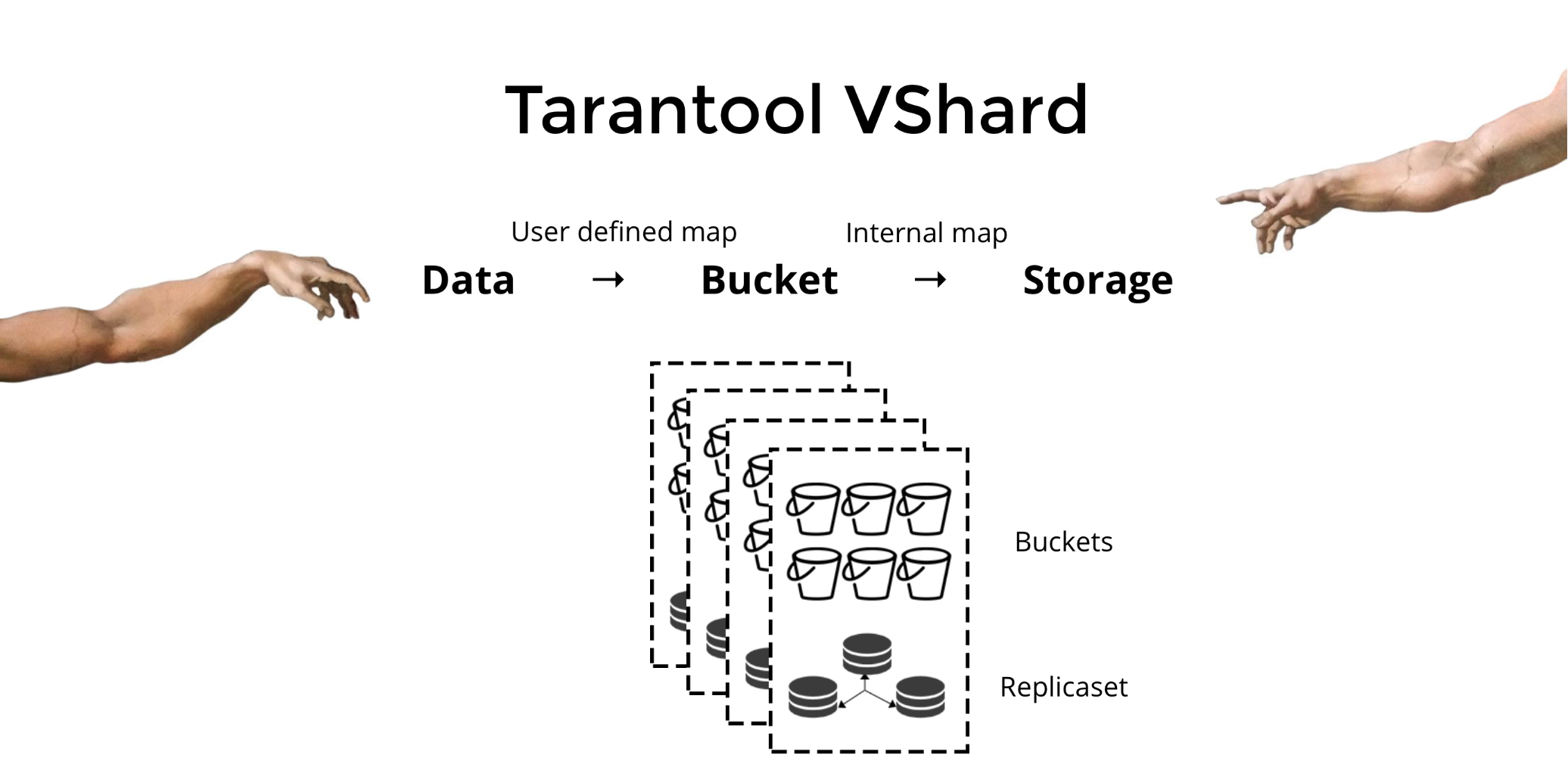
Mon nom est Vladislav, je participe au développement de
Tarantool - SGBD et serveur d'application dans une bouteille. Et aujourd'hui, je vais vous expliquer comment nous avons implémenté la mise à l'échelle horizontale dans Tarantool à l'aide du module
VShard .
Tout d'abord, un peu de théorie.
Il existe deux types de mise à l'échelle: horizontale et verticale. L'horizontale est divisée en deux types: réplication et partitionnement. La réplication est utilisée pour mettre à l'échelle l'informatique, le sharding est utilisé pour mettre à l'échelle les données.
Le partage est divisé en deux types: le partage par plages et le partage par hachages.
Lors du partitionnement avec des plages, nous calculons une clé de partition à partir de chaque enregistrement du cluster. Ces clés de fragments sont projetées sur une ligne droite, qui est divisée en plages que nous ajoutons à différents nœuds physiques.
