Avec la propagation et le développement des réseaux de neurones, il est de plus en plus nécessaire de les utiliser sur des appareils embarqués et de faible puissance, des robots et des drones. Le dispositif Neural Compute Stick en conjonction avec le cadre Intel OpenVINO nous permet de résoudre ce problème en assumant les calculs lourds des réseaux de neurones. Grâce à cela, vous pouvez facilement lancer un classificateur ou un détecteur de réseau neuronal sur un appareil de faible puissance comme le Raspberry Pi en temps quasi réel, sans augmenter considérablement la consommation d'énergie. Dans cet article, je vais vous montrer comment utiliser le framework OpenVINO (en C ++) et le Neural Compute Stick pour lancer un système de détection de visage simple sur le Raspberry Pi.
Comme d'habitude, tout le code est disponible sur
GitHub .

Un peu sur Neural Compute Stick et OpenVINO
À l'été 2017, Intel a publié le dispositif
Neural Compute Stick (NCS), conçu pour exécuter des réseaux de neurones sur des appareils à faible puissance, et après quelques mois, il pouvait être acheté et testé, ce que j'ai fait. NCS est un petit module informatique avec un boîtier de couleur azur (agissant également comme un radiateur), connecté à l'appareil principal via USB. À l'intérieur, entre autres, se trouve l'Intel Myriad
VPU , qui est essentiellement un processeur parallèle à 12 cœurs, affûté pour les opérations se produisant souvent dans les réseaux de neurones. Le NCS n'est pas adapté à la formation de réseaux de neurones, mais l'inférence dans les réseaux de neurones déjà formés est comparable en vitesse à celle sur le GPU. Tous les calculs dans NCS sont effectués sur des nombres flottants 16 bits, ce qui vous permet d'augmenter la vitesse. Le NCS ne nécessite que 1 Watt d'énergie pour fonctionner, c'est-à-dire qu'à 5 V, un courant allant jusqu'à 200 mA est consommé sur le connecteur USB - c'est encore moins que l'appareil photo du Raspberry Pi (250 mA).

Pour travailler avec le premier NCS, le
Neural Compute SDK (NCSDK) a été utilisé: il comprend des outils pour compiler les réseaux de neurones aux formats
Caffe et
TensorFlow au format NCS, des outils pour mesurer leurs performances, ainsi que l'API Python et C ++ pour l'inférence.
Puis une nouvelle version du framework NCS a été publiée:
NCSDK2 . L'API a beaucoup changé, et bien que certains changements me paraissent étranges, il y a eu des innovations utiles. En particulier, une conversion automatique de float 32 bits en float 16 bits en C ++ a été ajoutée (auparavant, des béquilles devaient être insérées sous forme de code de Numpy). Des files d'images et les résultats de leur traitement sont également apparus.
En mai 2018, Intel a publié
OpenVINO (anciennement appelé Intel Computer Vision SDK). Ce cadre est conçu pour lancer efficacement des réseaux de neurones sur divers appareils: processeurs et cartes graphiques Intel,
FPGA , ainsi que le Neural Compute Stick.
En novembre 2018, une nouvelle version de l'accélérateur est sortie:
Neural Compute Stick 2 . La puissance de calcul de l'appareil a été augmentée: dans la description sur le site, ils promettent une accélération jusqu'à 8x, cependant, je n'ai pas pu tester la nouvelle version de l'appareil. L'accélération est obtenue en augmentant le nombre de cœurs de 12 à 16, ainsi qu'en ajoutant de nouveaux dispositifs informatiques optimisés pour les réseaux de neurones. Certes, je n'ai pas trouvé d'informations sur la consommation d'énergie des informations.
La deuxième version de NCS est déjà incompatible avec NCSDK ou NCSDK2: OpenVINO, qui est capable de fonctionner avec de nombreux autres appareils en plus des deux versions de NCS, a passé son autorité. OpenVINO lui-même a de grandes fonctionnalités et comprend les composants suivants:
- Optimiseur de modèle: script Python qui vous permet de convertir les réseaux de neurones des frameworks d'apprentissage en profondeur populaires au format OpenVINO universel. La liste des frameworks supportés: Caffe , TensorFlow , MXNET , Kaldi (framework de reconnaissance vocale), ONNX (format ouvert pour représenter les réseaux de neurones).
