Début 2018, nous avons démarré activement le processus de digitalisation de la production et des processus dans l'entreprise. Dans le secteur pétrochimique, il ne s'agit pas seulement d'une tendance de la mode, mais d'une nouvelle étape évolutive vers l'augmentation de l'efficacité et de la compétitivité. Compte tenu des spécificités de l'entreprise qui, sans aucune digitalisation, affiche de bons résultats économiques, les digitaliseurs sont confrontés à une tâche difficile: changer les processus établis dans l'entreprise est une tâche assez laborieuse.
Notre digitalisation a commencé par la création de deux centres et de leurs blocs fonctionnels correspondants.
Il s'agit de la «fonction technologie numérique», qui comprend tous les domaines de produits: numérisation des processus, IIoT et analytique avancée, ainsi qu'un centre de gestion des données devenu un domaine indépendant.

Et la principale tâche du bureau de données est de mettre pleinement en œuvre la culture de la prise de décision basée sur les données (oui, oui, décision basée sur les données), ainsi que, en principe, de rationaliser tout ce qui concerne le travail avec les données: analyse, traitement , stockage et rapports. La particularité est que tous nos outils numériques devront non seulement utiliser activement leurs propres données, c'est-à-dire celles qu'ils génèrent eux-mêmes (par exemple, détours mobiles ou capteurs IIoT), mais aussi des données externes, avec une compréhension claire de l'endroit et des raisons pour lesquelles elles sont nécessaires à utiliser.
Je m'appelle Artyom Danilov, je suis le chef du département Infrastructure et Technologie de SIBUR, dans ce post, je vais vous dire comment et sur quoi nous construisons un grand système de traitement et de stockage des données pour l'ensemble du SIBUR. Pour commencer, nous ne parlerons que de l'architecture de haut niveau et de la façon dont vous pouvez faire partie de notre équipe.
Voici les domaines qui incluent le travail dans un bureau de données:
1. Travailler avec des donnéesLes gars qui sont activement impliqués dans l'inventaire et le catalogage de nos données travaillent ici. Ils comprennent les besoins d'une fonction particulière, peuvent déterminer quel type d'analyse peut être nécessaire, quelles mesures doivent être surveillées pour prendre des décisions et comment les données sont utilisées dans un domaine d'activité particulier.
2. BI et visualisation des donnéesLa direction est étroitement liée à la première et vous permet de visualiser les résultats du travail des gars de la première équipe.
3. Direction du contrôle de la qualité des donnéesIci, des outils de contrôle de la qualité des données sont introduits et toute la méthodologie d'un tel contrôle est mise en œuvre. En d'autres termes, les gars d'ici mettent en œuvre un logiciel, rédigent divers contrôles et tests, comprennent comment les vérifications croisées entre les différents systèmes se produisent, notent les fonctions des employés responsables de la qualité des données et établissent également une méthodologie commune.
4. Gestion de l'INSNous sommes une grande entreprise. Nous avons de nombreux types de répertoires - et de sous-traitants, et de matériaux, et un répertoire d'entreprises ... En général, croyez-moi, il y a plus qu'assez de répertoires.
Lorsqu'une entreprise achète activement quelque chose pour ses activités, elle dispose généralement de processus spéciaux pour remplir ces répertoires. Sinon, le chaos atteindra un niveau tel qu'il sera impossible de travailler à partir du mot «complètement». Nous avons également un tel système (MDM).
Voici les problèmes. Supposons que, dans l'une des divisions régionales, dont nous avons beaucoup, les employés s'assoient et saisissent des données dans le système. Contribuez à la main, avec toutes les conséquences découlant de cette méthode. Autrement dit, ils doivent entrer des données, vérifier que tout est arrivé dans le système sous la bonne forme, sans doublons. Dans le même temps, certaines choses, dans le cas de remplir certains détails et champs obligatoires, vous devez rechercher indépendamment et google. Par exemple, vous avez un NIF d'entreprise et vous avez besoin d'autres informations - vous consultez les services spéciaux et le registre.
Toutes ces données, bien sûr, sont déjà quelque part, il serait donc juste de les extraire automatiquement.
Auparavant, l'entreprise n'avait en principe pas de poste unique, une équipe claire qui le ferait. Il y avait de nombreuses divisions dispersées qui saisissaient manuellement les données. Mais il est généralement difficile pour de telles structures de formuler exactement quoi et où exactement dans le processus de travail avec les données doit être changé pour que tout soit parfait. Par conséquent, nous examinons le format et la structure de gestion de l'INS.
5. Mise en œuvre de l'entrepôt de données (nœud de données)C'est exactement ce que nous avons commencé à faire dans ce domaine.
Définissons immédiatement les termes, sinon les phrases que j'utilise peuvent se croiser avec d'autres concepts. En gros, nœud de données = lac de données + entrepôt de données. Un peu plus loin, je vais le révéler plus en détail.
