Donc, le 4 janvier, à 7h15, en m'essuyant les yeux du sommeil, je trouve un paquet d'un message dans le groupe Telegram du serveur Zabbix que la charge CPU sur l'un des serveurs de virtualisation a augmenté:
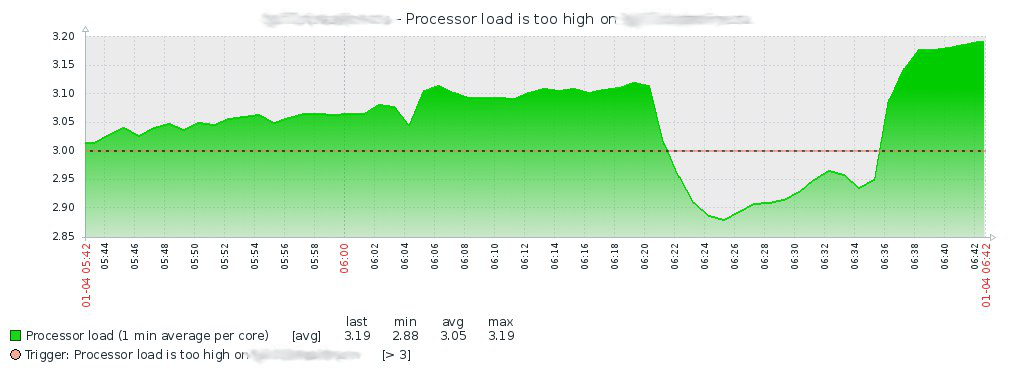
Après avoir regardé l'histoire de Zabbix, je monte sur le serveur et regarde dans dmesg, où je trouve ce qui suit:
[ 3 20:05:18 2019] qla2xxx [0000:21:00.1]-015b:10: Disabling adapter. [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device
Je monte dans le stockage où l'adaptateur QLogic FC regarde, je vois que le 1er janvier à 19:54 l'un des disques dans le stockage a été mis hors service, le disque de rechange a été ramassé et la réargenture s'est terminée le 2 janvier à 9:11:

J'ai pensé: peut-être que quelque chose venait du référentiel ou du commutateur FC, ce qui a provoqué la colère du pilote avec l'adaptateur QLogic.
A créé une tâche dans le tracker, redémarré le serveur, tout a fonctionné à nouveau comme il se doit, à première vue.
À ce sujet, il a reporté de nouvelles actions jusqu'à la fin des vacances du Nouvel An.
Avec le début de la semaine de travail le 9 janvier, il a commencé à trier la cause de l'échec.
Depuis le message:
[ 3 20:05:18 2019] qla2xxx [0000:21:00.1]-015b:10: Disabling adapter.
pas trop informatif, grimpé dans la source du pilote.
A en juger par le code du pilote, un message est émis lorsque le pilote est déchargé en raison d'une erreur sur le PCI (linux / drivers / scsi / qla2xxx / qla_os.c (kernel v4.15)):
qla2x00_disable_board_on_pci_error(struct work_struct *work) { struct qla_hw_data *ha = container_of(work, struct qla_hw_data, board_disable); struct pci_dev *pdev = ha->pdev; scsi_qla_host_t *base_vha = pci_get_drvdata(ha->pdev); /* * if UNLOAD flag is already set, then continue unload, * where it was set first. */ if (test_bit(UNLOADING, &base_vha->dpc_flags)) return; ql_log(ql_log_warn, base_vha, 0x015b, "Disabling adapter.\n");
J'ai commencé à creuser plus loin, je suis entré dans BMC, je regarde dans le journal des événements:
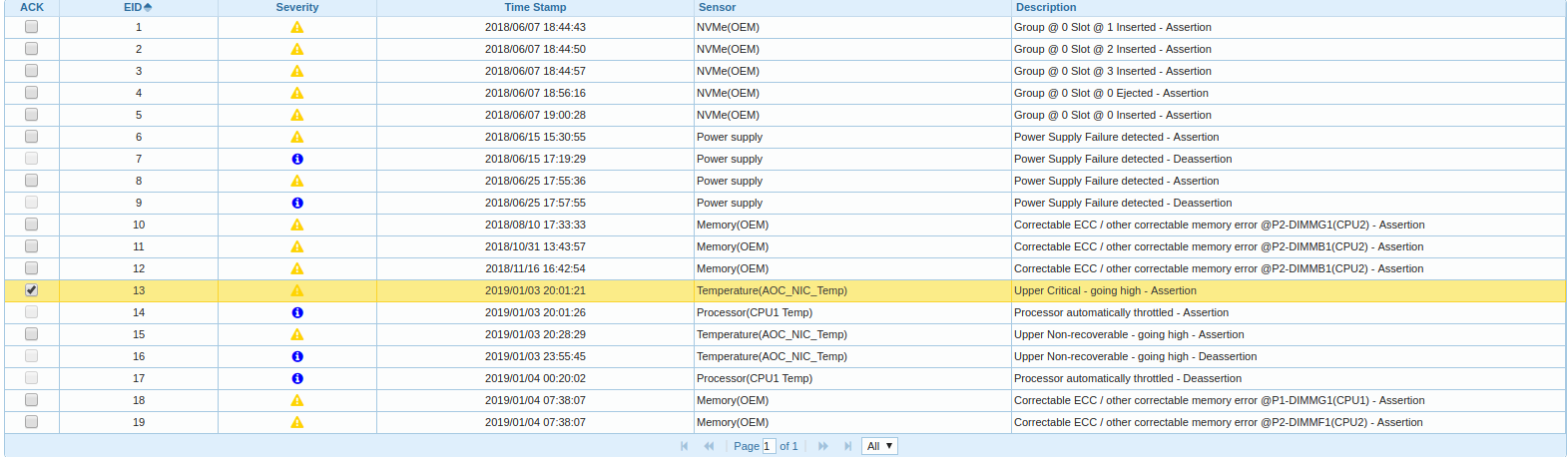
Il s'avère que l'un des deux nœuds CPU de la plate-forme est en phase de réchauffement et de limitation, et l'heure du message de déchargement du pilote de l'adaptateur FC est en corrélation avec l'heure de début de la limitation.
Ici, il convient de noter que la plate-forme de serveur que nous avons ici est https://www.supermicro.com/Aplus/system/2U/2123/AS-2123BT-HNC0R.cfm avec deux EPYC 7601 pour chaque nœud:
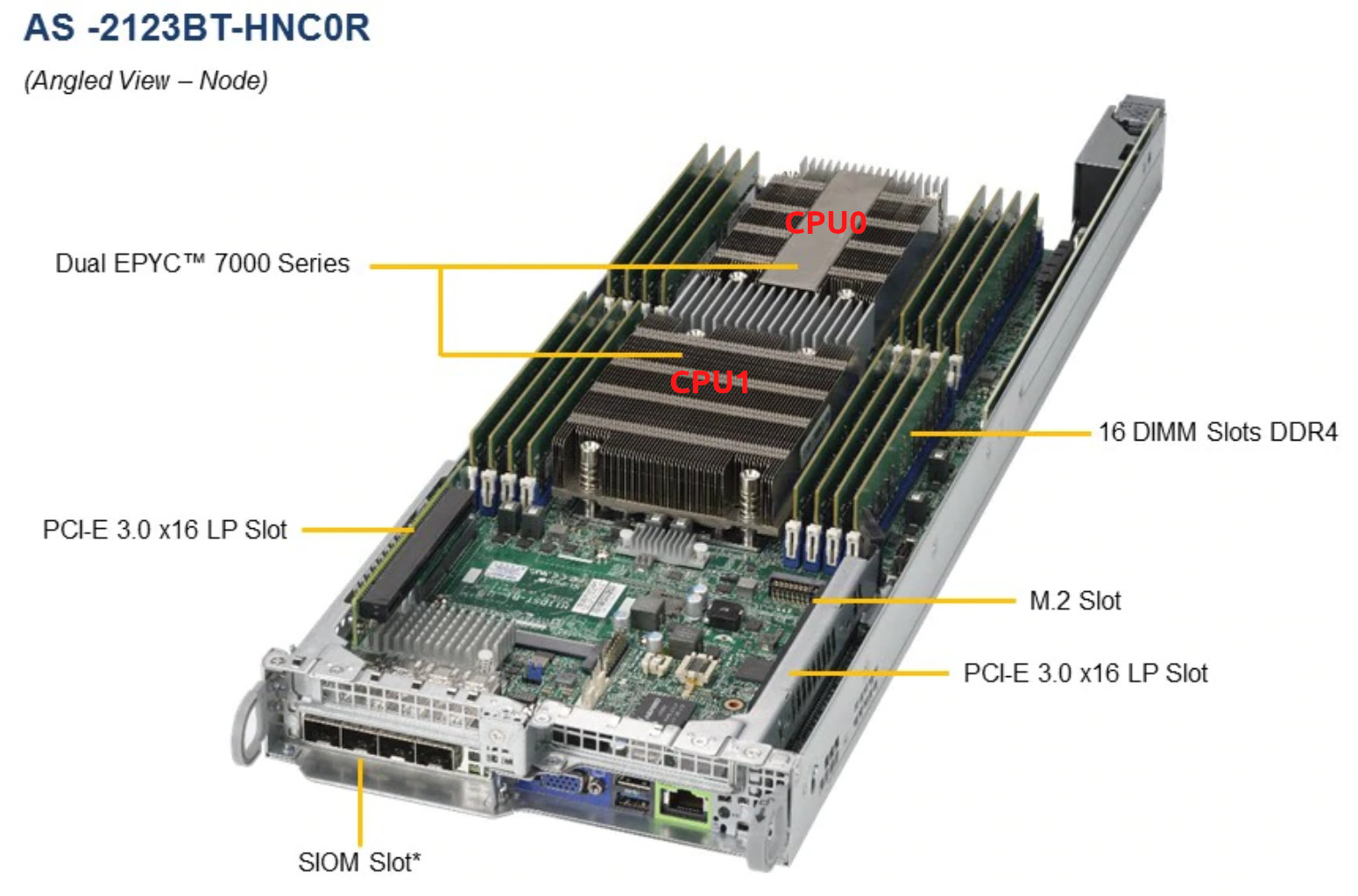
Je l'ai déplacé vers le centre de données, j'ai retiré le nœud du serveur, j'ai changé la pâte thermique, l'ai recollée, mais elle chauffe toujours.