- Moteur d'inférence: API C ++ et Python pour l'inférence de réseau neuronal, extrait d'un périphérique d'inférence spécifique. Le code API sera presque identique pour CPU, GPU, FPGA et NCS.
- Un ensemble de plugins pour différents appareils. Les plugins sont des bibliothèques dynamiques qui sont chargées explicitement dans le code du programme principal. Nous sommes plus intéressés par le plugin pour NCS.
- Un ensemble de modèles pré-formés au format universel OpenVINO (la liste complète est ici ). Une impressionnante collection de réseaux de neurones de haute qualité: détecteurs de visages, de piétons, d'objets; reconnaissance de l'orientation des visages, points particuliers des visages, postures humaines; super résolution; et d'autres. Il convient de noter que tous ne sont pas pris en charge par NCS / FPGA / GPU.
- Model Downloader: un autre script qui simplifie le téléchargement de modèles au format OpenVINO sur le réseau (bien que vous puissiez facilement vous en passer).
- Bibliothèque de vision par ordinateur OpenCV optimisée pour le matériel Intel.
- Bibliothèque de vision par ordinateur OpenVX .
- Bibliothèque de calcul Intel pour les réseaux de neurones profonds .
- Bibliothèque Intel Math Kernel pour les réseaux de neurones profonds .
- Un outil pour optimiser les réseaux de neurones pour FPGA (en option).
- Documentation et exemples de programmes.
Dans mes articles précédents, j'ai expliqué comment exécuter le détecteur de visage YOLO sur le NCS
(premier article) , ainsi que comment entraîner votre détecteur de visage SSD et l'exécuter sur le Raspberry Pi et NCS
(deuxième article) . Dans ces articles, j'ai utilisé NCSDK et NCSDK2. Dans cet article, je vais vous dire comment faire quelque chose de similaire, mais en utilisant OpenVINO, je ferai une petite comparaison des deux détecteurs de visage différents et de deux cadres pour les lancer, et je soulignerai quelques pièges. J'écris en C ++, car je pense que de cette façon, vous pouvez obtenir de meilleures performances, ce qui sera important dans le cas du Raspberry Pi.
Installez OpenVINO
Pas la tâche la plus difficile, bien qu'il y ait des subtilités. Au moment de la rédaction, OpenVINO ne prend en charge que Ubuntu 16.04 LTS, CentOS 7.4 et Windows 10. J'ai Ubuntu 18 et j'ai besoin de
petites béquilles pour l'installer. Je voulais également comparer OpenVINO avec NCSDK2, dont l'installation pose également des problèmes: en particulier, il resserre ses versions de Caffe et TensorFlow et peut légèrement casser les paramètres d'environnement. Au final, j'ai décidé de faire le chemin simple et d'installer les deux frameworks dans une machine virtuelle avec Ubuntu 16 (j'utilise
VirtualBox ).
Il convient de noter que pour réussir à connecter NCS à une machine virtuelle, vous devez installer les modules complémentaires invités VirtualBox et activer la prise en charge USB 3.0. J'ai également ajouté un filtre universel pour les périphériques USB, ce qui a permis au NCS de se connecter sans problème (bien que la webcam doive toujours être connectée dans les paramètres de la machine virtuelle). Pour installer et compiler OpenVINO, vous devez créer un compte Intel, choisissez une option de framework (avec ou sans support FPGA) et suivez les
instructions . NCSDK est encore plus simple: il démarre à
partir de GitHub (n'oubliez pas de sélectionner la branche ncsdk2 pour la nouvelle version du framework), après quoi vous devez
make install .
Le seul problème que j'ai rencontré lors de l'exécution de NCSDK2 dans une machine virtuelle est une erreur de la forme suivante:
E: [ 0] dispatcherEventReceive:236 dispatcherEventReceive() Read failed -1 E: [ 0] eventReader:254 Failed to receive event, the device may have reset
Cela se produit à la fin de l'exécution correcte du programme et (il semble) n'affecte rien. Apparemment, c'est un
petit bug lié à VM (cela ne devrait pas être sur Raspberry).