L'architecture
Tout d'abord, nous avons essayé de déterminer avec quel type de données travailler - quels systèmes sont là, quels capteurs. Nous avons compris ce que serait le streaming de données (c'est ce que les entreprises elles-mêmes génèrent à partir de tous leurs équipements, c'est IIoT et ainsi de suite) et les systèmes classiques, différents CRM, ERP et similaires.
Nous avons réalisé que les données dans les systèmes actuels ne seront pas suffisamment directes pour être très volumineuses, mais avec l'introduction des outils numériques et de l'IIoT, il y en aura beaucoup. Et il y aura également des données très hétérogènes des systèmes comptables classiques. Par conséquent, ils ont proposé l'architecture d'un tel plan.

Plus de détails sur les blocs.
Stockage
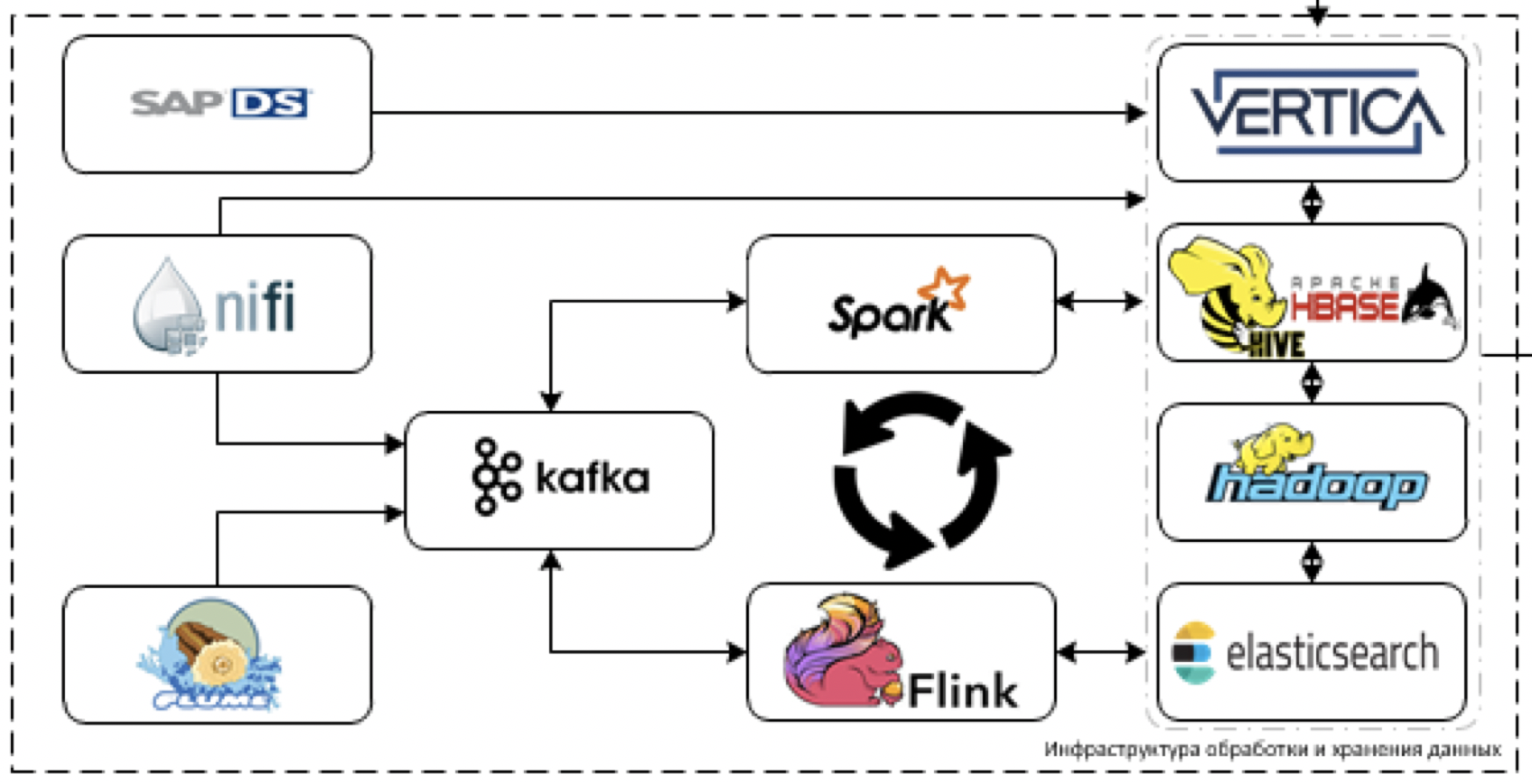
C'est le cœur de notre plateforme. Ce qui est utilisé pour traiter et stocker des données. Le défi consiste à télécharger les données de plus de 60 systèmes différents lorsqu'ils commencent à les fournir. Autrement dit, il existe généralement toutes les données qui peuvent être utiles pour prendre certaines décisions.
