
Début 2018, un article a été publié. L'apprentissage par renforcement profond ne fonctionne pas encore ("L'apprentissage par renforcement ne fonctionne pas encore."). La principale plainte était que les algorithmes d'apprentissage modernes avec renforcement nécessitent environ le même temps pour résoudre un problème qu'une recherche aléatoire régulière.
Depuis, quelque chose a-t-il changé? Non.
L'apprentissage renforcé est considéré comme l'un des trois principaux moyens de construire une IA forte. Mais les difficultés rencontrées dans ce domaine de l'apprentissage automatique et les méthodes que les scientifiques tentent de résoudre ces difficultés suggèrent qu'il peut y avoir des problèmes fondamentaux avec cette approche elle-même.
Attendez, qu'est-ce que l'un des trois signifie? Quels sont les deux autres?
Compte tenu du succès des réseaux de neurones ces dernières années et de l'analyse de leur fonctionnement avec des capacités cognitives de haut niveau, qui étaient auparavant considérées comme caractéristiques uniquement des humains et des animaux supérieurs, aujourd'hui, dans la communauté scientifique, il existe une opinion selon laquelle il existe trois approches principales pour créer une IA forte sur la base de réseaux de neurones, qui peuvent être considérés comme plus ou moins réalistes:
1. Traitement de texte
Le monde a accumulé un grand nombre de livres et de textes sur Internet, y compris des manuels et des livres de référence. Le texte est pratique et rapide pour un traitement sur ordinateur. Théoriquement, cet ensemble de textes devrait suffire à former une IA conversationnelle solide.
Il est sous-entendu que dans ces tableaux textuels, la structure complète du monde se reflète (au moins, elle est décrite dans les manuels et ouvrages de référence). Mais ce n'est pas du tout un fait. Les textes en tant que forme de présentation de l'information sont fortement dissociés du monde tridimensionnel réel et du cours du temps dans lequel nous vivons.
De bons exemples d'IA formés aux tableaux de texte sont les robots de discussion et les traducteurs automatiques. Puisque pour traduire le texte, vous devez comprendre le sens de la phrase et la redire dans de nouveaux mots (dans une autre langue). Il existe une idée fausse commune selon laquelle les règles de grammaire et de syntaxe, y compris une description de toutes les exceptions possibles, décrivent complètement un langage particulier. Ce n'est pas le cas. La langue n'est qu'un outil auxiliaire dans la vie, elle change facilement et s'adapte à de nouvelles situations.
Le problème avec le traitement de texte (même par des systèmes experts, même des réseaux de neurones) est qu'il n'y a pas d' ensemble de règles, quelles phrases doivent être appliquées dans quelles situations. Veuillez noter - pas les règles de construction des phrases elles-mêmes (ce que font la grammaire et la syntaxe), mais quelles phrases dans quelles situations. Dans la même situation, les gens prononcent des phrases dans différentes langues qui ne sont généralement pas liées les unes aux autres en termes de structure de la langue. Comparez les phrases avec une extrême surprise: "oh mon dieu!" et "ô merde!". Eh bien, et comment faire une correspondance entre eux, en connaissant le modèle de langage? Pas question. C'est arrivé par hasard historiquement. Vous devez connaître la situation et ce qu'ils parlent habituellement dans une langue particulière. C'est à cause de cela que les traducteurs automatiques sont si imparfaits.
On ne sait pas si ces connaissances peuvent être distinguées purement d'un ensemble de textes. Mais si les traducteurs automatiques traduisent parfaitement sans faire d'erreurs idiotes et ridicules, alors ce sera la preuve que la création d'une IA forte uniquement basée sur du texte est possible.
2. Reconnaissance d'image
Regardez cette image

En regardant cette photo, nous comprenons que la prise de vue a été effectuée la nuit. A en juger par les drapeaux, le vent souffle de droite à gauche. Et à en juger par la circulation à droite, l'affaire ne se produit pas en Angleterre ou en Australie. Aucune de ces informations n'est indiquée explicitement dans les pixels de l'image, il s'agit de connaissances externes. Sur la photo, il n'y a que des signes par lesquels nous pouvons utiliser les connaissances obtenues d'autres sources.
Savez-vous autre chose en regardant cette photo?A propos de cela et du discours ... Et trouvez-vous enfin une fille
Par conséquent, on pense que si vous entraînez un réseau de neurones à reconnaître des objets dans une image, il aura alors une idée interne du fonctionnement du monde réel. Et cette vue, obtenue à partir des photographies, correspondra certainement à notre monde réel et réel. Contrairement aux tableaux de textes où cela n'est pas garanti.
La valeur des réseaux de neurones formés sur un réseau de photographies ImageNet (et maintenant OpenImages V4 , COCO , KITTI , BDD100K et autres) n'est pas du tout le fait de la reconnaissance d'un chat sur une photo. Et cela est stocké dans l'avant-dernière couche. C'est là que se trouve un ensemble de fonctionnalités de haut niveau qui décrivent notre monde. Un vecteur de 1024 nombres suffit pour obtenir une description de 1000 catégories d'objets différentes avec une précision de 80% (et dans 95% des cas, la bonne réponse sera dans les 5 options les plus proches). Pensez-y.