L'installation sur le Raspberry Pi est sensiblement différente. Tout d'abord, assurez-vous que Raspbian Stretch est installé: les deux frameworks ne fonctionnent officiellement que sur ce système d'exploitation. NCSDK2 doit être
compilé en mode API uniquement , sinon il essaiera d'installer Caffe et TensorFlow, ce qui ne plaira probablement pas à votre Raspberry. Dans le cas d'OpenVINO, il existe une
version déjà
assemblée pour Raspberry , dont vous avez seulement besoin de décompresser et de configurer les variables d'environnement. Dans cette version, il n'y a que l'API C ++ et Python, ainsi que la bibliothèque OpenCV, tous les autres outils ne sont pas disponibles. Cela signifie que pour les deux frameworks, les modèles doivent être convertis à l'avance sur une machine avec Ubuntu. Ma
démo de détection de visage fonctionne à la fois sur Raspberry et sur le bureau, j'ai donc ajouté les fichiers de réseau neuronal convertis à mon référentiel GitHub pour faciliter la synchronisation avec Raspberry. J'ai un Raspberry Pi 2 modèle B, mais il devrait décoller avec d'autres modèles.
Il y a une autre subtilité concernant l'interaction du Raspberry Pi et du Neural Compute Stick: si dans le cas d'un ordinateur portable, il suffit de pousser le NCS dans le port USB 3.0 le plus proche, alors pour Raspberry, vous devrez trouver un câble USB, sinon NSC bloquera les trois connecteurs USB restants avec son corps. Il convient également de rappeler que Raspberry possède toutes les versions USB 2.0, de sorte que le taux d'inférence sera inférieur en raison des retards de communication (une comparaison détaillée sera plus tard). Mais si vous souhaitez connecter deux ou plusieurs NCS à Raspberry, vous devrez probablement trouver un concentrateur USB avec une puissance supplémentaire.
À quoi ressemble le code OpenVINO
Assez volumineux. Il y a beaucoup d'actions différentes à faire, en commençant par charger le plug-in et en terminant par l'inférence elle-même - c'est pourquoi j'ai écrit une classe wrapper pour le détecteur. Le code complet peut être consulté sur GitHub, mais ici, je viens d'énumérer les principaux points. Commençons dans l'ordre:
Les définitions de toutes les fonctions dont nous avons besoin se trouvent dans le fichier
InferenceEngine espace de noms
InferenceEngine .
#include <inference_engine.hpp> using namespace InferenceEngine;
Les variables suivantes seront nécessaires tout le temps. nous avons besoin de
inputName et
outputName afin d'adresser l'entrée et la sortie du réseau neuronal. De manière générale, un réseau neuronal peut avoir de nombreuses entrées et sorties, mais dans nos détecteurs, il y en aura une à la fois. La variable
net est le réseau lui-même, la
request est un pointeur vers la dernière demande d'inférence,
inputBlob est un pointeur vers le tableau de données d'entrée du réseau neuronal. Les variables restantes parlent d'elles-mêmes.
string inputName; string outputName; ExecutableNetwork net; InferRequest::Ptr request; Blob::Ptr inputBlob;
Téléchargez maintenant le plugin nécessaire - nous avons besoin de celui qui est responsable de NCS et NCS2, il peut être obtenu sous le nom "MYRIAD". Permettez-moi de vous rappeler que dans le contexte d'OpenVINO, un plugin est juste une bibliothèque dynamique qui se connecte par demande explicite. Le paramètre de la fonction
PluginDispatcher est une liste de répertoires dans lesquels rechercher des plugins. Si vous configurez les variables d'environnement selon les instructions, une ligne vide sera suffisante. Pour référence, les plugins se trouvent dans
[OpenVINO_install_dir]/deployment_tools/inference_engine/lib/ubuntu_16.04/intel64/ InferencePlugin plugin = PluginDispatcher({""}).getPluginByDevice("MYRIAD");
Créez maintenant un objet pour charger le réseau neuronal, considérez sa description et définissez la taille du lot (le nombre d'images traitées simultanément). Un réseau de neurones au format OpenVINO est défini par deux fichiers: un .xml avec une description de la structure et un .bin avec des poids. Alors que nous utiliserons des détecteurs prêts à l'emploi d'OpenVINO, nous en créerons plus tard. Ici
std::string filename est le nom du fichier sans l'extension. Vous devez également garder à l'esprit que le NCS ne prend en charge qu'une taille de lot de 1.