Le partage avec des hachages est plus simple: à partir de chaque enregistrement du cluster, nous considérons une fonction de hachage, nous ajoutons les entrées avec la même valeur de la fonction de hachage à un nœud physique.
Je vais parler de la mise à l'échelle horizontale à l'aide du découpage de hachage.
Implémentation précédente
Le premier module de mise à l'échelle horizontale que nous avions était
Tarantool Shard . Il s'agit d'un partitionnement par hachage très simple, qui prend en compte la clé de partition de la clé primaire de toutes les entrées du cluster.
function shard_function(primary_key) return guava(crc32(primary_key), shard_count) end
Mais une tâche s'est alors imposée que Tarantool Shard n'a pas été en mesure de gérer pour trois raisons fondamentales.
Premièrement, la
localisation des données logiquement liées était requise. Lorsque nous avons des données qui sont connectées logiquement, nous voulons toujours les stocker sur le même nœud physique, quelle que soit la façon dont la topologie du cluster change ou l'équilibrage est effectué. Et Tarantool Shard ne le garantit pas. Il considère le hachage uniquement par des clés primaires, et lors du rééquilibrage, même les enregistrements avec le même hachage peuvent être divisés pendant un certain temps - le transfert n'est pas atomique.
Le problème du manque de localisation des données nous a le plus empêché. Je vais vous donner un exemple. Il y a une banque dans laquelle le client a ouvert un compte. Les données du compte et du client doivent toujours être stockées physiquement ensemble afin de pouvoir être lues en une seule demande, échangées en une seule transaction, par exemple lors du transfert d'argent depuis un compte. Si vous utilisez le partitionnement classique avec Tarantool Shard, les valeurs des fonctions de partition seront différentes pour les comptes et les clients. Les données peuvent se trouver sur différents nœuds physiques. Cela complique grandement la lecture et le travail transactionnel avec un tel client.
format = {{'id', 'unsigned'}, {'email', 'string'}} box.schema.create_space('customer', {format = format}) format = {{'id', 'unsigned'}, {'customer_id', 'unsigned'}, {'balance', 'number'}} box.schema.create_space('account', {format = format})
Dans l'exemple ci-dessus, les champs
id peuvent facilement ne pas correspondre aux comptes et aux clients. Ils sont connectés via le champ de compte
customer_id et
customer_id id . Le même champ
id romprait l'unicité de la clé primaire du compte. Et d'une autre manière, Shard n'est pas en mesure de tailler.
Le problème suivant est
le rééchantillonnage lent . C'est le problème classique de tous les fragments sur les hachages. L'essentiel est que lorsque nous modifions la composition d'un cluster, nous changeons généralement la fonction de partition, car cela dépend généralement du nombre de nœuds. Et lorsque la fonction change, vous devez parcourir toutes les entrées du cluster et recalculer à nouveau la fonction de partition. Peut-être transférer quelques notes. Et pendant que nous les transférons, nous ne savons pas si les données nécessaires à la prochaine demande entrante ont déjà été transférées, peut-être sont-elles maintenant en cours de transfert. Par conséquent, lors du nouveau partage, il est nécessaire que chaque lecture fasse une demande pour deux fonctions de partition: l'ancienne et la nouvelle. Les demandes deviennent deux fois plus lentes et pour nous, c'était inacceptable.
Une autre caractéristique de Tarantool Shard était que lorsque certains nœuds dans les jeux de répliques échouaient, cela montrait une
mauvaise accessibilité en lecture .
Nouvelle solution
Pour résoudre les trois problèmes décrits, nous avons créé
Tarantool VShard . Sa principale différence est que le niveau de stockage des données est virtualisé: les stockages virtuels sont apparus au-dessus des stockages physiques et les enregistrements sont répartis entre eux. Ces stockages sont appelés bucket'ami. L'utilisateur n'a pas besoin de penser à quoi et sur quel nœud physique se trouve. Le seau est une unité de données atomique indivisible, comme dans le partage classique d'un tuple. VShard stocke toujours l'intégralité du compartiment sur un nœud physique et transfère toutes les données d'un compartiment de manière atomique lors du resharding. Pour cette raison, la localité est fournie. Nous avons juste besoin de mettre les données dans un seul compartiment, et nous pouvons toujours être sûrs que ces données seront associées à toutes les modifications du cluster.

Comment puis-je mettre les données dans un seul compartiment? Dans le schéma que nous avons introduit précédemment pour le client de banque, nous ajouterons l'
bucket id de
bucket id aux tables en fonction du nouveau champ. Si les données liées sont les mêmes, les enregistrements seront dans le même compartiment. L'avantage est que nous pouvons stocker ces enregistrements avec le même
bucket id de
bucket id dans différents espaces, et même dans différents moteurs. La
bucket id fournie, quelle que soit la façon dont ces enregistrements sont stockés.
format = {{'id', 'unsigned'}, {'email', 'string'}, {'bucket_id', 'unsigned'}} box.schema.create_space('customer', {format = format}) format = {{'id', 'unsigned'}, {'customer_id', 'unsigned'}, {'balance', 'number'}, {'bucket_id', 'unsigned'}} box.schema.create_space('account', {format = format})
Pourquoi sommes-nous si impatients pour cela? Si nous avons un partage classique, alors les données peuvent se glisser dans tous les stockages physiques que nous avons seulement. Dans l'exemple avec la banque, lors de la demande de tous les comptes d'un client, vous devrez vous tourner vers tous les nœuds. Il s'avère la difficulté de lire O (N), où N est le nombre de magasins physiques. Terriblement lent.
Grâce à bucket'am et à la localité par
bucket id de compartiment
bucket id nous pouvons toujours lire les données d'un nœud en une seule demande, quelle que soit la taille du cluster.

Vous devez calculer l'
bucket id et attribuer vous-même les mêmes valeurs. Pour certains, c'est un avantage, pour quelqu'un un désavantage. Je considère qu'il est avantageux que vous puissiez choisir vous-même la fonction de calcul de l'
bucket id compartiment.
Quelle est la principale différence entre le sharding classique et le sharding virtuel avec bucket?
Dans le premier cas, lorsque nous modifions la composition du cluster, nous avons deux états: l'actuel (ancien) et le nouveau, dans lesquels nous devons aller. Dans le processus de transition, vous devez non seulement transférer les données, mais également recalculer les fonctions de hachage pour tous les enregistrements. Ceci est très gênant, car à un moment donné, nous ne savons pas quelles données ont déjà été transférées et lesquelles ne le sont pas. De plus, ce n'est ni fiable ni atomique, car pour le transfert atomique d'un ensemble d'enregistrements avec la même valeur de la fonction de hachage, il est nécessaire de stocker de manière persistante l'état de transfert en cas de besoin de restauration. Il y a des conflits, des erreurs, vous devez redémarrer la procédure plusieurs fois.
Le partage virtuel est beaucoup plus simple. Nous n'avons pas deux états sélectionnés du cluster, nous n'avons que l'état du compartiment. Le cluster devient plus maniable, il passe progressivement d'un état à l'autre. Et maintenant, il y a plus de deux États. Grâce à une transition en douceur, vous pouvez modifier l'équilibre à la volée, supprimer le stockage nouvellement ajouté. Autrement dit, la contrôlabilité de l'équilibrage est considérablement augmentée, elle devient granulaire.
Utiliser
Disons que nous avons choisi une fonction pour l'
bucket id et versé tellement de données dans le cluster qu'il n'y avait plus d'espace. Maintenant, nous voulons ajouter des nœuds, et pour que les données y soient déplacées nous-mêmes. Dans VShard, cela se fait comme suit. Tout d'abord, lancez de nouveaux nœuds et Tarantools dessus, puis mettez à jour la configuration VShard. Il décrit tous les membres du cluster, toutes les répliques, les jeux de réplicas, les maîtres, les URI attribués et bien plus encore. Nous ajoutons de nouveaux nœuds à la configuration, et en utilisant la fonction
VShard.storage.cfg ,
VShard.storage.cfg utilisons sur tous les nœuds du cluster.
function create_user(email) local customer_id = next_id() local bucket_id = crc32(customer_id) box.space.customer:insert(customer_id, email, bucket_id) end function add_account(customer_id) local id = next_id() local bucket_id = crc32(customer_id) box.space.account:insert(id, customer_id, 0, bucket_id) end
Comme vous vous en souvenez, dans le partage classique avec un changement du nombre de nœuds, la fonction de partage change également. Dans VShard, cela ne se produit pas, nous avons un nombre fixe de stockages virtuels - bucket'ov. Il s'agit de la constante que vous sélectionnez lors du démarrage du cluster. Il peut sembler qu'à cause de cela, l'évolutivité est limitée, mais pas vraiment. Vous pouvez choisir un grand nombre de bucket'ov, des dizaines et des centaines de milliers. L'essentiel est qu'il devrait y avoir au moins deux ordres de grandeur de plus que le nombre maximum de jeux de répliques que vous aurez jamais dans le cluster.
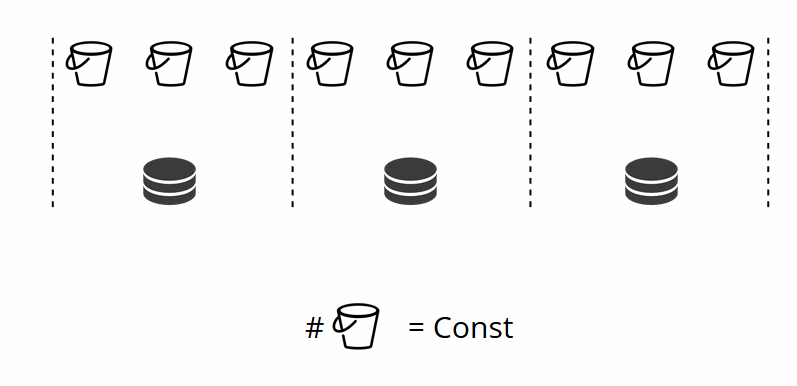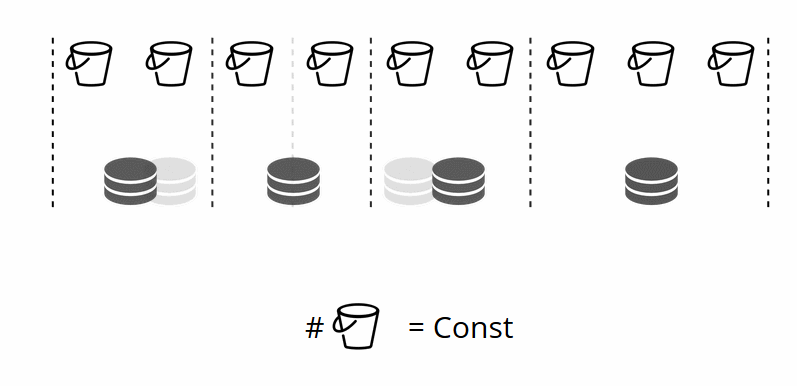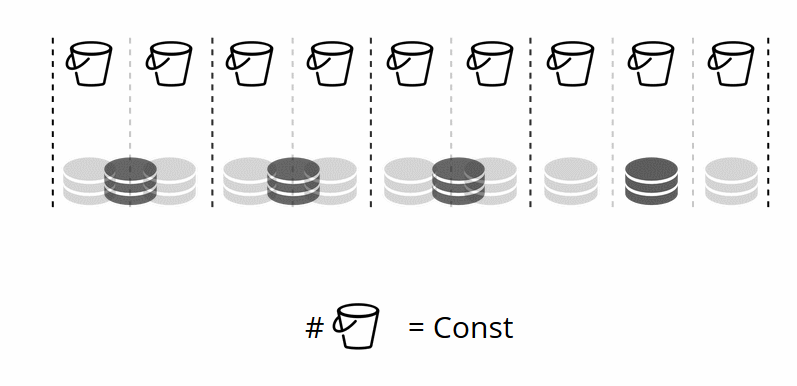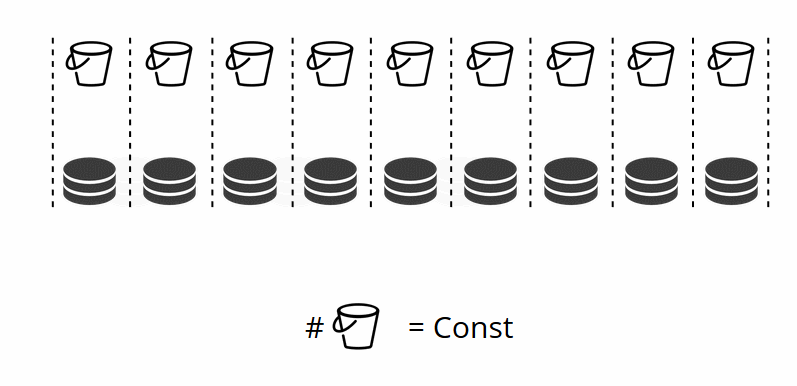
Étant donné que le nombre de stockages virtuels ne change pas - et la fonction de partition dépend uniquement de cette valeur - nous pouvons ajouter autant de stockages physiques que nécessaire sans recompter la fonction de partition.
Comment les paniers sont-ils distribués seuls dans les magasins physiques? Lorsque VShard.storage.cfg est appelé sur l'un des nœuds, le processus de rééquilibrage se réveille. Il s'agit d'un processus analytique qui calcule l'équilibre parfait dans un cluster. Il va à tous les nœuds physiques, demande qui a combien de bucket'ov, et construit des itinéraires pour leur mouvement afin de faire la moyenne de la distribution. Le rééquilibreur envoie des itinéraires vers des stockages bondés et ils commencent à envoyer des seaux. Après un certain temps, le cluster devient équilibré.
Mais dans les projets réels, le concept d'équilibre parfait peut être différent. Par exemple, je souhaite stocker moins de données sur un jeu de réplicas que sur l'autre, car il y a moins d'espace sur le disque dur. VShard pense que tout est bien équilibré, et en fait mon stockage est sur le point de déborder. Nous avons fourni un mécanisme d'ajustement des règles d'équilibrage à l'aide de pondérations. Chaque jeu de réplicas et référentiel peut être pondéré. Lorsque l'équilibreur décide à qui envoyer le nombre de bucket'ov, il prend en compte la
relation de toutes les paires de poids.
