J'ai été invité à écrire cet article par une grande quantité de documents sur l'analyse statique, qui attirent de plus en plus souvent mon attention. Tout d'abord, c'est le
blog PVS-studio , qui se promeut activement sur Habré à l'aide de revues d'erreurs trouvées par leur outil dans des projets open source. Récemment, PVS-studio a implémenté la
prise en
charge de Java et, bien sûr, les développeurs d'IntelliJ IDEA, dont l'analyseur intégré est probablement le plus avancé pour Java aujourd'hui,
n'ont pas pu rester à l'écart .
En lisant de telles critiques, on a l'impression que nous parlons d'un élixir magique: cliquez sur le bouton, et le voici - une liste de défauts sous vos yeux. Il semble qu'à mesure que les analyseurs s'améliorent, de plus en plus de bugs seront automatiquement détectés, et les produits scannés par ces robots deviendront de mieux en mieux, sans aucun effort de notre part.
Mais il n'y a pas d'élixirs magiques. Je voudrais parler de quelque chose qui n'est généralement pas mentionné dans des articles comme «ce sont les choses que notre robot peut trouver»: ce que les analyseurs ne peuvent pas faire, quel est leur véritable rôle et place dans le processus de livraison de logiciels, et comment les implémenter correctement.
 Ratchet (source: Wikipedia ).
Ratchet (source: Wikipedia ).Quels analyseurs statiques ne peuvent jamais
Qu'est-ce que, d'un point de vue pratique, l'analyse du code source? Nous soumettons certaines sources à l'entrée, et à la sortie dans un court laps de temps (beaucoup plus court que le test), nous obtenons des informations sur notre système. La limitation fondamentale et mathématiquement insurmontable est que nous ne pouvons obtenir qu'une classe d'informations assez étroite de cette manière.
L'exemple le plus célèbre d'un problème qui ne peut pas être résolu à l'aide d'une analyse statique est
le problème d'arrêt : il s'agit d'un théorème qui prouve qu'il est impossible de développer un algorithme général qui déterminerait par le code source d'un programme s'il bouclerait ou se terminerait dans un temps fini. Une extension de ce théorème est
le théorème de Rice, qui déclare que pour toute propriété non triviale de fonctions calculables, déterminer si un programme arbitraire calcule une fonction avec cette propriété est un problème algorithmiquement insoluble. Par exemple, il est impossible d'écrire un analyseur qui détermine par n'importe quel code source si le programme analysé est une implémentation d'un algorithme qui calcule, disons, la quadrature d'un entier.
Ainsi, la fonctionnalité des analyseurs statiques a des limites insurmontables. Dans tous les cas, l'analyseur statique ne sera jamais en mesure de détecter des choses telles que, par exemple, l'occurrence d'une "exception de pointeur nul" dans les langues annulables, ou dans tous les cas déterminera l'occurrence d'un "attribut introuvable" dans les langues typées dynamiquement. Tout ce que l'analyseur statique le plus avancé peut faire est de mettre en évidence des cas particuliers, dont le nombre parmi tous les problèmes possibles avec votre code source est, sans exagération, une goutte dans le seau.
L'analyse statique n'est pas une recherche de bogues
La conclusion découle de ce qui précède: l'analyse statique n'est pas un moyen de réduire le nombre de défauts dans un programme. J'oserai affirmer: quand il est appliqué pour la première fois à votre projet, il trouvera des endroits «occupés» dans le code, mais très probablement il ne trouvera aucun défaut affectant la qualité de votre programme.
Les exemples de défauts détectés automatiquement par les analyseurs sont impressionnants, mais il ne faut pas oublier que ces exemples ont été trouvés en scannant un large ensemble de grandes bases de code. Selon le même principe, les crackers ayant la capacité d'énumérer quelques mots de passe simples sur un grand nombre de comptes trouvent finalement les comptes qui ont un mot de passe simple.
Est-ce à dire que l'analyse statique n'a pas besoin d'être appliquée? Bien sûr que non! Et pour exactement la même raison qu'il vaut la peine de vérifier chaque nouveau mot de passe pour accéder à la liste d'arrêt des mots de passe "simples".