C'est pourquoi ces fonctionnalités de l'avant-dernière couche sont si bien utilisées dans des tâches complètement différentes en vision par ordinateur. Grâce à l'apprentissage par transfert et au réglage fin. À partir de ce vecteur en 1024 nombres, vous pouvez obtenir, par exemple, une carte de profondeur de l'image
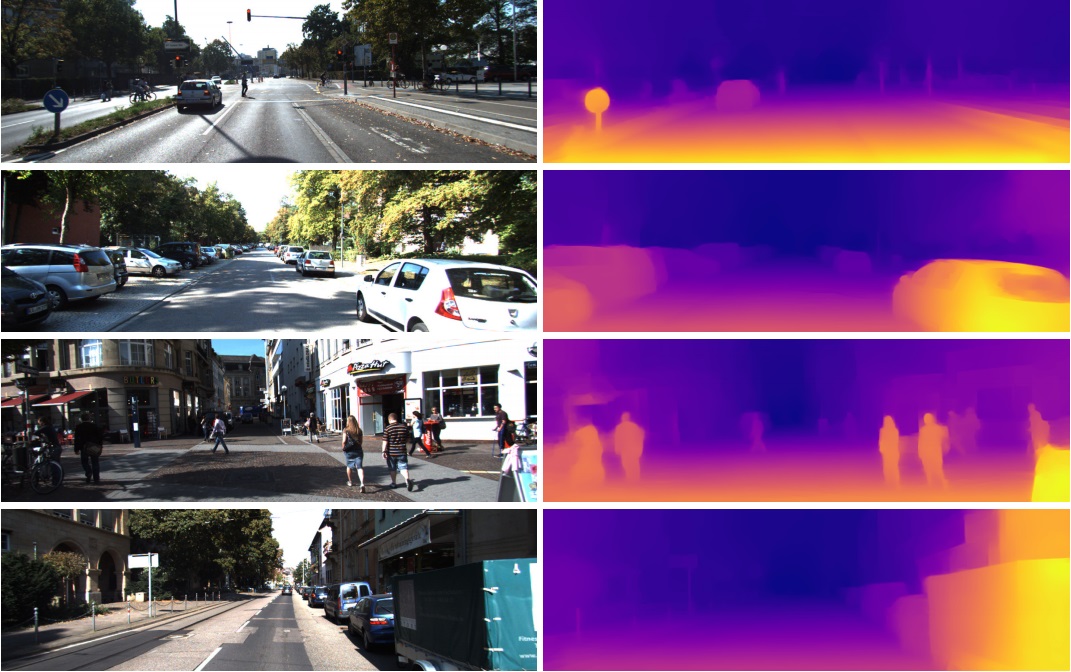
(un exemple du travail où un réseau Densenet-169 pré-formé pratiquement inchangé est utilisé)
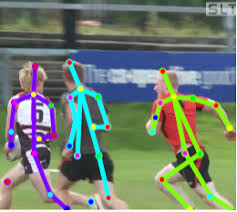
Ou déterminez la pose d'une personne. Il existe de nombreuses applications.
En conséquence, la reconnaissance d'image peut potentiellement être utilisée pour créer une IA forte, car elle reflète vraiment le modèle de notre monde réel. Une étape de la photographie à la vidéo, et la vidéo est notre vie, car nous obtenons environ 99% des informations visuellement.
Mais à partir de la photographie, il est complètement incompréhensible de motiver le réseau neuronal à penser et à tirer des conclusions. Elle peut être formée pour répondre à des questions comme "combien de crayons sont sur la table?" (cette classe de tâches s'appelle Visual Question Answering, un exemple d'un tel ensemble de données: https://visualqa.org ). Ou donnez une description textuelle de ce qui se passe sur la photo. Il s'agit de la classe de tâches de sous-titrage d'image .

Mais est-ce cette intelligence? Ayant développé cette approche, dans un avenir proche, les réseaux de neurones pourront répondre à des questions vidéo telles que "Deux moineaux assis sur les fils, l'un d'eux s'est envolé, combien de moineaux restaient?". Il s'agit de véritables mathématiques, dans des cas un peu plus compliqués, inaccessibles aux animaux et au niveau de l'éducation scolaire humaine. Surtout si, à l'exception des moineaux, il y aura des seins assis à côté d'eux, mais ils n'ont pas besoin d'être pris en compte, car la question ne concernait que les moineaux. Oui, ce sera certainement de l'intelligence.
3. Apprentissage par renforcement
L'idée est très simple: encourager les actions menant à la récompense et éviter de conduire à l'échec. Il s'agit d'un moyen d'apprentissage universel et, bien sûr, il peut certainement conduire à la création d'une IA forte. Par conséquent, il y a eu tellement d'intérêt pour l'apprentissage par renforcement ces dernières années.
