Dans cet article, nous présentons les
pages , un schéma de gestion de la mémoire très courant que nous appliquons également dans notre système d'exploitation. L'article explique pourquoi l'isolement de la mémoire est nécessaire, comment fonctionne la
segmentation , ce qu'est
la mémoire virtuelle et comment les pages résolvent le problème de fragmentation. Nous explorons également le schéma des tables de pages à plusieurs niveaux dans l'architecture x86_64.
Ce blog est publié sur
GitHub . Si vous avez des questions ou des problèmes, ouvrez-y la demande correspondante.
Protection de la mémoire
L'une des tâches principales du système d'exploitation est d'isoler les programmes les uns des autres. Par exemple, un navigateur ne doit pas interférer avec un éditeur de texte. Il existe différentes approches en fonction du matériel et de la mise en œuvre du système d'exploitation.
Par exemple, certains processeurs ARM Cortex-M (dans les systèmes embarqués) ont
une unité de protection de la mémoire (MPU) qui définit un petit nombre (par exemple, 8) de zones de mémoire avec différentes autorisations d'accès (par exemple, aucun accès, lecture seule, lecture et enregistrements). Chaque fois que la mémoire est accédée, le MPU s'assure que l'adresse est dans la zone avec les autorisations correctes, sinon il lève une exception. En modifiant la portée et les autorisations d'accès, le système d'exploitation garantit que chaque processus n'a accès qu'à sa mémoire afin d'isoler les processus les uns des autres.
Sur x86, deux approches différentes de protection de la mémoire sont prises en charge: la
segmentation et la
pagination .
Segmentation
La segmentation a été implémentée en 1978, initialement pour augmenter la quantité de mémoire adressable. À cette époque, le processeur ne prenait en charge que les adresses 16 bits, ce qui limitait la quantité de mémoire adressable à 64 Ko. Pour augmenter ce volume, des registres de segments supplémentaires ont été introduits, chacun contenant une adresse de décalage. Le CPU ajoute automatiquement ce décalage à chaque accès à la mémoire, adressant ainsi jusqu'à 1 Mo de mémoire.
Le CPU sélectionne automatiquement le registre de segment en fonction du type d'accès à la mémoire: le registre de segment de code
CS est utilisé pour recevoir des instructions et le registre de segment de pile
SS est utilisé pour les opérations de pile (push / pop). D'autres instructions utilisent le registre de segment de données
DS ou le registre de segment
ES option. Plus tard, deux registres de segment supplémentaires
FS et
GS ont été ajoutés pour une utilisation gratuite.
Dans la première version de segmentation, les registres contenaient directement le décalage et le contrôle d'accès n'était pas effectué. Avec l'avènement du
mode protégé, le mécanisme a changé. Lorsque la CPU fonctionne dans ce mode, les descripteurs de segment stockent l'index dans une table de descripteurs locale ou globale qui, en plus de l'adresse de décalage, contient la taille du segment et les autorisations d'accès. En chargeant des tables de descripteurs globales / locales distinctes pour chaque processus, le système d'exploitation peut isoler les processus les uns des autres.
En changeant les adresses mémoire avant l'accès réel, la segmentation a implémenté une méthode qui est maintenant utilisée presque partout: c'est
la mémoire virtuelle .
Mémoire virtuelle
L'idée de la mémoire virtuelle est d'abstraire des adresses de mémoire d'un périphérique physique. Au lieu d'accéder directement au périphérique de stockage, une étape de conversion est d'abord effectuée. En cas de segmentation, l'adresse de décalage du segment actif est ajoutée au stade de la traduction. Imaginez un programme qui accède à l'adresse mémoire
0x1234000 dans un segment avec un décalage de
0x1111000 : en réalité, l'adresse passe à
0x2345000 .
Pour distinguer deux types d'adresses, les adresses avant la conversion sont appelées
virtuelles et les adresses après la conversion sont appelées
physiques . Il existe une différence importante entre elles: les adresses physiques sont uniques et font toujours référence au même emplacement unique en mémoire. Les adresses virtuelles, en revanche, dépendent de la fonction de traduction. Deux adresses virtuelles différentes peuvent bien faire référence à la même adresse physique. De plus, des adresses virtuelles identiques peuvent faire référence à différentes adresses physiques après la conversion.
Un exemple d'utilisation utile de cette propriété est le lancement parallèle du même programme deux fois:
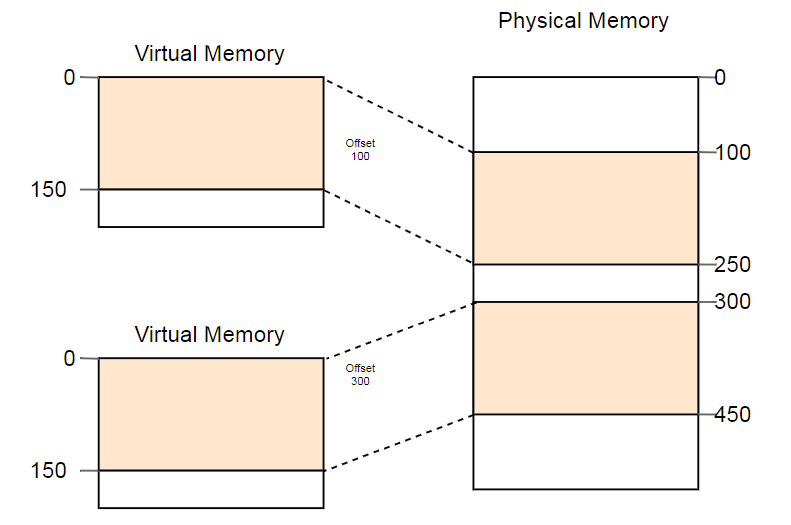
Ici, le même programme s'exécute deux fois, mais avec des fonctions de conversion différentes. La première instance a un décalage de segment de 100, donc ses adresses virtuelles 0-150 sont converties en adresses physiques 100-250. La deuxième instance a un décalage de 300, qui traduit les adresses virtuelles 0-150 en adresses physiques 300-450. Cela permet aux deux programmes d'exécuter le même code et d'utiliser les mêmes adresses virtuelles sans interférer l'un avec l'autre.