L'analyse statique est plus qu'une recherche de bogues
En fait, les tâches pratiquement résolues par l'analyse sont beaucoup plus larges. En effet, en général, l'analyse statique est toute vérification des sources effectuée avant leur lancement. Voici certaines choses que vous pouvez faire:
- Vérification du style de codage au sens large du terme. Cela comprend la vérification de la mise en forme ainsi que la recherche de l'utilisation de parenthèses vides / supplémentaires, la définition de valeurs de seuil pour des mesures telles que le nombre de lignes / la complexité cyclomatique de la méthode, etc. - tout cela rend potentiellement le code difficile à lire et à maintenir. En Java, un tel outil est Checkstyle, en Python - flake8. Les programmes de cette classe sont généralement appelés linters.
- Non seulement le code exécutable peut être analysé. La validité des fichiers de ressources tels que JSON, YAML, XML, .properties peut (et devrait!) Être automatiquement vérifiée. Après tout, il est préférable de découvrir qu'en raison de citations non appariées, la structure JSON est violée au début de la vérification automatique de la demande d'extraction que lors de l'exécution de tests ou lors de l'exécution? Des outils pertinents sont disponibles: par exemple, YAMLlint , JSONLint .
- La compilation (ou l'analyse pour les langages de programmation dynamiques) est également une forme d'analyse statique. En règle générale, les compilateurs sont en mesure d'émettre des avertissements signalant des problèmes de qualité du code source, et ils ne doivent pas être ignorés.
- Parfois, la compilation n'est pas seulement une compilation de code exécutable. Par exemple, si vous avez de la documentation au format AsciiDoctor , au moment de la conversion en HTML / PDF, le gestionnaire AsciiDoctor ( plugin Maven ) peut donner des avertissements, par exemple, sur des liens internes rompus. Et c'est une bonne raison de ne pas accepter la demande d'extraction avec des modifications de la documentation.
- La vérification orthographique est également une forme d'analyse statique. L'utilitaire aspell est capable de vérifier l'orthographe non seulement dans la documentation, mais aussi dans les codes sources des programmes (commentaires et littéraux) dans divers langages de programmation, y compris C / C ++, Java et Python. Une faute d'orthographe dans l'interface utilisateur ou la documentation est également un défaut!
- Les tests de configuration (pour ce que c'est - voir ceci et ces rapports), bien qu'ils soient exécutés dans un environnement d'exécution pour des tests unitaires comme pytest, sont en fait aussi une sorte d'analyse statique, car ils n'exécutent pas de codes source pendant leur exécution .
Comme vous pouvez le voir, la recherche de bogues dans cette liste joue le rôle le moins important, et tout le reste est disponible grâce à l'utilisation d'outils open source gratuits.
Lequel de ces types d'analyse statique doit être utilisé dans votre projet? Bien sûr, tout, plus - mieux c'est! L'essentiel est de l'implémenter correctement, ce qui sera discuté plus loin.
Pipeline de livraison en tant que filtre à plusieurs étages et analyse statique comme sa première cascade
La métaphore classique de l'intégration continue est le pipeline à travers lequel les changements se déroulent - de la modification du code source à la livraison à la production. La séquence standard des étapes de ce pipeline est la suivante:
- analyse statique
- compilation
- tests unitaires
- tests d'intégration
- Tests d'interface utilisateur
- vérification manuelle
Les modifications rejetées à la Nème étape du convoyeur ne sont pas transférées à l'étape N + 1.
Pourquoi et non autrement? Dans la partie test du pipeline, les testeurs reconnaissent la pyramide des tests bien connue.
 Pyramide de test. Source: article de Martin Fowler.
Pyramide de test. Source: article de Martin Fowler.Au bas de cette pyramide se trouvent des tests plus faciles à écrire, plus rapides à exécuter et sans tendance aux faux positifs. Par conséquent, il devrait y en avoir plus, ils devraient couvrir plus de code et être exécutés en premier. Au sommet de la pyramide, tout est dans l'autre sens, donc le nombre de tests d'intégration et d'interface utilisateur doit être réduit au minimum requis. La personne de cette chaîne est la ressource la plus chère, la plus lente et la moins fiable, elle est donc à la toute fin et ne fait le travail que si les étapes précédentes n'ont révélé aucun défaut. Cependant, selon les mêmes principes, un convoyeur est construit en pièces qui ne sont pas directement liées aux tests!
Je voudrais proposer une analogie sous la forme d'un système de filtration d'eau à plusieurs étages. L'eau sale (changements avec défauts) est fournie à l'entrée, à la sortie, nous devons obtenir de l'eau propre, dans laquelle toute pollution indésirable est éliminée.
 Filtre à plusieurs étages. Source: Wikimedia Commons
Filtre à plusieurs étages. Source: Wikimedia CommonsComme vous le savez, les filtres de nettoyage sont conçus pour que chaque cascade suivante puisse filtrer une fraction de plus en plus petite des contaminants. Dans le même temps, les cascades plus grossières ont un débit supérieur et un coût inférieur. Dans notre analogie, cela signifie que les portes de qualité d'entrée ont une plus grande vitesse, nécessitent moins d'efforts pour démarrer et sont elles-mêmes plus sans prétention dans leur travail - et c'est dans cette séquence qu'elles sont construites. Le rôle de l'analyse statique, qui, comme nous le comprenons maintenant, ne peut éliminer que les défauts les plus grossiers, est le rôle de la grille «piège à saleté» au tout début de la cascade de filtres.
L'analyse statique seule n'améliore pas la qualité du produit final, tout comme un collecteur de boue ne produit pas d'eau potable. Néanmoins, en général avec d'autres éléments du convoyeur, son importance est évidente. Bien que dans le filtre à plusieurs étages, les étages de sortie soient potentiellement capables de tout capturer de la même manière que ceux d'entrée, il est clair quelles conséquences la tentative de faire sans étages fins sans étages d'entrée y conduira.
Le but du «collecteur de saletés» est de soulager les cascades suivantes de la capture de défauts très grossiers. Par exemple, au moins la personne qui effectue la révision du code ne doit pas être distraite par un code mal formaté et une violation des normes de codage établies (comme des crochets supplémentaires ou des branches trop profondément imbriquées). Les bogues comme NPE devraient être détectés par des tests unitaires, mais si même avant le test, l'analyseur nous dit que le bogue devrait inévitablement se produire, cela accélérera considérablement sa correction.
Je pense qu'il est maintenant clair pourquoi l'analyse statique n'améliore pas la qualité du produit, si elle est appliquée sporadiquement, et doit être utilisée en continu pour filtrer les changements présentant des défauts grossiers. La question est de savoir si l'utilisation d'un analyseur statique améliorera la qualité de votre produit, est à peu près équivalente à la question "les qualités potables de l'eau prélevée dans un réservoir sale s'amélioreront-elles si elle passe dans une passoire?"
Implémentation dans un projet hérité
Une question pratique importante: comment intégrer l'analyse statique dans le processus d'intégration continue en tant que «porte qualité»? Dans le cas des tests automatiques, tout est évident: il y a un ensemble de tests, la chute de l'un d'entre eux est une raison suffisante pour croire que le montage n'a pas passé la barrière de la qualité. Une tentative de définir la porte de la même manière en fonction des résultats de l'analyse statique échoue: il y a trop d'avertissements d'analyse sur le code hérité, vous ne voulez pas les ignorer complètement, mais il est impossible d'arrêter la livraison du produit uniquement parce qu'il contient des avertissements d'analyseur.
Lorsqu'il est appliqué pour la première fois, l'analyseur génère un grand nombre d'avertissements sur tout projet, dont la grande majorité n'est pas liée au bon fonctionnement du produit. Il est impossible de corriger toutes ces remarques à la fois et beaucoup ne sont pas nécessaires. Au final, nous savons que notre produit dans son ensemble fonctionne, et avant l'introduction de l'analyse statique!
En conséquence, beaucoup sont limités à l'utilisation épisodique de l'analyse statique, ou ne l'utilisent qu'en mode informatif, lorsque le rapport de l'analyseur est simplement émis pendant l'assemblage. Cela équivaut à l'absence d'analyse, car si nous avons déjà de nombreux avertissements, alors l'émergence d'un autre (arbitrairement grave) lors du changement de code passe inaperçu.