Mélangez mais ne secouez pasBien sûr, il est préférable de créer une IA forte en combinant les trois approches. En images et avec une formation de renforcement, vous pouvez obtenir une IA de niveau animal. Et en ajoutant des noms textuels d'objets aux images (une blague, bien sûr - forçant l'IA à regarder des vidéos où les gens interagissent et parlent, comme lors de l'enseignement à un bébé), et se recycler sur un tableau de texte pour acquérir des connaissances (un analogue de notre école et université), en théorie, vous pouvez obtenir IA au niveau humain. Capable de parler.
L'apprentissage renforcé a un gros plus. Dans le simulateur, vous pouvez créer un modèle simplifié du monde. Ainsi, pour une figure humaine, seulement 17 degrés de liberté suffisent, au lieu de 700 chez une personne vivante (nombre approximatif de muscles). Par conséquent, dans le simulateur, vous pouvez résoudre le problème dans une très petite dimension.
À l'avenir, les algorithmes modernes d'apprentissage par renforcement ne sont pas en mesure de contrôler arbitrairement le modèle d'une personne, même avec 17 degrés de liberté. Autrement dit, ils ne peuvent pas résoudre le problème d'optimisation, où il y a 44 nombres à l'entrée et 17 à l'entrée. Il n'est possible de le faire que dans des cas très simples, avec un réglage fin des conditions initiales et des hyperparamètres. Et même dans ce cas, par exemple, pour enseigner un modèle humanoïde avec 17 degrés de liberté pour fonctionner, et à partir d'une position debout (ce qui est beaucoup plus simple), vous avez besoin de plusieurs jours de calculs sur un GPU puissant. Et des cas un peu plus compliqués, par exemple, apprendre à se lever d'une pose arbitraire, peuvent ne jamais apprendre du tout. C'est un échec.
En outre, tous les algorithmes d'apprentissage par renforcement fonctionnent avec des réseaux de neurones déprimants, mais ils ne peuvent pas faire face à l'apprentissage de grands réseaux. Les grands réseaux de convolution ne sont utilisés que pour réduire la dimension de l'image à plusieurs fonctionnalités, qui sont transmises aux algorithmes d'apprentissage avec renforcement. Le même humanoïde en marche est contrôlé par un réseau Feed Forward avec deux ou trois couches de 128 neurones. Vraiment? Et sur cette base, essayons-nous de construire une IA forte?
Pour essayer de comprendre pourquoi cela se produit et ce qui ne va pas avec l'apprentissage par renforcement, vous devez d'abord vous familiariser avec les architectures de base de l'apprentissage par renforcement moderne.
La structure physique du cerveau et du système nerveux est adaptée par l'évolution au type spécifique d'animal et à ses conditions de vie. Ainsi, au cours de l'évolution, une mouche a développé un tel système nerveux et un tel travail de neurotransmetteurs dans les ganglions (un analogue du cerveau chez les insectes) pour esquiver rapidement une tapette à mouches. Eh bien, non pas d'une tapette à mouches, mais d'oiseaux qui ont pêché pendant 400 millions d'années (je plaisante, les oiseaux eux-mêmes sont apparus il y a 150 millions d'années, très probablement à partir de grenouilles 360 millions d'années). Un rhinocéros assez tel un système nerveux et un cerveau pour se tourner lentement vers la cible et commencer à courir. Et là, comme on dit, le rhinocéros a une mauvaise vue, mais ce n'est pas son problème.
Mais en plus de l'évolution, chaque individu spécifique, à partir de la naissance et tout au long de la vie, travaille précisément le mécanisme d'apprentissage habituel avec renforcement. Dans le cas des mammifères et des insectes aussi , le système de dopamine fait ce travail. Son travail est plein de secrets et de nuances, mais tout se résume au fait qu'en cas de récompense, le système dopaminergique, grâce à des mécanismes de mémoire, fixe en quelque sorte les connexions entre les neurones qui étaient actifs immédiatement avant. C'est ainsi que se forme la mémoire associative.
Qui, en raison de son associativité, est ensuite utilisé dans la prise de décision. Autrement dit, si la situation actuelle (les neurones actifs actuels dans cette situation) à travers la mémoire associative activent les neurones de plaisir, alors l'individu sélectionne les actions qu'elle a faites dans une situation similaire et dont elle se souvient. «Choisir des actions» est une mauvaise définition. Il n'y a pas d'autre choix. Les neurones de mémoire du plaisir simplement activés, fixés par le système dopaminergique pour une situation donnée, activent automatiquement les motoneurones, entraînant une contraction musculaire. C'est si une action immédiate est nécessaire.
L'apprentissage artificiel avec renforcement, en tant que domaine de connaissance, il est nécessaire de résoudre ces deux problèmes:
1. Choisir l'architecture du réseau neuronal (ce que l'évolution a déjà fait pour nous)
La bonne nouvelle est que les fonctions cognitives supérieures réalisées dans le néocortex chez les mammifères (et dans le striatum chez les corvidés ) sont réalisées dans une structure approximativement uniforme. Apparemment, cela n'a pas besoin d'une "architecture" rigoureusement prescrite.
La diversité des régions cérébrales est probablement due à des raisons purement historiques. Lorsque, au fur et à mesure de leur évolution, de nouvelles parties du cerveau se sont développées au-dessus de celles de base laissées par les tout premiers animaux. Par le principe, cela fonctionne - ne touchez pas. D'un autre côté, chez différentes personnes, les mêmes parties du cerveau réagissent aux mêmes situations. Cela peut s'expliquer à la fois par l'associativité (caractéristiques et «neurones de grand-mère» naturellement formés à ces endroits au cours du processus d'apprentissage) et la physiologie. Que les voies de signalisation codées dans les gènes conduisent précisément à ces zones. Il n'y a pas de consensus, mais vous pouvez lire, par exemple, cet article récent: "Intelligence biologique et artificielle" .
2. Apprenez à former des réseaux de neurones selon les principes de l'apprentissage avec renforcement
C'est principalement ce que fait l'apprentissage par renforcement moderne. Et quels sont les succès? Pas vraiment.
Approche naïve
Il semblerait qu'il soit très simple de former un réseau de neurones avec renforcement: nous faisons des actions aléatoires, et si nous obtenons une récompense, alors nous considérons les actions prises comme «référence». Nous les mettons sur la sortie du réseau neuronal en tant qu'étiquettes standard et entraînons le réseau neuronal par la méthode de la propagation arrière de l'erreur, afin qu'il produise exactement une telle sortie. Eh bien, la formation de réseau neuronal la plus courante. Et si les actions ont conduit à un échec, alors ignorez ce cas ou supprimez ces actions (nous en définissons d'autres comme sortie, par exemple, toute autre action aléatoire). En général, cette idée répète le système dopaminergique.
Mais si vous essayez de former n'importe quel réseau de neurones de cette manière, quelle que soit la complexité de l'architecture, la récursivité, la convolution ou la distribution directe ordinaire, alors ... Cela ne fonctionnera pas!
Pourquoi? Inconnu
On pense que le signal utile est si petit qu'il est perdu sur le fond du bruit. Par conséquent, le réseau n'apprend pas la méthode standard de propagation de l'erreur. Une récompense arrive très rarement, peut-être une fois en centaines ou même en milliers d'étapes. Et même LSTM se souvient d'un maximum de 100-500 points dans l'histoire, et seulement dans des tâches très simples. Mais sur les plus complexes, s'il y a 10-20 points dans l'histoire, alors c'est déjà bien.
Mais la racine du problème réside précisément dans les récompenses très rares (au moins dans les tâches de valeur pratique). Pour le moment, nous ne savons pas comment former des réseaux de neurones qui se souviendraient de cas isolés. Ce que le cerveau fait avec brio. Vous vous souvenez de quelque chose qui ne s'est produit qu'une seule fois dans la vie. Et en passant, la plupart de la formation et du travail de l'intellect sont construits sur de tels cas.
Cela ressemble à un terrible déséquilibre des classes dans le domaine de la reconnaissance d'image. Il n'y a tout simplement aucun moyen de résoudre ce problème. Le mieux qu'ils ont pu trouver jusqu'à présent est simplement de soumettre à l'entrée du réseau, avec de nouvelles situations, des situations réussies du passé stockées dans un tampon spécial artificiel. Autrement dit, pour enseigner constamment non seulement les nouveaux cas, mais aussi les anciens réussis. Naturellement, un tel tampon ne peut pas être augmenté à l'infini, et on ne sait pas exactement quoi y stocker. J'essaie toujours de corriger temporairement les chemins à l'intérieur du réseau neuronal, qui étaient actifs lors d'un cas réussi, afin que la formation ultérieure ne les écrase pas. Une analogie assez proche de ce qui se passe dans le cerveau, à mon avis, même s'ils n'ont pas encore beaucoup de succès dans cette direction. Étant donné que les nouvelles tâches entraînées dans leur calcul utilisent les résultats des neurones quittant les chemins gelés, en conséquence, le signal n'interfère qu'avec les nouvelles gelées et les anciennes tâches cessent de fonctionner. Il existe une autre approche curieuse: former le réseau avec de nouveaux exemples / tâches uniquement dans le sens orthogonal aux tâches précédentes ( https://arxiv.org/abs/1810.01256 ). Cela n'écrase pas l'expérience précédente, mais limite considérablement la capacité du réseau.