CNNNetReader netReader; netReader.ReadNetwork(filename+".xml"); netReader.ReadWeights(filename+".bin"); netReader.getNetwork().setBatchSize(1);
Ensuite, ce qui se passe:
- Pour entrer dans le réseau neuronal, définissez le type de données sur un caractère non signé 8 bits. Cela signifie que nous pouvons saisir l'image dans le format dans lequel elle provient de la caméra, et InferenceEngine se chargera de la conversion (NCS effectue les calculs au format float 16 bits). Cela accélérera un peu sur le Raspberry Pi - si je comprends bien, la conversion se fait sur le NCS, donc il y a moins de retards dans le transfert de données via USB.
- Nous obtenons les noms d'entrée et de sortie, afin que nous puissions y accéder plus tard.
- Nous obtenons la description des sorties (c'est une carte du nom de la sortie à un pointeur vers un bloc de données). Nous obtenons un pointeur sur le bloc de données de la première sortie (unique).
- On obtient sa taille: 1 x 1 x nombre maximum de détections x longueur de la description de la détection (7). À propos du format de la description des détections - plus tard.
- Définissez le format de sortie sur flottant 32 bits. Encore une fois, la conversion de float 16 bits prend en charge InferenceEngine.
Maintenant, le point le plus important: nous chargeons le réseau de neurones dans le plugin (c'est-à-dire dans NCS). Apparemment, la compilation au format souhaité est à la volée. Si le programme plante sur cette fonction, le réseau neuronal n'est probablement pas adapté à cet appareil.
net = plugin.LoadNetwork(netReader.getNetwork(), {});
Et enfin - nous ferons une inférence d'essai et obtiendrons les tailles d'entrée (cela peut peut-être être fait plus élégamment). Tout d'abord, nous ouvrons une demande d'inférence, puis nous en obtenons un lien vers le bloc de données d'entrée, et nous en demandons déjà la taille.
Essayons de télécharger une image sur NCS. De la même manière, nous créons une demande d'inférence, en obtenons un pointeur vers un bloc de données et à partir de là, nous obtenons un pointeur vers le tableau lui-même. Ensuite, copiez simplement les données de notre image (ici, elles sont déjà réduites à la taille souhaitée). Il est à noter que dans
cv::Mat et
inputBlob mesures sont stockées dans un ordre différent (dans OpenCV, l'index de canal change plus rapidement que tous, dans OpenVINO il est plus lent que tous), donc memcpy est indispensable. Ensuite, nous commençons l'inférence asynchrone.
Pourquoi asynchrone? Cela optimisera l'allocation des ressources. Alors que le NCS considère le réseau de neurones, vous pouvez traiter la trame suivante - cela entraînera une accélération notable sur le Raspberry Pi.
cv::Mat data; ...
Si vous connaissez bien les réseaux de neurones, vous pourriez vous demander à quel point nous mettons à l'échelle les valeurs des pixels d'entrée du réseau de neurones (par exemple, nous portons à la plage
) Le fait est que dans les modèles OpenVINO, cette transformation est déjà incluse dans la description du réseau neuronal, et lorsque nous utiliserons notre détecteur, nous ferons quelque chose de similaire. Et puisque la conversion en float et la mise à l'échelle des entrées sont effectuées par OpenVINO, il suffit de redimensionner l'image.
Maintenant (après avoir fait un travail utile), nous allons compléter la demande d'inférence. Le programme est bloqué jusqu'à ce que les résultats de l'exécution arrivent. Nous obtenons un pointeur sur le résultat.
float * output; ncsCode = request->Wait(IInferRequest::WaitMode::RESULT_READY); output = request->GetBlob(outputName)->buffer().as<float*>();
Il est maintenant temps de réfléchir au format dans lequel le NCS renvoie le résultat du détecteur. Il convient de noter que le format est légèrement différent de ce qu'il était lors de l'utilisation de NCSDK. De manière générale, la sortie du détecteur est en quatre dimensions et a une dimension (1 x 1 x nombre maximum de détections x 7), nous pouvons supposer qu'il s'agit d'un tableau de taille (
maxNumDetectedFaces x 7).
Le paramètre
maxNumDetectedFaces est défini dans la description du réseau neuronal, et il est facile de le modifier, par exemple, dans la description .prototxt du réseau au format Caffe. Plus tôt, nous l'avons obtenu de l'objet représentant le détecteur. Ce paramètre est lié aux spécificités de la classe des détecteurs
SSD (Single Shot Detector) , qui inclut tous les détecteurs NCS pris en charge. Un SSD considère toujours le même (et très grand) nombre de cadres de délimitation pour chaque image, et après avoir filtré les détections avec un faible indice de confiance et supprimé les images qui se chevauchent à l'aide de la suppression non maximale, elles laissent généralement les 100-200 meilleures. C'est précisément ce dont le paramètre est responsable.
Les sept valeurs dans la description d'une détection sont les suivantes:
- le numéro de l'image dans le lot sur lequel l'objet est détecté (dans notre cas, il doit être nul);
- classe d'objet (0 - arrière-plan, à partir de 1 - autres classes, seules les détections avec une classe positive sont retournées);
- confiance en présence de détection (dans la plage );
- coordonnée x normalisée du coin supérieur gauche du cadre de sélection (dans la plage );
- de même - coordonnée y;
- largeur du cadre de délimitation normalisé (dans la plage );
- de même - hauteur;
Code pour extraire les boîtes englobantes de la sortie du détecteur void get_detection_boxes(const float* predictions, int numPred, int w, int h, float thresh, std::vector<float>& probs, std::vector<cv::Rect>& boxes) { float score = 0; float cls = 0; float id = 0;
nous apprenons
numPred partir du détecteur lui-même et
w,h - tailles d'image pour la visualisation.
Maintenant, à quoi ressemble le schéma général d'inférence en temps réel. Nous initialisons d'abord le réseau neuronal et la caméra, démarrons
cv::Mat pour les images brutes et un de plus pour les images réduites à la taille souhaitée. Nous remplissons nos cadres de zéros - cela ajoutera la certitude qu'à un seul démarrage, le réseau neuronal ne trouvera rien. Ensuite, nous commençons le cycle d'inférence:
- Nous chargeons la trame actuelle dans le réseau neuronal à l'aide d'une demande asynchrone - NCS a déjà commencé à fonctionner, et à ce moment nous avons la possibilité de faire un travail utile du processeur principal.
- Nous affichons toutes les détections précédentes sur l'image précédente, dessinons un cadre (si nécessaire).
- Nous obtenons un nouveau cadre de la caméra, le compressons à la taille souhaitée. Pour Raspberry, je recommande d'utiliser l'algorithme de redimensionnement le plus simple - dans OpenCV, il s'agit de l'interpolation des voisins les plus proches. Cela n'affectera pas la qualité des performances du détecteur, mais cela peut ajouter un peu de vitesse. Je reflète également le cadre pour une visualisation facile (en option).
- Il est maintenant temps d'obtenir le résultat avec NCS en remplissant la demande d'inférence. Le programme sera bloqué jusqu'à la réception du résultat.
- Nous traitons de nouvelles détections, sélectionnons des images.
- Le reste: élaboration des frappes, comptage des images, etc.
Comment le compiler
Dans les exemples InferenceEngine, je n'aimais pas les gros fichiers CMake, et j'ai décidé de tout réécrire de manière compacte dans mon Makefile:
g++ $(RPI_ARCH) \ -I/usr/include -I. \ -I$(OPENVINO_PATH)/deployment_tools/inference_engine/include \ -I$(OPENVINO_PATH_RPI)/deployment_tools/inference_engine/include \ -L/usr/lib/x86_64-linux-gnu \ -L/usr/local/lib \ -L$(OPENVINO_PATH)/deployment_tools/inference_engine/lib/ubuntu_16.04/intel64 \ -L$(OPENVINO_PATH_RPI)/deployment_tools/inference_engine/lib/raspbian_9/armv7l \ vino.cpp wrapper/vino_wrapper.cpp \ -o demo -std=c++11 \ `pkg-config opencv --cflags --libs` \ -ldl -linference_engine $(RPI_LIBS)
Cette équipe travaillera sur Ubuntu et Raspbian, grâce à quelques astuces. Les chemins de recherche des en-têtes et des bibliothèques dynamiques que j'ai indiqués pour Raspberry et la machine Ubuntu. Parmi les bibliothèques, en plus d'OpenCV, vous devez également connecter
libinference_engine et
libdl - une bibliothèque pour relier dynamiquement d'autres bibliothèques, elle est nécessaire pour charger le plugin. En même temps,
libmyriadPlugin lui
libmyriadPlugin même
libmyriadPlugin pas besoin d'être spécifié. Entre autres choses, pour Raspberry, je connecte également la bibliothèque
Raspicam pour travailler avec la caméra (c'est
$(RPI_LIBS) ). J'ai également dû utiliser la norme C ++ 11.
Par ailleurs, il convient de noter que lors de la compilation sur Raspberry, l'
-march=armv7-a est nécessaire (c'est
$(RPI_ARCH) ). Si vous ne le spécifiez pas, le programme se compilera, mais se bloquera avec un défaut de segmentation silencieux. Vous pouvez également ajouter des optimisations en utilisant
-O3 , cela augmentera la vitesse.
Quels sont les détecteurs
NCS ne prend en charge que les détecteurs SSD Caffe de la boîte, bien qu'avec quelques astuces sales, j'ai réussi à exécuter
YOLO à partir du format Darknet dessus.
Le Single Shot Detector (SSD) est une architecture populaire parmi les réseaux neuronaux légers, et avec l'aide de différents encodeurs (ou réseaux dorsaux), vous pouvez varier de manière assez flexible le rapport de vitesse et de qualité.
Je vais expérimenter avec différents détecteurs de visage:
- YOLO, extrait d'ici , converti d'abord au format Caffe, puis au format NCS (uniquement avec NCSDK). Image 448 x 448.
- Mon détecteur Mobilenet + SSD, dont j'ai parlé de la formation dans une publication précédente . J'ai toujours une version recadrée de ce détecteur, qui ne voit que les petits visages, et en même temps un peu plus vite. Je vérifierai la version complète de mon détecteur sur NCSDK et OpenVINO. Image 300 x 300.
- Détecteur face-detection-adas-0001 d'OpenVINO: MobileNet + SSD. Image 384 x 672.
- Détecteur OpenVINO face-detection-retail-0004: SqueezeNet + SSD léger. Image 300 x 300.
Pour les détecteurs d'OpenVINO, il n'y a pas d'échelles au format Caffe ou NCSDK, donc je ne peux les lancer qu'en OpenVINO.
Transformez votre détecteur au format OpenVINO
J'ai deux fichiers au format Caffe: .prototxt avec une description du réseau et .caffemodel avec des poids. J'ai besoin d'obtenir deux fichiers d'eux au format OpenVINO: .xml et .bin avec une description et des poids, respectivement. Pour ce faire, utilisez le script mo.py d'OpenVINO (aka Model Optimizer):
mo.py \ --framework caffe \ --input_proto models/face/ssd-face.prototxt \ --input_model models/face/ssd-face.caffemodel \ --output_dir models/face \ --model_name ssd-vino-custom \ --mean_values [127.5,127.5,127.5] \ --scale_values [127.5,127.5,127.5] \ --data_type FP16
output_dir spécifie le répertoire dans lequel les nouveaux fichiers seront créés,
model_name est le nom des nouveaux fichiers sans extension,
data_type (FP16/FP32) est le type d'équilibre dans le réseau neuronal (NCS ne prend en charge que FP16). Les
mean_values, scale_values définissent la moyenne et l'échelle de prétraitement des images avant leur lancement dans le réseau neuronal. La conversion spécifique ressemble à ceci:
Dans ce cas, les valeurs sont converties à partir de la plage
à portée
. En général, ce script a beaucoup de paramètres, dont certains sont spécifiques aux frameworks individuels, je vous recommande de consulter le manuel du script.
La distribution OpenVINO pour Raspberry n'a pas de modèles prêts à l'emploi, mais ils sont assez simples à télécharger.