Commençons par l'extraction et le traitement des données. À ces fins, nous prévoyons d'utiliser l'outil NiFi ETL pour le streaming et les données par paquets, ainsi que des outils de traitement du streaming: Flume pour la réception et le décodage des données primaires, Kafka pour la mise en mémoire tampon, Flink et Spark Streaming comme principaux outils de traitement des flux de données.
Le plus difficile à travailler avec les systèmes de pile SAP. Vous devez récupérer les données de SAP à l'aide d'un outil ETL distinct - SAP Data Services.
En tant qu'outils de stockage, nous prévoyons d'utiliser la plate-forme Cloudera Hadoop (HDFS, HBASE, Hive, Impala elle-même), le SGBD analytique Vertica et, pour les cas individuels, elasticsearch.
Fondamentalement, nous utilisons la pile la plus avancée. Oui, vous pouvez essayer de nous lancer des tomates et de narguer ce que nous appelons la pile la plus moderne, mais en fait - ça l'est.
Nous ne sommes pas limités au développement hérité, mais nous ne pouvons pas utiliser le dernier cri dans une solution industrielle en raison de l'orientation d'entreprise explicite de notre plate-forme. Par conséquent, nous ne traînons peut-être pas Horton, mais nous nous limitons à Clouder, dans la mesure du possible, nous essayons certainement de faire glisser un outil plus récent.

SAS Data Quality est utilisé pour contrôler la qualité des données, et Airflow est utilisé pour gérer toutes ces qualités. Nous surveillons l'ensemble de la plateforme via la pile ELK. Nous prévoyons de faire la visualisation pour la plupart sur Tableau, certains rapports complètement statiques sur SAP BO.
Nous comprenons déjà qu'une partie des tâches ne peut pas être réalisée grâce à des solutions BI standard, car une visualisation en temps réel très sophistiquée avec de nombreux contrôles en carton est requise. Par conséquent, nous écrirons notre propre cadre de visualisation, qui pourrait être intégré dans les produits numériques en cours de développement.
À propos de la plateforme numérique
Si vous regardez un peu plus largement, maintenant nos collègues de la fonction technologie numérique construisent une plate-forme numérique unique dont la tâche est le développement rapide de nos propres applications.
Le lac de données est l'un des éléments de cette plateforme.
Dans le cadre de cette activité, nous comprenons que nous devrons mettre en œuvre une interface pratique pour accéder aux données analytiques. Par conséquent, nous prévoyons de mettre en œuvre l'API de données et le modèle d'objet de production pour un accès plus pratique aux données de production.
Que faisons-nous d'autre et de qui avons-nous besoin
En plus du stockage et du traitement des données, tout l'apprentissage automatique, ainsi que le cadre IIoT, fonctionneront sur notre plate-forme. Le lac servira à la fois de source de données pour les modèles de formation et de travail et de capacité pour les modèles de travail. Un framework ML qui fonctionnera au-dessus de la plateforme est déjà prêt.

En ce moment, j'ai une équipe, un couple d'architectes et 6 développeurs, nous recherchons donc activement de nouvelles personnes (j'ai besoin d'
architectes de données et d'
ingénieurs de données ) qui nous aideront dans le développement de la plateforme. Vous n'avez pas à fouiller dans l'héritage (l'héritage n'est ici qu'à l'entrée des systèmes), la pile est fraîche.
C'est là que les subtilités seront - c'est dans les intégrations. Connecter l'ancien avec le nouveau, afin qu'il fonctionne bien et résout les problèmes, est un défi. En outre, il sera nécessaire d'inventer, d'élaborer et de suspendre un tas de métriques différentes.
La collecte de données est effectuée à partir de tous les principaux systèmes - 1C, SAP et un tas de tout le reste. Sur la base des données collectées ici, toutes les analyses, toutes les prévisions, tous les rapports numériques seront construits.
En bref, nous voulons que les données fonctionnent vraiment bien. Par exemple, le marketing et les ventes - ils ont des gens qui collectent toutes les statistiques à la main. Autrement dit, ils sont assis et à partir de 5 systèmes différents pompent des données disparates dans différents formats, les chargent à partir de 5 programmes différents, puis déchargent tout cela dans Excel. Ensuite, ils résument les informations dans des tableaux Excel unifiés, en quelque sorte ils essaient de faire de la visualisation.
En général, le wagon prend tout ce temps. Nous voulons résoudre de tels problèmes avec notre plateforme. Et dans les articles suivants, nous vous expliquerons en détail comment nous avons connecté les éléments ensemble et mis en place le bon fonctionnement du système.
Soit dit en passant, en plus des
architectes et
des ingénieurs de données de cette équipe, nous serons heureux de voir: