Salut Je m'appelle Ivan Smurov et je dirige le groupe de recherche PNL chez ABBYY. Vous pouvez lire ce que notre groupe fait
ici . J'ai récemment donné une conférence sur le traitement automatique du langage naturel (NLP) à la
School of Deep Learning - c'est un groupe à la PhysTech School of Applied Mathematics and Computer Science au MIPT pour les étudiants seniors intéressés par la programmation et les mathématiques. Peut-être que les thèses de ma conférence seront utiles à quelqu'un, alors je les partagerai avec Habr.
Puisque tout ne peut pas être saisi à la fois, nous diviserons l'article en deux parties. Aujourd'hui, je vais parler de la façon dont les réseaux de neurones (ou l'apprentissage en profondeur) sont utilisés dans la PNL. Dans la deuxième partie de l'article, nous nous concentrerons sur l'une des tâches PNL les plus courantes - la tâche d'extraction d'entités nommées (reconnaissance d'entité nommée, NER) et analyser en détail l'architecture de ses solutions.
Qu'est-ce que la PNL?
Il s'agit d'un large éventail de tâches pour le traitement de textes dans une langue naturelle (c'est-à-dire la langue que les gens parlent et écrivent). Il existe un ensemble de tâches PNL classiques, dont la solution est pratique.
- La première et la plus importante tâche historique est la traduction automatique. Il est pratiqué depuis très longtemps et il y a d'énormes progrès. Mais la tâche d'obtenir une traduction entièrement automatique de haute qualité (FAHQMT) n'est toujours pas résolue. D'une certaine manière, c'est le moteur NLP, l'une des plus grandes tâches que vous pouvez faire.

- La deuxième tâche est la classification des textes. Un ensemble de textes est donné et la tâche consiste à classer ces textes en catégories. Lequel? C'est une question pour le corps.
Le premier et l'un des moyens les plus pratiques de l'appliquer d'un point de vue pratique est la classification des lettres en spam et en rogne (pas en spam).
Une autre option classique est la classification multiclasse des nouvelles en catégories (rubrication) - politique étrangère, sport, chapiteau, etc. Ou, disons, vous recevez des lettres et vous souhaitez séparer les commandes de la boutique en ligne des billets d'avion et des réservations d'hôtel.
La troisième application classique du problème de classification des textes est l'analyse sentimentale. Par exemple, la classification des avis comme positifs, négatifs et neutres.
Étant donné qu'il existe de nombreuses catégories possibles dans lesquelles vous pouvez diviser des textes, la classification des textes est l'une des tâches pratiques les plus populaires de la PNL. - La troisième tâche consiste à récupérer les entités nommées, NER. Nous sélectionnons dans les sections de texte qui correspondent à un ensemble présélectionné d'entités, par exemple, vous devez trouver tous les emplacements, personnes et organisations dans le texte. Dans le texte «Ostap Bender - Directeur du bureau« Horns and Hooves »», vous devez comprendre que Ostap Bender est une personne et que «Horns and Hooves» est une organisation. Pourquoi cette tâche est nécessaire dans la pratique et comment la résoudre, nous parlerons dans la deuxième partie de notre article.
 La quatrième tâche est liée à la troisième - la tâche d'extraire des faits et des relations (extraction de relations). Par exemple, il y a une attitude de travail (Profession). D'après le texte «Ostap Bender - Directeur du bureau« Horns and Hooves »», il est clair que notre héros est lié aux relations professionnelles avec «Horns and Hooves». La même chose peut être dite de bien d'autres façons: «Le bureau d'Ostap Bender est dirigé par le bureau« Horns and Hooves », ou« Ostap Bender est passé du simple fils du lieutenant Schmidt au chef du bureau «Horns and Hooves». Ces phrases diffèrent non seulement par leur prédicat, mais aussi par leur structure.
La quatrième tâche est liée à la troisième - la tâche d'extraire des faits et des relations (extraction de relations). Par exemple, il y a une attitude de travail (Profession). D'après le texte «Ostap Bender - Directeur du bureau« Horns and Hooves »», il est clair que notre héros est lié aux relations professionnelles avec «Horns and Hooves». La même chose peut être dite de bien d'autres façons: «Le bureau d'Ostap Bender est dirigé par le bureau« Horns and Hooves », ou« Ostap Bender est passé du simple fils du lieutenant Schmidt au chef du bureau «Horns and Hooves». Ces phrases diffèrent non seulement par leur prédicat, mais aussi par leur structure.
Des exemples d'autres relations qui sont souvent mises en évidence sont l'achat et la vente, la propriété, le fait de la naissance avec des attributs - date, lieu, etc. (naissance) et quelques autres.
La tâche ne semble pas avoir d'application pratique évidente, mais elle est néanmoins utilisée dans la structuration d'informations non structurées. De plus, il est important dans les systèmes de questions-réponses et de dialogue, dans les moteurs de recherche - toujours lorsque vous devez analyser une question et comprendre à quel type elle se rapporte, ainsi que les restrictions qui existent sur la réponse.

- Les deux tâches suivantes sont probablement les plus hype. Ce sont des systèmes de questions-réponses et de dialogue (chat bots). Amazon Alexa, Alice sont des exemples classiques de systèmes conversationnels. Pour qu'ils fonctionnent correctement, de nombreuses tâches PNL doivent être résolues. Par exemple, la classification de texte permet de déterminer si nous tombons dans l'un des scénarios de chatbot orientés objectif. Supposons que "la question des taux de change". L'extraction des relations est nécessaire pour identifier les espaces réservés pour le modèle de script, et la tâche de mener un dialogue sur des sujets communs («orateurs») nous aidera dans une situation où nous ne sommes tombés dans aucun des scénarios.
Les systèmes de questions-réponses sont également une chose compréhensible et utile. Vous posez une question à une voiture, la voiture cherche une réponse dans une base de données ou un corps de texte. IBM Watson ou Wolfram Alpha sont des exemples de tels systèmes. - Un autre exemple du problème classique de la PNL est la sammarisation. L'énoncé du problème est simple: le système d'entrée accepte un texte volumineux et la sortie est un texte plus petit, reflétant en quelque sorte le contenu d'un texte volumineux. Par exemple, une machine est nécessaire pour générer une nouvelle narration d'un texte, de son nom ou de son annotation.

- Une autre tâche populaire est l'exploration d'argumentation, la recherche de justification dans le texte. On vous donne un fait et un texte, vous devez trouver une justification à ce fait dans le texte.
Ce n'est en aucun cas la liste complète des tâches PNL. Il y en a des dizaines. Dans l'ensemble, tout ce qui peut être fait avec du texte dans une langue naturelle peut être attribué aux tâches de la PNL, seuls les sujets énumérés sont à l'oreille et ils ont les applications pratiques les plus évidentes.
Pourquoi est-il difficile de résoudre des tâches PNL?
La formulation des tâches n'est pas très compliquée, mais les tâches elles-mêmes ne sont pas du tout simples, car nous travaillons avec le langage naturel. Les phénomènes de polysémie (les mots polysémiques ont une signification initiale commune) et d'homonymie (les mots ayant des sens différents sont prononcés et écrits de la même manière) sont caractéristiques de tout langage naturel. Et si un locuteur natif du russe comprend bien que
l'accueil chaleureux a peu de choses en commun avec la
technique de combat , d'une part, et la
bière chaude , d'autre part, le système automatique doit l'apprendre depuis longtemps. Pourquoi est-il préférable de traduire «
Appuyez sur la barre d'espace pour continuer » en ennuyeux «
Pour continuer, appuyez sur la barre d'espace » que «La
barre de presse d'espace continuera de fonctionner ».
- Polysémie: arrêt (processus ou bâtiment), table (organisation ou objet), pic (oiseau ou personne).
- Homonymie: clé, arc, serrure, poêle.

- Un autre exemple classique de la complexité du langage est le pronom anaphore. Par exemple, donnons-nous le texte " Concierge deux heures de neige, il était mécontent ". Le pronom «il» peut désigner à la fois le concierge et la neige. Par contexte, on comprend facilement que c'est un concierge, pas de la neige. Mais pour que l'ordinateur le comprenne aussi facilement, ce n'est pas facile. Le problème du pronom anaphore n'est pas encore très bien résolu; les tentatives actives pour améliorer la qualité des décisions se poursuivent.
- Une autre complexité supplémentaire est l'ellipse. Par exemple, " Petya a mangé une pomme verte et Masha en a mangé une rouge ." Nous comprenons que Masha a mangé une pomme rouge. Cependant, il n'est pas facile de faire comprendre cela à la machine. Maintenant, la tâche de restaurer les ellipses est résolue sur de minuscules cas (plusieurs centaines de phrases), et sur eux la qualité de la restauration complète est franchement faible (de l'ordre de 0,5). Il est clair que pour des applications pratiques, une telle qualité n'est pas bonne.
Soit dit en passant, cette année, lors de la conférence
Dialogue , des pistes auront lieu à la fois sur l'anaphore et sur les espaces (un type d'ellipse) pour la langue russe. Pour les deux tâches, les caisses ont été assemblées avec un volume plusieurs fois supérieur aux volumes des bâtiments existants (de plus, pour les espaces, le volume de la valise est d'un ordre de grandeur supérieur aux volumes des valises, non seulement pour le russe, mais pour toutes les langues en général). Si vous souhaitez participer à des compétitions dans ces bâtiments,
cliquez ici (avec inscription, mais sans SMS) .
Comment les tâches PNL sont résolues
Contrairement au traitement d'image, vous pouvez toujours trouver des articles sur la PNL qui décrivent des solutions qui utilisent des algorithmes classiques tels que
SVM ou
Xgboost , pas des réseaux de neurones, et qui montrent des résultats qui ne sont pas trop inférieurs aux solutions de pointe.
Cependant, il y a plusieurs années, les réseaux de neurones ont commencé à vaincre les modèles classiques. Il est important de noter que pour la plupart des tâches, les solutions basées sur des méthodes classiques étaient uniques, en règle générale, pas similaires à la résolution d'autres problèmes à la fois dans l'architecture et dans la façon dont la collecte et le traitement des attributs se produisent.
Cependant, les architectures de réseaux de neurones sont beaucoup plus générales. L'architecture du réseau lui-même, très probablement, est également différente, mais beaucoup plus petite, il y a une tendance à l'universalisation complète. Cependant, avec quelles fonctionnalités et comment nous travaillons exactement, c'est déjà presque la même chose pour la plupart des tâches PNL. Seules les dernières couches des réseaux de neurones diffèrent. Ainsi, nous pouvons supposer qu'un seul pipeline NLP a été formé. Sur la façon dont il est organisé, nous allons maintenant vous en dire plus.
Pipeline nlp
Cette façon de travailler avec les enseignes, qui est plus ou moins la même pour toutes les tâches.
En ce qui concerne la langue, l'unité de base avec laquelle nous travaillons est le mot. Ou plus formellement un "jeton". Nous utilisons ce terme parce qu'il n'est pas très clair ce qu'est 2128506 - est-ce un mot ou pas? La réponse n'est pas évidente. Le jeton est généralement séparé des autres jetons par des espaces ou des signes de ponctuation. Et comme vous pouvez le comprendre à partir des difficultés que nous avons décrites ci-dessus, le contexte de chaque jeton est très important. Il existe différentes approches, mais dans 95% des cas, le contexte pris en compte lors de l'exécution du modèle est la proposition, y compris le jeton d'origine.
De nombreuses tâches sont généralement résolues au niveau de la proposition. Par exemple, la traduction automatique. Plus souvent qu'autrement, nous traduisons simplement une phrase et n'utilisons pas du tout un contexte plus large. Il y a des tâches où ce n'est pas le cas, par exemple, les systèmes de dialogue. Il est important de se rappeler de quoi le système a été question auparavant afin qu'il puisse répondre aux questions. Cependant, l'offre est également l'unité principale avec laquelle nous travaillons.
Par conséquent, les deux premières étapes du pipeline qui sont effectuées pour résoudre presque toutes les tâches sont la segmentation (division du texte en phrases) et la tokenisation (division des phrases en jetons, c'est-à-dire des mots individuels). Cela se fait avec des algorithmes simples.
Ensuite, vous devez calculer les caractéristiques de chaque jeton. En règle générale, cela se produit en deux étapes. La première consiste à calculer des attributs de jeton indépendants du contexte. Il s'agit d'un ensemble de signes qui ne dépendent en aucun cas d'autres mots entourant notre jeton. Les attributs communs indépendants du contexte sont:
- plongements
- signes symboliques
- fonctionnalités supplémentaires spécifiques à une tâche ou une langue particulière
Nous parlerons des encastrements et des signes symboliques plus en détail ci-dessous (à propos des signes symboliques - pas aujourd'hui, mais dans la deuxième partie de notre article), mais pour l'instant donnons des exemples possibles de signes supplémentaires.
L'une des fonctionnalités les plus couramment utilisées est la partie de la parole ou la balise POS (partie de la parole). Ces fonctionnalités peuvent être importantes pour résoudre de nombreux problèmes, par exemple les tâches d'analyse. Pour les langues à morphologie complexe, comme la langue russe, les caractères morphologiques sont également importants: par exemple, dans quel cas est le nom, quel type d'adjectif. Nous pouvons en tirer différentes conclusions sur la structure de la proposition. De plus, la morphologie est nécessaire pour la lemmatisation (réduction des mots aux formes initiales), à l'aide de laquelle nous pouvons réduire la dimension de l'espace attributaire, et donc l'analyse morphologique est activement utilisée pour la plupart des problèmes de PNL.
Lorsque nous résolvons un problème où l'interaction entre différents objets est importante (par exemple, dans la tâche d'extraction de relation ou lors de la création d'un système de questions-réponses), nous devons en savoir beaucoup sur la structure de la proposition. Cela nécessite une analyse. À l'école, tout le monde a analysé une phrase pour un sujet, un prédicat, un ajout, etc. L'analyse syntaxique est quelque chose dans cet esprit, mais plus compliqué.
Un autre exemple de fonctionnalité supplémentaire est la position du jeton dans le texte. On peut savoir a priori qu'une entité se retrouve le plus souvent au début du texte ou vice versa à la fin.
Tous ensemble - encastrements, signes symboliques et additionnels - forment un vecteur de signes symboliques qui ne dépend pas du contexte.
Fonctionnalités contextuelles
Les signes de jeton contextuels sont un ensemble de signes qui contient des informations non seulement sur le jeton lui-même, mais aussi sur ses voisins. Il existe différentes façons de calculer ces symptômes. Dans les algorithmes classiques, les gens marchaient souvent simplement par la «fenêtre»: ils prenaient plusieurs (par exemple, trois) jetons à l'original et plusieurs jetons après, puis calculaient tous les signes dans une telle fenêtre. Cette approche n'est pas fiable, car des informations importantes pour l'analyse peuvent être à une distance supérieure à la fenêtre, respectivement, nous pouvons manquer quelque chose.
Par conséquent, toutes les fonctionnalités contextuelles sont désormais calculées au niveau de la proposition de manière standard: en utilisant des réseaux de neurones récurrents bidirectionnels LSTM ou GRU. Pour obtenir des attributs de jeton contextuels à partir d'indépendants du contexte, les attributs indépendants du contexte de tous les jetons d'offre sont soumis au RNN bidirectionnel (simple ou multicouche). La sortie du RNN bidirectionnel au i-ème instant dans le temps est un signe contextuel du i-token, qui contient des informations sur les deux jetons précédents (puisque ces informations sont contenues dans la i-ème valeur du RNN direct), et sur les suivants (t .k. cette information est contenue dans la valeur correspondante du RNN inverse).
De plus, pour chaque tâche individuelle, nous faisons quelque chose de différent, mais les premières couches - jusqu'au RNN bidirectionnel, peuvent être utilisées pour presque toutes les tâches.
Cette méthode d'obtention de fonctionnalités est appelée pipeline NLP.
Il convient de noter qu'au cours des 2 dernières années, les chercheurs ont activement essayé d'améliorer le pipeline NLP - à la fois en termes de vitesse (par exemple, le transformateur - une architecture basée sur l'auto-attention qui ne contient pas de RNN et est donc capable d'apprendre et d'appliquer plus rapidement), et avec point de vue des signes utilisés (maintenant ils utilisent activement des signes basés sur des modèles de langage pré-formés, par exemple
ELMo , ou ils utilisent les premières couches du modèle de langage pré-formé et les recyclent dans le cas disponible pour la tâche -
ULMFit ,
BERT ).
Intégrations sous forme de mots
Examinons de plus près ce qu'est l'intégration. En gros, l'incorporation est une représentation concise du contexte d'un mot. Pourquoi est-il important de connaître le contexte d'un mot? Parce que nous croyons en une hypothèse de distribution - que des mots qui ont un sens similaire sont utilisés dans des contextes similaires.
Essayons maintenant de donner une définition rigoureuse de l'incorporation. L'incorporation est une cartographie d'un vecteur discret de caractéristiques catégorielles dans un vecteur continu avec une dimension prédéterminée.
Un exemple canonique d'intégration est l'intégration de mots (intégration sous forme de mots).
Qu'est-ce qui agit habituellement comme vecteur d'entités discrètes? Un vecteur booléen correspondant à toutes les valeurs possibles d'une certaine catégorie (par exemple, toutes les parties possibles du discours ou tous les mots possibles d'un dictionnaire limité).
