Les architectures de centres de données à usage général (ces centres de données sont encore largement utilisés aujourd'hui) ont bien fonctionné dans le passé, mais la plupart d'entre eux ont récemment atteint leurs limites d'évolutivité, de performances et d'efficacité. L'architecture de ces centres de données utilise généralement le principe de l'allocation globale des ressources - processeurs, disques durs et largeurs de canaux réseau.
Dans ce cas, un changement du volume des ressources utilisées (augmentation ou diminution) se produit discrètement dans ces centres de données, avec des coefficients prédéterminés. Par exemple, avec un coefficient de 2, nous pouvons obtenir cette série de configurations:
- 2 processeurs, 8 Go de RAM, 40 Go de stockage;
- 4CPU, 16 Go de RAM, 80 Go de stockage;
- 8CPU, 32 Go de RAM, 160 Go de stockage;
- ...
Cependant, pour de nombreuses tâches, ces configurations sont économiquement inefficaces, souvent une configuration intermédiaire est suffisante pour les clients, par exemple, - 6 CPU, 16 Go de RAM, 100 Go de stockage. Ainsi, nous arrivons à la compréhension que l'approche universelle ci-dessus pour l'allocation des ressources du centre de données est inefficace, en particulier lorsque vous travaillez intensivement avec les mégadonnées (par exemple, données rapides, analyses, intelligence artificielle, apprentissage automatique). Dans de tels cas, les utilisateurs veulent avoir des capacités de contrôle plus flexibles des ressources utilisées, ils ont besoin de pouvoir évoluer indépendamment les processeurs, la mémoire et le stockage de données, les canaux réseau. Le but ultime de cette idée est de créer une infrastructure de composants flexible.
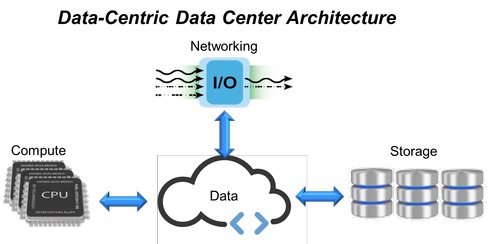 Fig. 1. Architecture de centre de données centrée sur les données.
Fig. 1. Architecture de centre de données centrée sur les données.En réponse à ces exigences, des centres de données à infrastructure hyperconvergée (HCI, Hyper-Converged Infrastructure) combinent toutes les ressources informatiques, les systèmes de stockage et les canaux réseau en un seul système virtualisé (Fig.1). Cependant, dans cette structure, pour étendre les limites de l'évolutivité (ajout de nouveaux systèmes de stockage, de mémoire ou de canaux réseau), des serveurs supplémentaires sont nécessaires. Cela a prédéterminé l'apparition d'une approche basée sur l'expansion de l'infrastructure HCI avec des modules fixes (dont chacun contient des processeurs, de la mémoire et du stockage de données), ce qui en fin de compte n'offre pas le niveau de flexibilité et de performance prévisible qui est si demandé dans les centres de données modernes.
HCI est déjà remplacé par des infrastructures désagrégées en composants (CDI, Composable-Disaggregated Infrastructures), conçues pour surmonter les limites des solutions informatiques convergées ou hyperconvergées et offrir une meilleure flexibilité aux centres de données.
L'avènement d'une infrastructure ventilée par composantsPour surmonter les problèmes liés à l'architecture des centres de données à usage général (ratio fixe de ressources, sous-utilisation et redondance), une infrastructure convergente a d'abord été développée, composée de ressources matérielles préconfigurées au sein d'un même système. Les ressources informatiques, les systèmes de stockage et les interactions réseau qui s'y trouvent sont discrets et les volumes de leur consommation sont configurés par programme. Ensuite, les structures convergentes ont été transformées en hyperconvergées (HCI), où toutes les ressources matérielles sont virtualisées, et l'allocation des quantités nécessaires de ressources informatiques, de stockage et de canaux réseau est automatisée au niveau logiciel.
Malgré le fait que HCI intègre toutes les ressources dans un seul système virtualisé, cette approche a également ses inconvénients. Pour ajouter au client, par exemple, une quantité beaucoup plus importante de stockage, de RAM ou d'étendre le canal réseau, dans l'architecture HCI, cela nécessitera l'utilisation de modules de processeur supplémentaires, même s'ils ne seront pas utilisés directement pour les opérations informatiques. En conséquence, nous avons une situation où, lors de la création de centres de données plus flexibles que les architectures précédentes, ils utilisent toujours des éléments de construction inflexibles.