Une classe distincte d'algorithmes conçus pour faire face à cette catastrophe (et en même temps donner l'espoir de parvenir à une IA forte) est en cours de développement dans Meta-Learning. Ce sont des tentatives pour enseigner à un réseau de neurones plusieurs tâches à la fois. Pas dans le sens où il reconnaît différentes images dans une même tâche, à savoir différentes tâches dans différents domaines (chacune avec sa propre distribution et son propre paysage de solutions). Dites, reconnaissez les images et faites du vélo en même temps. Jusqu'à présent, le succès n'est pas très bon non plus, car il s'agit généralement de préparer un réseau de neurones à l'avance avec des poids universels généraux, puis rapidement, en quelques étapes de descente de gradient, de les adapter à une tâche spécifique. Des exemples d'algorithmes de méta-apprentissage sont MAML et Reptile .
En général, seul ce problème (l'incapacité d'apprendre à partir d'exemples réussis) met un terme à la formation moderne avec renforcement. Toute la puissance des réseaux de neurones devant ce triste fait est jusqu'à présent impuissante.
Ce fait, que la manière la plus simple et la plus évidente ne fonctionne pas, a forcé les chercheurs à revenir à l'apprentissage par renforcement classique basé sur une table. Ce qui, en tant que science, est apparu dans l'antiquité, alors que les réseaux de neurones n'étaient même pas dans le projet. Mais maintenant, au lieu de calculer manuellement les valeurs dans les tableaux et les formules, utilisons un approximateur aussi puissant que les réseaux de neurones comme fonctions objectives! C'est l'essence même de l'apprentissage par renforcement moderne. Et sa principale différence avec la formation habituelle des réseaux de neurones.
Q-learning et DQN
L'apprentissage par renforcement (avant même les réseaux de neurones) est né comme une idée assez simple et originale: faisons des actions aléatoires, puis pour chaque cellule du tableau et chaque direction de mouvement, nous calculons selon une formule spéciale (appelée l'équation de Bellman, ce mot vous à rencontrer dans presque tous les travaux avec une formation de renforcement) à quel point cette cellule et la direction choisie sont bonnes. Plus ce nombre est élevé, plus ce chemin mène à la victoire.
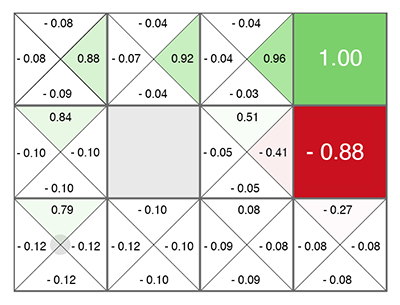
Quelle que soit la cellule dans laquelle vous apparaissez, déplacez-vous dans le vert en pleine croissance! (vers le nombre maximum sur les côtés de la cellule actuelle).
Ce nombre est appelé Q (du mot qualité - qualité de choix, évidemment), et la méthode est Q-learning. Remplaçant la formule de calcul de ce nombre par un réseau neuronal, ou plutôt enseignant le réseau neuronal à l'aide de cette formule (plus quelques astuces liées uniquement aux mathématiques de la formation des réseaux neuronaux), Deepmind a obtenu la méthode DQN . C'est qui, en 2015, a remporté le tas de jeux Atari et a inauguré une révolution dans l'apprentissage par renforcement profond.
Malheureusement, cette méthode dans son architecture ne fonctionne qu'avec des actions discrètes discrètes. Dans le DQN, l'état actuel (la situation actuelle) est transmis à l'entrée du réseau neuronal, et à la sortie, le réseau neuronal prédit le nombre Q.Et comme la sortie du réseau répertorie toutes les actions possibles à la fois (chacune avec son propre Q prédit), il s'avère que le réseau neuronal dans DQN implémente la fonction classique Q (s, a) de Q-learning. Q state action ( Q(s,a) s a). argmax Q , .
Q, . , Q- (.. Q , ). . , (Exploration), , , . , .
, ? 5 Atari, continuous ? , -1..1 0.1, , Atari. . , . 10 . - , 10 . . DQN , 17 . , , .
DQN, , , continuous ( ): DDQN, DuDQN, BDQN, CDQN, NAF, Rainbow. , Direct Future Prediction (DFP) , DQN . Q , DFP , . . , . , , , .
, Reinforcement Learning.
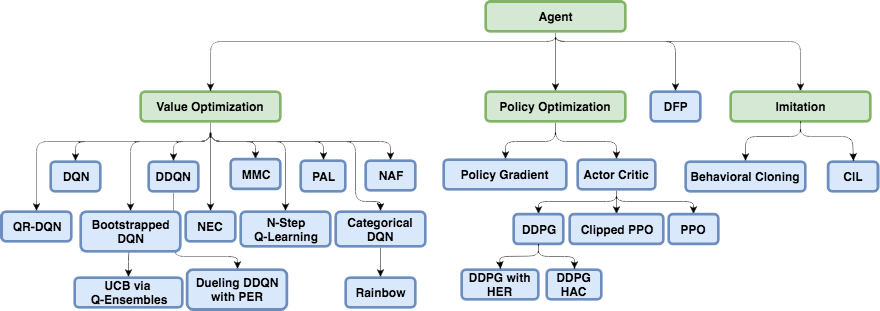
Policy Gradient
state, ( , ). , actions, . , R . ( ), ( ). . .