Un autre avantage est que les programmes peuvent désormais être placés à des endroits arbitraires sur la mémoire physique. Ainsi, le système d'exploitation utilise la totalité de la mémoire disponible sans avoir besoin de recompiler les programmes.
Fragmentation
La différence entre les adresses virtuelles et physiques est une réelle réalisation de segmentation. Mais il y a un problème. Imaginez que nous voulons exécuter la troisième copie du programme que nous avons vu ci-dessus:
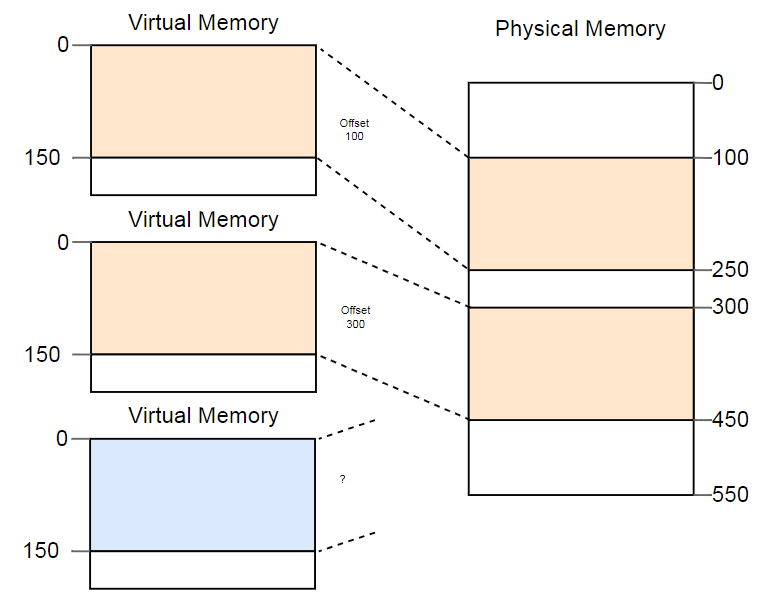
Bien qu'il y ait plus qu'assez d'espace dans la mémoire physique, la troisième copie ne tient nulle part. Le problème est qu'il a besoin d'un fragment de mémoire
continu et nous ne pouvons pas utiliser de sections libres séparées.
Une façon de lutter contre la fragmentation consiste à suspendre l'exécution du programme, à rapprocher les parties de mémoire utilisées, à mettre à jour la conversion, puis à reprendre l'exécution:
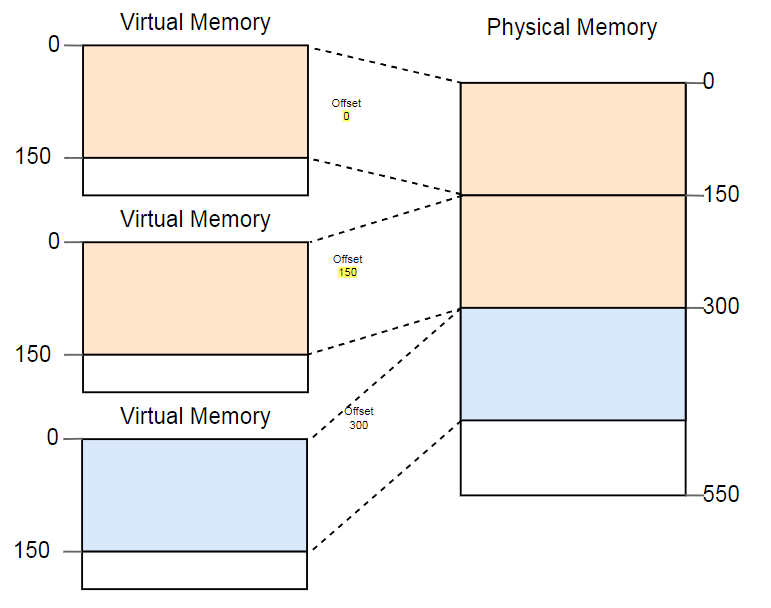
Il y a maintenant suffisamment d'espace pour lancer la troisième instance.
L'inconvénient de cette défragmentation est la nécessité de copier de grandes quantités de mémoire, ce qui réduit les performances. Cette procédure doit être effectuée régulièrement jusqu'à ce que la mémoire soit devenue trop fragmentée. Les performances deviennent imprévisibles, les programmes s'arrêtent à tout moment et peuvent cesser de répondre.
La fragmentation est l'une des raisons pour lesquelles la segmentation n'est pas utilisée dans la plupart des systèmes. En fait, il n'est plus pris en charge même en mode 64 bits sur x86. Au lieu de la segmentation, des pages sont utilisées qui éliminent complètement le problème de fragmentation.
Organisation de la page de la mémoire
L'idée est de diviser l'espace de la mémoire virtuelle et physique en petits blocs de taille fixe. Les blocs de mémoire virtuelle sont appelés pages et les blocs d'espace d'adressage physique sont appelés cadres. Chaque page est mappée individuellement à un cadre, ce qui vous permet de diviser de grandes zones de mémoire entre des cadres physiques non adjacents.
