Version russe
Imaginons que vous développez des appliances matérielles et logicielles. L'appliance se compose de serveurs de distribution personnalisés, de serveurs haut de gamme et de beaucoup de logique métier. Par conséquent, elle doit utiliser du matériel réel. Si vous sortez un appareil cassé, vos utilisateurs ne seront pas satisfaits. Comment faire des versions stables?
J'aimerais partager mon histoire sur la façon dont nous l'avons traitée.
Preuve de concept
Si vous ne connaissez pas un objectif, il sera très difficile d'accomplir la tâche. La première variante de déploiement ressemblait à bash :
make dist for i in abc ; do scp ./result.tar.gz $i:~/ ssh $i "tar -zxvf result.tar.gz" ssh $i "make -C ~/resutl install" done
Le script a été simplifié juste pour montrer l'idée principale: il n'y avait pas de CI / CD. Notre flux était:
- Construit sur l'hôte développeur.
- Déployé pour tester l'environnement pour une démo.
Au stade actuel, la connaissance de la façon dont il a été approvisionné, tous les kludges connus étaient de la magie sale dans l'esprit des développeurs. C'était un vrai problème pour nous en raison de la croissance de l'équipe.
Faites-le
Nous avions utilisé TeamCity pour nos projets et gitlab n'était pas populaire, nous avons donc décidé d'utiliser TeamCity. Nous avons créé manuellement une machine virtuelle. Nous exécutions des tests à l'intérieur de la machine virtuelle.
Il y a eu quelques étapes dans le flux de génération:
- Installez certains utilitaires dans un environnement préparé manuellement.
- Vérifiez que cela fonctionne.
- Si cela vous convient, publiez les RPM.
- Mettre à jour le transfert vers la nouvelle version.
make install && ./libs/run_all_tests.sh make dist make srpm rpmbuild -ba SPECS/xxx-base.spec make publish
Nous avons reçu un résultat temporaire:
- Quelque chose de exécutable était dans la branche principale.
- Cela a fonctionné quelque part.
- Nous avons pu détecter certains problèmes occasionnels.
Ressentez-vous l'odeur?
- Il y avait un enfer de dépendance avec les RPM.
- Chacun avait son propre environnement de développement pour animaux de compagnie.
- Les tests étaient en cours d'exécution dans l'environnement inconnu.
- Il y avait trois entités complètement illimitées: la construction du système d'exploitation, la fourniture des installations et les tests.
Réduisez la magie sale
Nous avons changé les flux et les processus:
- Nous avions créé un méta-package RPM et supprimé l'enfer des dépendances.
- Nous avons créé un modèle de VM de développement via vagrant.
- Nous avons déplacé les scripts bash vers ansible.
- D'une part, nous avons créé un framework de tests d'intégration, mais d'autre part, nous avons utilisé serverspec .
À la suite de l'étape actuelle, nous avons reçu:
- Tous nos environnements de développement étaient identiques.
- Le code de l'application et la logique de mise à disposition ont été synchronisés entre eux.
- Nous avons accéléré le processus d'intégration des nouveaux développeurs.
D'une part, une construction était vraiment lente (environ 30 à 60 minutes), mais d'autre part, elle était assez bonne et a réussi à résoudre la grande majorité des problèmes avant l'assurance qualité manuelle. Cependant, nous avons été confrontés à de nouveaux problèmes différents, c'est-à-dire que nous avons mis à jour le noyau ou annulé un package.
Améliorez-le
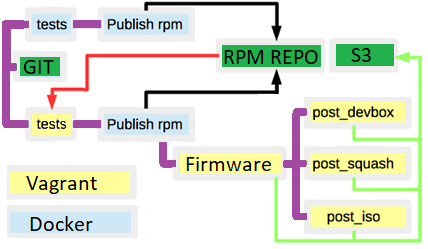
Nous avons résolu de nombreux problèmes différents:
- Les tests d'intégration fonctionnaient de plus en plus lentement car le modèle de machine virtuelle de développement était plus ancien que les RPM réels. Nous reconstruisions le modèle manuellement, puis nous avons décidé de l'automatiser:
- Créez automatiquement un VMDK.
- Attachez le VMDK à une machine virtuelle.
- Emballez la VM et téléchargez-la sur s3.