, R , , . ! . "" labels ( ), . , , R.
Policy Gradient. — , R, . — , , . , .
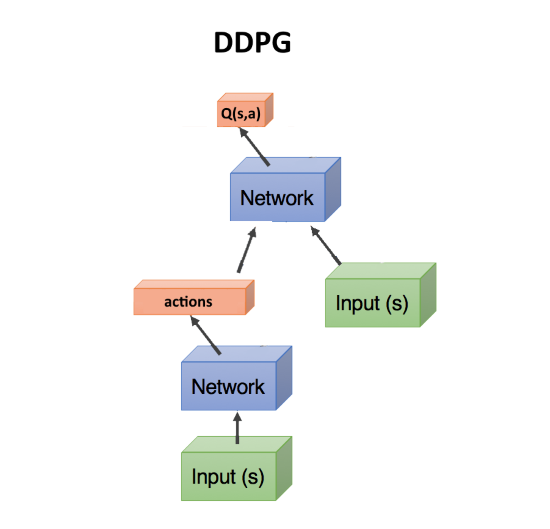
Actor-critic, DDPG
, — , . , Q- , DQN. state, action(s). state, action, , Q : Q(s,a).
, Q(s,a), ( critic, ), , ( , actor), R. , . actor-critic. Policy Gradient, , . .
DDPG. actions, continuous . DDPG continuous DQN .
Advantage Actor Critic (A3C/A2C)
critic Q(s,a) — , actor, DDPG. , .
, . , , , . , , , ( , ).
Q(s,a), Advantage: A(s,a) = Q(s,a) — V(s). A(s,a) Q(s,a) , — , V(s). A(s,a) > 0, , . A(s,a) < 0, , , .. .
V(s) state , ( s, a). — state, V(s). , state, V(s).
, Q(s,a) r, , A = r — V(s).
, V(s) ( ), — actor critic, ! state, head: actions, V(s). c , .. state. , .
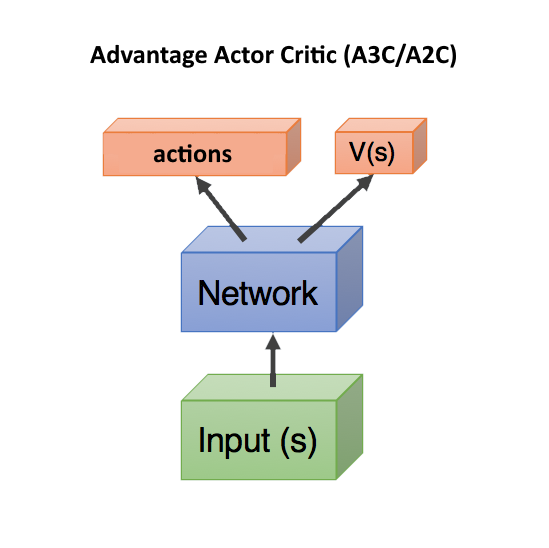
V(s) . V(s), action ( ), . Dueling Q-Network (DuDQN), Q(s,a) Q(s,a) = V(s) + A(a), .
Asynchronous Advantage Actor Critic (A3C) , , actor. batch . , actor. , , . , A2C — A3C, actor ( ). A2C , , .
TRPO, PPO, SAC
, .
, . Reinforcement Learning , , , — , . .
— TRPO PPO, state-of-the-art, Actor-Critic. PPO RL. , OpenAI Five Dota 2.
, TRPO PPO — , . , A3C/A2C , . , policy , . - gradient clipping , . , ( , ), , , - .
Récemment, l'algorithme Soft-Actor-Critic (SAC) a gagné en popularité. Il n'est pas très différent de PPO, seul un objectif a été ajouté lors de l'apprentissage de l'augmentation de l'entropie dans la politique. Rendre le comportement des agents plus aléatoire. Non, pas comme ça. Que l'agent a pu agir dans des situations plus aléatoires. Cela augmente automatiquement la fiabilité de la politique, une fois que l'agent est prêt pour toutes les situations aléatoires. De plus, le SAC nécessite un peu moins d'exemples de formation que PPO et est moins sensible aux paramètres d'hyperparamètre, ce qui est également un plus. Cependant, même avec SAC, pour former un humanoïde à courir avec 17 degrés de liberté, à partir d'une position debout, vous avez besoin d'environ 20 millions d'images et d'environ une journée de calcul sur un GPU. Des conditions initiales plus difficiles, par exemple, pour apprendre à un humanoïde à se lever d'une pose arbitraire, peuvent ne pas être enseignées du tout.
Total, la recommandation générale de l'apprentissage par renforcement moderne: utilisez SAC, PPO, DDPG, DQN (dans cet ordre, décroissant).