Par exemple, un magasin a un poids de 100 et l'autre 200. Ensuite, le premier stockera deux fois moins de bucket'ov que le second. Veuillez noter que je parle spécifiquement du
rapport des poids. Les significations absolues n'ont aucun effet. Vous pouvez choisir des pondérations basées sur une distribution de cluster à 100%: un magasin a 30%, un autre a 70%. Vous pouvez prendre la capacité de stockage en gigaoctets comme base, ou vous pouvez mesurer les poids dans le nombre de bucket'ov. L'essentiel est d'observer l'attitude dont vous avez besoin.
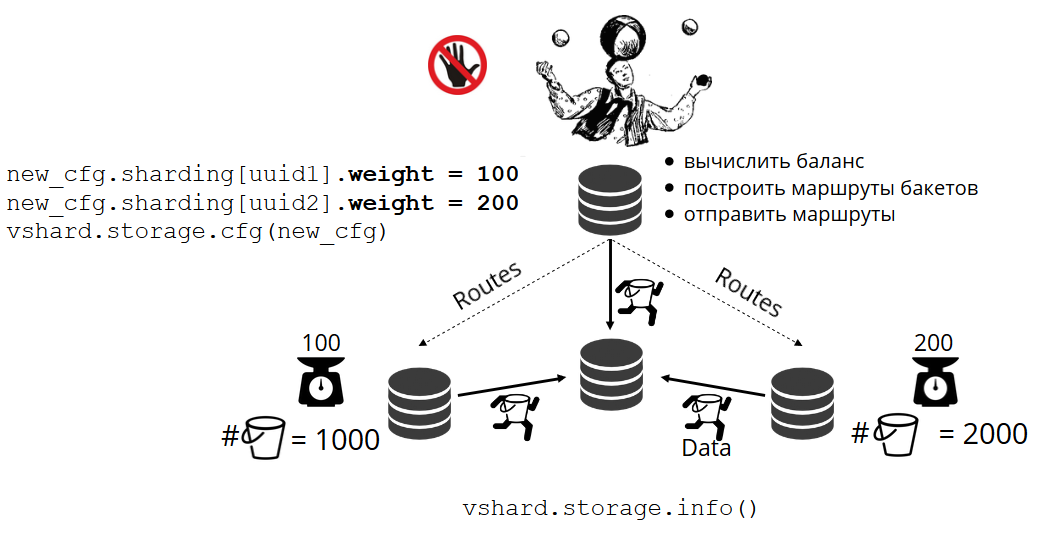
Un tel système a un effet secondaire intéressant: si vous attribuez un poids nul à un magasin, l'équilibreur ordonnera au magasin de distribuer tous ses seaux. Après cela, vous pouvez supprimer l'ensemble de réplicas de la configuration.
Transfert de seau atomique
Nous avons un compartiment, il accepte une sorte de demande de lecture et d'écriture, puis l'équilibreur demande de le transférer vers un autre stockage. Bucket cesse d'accepter les demandes d'enregistrement, sinon ils auront le temps de le mettre à jour pendant le transfert, puis ils auront le temps de mettre à jour la mise à jour portable, puis la mise à jour portable, et ainsi de suite à l'infini. Par conséquent, l'enregistrement est bloqué et vous pouvez toujours lire à partir du compartiment. Le transfert de morceaux vers un nouvel endroit commence. Une fois le transfert terminé, le compartiment recommence à accepter les demandes. Dans l'ancien emplacement, il se trouve également toujours, mais il a déjà été marqué comme poubelle et par la suite, le garbage collector le supprimera morceau par morceau.
Chaque compartiment est associé à des métadonnées physiquement stockées sur le disque. Toutes les étapes ci-dessus sont enregistrées sur le disque et, quoi qu'il arrive avec le référentiel, l'état du compartiment sera automatiquement restauré.
Vous pourriez avoir des questions:
- Qu'arrivera-t-il aux demandes qui ont fonctionné avec le compartiment quand elles ont commencé à le porter?
Il existe deux types de liens dans les métadonnées de chaque compartiment: lecture et écriture. Lorsque l'utilisateur fait une demande au compartiment, il indique comment il va l'utiliser, en lecture seule ou en lecture-écriture. Pour chaque demande, le compteur de référence correspondant est incrémenté.
Pourquoi ai-je besoin d'un compteur de référence pour lire les demandes? Disons que le seau est transféré tranquillement, et ici le ramasse-miettes vient et veut supprimer ce seau. Il voit que le nombre de liens est supérieur à zéro, vous ne pouvez donc pas le supprimer. Et lorsque les demandes seront traitées, le garbage collector pourra achever son travail.
