 ms 64 bytes from 192.168.85.1: icmp_seq=5 ttl=9 time=0.803 ms 64 bytes from 192.168.85.1: icmp_seq=6 ttl=22 time=0.780 ms 64 bytes from 192.168.85.1: icmp_seq=7 ttl=32 time=0.847 ms 64 bytes from 192.168.85.1: icmp_seq=8 ttl=50 time=0.750 ms 64 bytes from 192.168.85.1: icmp_seq=9 ttl=24 time=0.744 ms 64 bytes from 192.168.85.1: icmp_seq=10 ttl=42 time=0.791 ms --- 192.168.85.1 ping statistics --- 10 packets transmitted, 10 received, 0% packet loss, time 125ms rtt min/avg/max/mdev = 0.744/0.849/0.954/0.082 ms
Chaque paquet passe par eBPF, qui finalement apporte quelques modifications et décide de supprimer le paquet ou de l'ignorer.
Comment eBPF peut vous aiderRevenant au problème de réseau d'origine, nous rappelons qu'il était nécessaire de marquer plusieurs drapeaux TCP, un par connexion, et ni
iptables ni
tc ne pouvaient le faire. L'écriture de code pour ce scénario n'est pas difficile du tout: configurez deux machines virtuelles connectées par un pont OVS et connectez simplement l'eBPF à l'un des périphériques de machine virtuelle.
Cela semble être une excellente solution, mais gardez à l'esprit que XDP ne prend en charge que le traitement des paquets reçus, et la connexion de l'eBPF au chemin
rx de la machine virtuelle réceptrice n'aura aucun effet sur le commutateur.
Pour résoudre ce problème, eBPF doit être chargé à l'aide de
tc et connecté au chemin de sortie de la machine virtuelle, car
tc peut charger et connecter des programmes eBPF à qdisk. Pour marquer les paquets quittant l'hôte, eBPF doit être connecté au qdisk de sortie.
Lors du chargement du programme eBPF, il existe quelques différences entre l'API
XDP et
tc : par défaut, différents noms de section, le type de structure de l'argument de la fonction principale, différentes valeurs de retour. Mais ce n'est pas un problème. Voici un extrait d'un programme qui marque TCP lors de la jointure d'une action tc:
#define RATIO 10 SEC("action") int bpf_main(struct __sk_buff *skb) { void *data = (void *)(uintptr_t)skb->data; void *data_end = (void *)(uintptr_t)skb->data_end; struct ethhdr *eth = data; struct iphdr *iph = (struct iphdr *)(eth + 1); struct tcphdr *tcphdr = (struct tcphdr *)(iph + 1); if ((void *)(tcphdr + 1) > data_end) return TC_ACT_OK; if (eth->h_proto != __constant_htons(ETH_P_IP) || iph->protocol != IPPROTO_TCP) return TC_ACT_OK; if (tcphdr->syn || tcphdr->fin || tcphdr->rst || tcphdr->psh) return TC_ACT_OK; if (bpf_get_prandom_u32() % RATIO == 0) tcphdr->psh = 1; return TC_ACT_OK; } char _license[] SEC("license") = "GPL";
La compilation en bytecode se fait comme indiqué dans l'exemple XDP ci-dessus en utilisant ce qui suit:
clang -O2 -target bpf -c tcp_psh.c -o tcp_psh.o
Mais le téléchargement est différent:
Maintenant, le eBPF est chargé au bon endroit et les paquets quittant la VM sont marqués. Après avoir vérifié les paquets reçus dans la deuxième machine virtuelle, nous verrons ce qui suit:
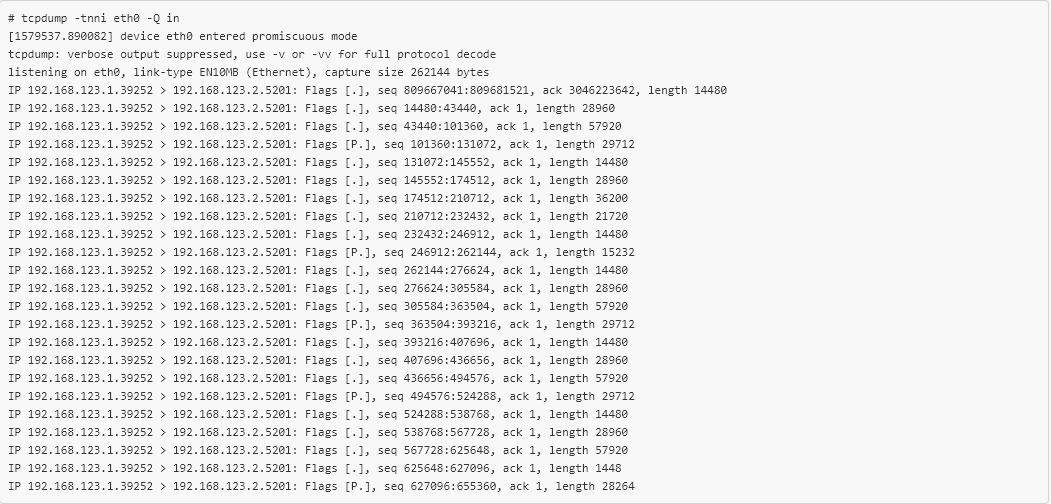
tcpdump confirme que le nouveau code eBPF fonctionne et qu'environ 1 paquet TCP sur 10 a l'indicateur PSH défini. Seules 20 lignes de code C étaient nécessaires pour marquer sélectivement les paquets TCP quittant la machine virtuelle, reproduire l'erreur qui se produit «au combat», et tout cela sans recompiler ni même redémarrer! Cela a grandement simplifié la vérification du
correctif Open vSwitch , qui était impossible à réaliser avec d'autres outils.
ConclusioneBPF est une technologie assez nouvelle et la communauté a une opinion claire sur sa mise en œuvre. Il convient également de noter que les projets basés sur eBPF, par exemple
bpfilter , sont de plus en plus populaires et, par conséquent, de nombreux fournisseurs d'équipement commencent à implémenter le support eBPF directement dans les cartes réseau.
L'eBPF ne résoudra pas tous les problèmes, alors n'en abusez pas, mais il reste tout de même un outil très puissant pour le débogage réseau et mérite l'attention. Je suis sûr qu'il jouera un rôle important dans l'avenir des réseaux.
LA FINNous attendons vos commentaires ici, et nous vous invitons également à visiter notre
leçon ouverte , où si vous pouvez également poser des questions.