- En cas de fusion, il n'a pas été possible d'obtenir le statut de génération, par conséquent, nous sommes passés à gitlab.
- Nous avions l'habitude de faire une version manuelle chaque semaine, nous l'avons automatisée.
- Version à incrémentation automatique.
- Générez des notes de publication en fonction des problèmes résolus.
- Mettre à jour le journal des modifications.
- Créez des demandes de fusion.
- Créez un nouveau jalon.
- Nous avons déplacé certaines étapes dans Docker (lint, exécuter des tests, envoyer des messages, construire des documents, etc.).
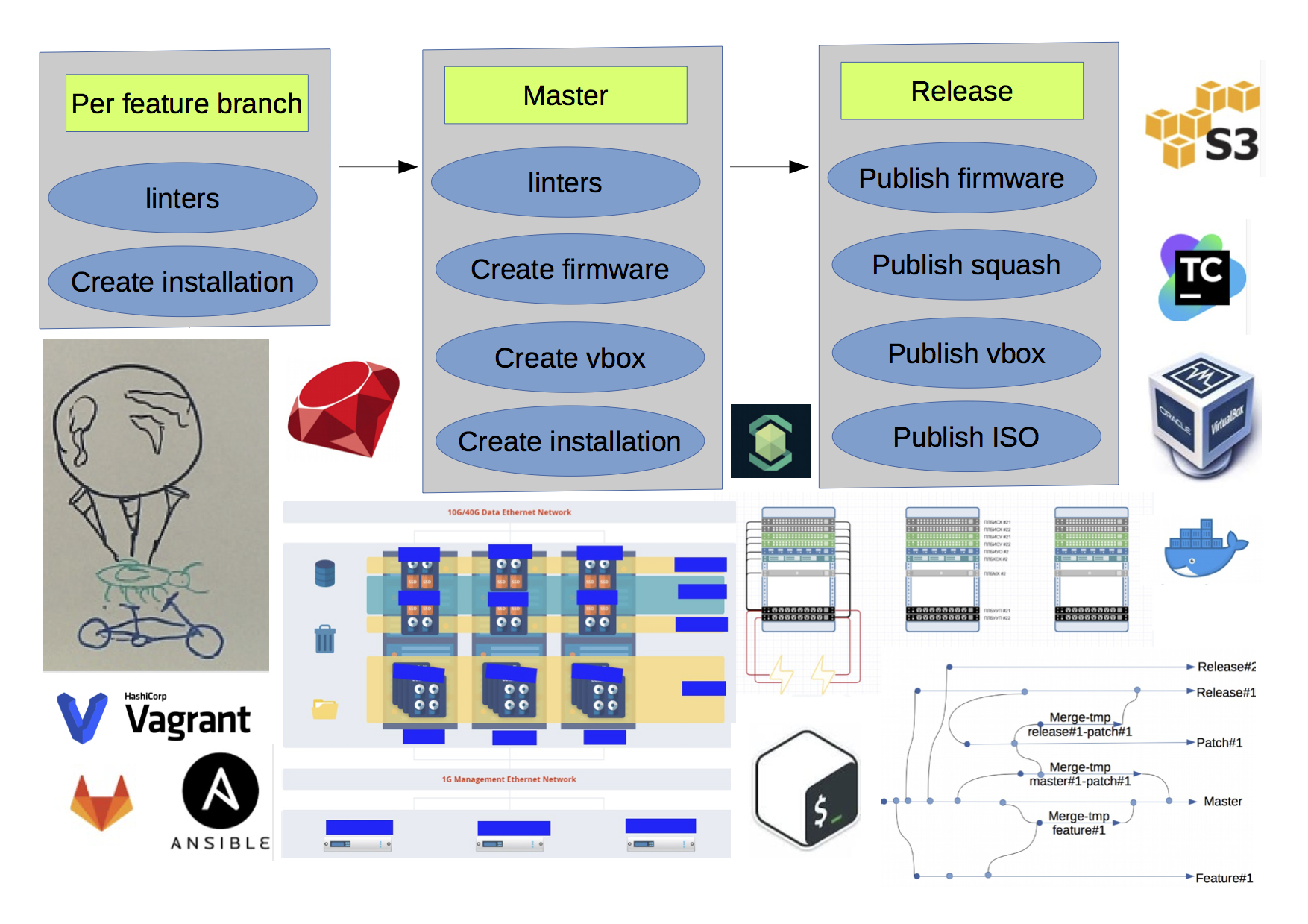
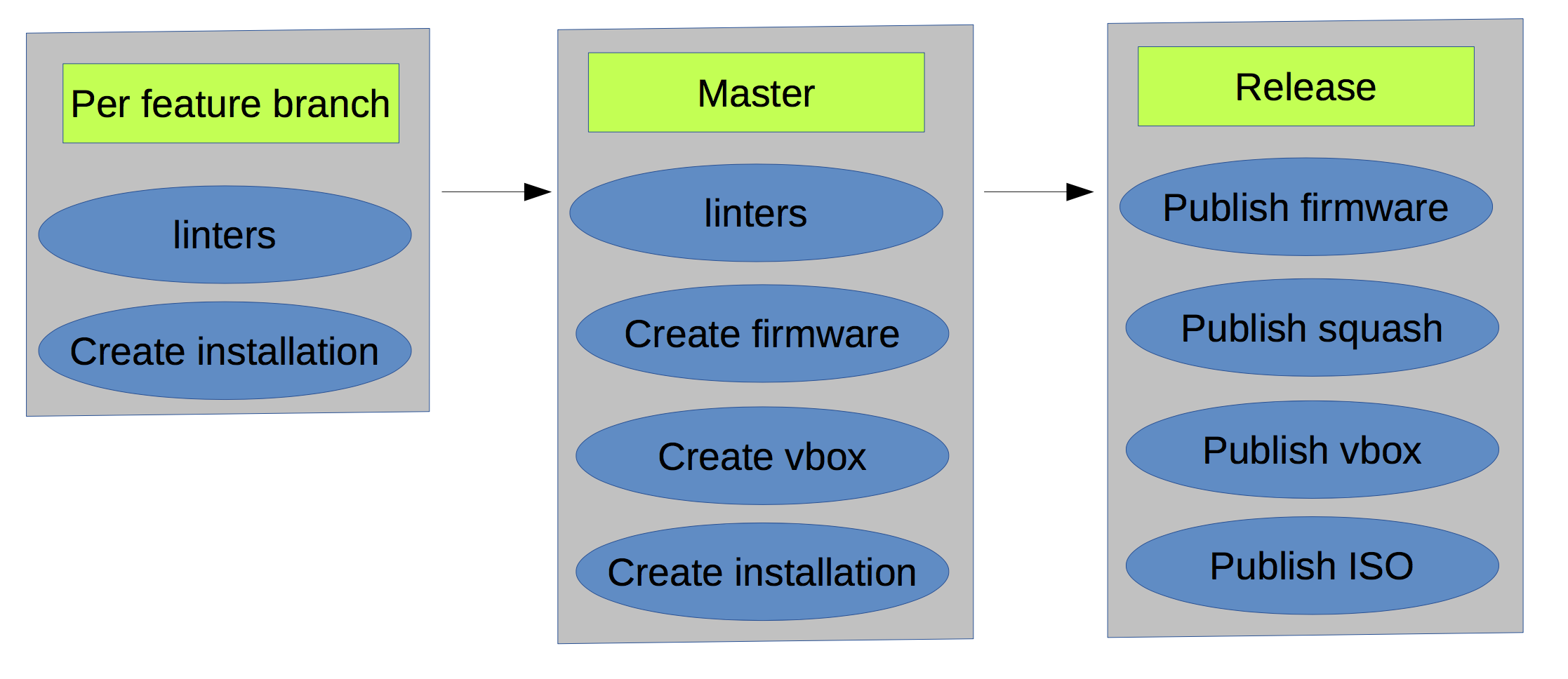
En conséquence, au stade actuel, le schéma ressemblait à ceci:

- Il y avait beaucoup de dépôts RPM / DEB pour les packages.
- Il y avait s3 comme entrepôt d'objets.
- Si vous exécutiez deux fois une génération pour la même branche, vous obtiendriez un résultat différent, car les dépendances du méta-paquet n'étaient pas codées en dur.
- Il y avait des limites non évidentes (lignes de couleur rouge) à travers les versions.
Cependant, nous avons pu produire une version chaque semaine et améliorer la vitesse de développement.
Conclusion
Le résultat n'était pas idéal, mais un voyage de mille li commence par une seule étape ©.
PS c'est crosspost