Le compteur de référence pour les demandes d'écriture garantit que le compartiment ne commence même pas à être transféré pendant qu'au moins une demande d'écriture fonctionne avec. Mais les demandes d'écriture peuvent venir en permanence, et le bucket ne sera jamais transféré. Le fait est que si l'équilibreur a exprimé le souhait de le transférer, les nouvelles demandes d'enregistrement commenceront à être bloquées et le système actuel attendra la fin d'un certain délai. Si les demandes ne se terminent pas dans le délai imparti, le système recommencera à accepter de nouvelles demandes d'écriture, reportant le transfert du compartiment pendant un certain temps. Ainsi, l'équilibreur effectuera les tentatives de transfert jusqu'à ce que l'une soit réussie.
VShard possède une API bucket_ref de bas niveau au cas où vous auriez peu de fonctionnalités de haut niveau. Si vous voulez vraiment faire quelque chose vous-même, accédez simplement à cette API à partir du code. - Est-il possible de ne pas bloquer du tout les enregistrements?
C'est impossible. Si le compartiment contient des données critiques qui nécessitent un accès constant en écriture, vous devrez bloquer complètement son transfert. Il existe une fonction bucket_pin pour cela, elle attache étroitement le bucket_pin au jeu de répliques actuel, empêchant son transfert. Dans ce cas, le bucket'y voisin pourra se déplacer sans restrictions.

Il existe un outil encore plus puissant que bucket_pin - blocage du jeu de réplicas. Cela ne se fait plus en code, mais en configuration. Le blocage interdit le mouvement de tout bucket'ov de cette réplique set'a et la réception de nouveaux. En conséquence, toutes les données seront disponibles en permanence pour l'enregistrement.

VShard.router
VShard se compose de deux sous-modules: VShard.storage et VShard.router. Ils peuvent être créés et mis à l'échelle indépendamment, même sur une seule instance. Lors de l'accès au cluster, nous ne savons pas où se trouve le compartiment, et VShard.router le recherchera par
bucket id de compartiment pour nous.
Regardons un exemple de ce à quoi cela ressemble. Nous revenons au cluster bancaire et aux comptes clients. Je veux pouvoir retirer tous les comptes d'un client particulier du cluster. Pour ce faire, j'écris la fonction habituelle de recherche locale:
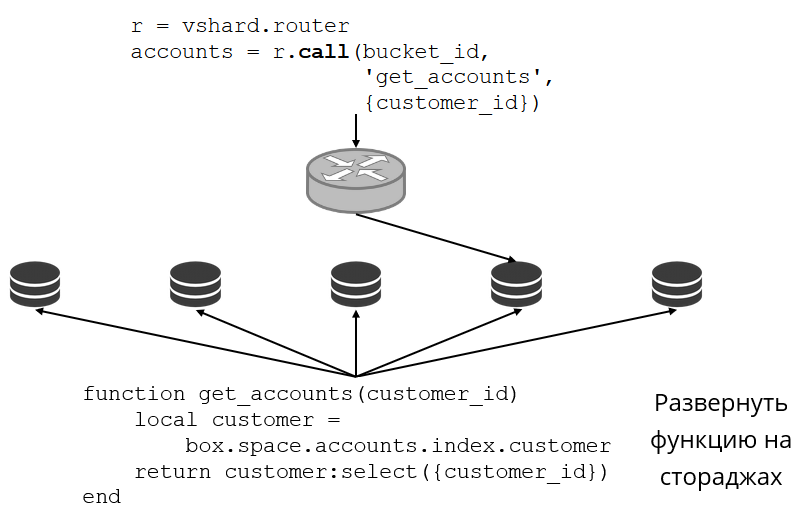
Elle recherche tous les comptes clients par son identifiant. Maintenant, je dois décider lequel des référentiels appeler cette fonction. Pour ce faire, je calcule l'
bucket id de compartiment à partir de l'ID client dans ma demande et demande à VShard.router de m'appeler une telle fonction dans le stockage où réside le compartiment avec l'
bucket id compartiment résultant. Il existe une table de routage dans le sous-module, dans laquelle l'emplacement du compartiment dans le jeu de réplicas est spécifié. Et VShard.router procède par procuration à ma demande.
Bien sûr, il peut arriver qu'à ce moment-là, le resharding commence et que le godet commence à bouger. Le routeur en arrière-plan met progressivement à jour la table en gros morceaux: il interroge les référentiels pour leurs tables de compartiment actuelles.
Il peut même arriver que nous nous tournions vers le bucket qui vient de se déplacer, et le routeur n'a pas encore réussi à mettre à jour sa table de routage. Ensuite, il se tournera vers l'ancien référentiel, et il indiquera au routeur où chercher le compartiment, ou répondra simplement qu'il ne dispose pas des données nécessaires. Ensuite, le routeur fera le tour de tous les stockages à la recherche du seau souhaité. Et tout cela est transparent pour nous, on ne remarquera même pas un manque dans la table de routage.