Les méthodes suivantes d'administration de portes de qualité sont connues:
- Fixer une limite au nombre total d'avertissements ou au nombre d'avertissements divisé par le nombre de lignes de code. Cela fonctionne mal, car une telle porte saute librement les modifications avec de nouveaux défauts jusqu'à ce que leur limite soit dépassée.
- Correction, à un certain moment, de tous les anciens avertissements du code ignorés et refus de générer lorsque de nouveaux avertissements se produisent. Cette fonctionnalité est fournie par PVS-studio et certaines ressources en ligne, par exemple, Codacy. Je n'ai pas pu travailler dans PVS-studio, car pour mon expérience avec Codacy, leur principal problème est que déterminer ce qui est «ancien» et ce qui est «nouveau» est un algorithme plutôt compliqué et pas toujours fonctionnel, surtout si les fichiers sont fortement modifiés ou renommés. Dans ma mémoire, Codacy pourrait ignorer les nouveaux avertissements dans la demande d'extraction, et en même temps ne pas ignorer la demande d'extraction en raison d'avertissements non liés aux modifications du code de ce PR.
- À mon avis, la solution la plus efficace est décrite dans le livre Continuous Delivery "ratcheting" ("ratcheting"). L'idée principale est que la propriété de chaque version est le nombre d'avertissements de l'analyse statique, et seules les modifications autorisées n'augmentent pas le nombre total d'avertissements.
Cliquet
Cela fonctionne de cette façon:
- Au stade initial, le nombre d'avertissements dans le code trouvé par les analyseurs est enregistré dans les métadonnées concernant la version. Ainsi, lors de la construction de la branche principale, non seulement la «version 7.0.2», mais la «version 7.0.2, contenant 100 500 avertissements Checkstyle» est écrite dans votre gestionnaire de référentiel. Si vous utilisez un gestionnaire de référentiel avancé (tel que Artifactory), il est facile d'enregistrer de telles métadonnées sur votre version.
- Désormais, chaque demande d'extraction lors de l'assemblage compare le nombre d'avertissements reçus avec le nombre dans la version actuelle. Si PR conduit à une augmentation de ce nombre, le code ne passe pas la porte de qualité pour l'analyse statique. Si le nombre d'avertissements diminue ou ne change pas, il passe.
- À la prochaine version, le nombre compté d'avertissements sera réécrit dans les métadonnées de la version.
Donc, petit à petit, mais régulièrement (comme avec le cliquet), le nombre d'avertissements tendra vers zéro. Bien sûr, le système peut être trompé en introduisant un nouvel avertissement, mais en corrigeant celui de quelqu'un d'autre. C'est normal, car sur une longue distance, cela donne le résultat: les avertissements sont généralement corrigés non pas individuellement, mais immédiatement par un groupe d'un certain type, et tous les avertissements facilement éliminés sont rapidement éliminés.
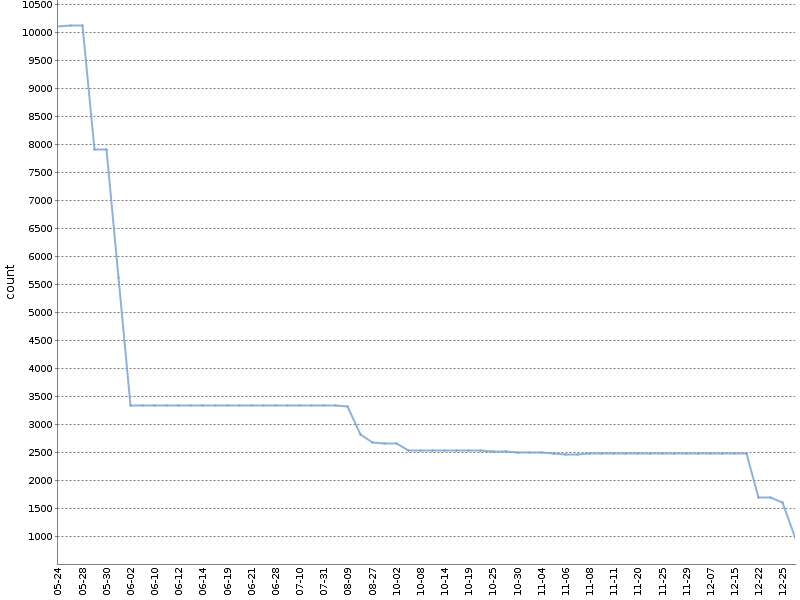
Ce graphique montre le nombre total d'avertissements Checkstyle pour une demi-année de travail d'un tel cliquet sur l'
un de nos projets OpenSource . Le nombre d'avertissements a diminué d'un ordre de grandeur, et cela s'est produit naturellement, en parallèle avec le développement du produit!