L'avantage devient évident si vous répétez l'exemple avec un espace mémoire fragmenté, mais cette fois en utilisant des pages au lieu de la segmentation:
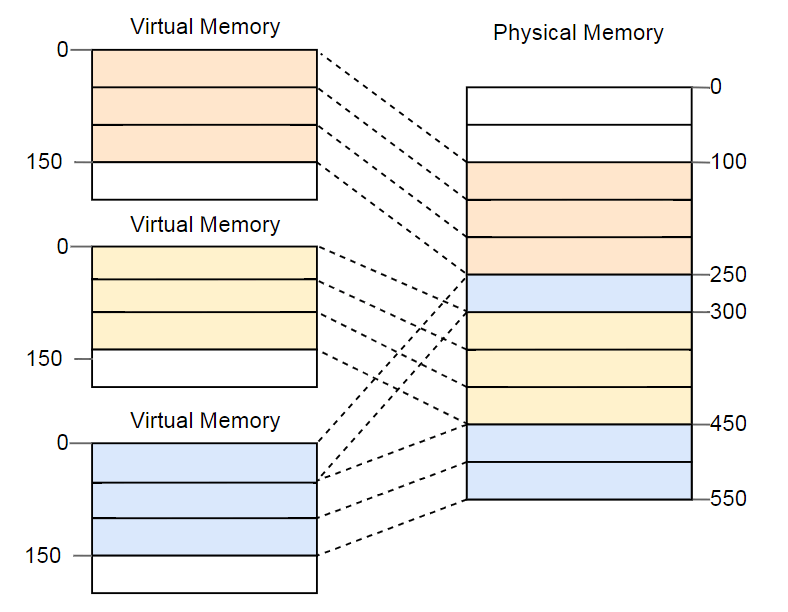
Dans cet exemple, la taille de la page est de 50 octets, c'est-à-dire que chacune des zones de mémoire est divisée en trois pages. Chaque page est mappée sur un cadre distinct, de sorte qu'une région contiguë de mémoire virtuelle peut être mappée sur des cadres physiques isolés. Cela vous permet d'exécuter la troisième instance du programme sans défragmentation.
Fragmentation cachée
Par rapport à la segmentation, une organisation de pagination utilise de nombreuses petites zones de mémoire de taille fixe au lieu de plusieurs grandes zones de taille variable. Chaque cadre a la même taille, donc la fragmentation due à des cadres trop petits n'est pas possible.
Mais ce n'est qu'une
apparence . En fait, il existe une forme cachée de fragmentation, la soi-disant
fragmentation interne car toutes les zones de mémoire ne sont pas exactement un multiple de la taille de la page. Imaginez dans l'exemple ci-dessus, un programme de taille 101: il aura toujours besoin de trois pages de taille 50, donc cela prendra 49 octets de plus que ce dont vous avez besoin. Pour plus de clarté, la fragmentation due à la segmentation est appelée
fragmentation externe .
Il n'y a rien de bon dans la fragmentation interne, mais souvent c'est un moindre mal que la fragmentation externe. De la mémoire supplémentaire est toujours consommée, mais vous n'avez plus besoin de la défragmenter et le volume de fragmentation est prévisible (en moyenne, une demi-page pour chaque zone de mémoire).
Tableaux de pages
Nous avons vu que chacune des millions de pages possibles est mappée individuellement à un cadre. Ces informations de traduction d'adresse doivent être stockées quelque part. Lors de la segmentation, des registres de segment séparés sont utilisés pour chaque zone mémoire active, ce qui est impossible dans le cas des pages, car il y en a beaucoup plus que des registres. Au lieu de cela, il utilise une structure appelée
table de pages .
Pour l'exemple ci-dessus, les tableaux ressembleront à ceci:
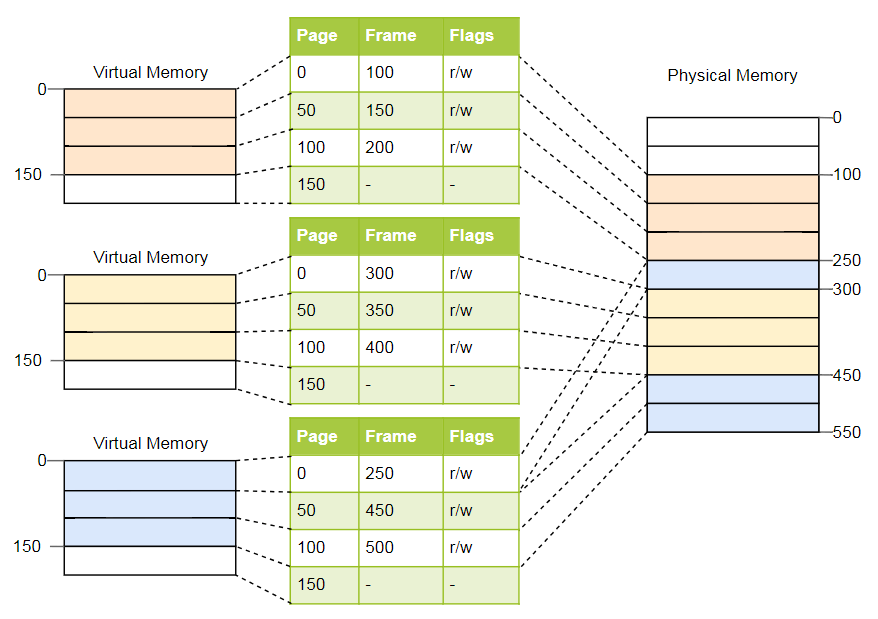
Comme vous pouvez le voir, chaque instance du programme a sa propre table de pages. Un pointeur vers la table active actuelle est stocké dans un registre spécial de la CPU. Sur
x86 il s'appelle
CR3 . Avant de démarrer chaque instance du programme, le système d'exploitation doit y charger un pointeur vers la table de pages appropriée.
A chaque accès à la mémoire, la CPU lit le pointeur de table dans le registre et recherche la trame correspondante dans la table. Il s'agit d'une fonction entièrement matérielle qui s'exécute de manière totalement transparente pour un programme en cours d'exécution. Pour accélérer le processus, de nombreuses architectures de processeurs disposent d'un cache spécial qui se souvient des résultats des dernières conversions.
Selon l'architecture, des attributs tels que les autorisations peuvent également être stockés dans le champ indicateur de la table de pages. Dans l'exemple ci-dessus, l'indicateur
r/w rend la page lisible et inscriptible.