Par exemple, comme ça. wget --no-check-certificate \ https://download.01.org/openvinotoolkit/2018_R4/open_model_zoo/face-detection-retail-0004/FP16/face-detection-retail-0004.xml \ -O ./models/face/vino.xml; \ wget --no-check-certificate \ https://download.01.org/openvinotoolkit/2018_R4/open_model_zoo/face-detection-retail-0004/FP16/face-detection-retail-0004.bin \ -O ./models/face/vino.bin
Comparaison des détecteurs et des cadres
J'ai utilisé trois options de comparaison: 1) NCS + Virtual Machine avec Ubuntu 16.04, processeur Core i7, connecteur USB 3.0; 2) NCS + La même machine, connecteur USB 3.0 + câble USB 2.0 (il y aura plus de retard dans l'échange avec l'appareil); 3) NCS + Raspberry Pi 2 modèle B, Raspbian Stretch, connecteur USB 2.0 + câble USB 2.0.
J'ai commencé mon détecteur avec OpenVINO et NCSDK2, les détecteurs d'OpenVINO uniquement avec leur framework natif, YOLO uniquement avec NCSDK2 (très probablement, il peut également être exécuté sur OpenVINO).
Le tableau FPS pour différents détecteurs ressemble à ceci (les chiffres sont approximatifs):
| Modèle | USB 3.0 | USB 2.0 | Raspberry pi |
|---|
| SSD personnalisé avec NCSDK2 | 10,8 | 9.3 | 7.2 |
| SSD longue portée personnalisé avec NCSDK2 | 11,8 | 10,0 | 7.3 |
| YOLO v2 avec NCSDK2 | 5.3 | 4.6 | 3,6 |
| SSD personnalisé avec OpenVINO | 10,6 | 9,9 | 7,9 |
| OpenVINO face-detection-retail-0004 | 15,6 | 14,2 | 9.3 |
| OpenVINO face-detection-adas-0001 | 5.8 | 5.5 | 3.9 |
Remarque: les performances ont été mesurées pour l'ensemble du programme de démonstration, y compris le traitement et la visualisation des images.YOLO était le plus lent et le plus instable de tous. Il saute très souvent la détection et ne peut pas fonctionner avec des cadres éclairés.
Le détecteur que j'ai formé fonctionne deux fois plus vite, est plus résistant à la distorsion dans les cadres et détecte même les petits visages. Cependant, il ignore parfois la détection et détecte parfois les faux. Si vous en coupez les derniers calques, cela deviendra un peu plus rapide, mais cela cessera de voir de grands visages. Le même détecteur lancé via OpenVINO devient un peu plus rapide lors de l'utilisation de l'USB 2.0, la qualité ne change pas visuellement.
Les détecteurs OpenVINO, bien sûr, sont de loin supérieurs à la fois à YOLO et à mon détecteur. (Je ne commencerais même pas à entraîner mon détecteur si OpenVINO existait sous sa forme actuelle à l'époque). Le modèle Retail-0004 est nettement plus rapide et en même temps ne manque pratiquement pas le visage, mais j'ai réussi à le tromper un peu (bien que la confiance dans ces détections soit faible):
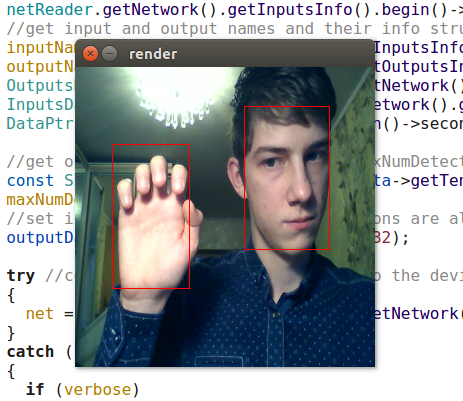 Attaque compétitive de l'intelligence naturelle sur artificielle
Attaque compétitive de l'intelligence naturelle sur artificielleLe détecteur adas-0001 est beaucoup plus lent, mais il fonctionne avec de grandes images et devrait être plus précis. Je n'ai pas remarqué la différence, mais j'ai vérifié des cadres assez simples.
Conclusion
En général, il est très agréable que sur un appareil de faible puissance comme le Raspberry Pi, vous puissiez utiliser des réseaux de neurones, et même en temps quasi réel. OpenVINO fournit des fonctionnalités très étendues pour l'inférence des réseaux de neurones sur de nombreux appareils différents - beaucoup plus large que je l'ai décrit dans l'article. Je pense que Neural Compute Stick et OpenVINO seront très utiles dans mes recherches robotiques.