Basé sur un modèle
Il existe une autre approche intéressante, indirectement liée à l'apprentissage par renforcement. Il s'agit de construire un modèle de l'environnement et de l'utiliser pour prédire ce qui se passera si nous prenons des mesures.
Son inconvénient est qu'il ne dit en aucune manière quelles mesures doivent être prises. Seulement sur leur résultat. Mais un tel réseau de neurones est facile à former - il suffit de s'entraîner sur toutes les statistiques. Il se révèle quelque chose comme un simulateur mondial basé sur un réseau de neurones.
Après cela, nous générons un grand nombre d'actions aléatoires, et chacune est conduite via ce simulateur (via un réseau de neurones). Et nous regardons lequel apportera la récompense maximale. Il y a une petite optimisation - pour générer non seulement des actions aléatoires, mais s'écartant selon la loi normale de la trajectoire actuelle. Et en effet, si nous levons la main, alors avec une forte probabilité, nous devons continuer à la lever. Par conséquent, vous devez d'abord vérifier les écarts minimaux par rapport à la trajectoire actuelle.
L'astuce ici est que même un simulateur physique primitif comme MuJoCo ou pyBullet produit environ 200 FPS. Et si vous entraînez un réseau neuronal à prédire en avant au moins quelques étapes, alors pour des environnements simples, vous pouvez facilement obtenir des lots de prédictions de 2000 à 5000 à la fois. Selon la puissance du GPU, vous pouvez obtenir une prévision pour des dizaines de milliers d'actions aléatoires par seconde en raison de la parallélisation dans le GPU et de la vitesse de calcul dans le réseau neuronal. Le réseau neuronal agit ici simplement comme un simulateur très rapide de la réalité.
De plus, étant donné que le réseau neuronal peut prédire le monde réel (il s'agit d'une approche basée sur un modèle, au sens général), l'entraînement peut être effectué entièrement en imagination, pour ainsi dire. Ce concept dans l'apprentissage par renforcement s'appelle Dream Worlds, ou World Models. Cela fonctionne bien, une bonne description est ici: https://worldmodels.imtqy.com . De plus, il a une contrepartie naturelle - des rêves ordinaires. Et le défilement multiple des événements récents ou prévus dans la tête.
Apprentissage par imitation
En raison de l'impuissance que les algorithmes d'apprentissage par renforcement ne fonctionnent pas sur les grandes dimensions et les tâches complexes, les gens se sont efforcés de répéter au moins les actions des experts sous forme de personnes. Ici, de bons résultats ont été obtenus (inaccessibles par l'apprentissage par renforcement conventionnel). Ainsi, OpenAI s'est avéré réussir le jeu Montezuma's Revenge . L'astuce s'est avérée simple: placer l'agent immédiatement à la fin de la partie (à la fin de la trajectoire indiquée par la personne). Là, avec l'aide de PPO, grâce à la proximité de la récompense finale, l'agent apprend rapidement à marcher le long de la trajectoire. Après cela, nous le remettons un peu en arrière, où il apprend rapidement à atteindre le lieu qu'il a déjà étudié. Ainsi, en déplaçant progressivement le point de "réapparition" le long de la trajectoire jusqu'au tout début du jeu, l'agent apprend à passer / simuler la trajectoire experte tout au long du jeu.
Un autre résultat impressionnant est la répétition des mouvements pour les personnes filmées sur Motion Capture: DeepMimic . La recette est similaire à la méthode OpenAI: chaque épisode ne commence pas au début du chemin, mais à partir d'un point aléatoire le long du chemin. PPO étudie ensuite avec succès les environs de ce point.
Je dois dire que l'algorithme sensationnel Go-Explore d'Uber, qui a dépassé Montezuma's Revenge avec des points d'enregistrement, n'est pas du tout un algorithme d'apprentissage par renforcement. Il s'agit d'une recherche aléatoire régulière, mais en commençant par une cellule de cellule visitée au hasard (une cellule grossière dans laquelle plusieurs états tombent). Et ce n'est que lorsque la trajectoire jusqu'à la fin du jeu est trouvée par une telle recherche aléatoire, que le réseau neuronal est entraîné à l'aide de Imitation Learning. D'une manière similaire à OpenAI, c'est-à-dire à partir de la fin de la trajectoire.
Curiosité (Curiosité)
Un concept très important dans l'apprentissage par renforcement est la curiosité. Dans la nature, c'est un moteur de recherche environnementale.
Le problème est que, par mesure de curiosité, vous ne pouvez pas utiliser une simple erreur de prédiction de réseau, ce qui se passera ensuite. Sinon, un tel réseau sera suspendu devant le premier arbre au feuillage oscillant. Ou devant un téléviseur avec commutation aléatoire des canaux. Car le résultat dû à la complexité sera impossible à prévoir et l'erreur sera toujours importante. Cependant, c'est précisément la raison pour laquelle nous (les gens) aimons regarder le feuillage, l'eau et le feu. Et comment les autres travaillent =). Mais nous avons des mécanismes de protection pour ne pas pendre pour toujours.
