Prometheus 2.6.0 optimise le chargement WAL, ce qui accélère le processus de démarrage.
L'objectif non officiel du développement de Prometheus 2.x TSDB est d'accélérer le lancement afin qu'il ne prenne pas plus d'une minute. Ces derniers mois, il a été rapporté que le processus prenait un peu plus de temps, et si Prometheus redémarre pour une raison quelconque, alors c'est déjà un problème. Presque tout ce temps, le WAL (enregistrement de pré-enregistrement) est chargé, qui comprend des échantillons des dernières heures qui n'ont pas encore été compressés dans un bloc. Fin octobre, j'ai finalement réussi à le comprendre; le résultat est PR # 440 , qui réduit le temps CPU de 6,5 fois et le temps de calcul de 4 fois. Voyons comment j'ai apporté ces améliorations.

Tout d'abord, une configuration de test est nécessaire. J'ai créé un petit programme Go qui génère TSDB avec WAL avec un milliard d'échantillons répartis sur 10 000 séries chronologiques. Ensuite, j'ai ouvert ce TSDB et regardé combien de temps il a fallu pour utiliser l'utilitaire de time (pas la structure intégrée, car il n'inclut pas les statistiques de mémoire), et j'ai également créé un profil de processeur à l'aide du package runtime / pprof :
f, err := os.Create("cpu.prof") if err != nil { log.Fatal(err) } pprof.StartCPUProfile(f) defer pprof.StopCPUProfile()
Le profil CPU ne nous permet pas de déterminer directement le temps de calcul qui nous intéresse, cependant, il existe une corrélation significative. En conséquence, sur mon ordinateur de bureau (processeur i7-3770 avec 16 Go de RAM et disques SSD), le téléchargement a pris environ 4 minutes et un peu moins de 6 Go de RAM à son apogée:
1727.50user 16.61system 4:01.12elapsed 723%CPU (0avgtext+0avgdata 5962812maxresident)k 23625165inputs+95outputs (196major+2042817minor)pagefaults 0swaps
Ce n'est pas un buzz, alors chargeons le profil à l'aide de go tool pprof cpu.prof et voyons combien de temps le processus prendra si vous utilisez la commande top .

Ici, flat est le temps passé sur une fonction donnée, et cum est le temps passé sur cette fonction et toutes les fonctions appelées par elle. Il peut également être utile de visualiser ces données dans un graphique pour avoir une idée de la question. Je préfère utiliser la commande web pour cela, mais il existe d'autres options, notamment des fichiers svg, png et pdf.
On peut voir qu'environ un tiers de notre CPU est consacré à l'ajout d'échantillons à la base de données interne, environ les deux tiers au traitement WAL en général et un quart au nettoyage de la mémoire ( runtime.scanobject ). Examinons le code du premier de ces processus en utilisant la list memSeries.*append :
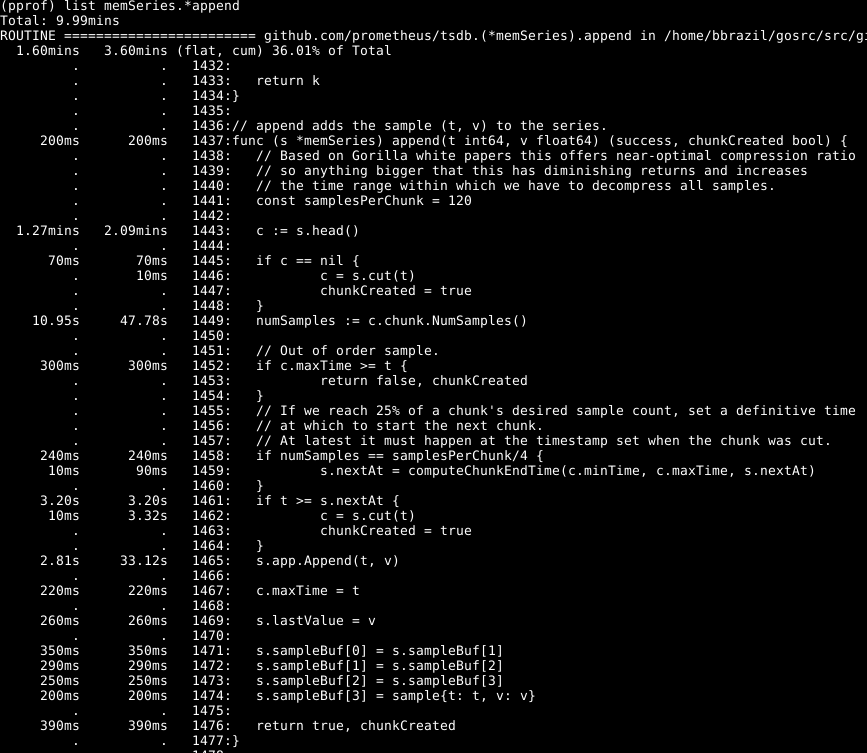
Ce qui suit est frappant ici: plus de la moitié du temps est consacré à l'obtention de la tête de données pour la série à la ligne 1443. De plus, pas mal de temps est consacré à la définition du nombre d'échantillons dans cette donnée à la ligne 1449. Le temps nécessaire pour compléter la ligne 1465 - attendu, car c'est le cœur de l'action de cette fonction. En conséquence, je m'attendais à ce que l'opération prenne la plupart du temps.