Pour les intégrations sous forme de mots, cette catégorie est généralement l'index du mot dans le dictionnaire. Disons qu'il existe un dictionnaire avec une dimension de 100 000. En conséquence, chaque mot a un vecteur caractéristique discret - un vecteur booléen de dimension 100 000, où à un endroit (l'index du mot dans notre dictionnaire) est un, et les autres sont des zéros.
Pourquoi voulons-nous mapper nos vecteurs d'entités discrètes à des dimensions données continues? Parce que les vecteurs avec une dimension de 100 000 ne sont pas très pratiques à utiliser pour les calculs, mais les vecteurs d'entiers de dimensions 100, 200 ou, par exemple, 300, sont beaucoup plus pratiques.
En principe, nous ne pouvons pas essayer d'imposer des restrictions supplémentaires sur une telle cartographie. Mais puisque nous construisons un tel mappage, essayons de nous assurer que les vecteurs de mots de même signification sont également proches dans un certain sens. Cela se fait à l'aide d'un simple réseau neuronal à action directe.
Intégrer la formation
Comment les plongements sont-ils formés? Nous essayons de résoudre le problème de la restauration d'un mot par contexte (ou vice versa, la restauration d'un contexte par mot). Dans le cas le plus simple, nous obtenons l'index dans le dictionnaire du mot précédent (le vecteur booléen de la dimension du dictionnaire) en entrée et essayons de déterminer l'index dans le dictionnaire de notre mot. Cela se fait à l'aide d'une grille avec une architecture extrêmement simple: deux couches entièrement connectées. Vient d'abord une couche entièrement connectée du vecteur booléen de la dimension du dictionnaire à la couche cachée de la dimension d'incorporation (c'est-à-dire multipliant simplement le vecteur booléen par la matrice de la dimension souhaitée). Et puis vice versa, une couche entièrement connectée avec softmax à partir d'une couche cachée de dimension incorporée dans un vecteur de dimension de dictionnaire. Grâce à la fonction d'activation softmax, nous obtenons la distribution de probabilité de notre mot et pouvons choisir l'option la plus probable.
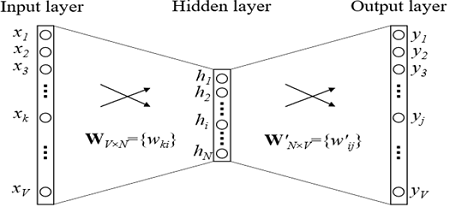
Dans les modèles utilisés en pratique, l'architecture est plus complexe, mais pas beaucoup. La principale différence est que nous utilisons non pas un vecteur du contexte pour définir notre mot, mais plusieurs (par exemple, tout dans une fenêtre de taille 3). Une option légèrement plus populaire consiste à prédire non pas un mot par contexte, mais plutôt un contexte par mot. Cette approche est appelée Skip-gram.
Donnons un exemple de l'application d'une tâche qui est résolue lors de la formation des plongements (dans la variante CBOW, prédictions de mots par contexte). Par exemple, supposons qu'un contexte de jeton se compose de 2 mots précédents. “ ”, , , “”.
, ( ), , .
, , , (, , ). — .
, , . , , , .
, — ELMo, ULMFit, BERT. , ( , , , ).
?
, 2 .
- -, , , - 100 . – : , , .
- -, . -. . . , , . , , . . , , .
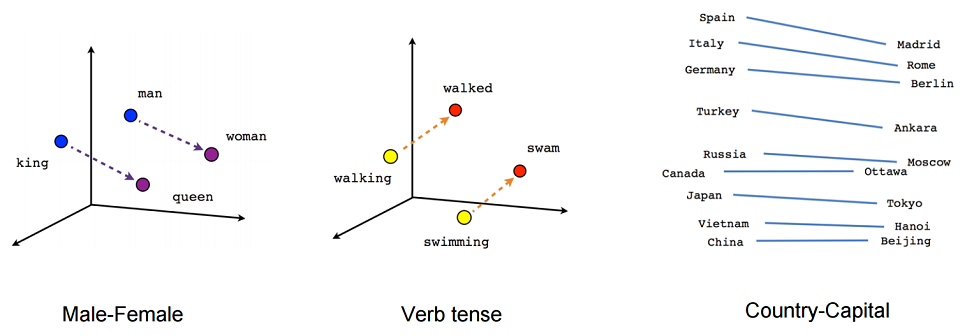
, .
, , , , , . , , , , .
NER. , , . , , , , .