Tableaux de pages en couches
Les tables de page simples ont un problème avec les grands espaces d'adressage: la mémoire est gaspillée. Par exemple, le programme utilise quatre pages virtuelles
0 ,
1_000_000 ,
1_000_050 et
1_000_100 (nous utilisons
_ comme séparateur de chiffres):
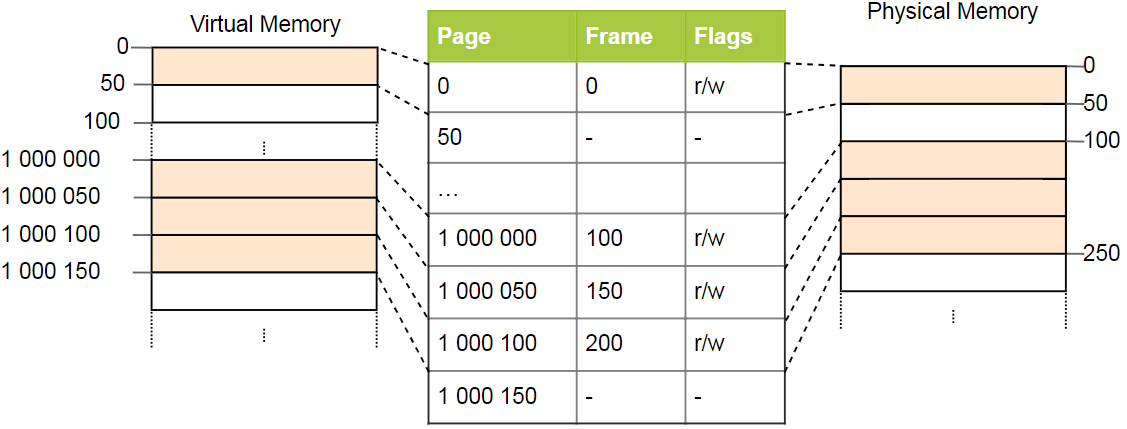
Seuls quatre cadres physiques sont requis, mais il y a plus d'un million d'enregistrements dans le tableau des pages. Nous ne pouvons pas ignorer les enregistrements vides, car le processeur pendant le processus de conversion ne pourra pas accéder directement à l'enregistrement correct (par exemple, il n'est plus garanti que la quatrième page utilise le quatrième enregistrement).
Pour réduire la perte de mémoire, vous pouvez utiliser une
organisation à deux niveaux . L'idée est que nous utilisons différentes tables pour différents domaines. Une table supplémentaire, appelée table de pages de
deuxième niveau , convertit entre les zones d'adresse et les tables de pages de premier niveau.
Ceci est mieux expliqué par l'exemple. Nous définissons que chaque table de page de niveau 1 est responsable d'une zone de taille
10_000 . Dans l'exemple ci-dessus, les tableaux suivants existeront:
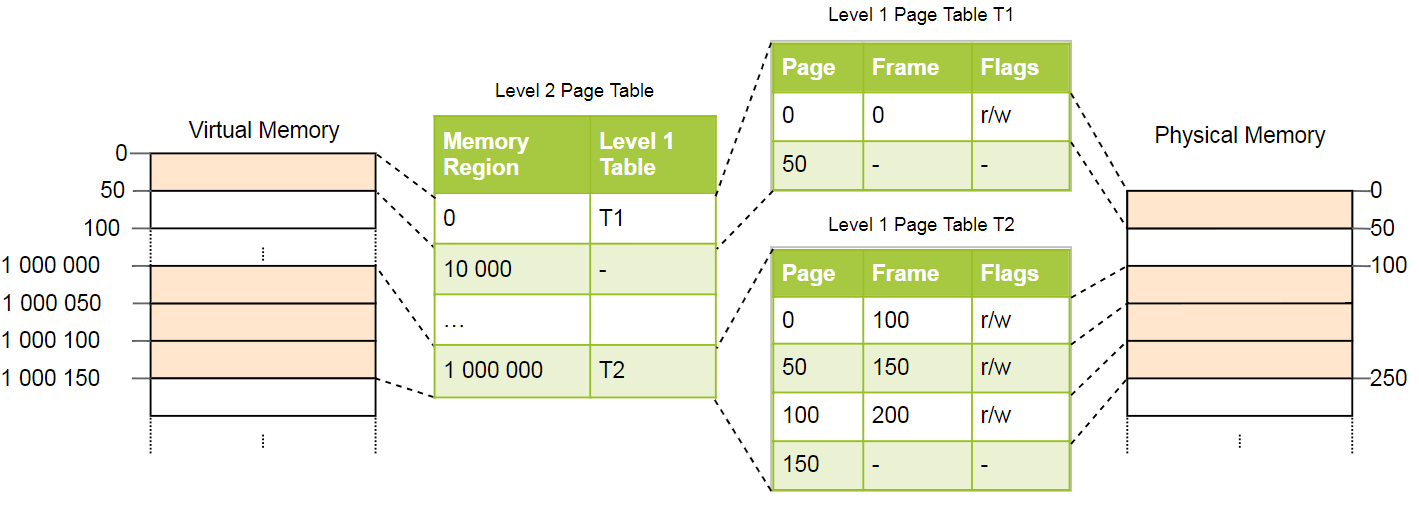
La page 0 tombe dans la première zone de
10_000 octets, elle utilise donc le premier enregistrement dans la table de pages du deuxième niveau. Cette entrée pointe vers le tableau de page T1 de premier niveau, qui détermine que la page 0 fait référence au cadre 0.
Les pages
1_000_000 ,
1_000_050 et
1_000_100 tombent dans la région du 100e octet de
10_000 , elles utilisent donc le 100e enregistrement du tableau de pages de niveau 2. Cet enregistrement pointe vers un autre premier tableau de niveau T2, qui traduit trois pages en cadres 100, 150 et 200. Remarque que l'adresse de page dans les tables du premier niveau ne contient pas de décalage de région, par conséquent, par exemple, l'enregistrement pour la page
1_000_050 n'est que de
50 .
Nous avons encore 100 entrées vides dans le tableau de deuxième niveau, mais c'est beaucoup moins que le million précédent. La raison de ces économies est que vous n'avez pas besoin de créer des tables de pages de premier niveau pour des zones de mémoire
10_000 entre
10_000 et
1_000_000 .