Jetez un œil à l'élément memSeries.head : il calcule une donnée qui est renvoyée à chaque fois. Le fragment de données ne change qu'après 120 ajouts, et ainsi, nous pouvons enregistrer le fragment de tête actuel dans la structure de données de la série . Cela occupe une partie de la RAM ( que je reviendrai plus tard ), mais économise une quantité importante de CPU. Et dans l'ensemble, cela accélère également Prometheus.
Head.processWALSamples un œil à Head.processWALSamples :
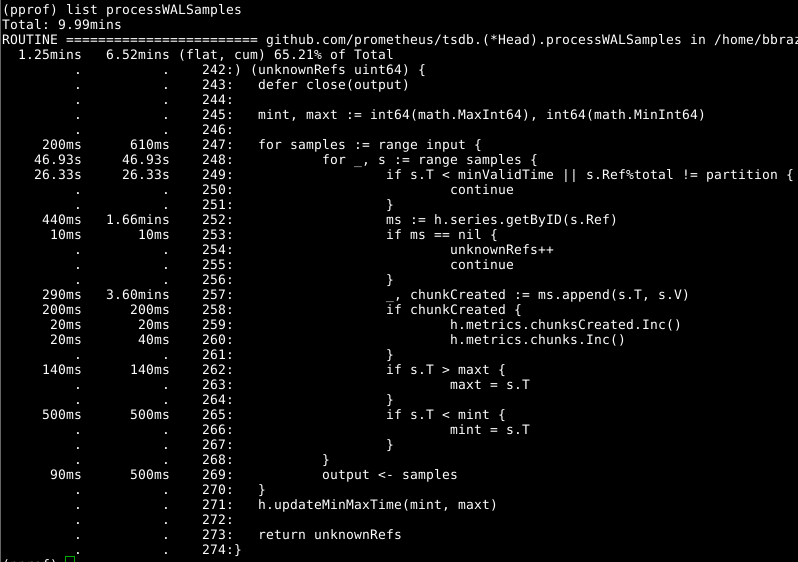
Ce module complémentaire a déjà été optimisé ci-dessus, alors regardez le prochain coupable évident, getByID sur la ligne 252:
(code)
Il semble qu'il y ait une sorte de conflit bloquant, et du temps est perdu à faire une recherche de carte à deux niveaux. Le cache pour chaque identifiant réduit considérablement cet indicateur.
Il vaut la peine de jeter Head.processWALSamples deuxième coup d'œil à Head.processWALSamples , et vous êtes surpris du temps passé sur la ligne 249. Revenons un peu à la question du fonctionnement du chargement WAL: Head.processWALSamples Head.processWALSamples est créé pour chaque CPU disponible, en plus d'un autre pour la lecture et décodage WAL du disque. Les rangées sont segmentées par ces goroutines, la concurrence peut donc être un avantage. La méthode de mise en œuvre est la suivante: tous les échantillons sont envoyés à la première gorutine, qui traite les éléments dont elle a besoin. Elle envoie ensuite tous les échantillons à la deuxième gorutine, qui traite les éléments dont elle a besoin, et ainsi de suite, jusqu'à ce que la dernière gorutine, Head.processWALSamples renvoie toutes les données à la gorutine de contrôle.