Lire l'instabilité
Rappelez-vous quels problèmes nous avions initialement:
- Il n'y avait aucune localité de données. Nous avons décidé en ajoutant bucket'ov.
- Le resharding a tout ralenti et ralenti. Implémentation du bucket'ami de transfert de données atomiques, débarrassé des fonctions de recomptage des fragments.
- Lecture instable.
Le dernier problème est résolu par VShard.router en utilisant le sous-système de basculement en lecture automatique.
Le routeur envoie régulièrement un ping au stockage spécifié dans la configuration. Et puis certains d'entre eux ont cessé de cingler. Le routeur dispose d'une connexion de sauvegarde à chaud à chaque réplique et si la connexion actuelle cesse de répondre, elle ira à une autre. La demande de lecture sera traitée normalement, car nous pouvons lire sur des répliques (mais pas écrire). Nous pouvons définir la priorité des répliques par lesquelles le routeur doit sélectionner le basculement pour les lectures. Nous le faisons avec le zonage.
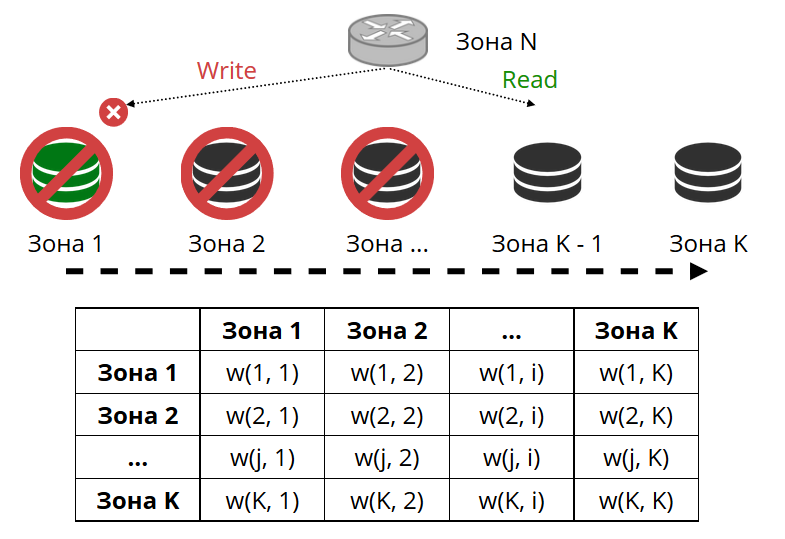
Nous attribuons un numéro de zone à chaque réplique et à chaque routeur et définissons une table dans laquelle nous indiquons la distance entre chaque paire de zones. Lorsque le routeur décide où envoyer une demande de lecture, il sélectionne une réplique dans la zone la plus proche de la sienne.
A quoi cela ressemble dans la configuration:
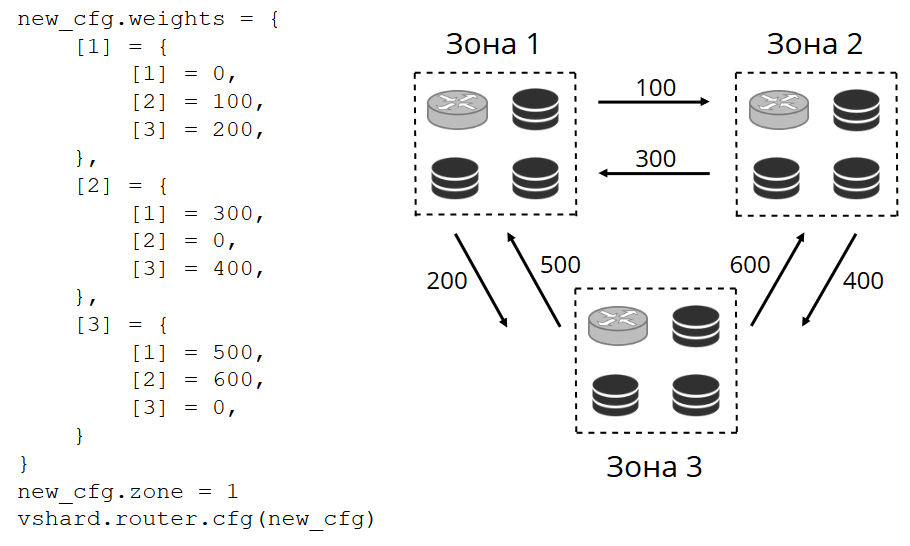
Dans le cas général, vous pouvez faire référence à une réplique arbitraire, mais si le cluster est grand et complexe, très distribué, le zonage est très utile. Différents racks de serveurs peuvent être des zones, afin de ne pas charger le réseau de trafic. Ou il peut s'agir de points géographiquement éloignés les uns des autres.