Selon les enquêtes auprès des utilisateurs informatiques des centres de données d'entreprise de moyenne et grande taille, environ 50% de la capacité de stockage totale disponible est allouée à une utilisation réelle, tandis que les applications n'utilisent que la moitié du volume de stockage alloué, et le temps CPU est également utilisé par environ 50%. Ainsi, l'approche utilisant des systèmes structurels fixes conduit à leur sous-charge et ne fournit pas la flexibilité nécessaire et les performances prévisibles. Pour résoudre ces problèmes, un modèle désagrégé a été créé, qui est facile à assembler à partir de modules fonctionnels séparés à l'aide d'outils logiciels avec une API ouverte.
L'infrastructure désagrégée de composants (CDI) est une architecture de centre de données dans laquelle les ressources physiques - puissance de calcul, stockage et canaux réseau - sont traitées comme des services. Fournir aux applications utilisateur toutes les ressources nécessaires pour remplir leur charge actuelle se produit en temps réel, ce qui permet d'atteindre des performances optimales au sein du centre de données.
Modèle anti-convergence désagrégé par composants
Les serveurs virtuels dans une infrastructure désagrégée en composants (Fig.2) sont créés en reliant les ressources de pools indépendants de systèmes informatiques, de stockage et de périphériques réseau, contrairement à HCI, où les ressources physiques sont liées aux serveurs HCI. De cette façon, les serveurs CDI peuvent être créés et reconfigurés selon les besoins en fonction des exigences d'une charge de travail particulière. En utilisant l'accès API au logiciel de virtualisation, l'application peut demander toutes les ressources nécessaires, recevoir une reconfiguration instantanée du serveur en temps réel, sans intervention humaine - une véritable étape vers un centre de données autogéré.
 Fig. 2: Modèle hyperconvergé (HCI) et Composant désagrégé (CDI).
Fig. 2: Modèle hyperconvergé (HCI) et Composant désagrégé (CDI).Une partie importante de l'architecture CDI est l'interface de communication interne, qui assure la séparation (désagrégation) des périphériques de stockage d'un serveur particulier de sa puissance de calcul et leur mise à disposition pour une utilisation par d'autres applications.
NVMe-over-Fabrics est utilisé ici comme protocole principal. Il fournit les plus petits retards de transfert de données de bout en bout entre les applications et les périphériques de stockage eux-mêmes. En conséquence, cela permet à CDI de fournir aux utilisateurs tous les avantages du stockage à connexion directe (faible latence et hautes performances), offrant réactivité et flexibilité grâce au partage des ressources.
 Fig. 3. La structure de NVMe-over-Fabrics.
Fig. 3. La structure de NVMe-over-Fabrics.La technologie NVMe (Non-Volatile Memory Express) elle-même est une interface optimisée, hautes performances et à faible latence qui utilise une architecture et un ensemble de protocoles spécialement conçus pour connecter des SSD à des serveurs via le bus PCI Express. Pour CDI, cette norme a été étendue à NVMe-over-Fabrics - au-delà des serveurs locaux.
Cette spécification permet aux périphériques flash de communiquer sur le réseau (en utilisant différents protocoles réseau et supports de transmission - voir la figure 3), offrant les mêmes performances élevées et un délai de transmission aussi faible que les périphériques NVMe locaux. Dans le même temps, il n'y a pratiquement aucune restriction sur le nombre de serveurs pouvant partager des périphériques NVMe-over-Fabrics ou sur le nombre de ces périphériques de stockage accessibles par un serveur.
Les besoins des applications intensives de Big Data d'aujourd'hui dépassent les capacités des architectures de datacenter traditionnelles, notamment en termes d'évolutivité, de performances et d'efficacité. Avec l'avènement du CDI (infrastructure désagrégée par composants), les architectes de centres de données, les fournisseurs de services cloud, les intégrateurs de systèmes, les développeurs de stockage et les OEM peuvent fournir des services de stockage et d'informatique avec une plus grande rentabilité, flexibilité, efficacité et facilité d'évolutivité, fournissant dynamiquement le SLA requis pour tout le monde charges de travail.