En attendant, des modules complémentaires sont répartis sur les noyaux - ce dont vous avez besoin - et de nombreuses tâches en double sont effectuées dans chaque gorutine, qui doit traiter tous les échantillons et calculer le module. En fait, plus il y a de cœurs, plus le travail est dupliqué. J'ai apporté des modifications pour segmenter les données dans la gourutin du contrôleur, afin que chaque gorutine de Head.processWALSamples ne Head.processWALSamples désormais que les échantillons dont elle a besoin . Sur mon ordinateur - 8 exécutant gorutin - le temps de calcul a été enregistré un peu, mais le volume du processeur était décent. Pour les ordinateurs avec un grand nombre de cœurs, les avantages devraient être plus importants.
Et encore une fois, nous revenons à la question: le temps de vider la mémoire. Nous ne pouvons pas (généralement) déterminer cela par le biais de profils CPU. Faites plutôt attention aux profils de mémoire dynamique pour trouver les éléments qui se démarquent. Cela nécessite une certaine extension de code à la fin du programme:
runtime.GC() hf, err := os.Create("heap.prof") if err != nil { log.Fatal(err) } pprof.WriteHeapProfile(hf)
Le nettoyage formel de la mémoire est associé à certaines informations de la mémoire dynamique, dont la collecte et le nettoyage sont effectués uniquement pendant le nettoyage de la mémoire.
Nous utilisons à nouveau le même outil, mais -alloc_space étiquette -alloc_space , car nous nous intéressons à toutes les opérations d'allocation de mémoire, et pas seulement aux opérations qui utilisent la mémoire à un moment particulier; ainsi, exécutez go tool pprof -alloc_space heap.prof . Si vous regardez le distributeur supérieur, le coupable est évident:
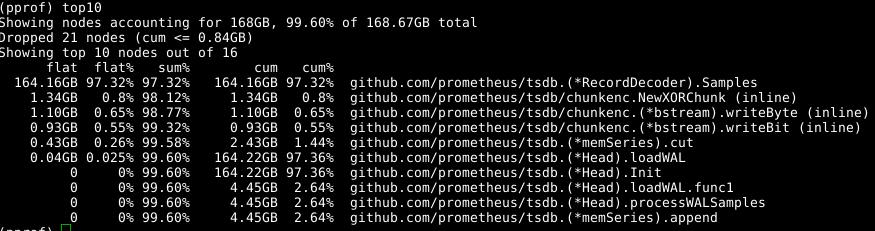
Jetez un œil au code:
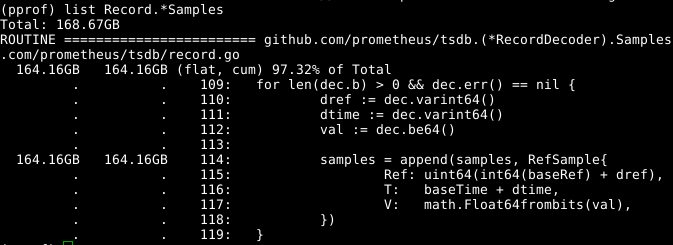
Le tableau d' samples extensible semble être un problème. Si nous pouvions réutiliser le tableau en même temps que d'appeler RecordDecoder.Samples , cela économiserait une quantité importante de mémoire. Il s'avère que le code a été composé de cette façon, mais une petite erreur de codage a conduit au fait qu'il ne fonctionnait pas. Si vous le corrigez , la mémoire est effacée en 8 secondes du CPU au lieu de 151 secondes.
Les résultats globaux sont assez tangibles:
269.18user 10.69system 1:05.58elapsed 426%CPU (0avgtext+0avgdata 3529556maxresident)k 23174929inputs+70outputs (815major+1083172minor)pagefaults 0swap
Nous avons non seulement réduit le temps de calcul de 4 fois et le temps CPU - de 6,5 fois, mais également la quantité de mémoire occupée est réduite de plus de 2 Go.
Il semble que tout soit simple, mais l'astuce est la suivante: j'ai décemment fouillé dans la base de code et analysé tout comme avec le recul. En étudiant le code, je me suis retrouvé dans une impasse plusieurs fois, par exemple, lors de la suppression d'un appel NumSamples , de la lecture et du décodage dans des threads séparés, ainsi que de plusieurs manières pour segmenter processWALSamples . Je suis presque sûr qu'en régulant le nombre de gorutins, on peut faire plus, mais pour cela les tests doivent être effectués sur des machines plus puissantes que les miennes, pour qu'il y ait plus de noyaux. J'ai atteint mon objectif: la productivité a augmenté et j'ai réalisé qu'il valait mieux ne pas rendre le registre du programme trop volumineux et j'ai donc décidé de m'arrêter là.