Nous avons remarqué que le flux d'air dans une partie du serveur n'est pas aussi fort que dans l'autre. Après avoir légèrement chargé tous les nœuds avec stress-ng, il est devenu clair que les processeurs de nœuds sur le côté droit de la plate-forme ne soufflent pas correctement et que la température du deuxième processeur dans deux nœuds atteint très rapidement un niveau critique.
Après avoir essayé de changer les paramètres de soufflage dans BMC, il s'est avéré qu'ils n'avaient aucun effet:
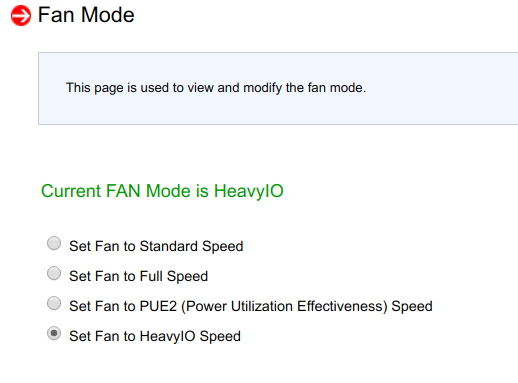
Le redémarrage de BMC n'a également eu aucun effet.
Après avoir regardé les lectures des capteurs, j'ai vu que sur un nœud sur 53 capteurs, seulement 4 sont détectés et sur l'autre nœud seulement 6:
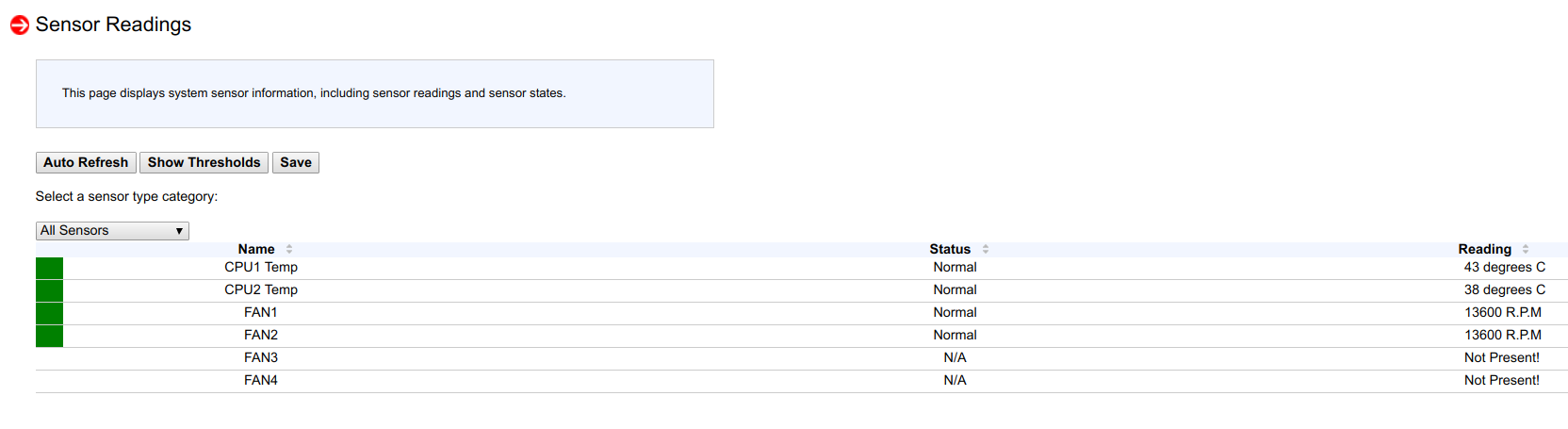
Et puis, je me suis souvenu que lors du flashage d'une nouvelle version du BIOS et d'un nouveau BMC dans des nœuds il y a un mois ou deux, sur deux nœuds, je n'ai pas réinitialisé la configuration du BMC aux paramètres d'usine (afin de vérifier un cas particulier de réglage).
Après avoir réinitialisé le BMC aux paramètres d'usine, les 53 capteurs ont de nouveau été détectés, le contrôle de la vitesse du ventilateur a de nouveau fonctionné, les processeurs ont arrêté de chauffer.
Le fait que la cause du déchargement du pilote QLogic soit la surchauffe du processeur n'est pas précis, mais je n'ai pas trouvé d'autres corrélations étroites.
Conclusions:
- après le micrologiciel BMC, même si tout fonctionne bien à première vue, il vaut toujours la peine de réinitialiser les paramètres d'usine;
- Bien sûr, les messages d'erreur de température et de noyau doivent être surveillés et cela est naturel dans les plans, mais pas tous en même temps.