Le principe des tables à deux niveaux peut être étendu à trois, quatre niveaux ou plus. En général, un tel système est appelé une table de pages à
plusieurs niveaux ou
hiérarchique .
Connaissant l'organisation des pages et les tables à plusieurs niveaux, vous pouvez voir comment l'organisation des pages est implémentée dans l'architecture x86_64 (nous supposons que le processeur s'exécute en mode 64 bits).
Organisation de la page sur x86_64
L'architecture x86_64 utilise une table à quatre niveaux avec une taille de page de 4 Ko. Quel que soit le niveau, chaque table de pages comporte 512 éléments. Chaque enregistrement a une taille de 8 octets, donc la taille des tables est de 512 × 8 octets = 4 Ko.

Comme vous pouvez le voir, chaque index de table contient 9 bits, ce qui est logique, car les tables ont 2 ^ 9 = 512 entrées. Les 12 derniers bits sont le décalage de page de 4 kilo-octets (2 ^ 12 octets = 4 Ko). Les bits 48 à 64 sont ignorés, donc x86_64 n'est en fait pas un système 64 bits, mais ne prend en charge que les adresses 48 bits. Il est prévu d'étendre la taille de l'adresse à 57 bits via une
table de pages à 5 niveaux , mais un tel processeur n'a pas encore été créé.
Bien que les bits 48 à 64 soient ignorés, ils ne peuvent pas être définis sur des valeurs arbitraires. Tous les bits de cette plage doivent être des copies du bit 47 afin de conserver des adresses uniques et de permettre une extension future, par exemple, vers une table de pages à 5 niveaux. Cela s'appelle une extension de signe, car elle est très similaire à
une extension de signe dans du code supplémentaire . Si l'adresse n'est pas correctement développée, le CPU lève une exception.
Exemple de conversion
Voyons un exemple du fonctionnement de la traduction d'adresses:
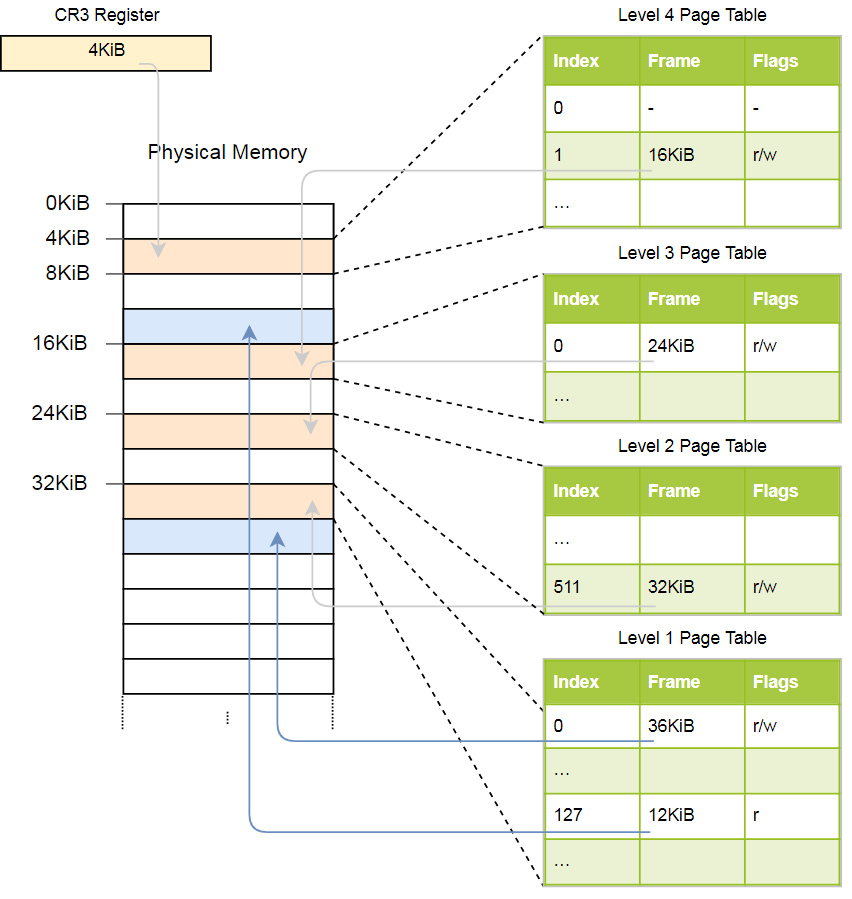
L'adresse physique de la table de pages active actuelle des pages de niveau 4, qui est la table racine des pages de pages de ce niveau, est stockée dans le
CR3 . Chaque entrée de table de pages pointe ensuite sur le cadre physique de la table de niveau suivant. Une entrée de tableau de niveau 1 indique le cadre affiché. Veuillez noter que toutes les adresses dans les tables de pages sont physiques et non virtuelles, car sinon le CPU devra convertir ces adresses (ce qui peut conduire à une récursion infinie).
La hiérarchie ci-dessus convertit deux pages (en bleu). D'après les indices, nous pouvons conclure que les adresses virtuelles de ces pages sont
0x803fe7f000 et
0x803FE00000 . Voyons ce qui se passe lorsqu'un programme essaie de lire la mémoire à l'adresse
0x803FE7F5CE . Tout d'abord, convertissez l'adresse en binaire et déterminez les index de table de pages et le décalage de l'adresse:

En utilisant ces index, nous pouvons maintenant parcourir la hiérarchie des tables de pages et trouver le cadre correspondant:
- Lisez l'adresse de la table de quatrième niveau dans le
CR3 . - L'indice du quatrième niveau est 1, nous examinons donc l'enregistrement avec l'indice 1 dans ce tableau. Elle dit qu'une table de niveau 3 est stockée à 16 Ko.
- Nous chargeons la table de troisième niveau à partir de cette adresse et examinons l'enregistrement avec l'index 0, qui pointe vers la table de deuxième niveau à 24 Ko.
- L'index du deuxième niveau est 511, nous recherchons donc le dernier enregistrement sur cette page pour connaître l'adresse du tableau du premier niveau.