Le zonage permet également de varier les performances des répliques. Par exemple, dans chaque jeu de réplicas, nous avons un réplica de sauvegarde, qui ne doit pas accepter les demandes, mais uniquement stocker une copie des données. Ensuite, nous le faisons dans la zone, qui sera très loin de tous les routeurs du tableau, et ils se tourneront vers elle dans le cas le plus extrême.
Enregistrement de l'instabilité
Puisque nous parlons de basculement en lecture, qu'en est-il du basculement en écriture lors du changement de l'assistant? Ici, VShard n'est pas si rose: l'élection d'un nouveau maître n'y est pas implémentée, vous devrez le faire vous-même. Lorsque nous l'avons sélectionné d'une manière ou d'une autre, il est nécessaire que cette instance prenne maintenant l'autorité du maître. Nous mettons à jour la configuration en spécifiant
master = false pour l'ancien master, et
master = true pour le nouveau, l'appliquons via VShard.storage.cfg et le roulons vers le stockage. Ensuite, tout se passe automatiquement. L'ancien maître arrête d'accepter les demandes d'écriture et commence à se synchroniser avec le nouveau, car il peut y avoir des données qui ont déjà été appliquées sur l'ancien maître, mais la nouvelle n'est pas encore arrivée. Après cela, le nouveau maître entre dans le rôle et commence à accepter les demandes, et l'ancien maître devient une réplique. Voici comment fonctionne le basculement en écriture dans VShard.
replicas = new_cfg.sharding[uud].replicas replicas[old_master_uuid].master = false replicas[new_master_uuid].master = true vshard.storage.cfg(new_cfg)
Comment maintenant suivre toute cette variété d'événements?
Dans le cas général, deux poignées suffisent -
VShard.storage.info et
VShard.router.info .
VShard.storage.info affiche des informations dans plusieurs sections.
vshard.storage.info() --- - replicasets: <replicaset_2>: uuid: <replicaset_2> master: uri: storage@127.0.0.1:3303 <replicaset_1>: uuid: <replicaset_1> master: missing bucket: receiving: 0 active: 0 total: 0 garbage: 0 pinned: 0 sending: 0 status: 2 replication: status: slave Alerts: - ['MISSING_MASTER', 'Master is not configured for ''replicaset <replicaset_1>']
Le premier est la section de réplication. L'état du jeu de réplicas auquel vous avez appliqué cette fonction s'affiche: quel décalage de réplication il a, avec qui il a des connexions et avec qui il n'est pas disponible, qui est disponible et non disponible, quel assistant est configuré pour quoi, etc.
Dans la section Bucket, vous pouvez voir en temps réel combien de bucket'ov se déplacent actuellement vers le jeu de réplicas actuel, combien le quittent, combien y travaillent actuellement, combien sont marqués comme ordures, combien sont attachés.
La section Alert est un tel méli-mélo de tous les problèmes que VShard a pu déterminer indépendamment: le maître n'est pas configuré, le niveau de redondance est insuffisant, le maître est là, mais toutes les répliques ont échoué, etc.
Et la dernière section est une lumière qui s'allume en rouge lorsque les choses deviennent vraiment mauvaises. C'est un nombre de zéro à trois, plus c'est pire.
VShard.router.info a les mêmes sections, mais elles signifient un peu différentes.
vshard.router.info() --- - replicasets: <replicaset_2>: replica: &0 status: available uri: storage@127.0.0.1:3303 uuid: 1e02ae8a-afc0-4e91-ba34-843a356b8ed7 bucket: available_rw: 500 uuid: <replicaset_2> master: *0 <replicaset_1>: replica: &1 status: available uri: storage@127.0.0.1:3301 uuid: 8a274925-a26d-47fc-9e1b-af88ce939412 bucket: available_rw: 400 uuid: <replicaset_1> master: *1 bucket: unreachable: 0 available_ro: 800 unknown: 200 available_rw: 700 status: 1 alerts: - ['UNKNOWN_BUCKETS', '200 buckets are not discovered']
La première section est la réplication. , : , replica set' , , , replica set' bucket' , .
Bucket bucket', ; bucket' ; , replica set'.
Alert, , , failover, bucket'.
, .
VShard?
— bucket'.
int32_max ? bucket' — 30 16 . bucket', . bucket', bucket'. , .
— -
bucket id . , - , bucket — . , bucket' , VShard bucket'. -, bucket' bucket, -. .
Résumé
Vshard :
- ;
- ;
- ;
- read failover;
- bucket'.
VShard . - . —
. , . .
—
lock-free bucket' . , bucket' . , .
—
. : - , , ? .