L'un de ces mécanismes a été inventé comme le modèle inverse dans l' exploration axée sur la curiosité par
Prédiction auto-supervisée . En bref, un agent (réseau de neurones), en plus de prédire quelles actions sont les mieux exécutées dans une situation donnée, essaie également de prédire ce qui va arriver au monde après les actions prises. Et il utilise cette prédiction du monde pour l'étape suivante, afin que lui et l'étape actuelle puissent prédire ses actions prises plus tôt (oui, c'est difficile, vous ne pouvez pas le comprendre sans une pinte).
Cela conduit à un effet curieux: l'agent ne devient curieux que de ce qu'il peut influencer par ses actions. Il ne peut pas influencer les branches d'un arbre qui se balancent, elles deviennent donc sans intérêt pour lui. Mais il peut se promener dans le quartier, il est donc curieux de marcher et d'explorer le monde.
Cependant, si l'agent dispose d'une télécommande TV qui commute des canaux aléatoires, il peut l'affecter! Et il sera curieux de cliquer sur les canaux à l'infini (puisqu'il ne peut pas prédire quel sera le prochain canal, car il est aléatoire). Google a tenté de contourner ce problème dans le cadre de son travail sur la curiosité épisodique grâce à l'accessibilité .
Mais peut-être que le meilleur résultat de pointe est dû à la curiosité, OpenAI est actuellement propriétaire de l'idée de la distillation en réseau aléatoire (RND) . Son essence est qu'il faut un deuxième réseau, complètement initialisé de manière aléatoire, et que l'état actuel lui est transmis. Et notre principal réseau de neurones actif essaie de deviner la sortie de ce réseau de neurones. Le deuxième réseau n'est pas formé, il reste fixe tout le temps comme il a été initialisé.
À quoi ça sert? Le fait est que si un état a déjà été visité et étudié par notre réseau de travail, il pourra plus ou moins réussir à prédire la sortie de ce deuxième réseau. Et s'il s'agit d'un nouvel état, où nous n'avons jamais été, alors notre réseau de neurones ne pourra pas prédire la sortie de ce réseau RND. Cette erreur de prédiction de la sortie de ce réseau initialisé au hasard est utilisée comme un indicateur de curiosité (elle donne des récompenses élevées si nous ne pouvons pas prédire sa sortie dans cette situation).
Pourquoi cela fonctionne n'est pas entièrement clair. Mais ils écrivent que cela élimine le problème lorsque la cible de prédiction est stochastique et lorsqu'il n'y a pas suffisamment de données pour faire une prédiction de ce qui se passera ensuite (ce qui donne une grosse erreur de prédiction dans les algorithmes de curiosité ordinaires). D'une manière ou d'une autre, mais RND a vraiment montré d'excellents résultats de recherche basés sur la curiosité dans les jeux. Et fait face au problème de la télévision aléatoire.
Avec RND, la curiosité d'OpenAI pour la première fois honnêtement (et non par une recherche aléatoire préliminaire, comme dans Uber) a franchi le premier niveau de la vengeance de Montezuma. Pas à chaque fois et de manière non fiable, mais de temps en temps, cela se révèle.

Quel est le résultat?
Comme vous pouvez le voir, en quelques années seulement, l'apprentissage par renforcement a parcouru un long chemin. Pas seulement quelques solutions réussies, comme dans les réseaux convolutionnels, où les connexions de resudal et de saut ont permis de former des réseaux à des centaines de couches en profondeur, au lieu d'une douzaine de couches avec la seule fonction d'activation Relu, qui a surmonté le problème de la disparition des gradients dans sigmoid et tanh. Dans l'apprentissage par renforcement, des progrès ont été accomplis dans les concepts et dans la compréhension des raisons pour lesquelles telle ou telle version naïve de la mise en œuvre n'a pas fonctionné. Le mot clé "n'a pas fonctionné".
Mais du point de vue technique, tout repose toujours sur les prédictions des mêmes valeurs Q, V ou A. Il n'y a pas de dépendances temporelles à différentes échelles, comme dans le cerveau (Hierarchical Reinforcement Learning ne compte pas, la hiérarchie y est trop primitive par rapport à l'associativité dans le cerveau vivant). Aucune tentative de proposer une architecture de réseau spécialement conçue pour l'apprentissage par renforcement, comme cela s'est produit avec LSTM et d'autres réseaux récurrents pour les séquences temporelles. Renforcement Apprendre à piétiner sur place, à se réjouir de petits succès ou à se déplacer dans une direction complètement fausse.
Je voudrais croire qu'une fois dans l'apprentissage par renforcement, il y aura une percée dans l'architecture des réseaux de neurones, similaire à ce qui s'est passé dans les réseaux convolutionnels. Et nous verrons vraiment un apprentissage par renforcement efficace. Apprendre sur des exemples isolés, avec travailler la mémoire associative et travailler sur différentes échelles de temps.