- À partir de l'entrée avec l'index 127 dans la table de premier niveau, nous découvrons enfin que la page correspond à un cadre de 12 Ko ou 0xc000 au format hexadécimal.
- La dernière étape consiste à ajouter un décalage à l'adresse de trame pour obtenir l'adresse physique: 0xc000 + 0x5ce = 0xc5ce.
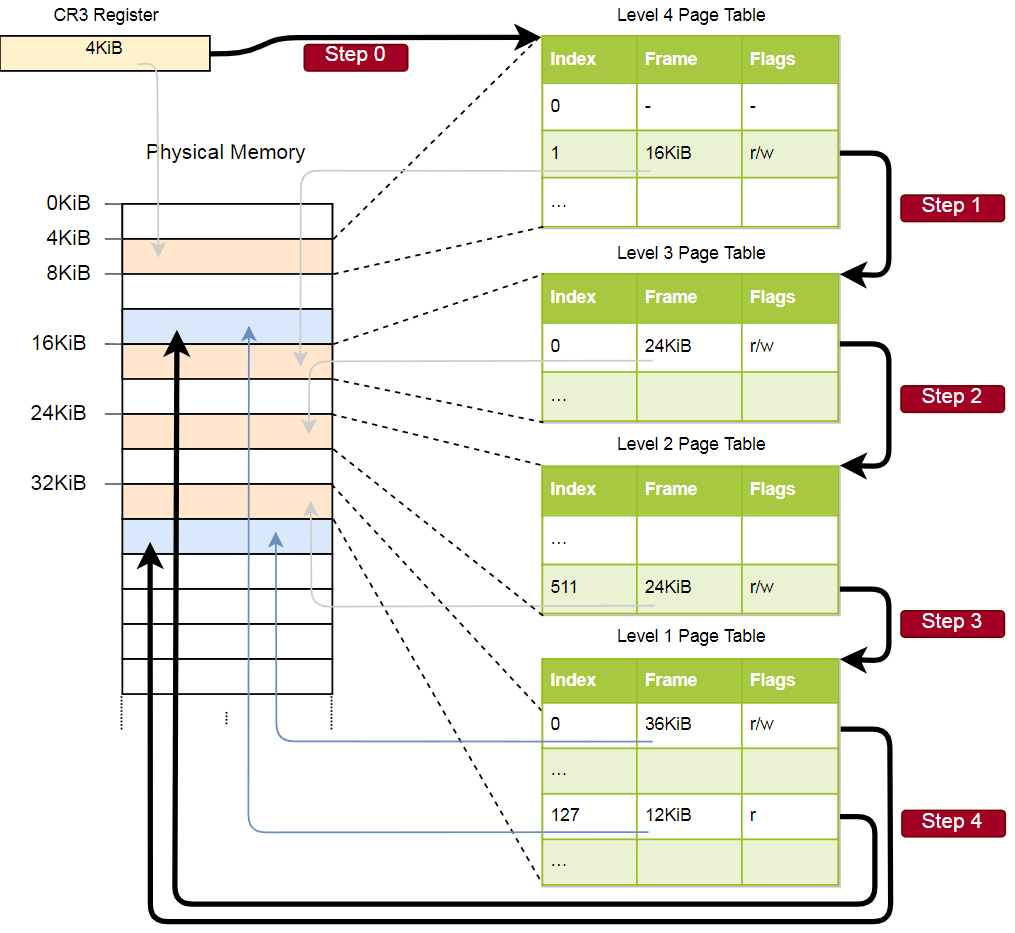
Pour la page du tableau du premier niveau, l'indicateur
r est spécifié, c'est-à-dire que seule la lecture est autorisée. Une exception sera levée au niveau matériel si nous essayons d'enregistrer là-bas. Les autorisations des tables de niveau supérieur s'étendent aux niveaux inférieurs, donc si nous définissons l'indicateur de lecture seule au troisième niveau, aucune page de niveau inférieur ultérieure ne sera accessible en écriture, même si les indicateurs permettant l'écriture y sont indiqués.
Bien que cet exemple utilise une seule instance de chaque table, généralement dans chaque espace d'adressage, il existe plusieurs instances de chaque niveau. Maximum:
- une table du quatrième niveau,
- 512 tables du troisième niveau (puisqu'il y a 512 enregistrements dans la table du quatrième niveau),
- 512 * 512 tables de deuxième niveau (puisque chacune des tables de troisième niveau a 512 entrées), et
- 512 * 512 * 512 tables du premier niveau (512 enregistrements pour chaque table du deuxième niveau).
Format de table de page
Dans l'architecture x86_64, les tables de pages sont essentiellement des tableaux de 512 entrées. Dans la syntaxe Rust:
#[repr(align(4096))] pub struct PageTable { entries: [PageTableEntry; 512], }
Comme indiqué dans l'attribut
repr , les tableaux doivent être alignés sur la page, c'est-à-dire sur la bordure de 4 Ko. Cette exigence garantit que le tableau remplit toujours de manière optimale la page entière, ce qui rend les entrées très compactes.
La taille de chaque enregistrement est de 8 octets (64 bits) et le format suivant:
| Bit (s) | Le titre | Valeur |
|---|
| 0 | présent | page en mémoire |
| 1 | accessible en écriture | enregistrement autorisé |
| 2 | accessible à l'utilisateur | si le bit n'est pas défini, seul le noyau a accès à la page |
| 3 | écrire via la mise en cache | écrire directement dans la mémoire |
| 4 | désactiver le cache | désactiver le cache pour cette page |
| 5 | accédé | Le CPU définit ce bit lorsque la page est en cours d'utilisation. |
| 6 | sale | Le CPU définit ce bit lors de l'écriture sur la page |
| 7 | énorme page / null | le bit zéro dans P1 et P4 crée des pages de 1 Ko dans P3, une page de 2 Mo dans P2 |
| 8 | global | la page n'est pas remplie depuis le cache lors de la commutation de l'espace d'adressage (le bit PGE du registre CR4 doit être défini) |
| 9-11 | disponible | OS peut les utiliser librement |
| 12-51 | adresse physique | adresse physique 52 bits alignée sur la page du cadre ou du tableau de pages suivant |
| 52-62 | disponible | OS peut les utiliser librement |
| 63 | pas d'exécution | interdit l'exécution de code sur cette page (le bit NXE doit être défini dans le registre EFER) |
Nous voyons que seuls les bits 12-51 sont utilisés pour stocker l'adresse physique de la trame, et le reste fonctionne comme des drapeaux ou peut être librement utilisé par le système d'exploitation. Cela est possible car nous pointons toujours soit vers une adresse alignée sur 4096 octets, soit vers une page de tableaux alignée, soit vers le début du cadre correspondant. Cela signifie que les bits 0-11 sont toujours nuls, donc ils ne peuvent pas être stockés, ils sont simplement réinitialisés au niveau matériel avant d'utiliser l'adresse. Il en va de même pour les bits 52 à 63, car l'architecture x86_64 ne prend en charge que les adresses physiques 52 bits (et uniquement les adresses virtuelles 48 bits).