J'utilise une version modifiée de cette méthode, en comptant séparément les avertissements ventilés par modules de projet et outils d'analyse, le fichier YAML généré avec les métadonnées d'assemblage ressemble à ceci:
celesta-sql: checkstyle: 434 spotbugs: 45 celesta-core: checkstyle: 206 spotbugs: 13 celesta-maven-plugin: checkstyle: 19 spotbugs: 0 celesta-unit: checkstyle: 0 spotbugs: 0
Dans tout système CI avancé, le «cliquet» peut être implémenté pour tous les outils d'analyse statique, sans dépendre de plugins et d'outils tiers. Chacun des analyseurs produit son rapport dans un format texte ou XML simple, facile à analyser. Il reste à enregistrer uniquement la logique nécessaire dans le script CI. Vous pouvez voir comment cela est mis en œuvre dans nos projets open source basés sur Jenkins et Artifactory
ici ou
ici . Les deux exemples dépendent de la bibliothèque
ratchetlib : la méthode
countWarnings() calcule
countWarnings() les balises xml dans les fichiers générés par Checkstyle et Spotbugs, et
compareWarningMaps() implémente le même cliquet, générant une erreur lorsque le nombre d'avertissements dans l'une des catégories augmente.
Une implémentation intéressante du cliquet est possible pour analyser l'orthographe des commentaires, des littéraux de texte et de la documentation en utilisant aspell. Comme vous le savez, lors de la vérification de l'orthographe, tous les mots inconnus du dictionnaire standard ne sont pas incorrects; ils peuvent être ajoutés au dictionnaire utilisateur. Si vous intégrez un dictionnaire personnalisé au code source du projet, le portail de qualité pour l'orthographe peut être formulé comme suit: l'exécution de aspell avec un dictionnaire standard et personnalisé
ne doit pas trouver d'erreurs d'orthographe.
À propos de l'importance de corriger la version de l'analyseur
En conclusion, il convient de noter ce qui suit: quelle que soit la façon dont vous intégrez l'analyse dans votre pipeline de livraison, la version de l'analyseur doit être corrigée. Si vous autorisez l'analyseur à se mettre à jour spontanément, lors de l'assemblage de la prochaine demande d'extraction, de nouveaux défauts peuvent apparaître qui ne sont pas liés à la modification du code, mais sont liés au fait que le nouvel analyseur est simplement capable de trouver plus de défauts - et cela interrompra le processus de réception des demandes d'extraction. . La mise à niveau de l'analyseur doit être une action consciente. Cependant, la fixation serrée de la version de chaque composant de l'assemblage est généralement une exigence nécessaire et un sujet pour une conversation distincte.
Conclusions
- L'analyse statique ne vous trouvera pas de bogues et n'améliorera pas la qualité de votre produit à la suite d'une seule application. Un effet positif sur la qualité n'est fourni que par son utilisation constante dans le processus de livraison.
- La recherche de bogues n'est pas du tout la tâche principale de l'analyse, la grande majorité des fonctions utiles sont disponibles dans les outils open source.
- Implémentez des portes de qualité basées sur les résultats de l'analyse statique à la toute première étape du pipeline de livraison, en utilisant un cliquet pour le code hérité.
Les références
- Livraison continue
- A. Kudryavtsev: Analyse des programmes: comment comprendre que vous êtes un bon programmeur rapport sur différentes méthodes d'analyse de code (pas seulement statique!)