Examinons de plus près les drapeaux disponibles:
- Le drapeau
present distingue les pages affichées des pages non affichées. Il peut être utilisé pour enregistrer temporairement des pages sur le disque lorsque la mémoire principale est pleine. Lors du prochain accès à la page, une exception PageFault spéciale se produit, à laquelle le système d'exploitation répond en échangeant la page du disque - le programme continue. - Les indicateurs en
writable et no execute déterminent si le contenu de la page est accessible en écriture ou contient des instructions exécutables, respectivement. - Les drapeaux
accessed et dirty sont automatiquement définis par le processeur lors de la lecture ou de l'écriture sur la page. Le système d'exploitation peut utiliser ces informations, par exemple, s'il échange des pages ou lorsqu'il vérifie si le contenu de la page a changé depuis le dernier pompage sur le disque. - Les indicateurs d'
write through caching et de disable cache vous permettent de gérer le cache pour chaque page individuellement. - L'indicateur
user accessible rend la page accessible pour le code à partir de l'espace utilisateur, sinon elle n'est disponible que pour le noyau. Cette fonction peut être utilisée pour accélérer les appels système tout en conservant le mappage d'adresses pour le noyau pendant l'exécution du programme utilisateur. Cependant, la vulnérabilité Spectre permet à ces pages d'être lues par des programmes depuis l'espace utilisateur. global , (. TLB ) (address space switch). user accessible .huge page , 2 3 . 512 : 2 = 512 × 4 , 1 = 512 × 2 . .
L'architecture x86_64 définit le format des tables de pages et de leurs enregistrements , nous n'avons donc pas à créer ces structures nous-mêmes.Tampon de traduction associatif (TLB)
En raison des quatre niveaux, chaque traduction d'adresse nécessite quatre accès à la mémoire. Pour des raisons de performances, x86_64 met en cache les dernières traductions dans le soi-disant tampon de traduction associatif (TLB). Cela vous permet d'ignorer la conversion si elle est toujours dans le cache.Contrairement aux autres caches de processeur, TLB n'est pas complètement transparent, ne met pas à jour ni ne supprime les conversions lors de la modification du contenu des tableaux de pages. Cela signifie que le noyau doit mettre à jour le TLB lui-même chaque fois qu'il modifie la table de pages. Pour ce faire, il existe une instruction CPU spéciale appelée invlpg(invalider la page), qui supprime la traduction de la page spécifiée du TLB, de sorte que la prochaine fois, elle sera rechargée à partir de la table des pages. TLB est complètement effacé par le rechargement du registreCR3qui imite un commutateur d'espace d'adressage. Les deux options sont disponibles via le module tlb dans Rust.Il est important de ne pas oublier de nettoyer le TLB après chaque changement de table de pages, sinon le CPU continuera à utiliser l'ancienne traduction, ce qui entraînera des erreurs imprévisibles très difficiles à déboguer.Implémentation
Nous n'avons pas mentionné une chose: notre cœur prend déjà en charge l'organisation des pages . Le chargeur de démarrage de l'article «Minimal Kernel on Rust» a déjà établi une hiérarchie à quatre niveaux qui mappe chaque page de notre noyau à un cadre physique, car l'organisation des pages est requise en mode 64 bits sur x86_64.Cela signifie que dans notre cœur, toutes les adresses mémoire sont virtuelles. L'accès au tampon VGA à l'adresse 0xb8000n'a fonctionné que parce que l'identifiant du chargeur de démarrage a traduit cette page en mémoire, c'est-à-dire qu'il a mappé la page virtuelle 0xb8000sur le cadre physique 0xb8000.Grâce à l'organisation des pages, le noyau est déjà relativement sûr: chaque accès au-delà de la mémoire autorisée provoque une erreur de page et ne permet pas d'écrire dans la mémoire physique. Le chargeur a même défini les autorisations d'accès correctes pour chaque page: seules les pages avec du code seront exécutables, et seules les pages avec des données sont disponibles pour l'écritureErreurs de page (PageFault)
Essayons d'appeler PageFault en accédant à la mémoire en dehors du noyau. Tout d'abord, créez un gestionnaire d'erreurs et enregistrez-le dans notre IDT pour voir une exception spécifique au lieu d'une double erreur de type général:
Si la page échoue, le CPU définit automatiquement la casse CR2. Il contient l'adresse virtuelle de la page à l'origine de l'échec. Pour lire et afficher cette adresse, utilisez la fonction Cr2::read. En règle générale, le type PageFaultErrorCodedonne plus d'informations sur le type d'accès à la mémoire qui a provoqué l'erreur, mais un code d'erreur non valide est transmis en raison du bogue LLVM , nous ignorerons donc ces informations pour l'instant. L'exécution du programme ne peut pas se poursuivre tant que nous n'avons pas résolu l'erreur de page hlt_loop.Maintenant, nous avons accès à la mémoire en dehors du noyau:
Après le démarrage, nous voyons que le gestionnaire d'erreur de page est appelé: Le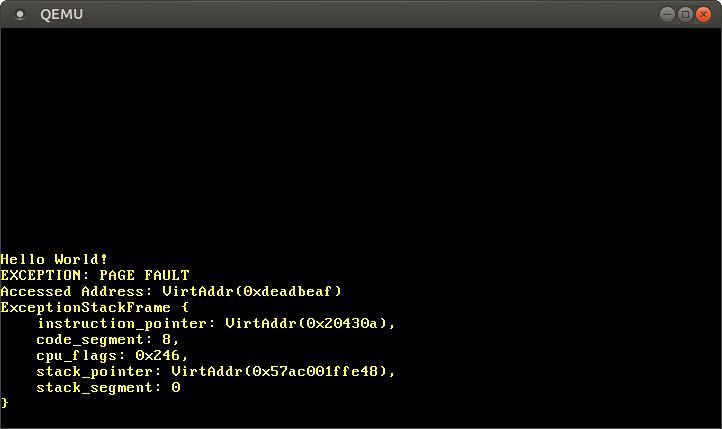 registre
registre CR2contient vraiment l'adresse à laquelle 0xdeadbeafnous voulions accéder.Le pointeur d'instruction actuel est 0x20430a, nous savons donc que cette adresse pointe vers une page de code. Les pages de codes sont affichées par le chargeur en lecture seule, donc la lecture à partir de cette adresse fonctionne et l'écriture provoquera une erreur. Essayez de changer le pointeur 0xdeadbeafen 0x20430a:
Si nous commentons la dernière ligne, nous pouvons nous assurer que la lecture fonctionne et que l'écriture provoque une erreur PageFault.Accès aux tableaux de pages
Jetez maintenant un œil aux tables de pages du noyau:
La fonction Cr3::readde x86_64retourne du registre la CR3table active actuelle des pages du quatrième niveau. Un couple revient PhysFrameet Cr3Flags. Nous ne sommes intéressés que par le premier.Après le démarrage, on voit ce résultat:Level 4 page table at: PhysAddr(0x1000)Ainsi, actuellement, la table active des pages du quatrième niveau est stockée en mémoire physique à l'adresse 0x1000indiquée par le type PhysAddr. Maintenant, la question est: comment accéder à cette table depuis le noyau?Avec l'organisation des pages, l'accès direct à la mémoire physique n'est pas possible, sinon les programmes pourront facilement contourner la protection et accéder à la mémoire des autres programmes. Ainsi, le seul moyen d'accéder à ces informations consiste à utiliser une page virtuelle, qui est traduite en un cadre physique sur0x1000. Il s'agit d'un problème typique car le noyau doit accéder régulièrement aux tables de pages, par exemple, lors de l'allocation d'une pile pour un nouveau thread.Les solutions à ce problème seront décrites en détail dans le prochain article. Pour l'instant, disons simplement que le chargeur utilise une méthode appelée tables de pages récursives . La dernière page de l'espace d'adressage virtuel est 0xffff_ffff_ffff_f000, nous l'utilisons pour lire certaines entrées de ce tableau:
u64 . , 8 (64 ),
u64 .
for 10 .
offset .
:
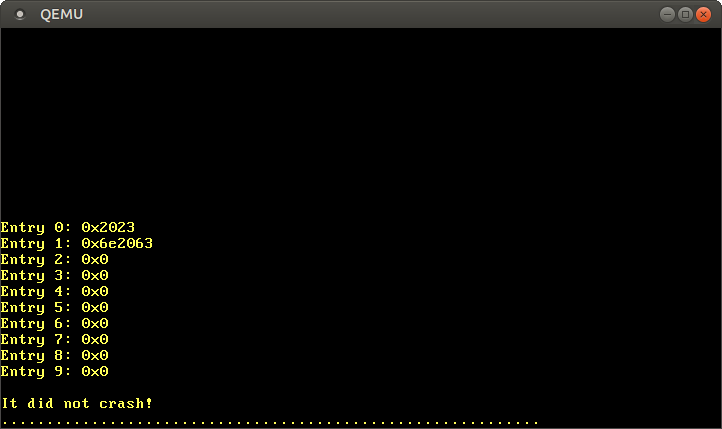
,
0x2023 0
present ,
writable ,
accessed 0x2000 . 1
0x6e2000 ,
dirty. Les entrées 2 à 9 étant manquantes, ces plages d'adresses virtuelles ne sont mappées à aucune adresse physique.Au lieu de travailler directement avec des pointeurs dangereux, vous pouvez utiliser un type PageTablede x86_64:
0xffff_ffff_ffff_f000 , Rust. - , , .
&PageTable , ,
.
x86_64 , :

— 0 1 3. ,
0x2000 0x6e5000 , . .
Résumé
L'article présente deux méthodes de protection de la mémoire: la segmentation et l'organisation des pages. La première méthode utilise des zones de mémoire de taille variable et souffre d'une fragmentation externe, la seconde utilise des pages de taille fixe et permet un contrôle beaucoup plus précis des droits d'accès.Une organisation de page stocke les informations de traduction de page dans des tableaux d'un ou plusieurs niveaux. L'architecture x86_64 utilise des tables à quatre niveaux avec une taille de page de 4 Ko. L'équipement contourne automatiquement les tables de pages et met en cache les résultats de la conversion dans le tampon de traduction associatif (TLB). Lors du changement de tables de pages, il doit être forcé à nettoyer.Nous avons appris que notre cœur prend déjà en charge l'organisation des pages et que l'accès non autorisé à la mémoire supprime PageFault. Nous avons essayé d'accéder aux tables de pages actuellement actives, mais nous avons réussi à accéder uniquement à la table de quatrième niveau, car les adresses de page stockent des adresses physiques, et nous ne pouvons pas y accéder directement à partir du noyau.Et ensuite?
L'article suivant est basé sur les fondements fondamentaux que nous avons maintenant appris. Pour accéder aux tables de pages à partir du noyau, une technique avancée appelée tables de pages récursives est utilisée pour parcourir la hiérarchie des tables et implémenter la traduction d'adresses programmatique. L'article explique également comment créer de nouvelles traductions dans des tableaux de pages.