Le langage R est aujourd'hui l'un des outils les plus puissants et multifonctionnels pour travailler avec les données, mais comme nous le savons presque toujours, dans n'importe quel baril de miel, il y a une mouche dans la pommade. Le fait est que R est un thread unique par défaut.
Il est très probable que cela ne vous dérange pas suffisamment longtemps et il est peu probable que vous posiez cette question. Mais par exemple, si vous êtes confronté à la tâche de collecter des données à partir d'un grand nombre de comptes publicitaires à partir de l'API, par exemple Yandex.Direct, vous pouvez considérablement, au moins deux à trois fois, réduire le temps nécessaire pour collecter des données à l'aide du multithreading.

Le sujet du multithreading en R n'est pas nouveau, et a été soulevé à plusieurs reprises sur Habré ici , ici et ici , mais la dernière publication date de 2013, et comme on dit, tout ce qui est nouveau est bien oublié. De plus, le multithreading a déjà été discuté pour le calcul de modèles et la formation de réseaux de neurones, et nous parlerons de l'utilisation de l'asynchronie pour travailler avec l'API. Néanmoins, je voudrais saisir cette occasion pour remercier les auteurs de ces articles car ils m'ont beaucoup aidé en écrivant cet article avec leurs publications.
Table des matières
La deuxième partie de l'article, qui traite des options plus modernes pour implémenter le multithreading dans R, est disponible ici .
Qu'est-ce que le multithreading
One-threading (calculs séquentiels) - un mode de calcul dans lequel toutes les actions (tâches) sont exécutées séquentiellement, la durée totale de toutes les opérations données dans ce cas sera égale à la somme de la durée de toutes les opérations.
Multithreading (Parallel computing) - un mode de calcul dans lequel des actions (tâches) spécifiées sont exécutées en parallèle, c'est-à-dire en même temps, alors que le temps d'exécution total de toutes les opérations ne sera pas égal à la somme de la durée de toutes les opérations.
Pour simplifier la perception, regardons le tableau suivant:
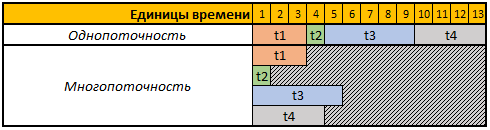
La première ligne du tableau donné est des unités de temps conditionnelles, dans ce cas, cela n'a pas d'importance pour nous secondes, minutes ou toute autre période.
Dans cet exemple, nous devons effectuer 4 opérations, chaque opération dans ce cas a une durée de calcul différente, en mode mono-thread, les 4 opérations seront effectuées séquentiellement les unes après les autres, donc le temps total pour leur exécution sera t1 + t2 + t3 + t4, 3 + 1 + 5 + 4 = 13.
En mode multi-thread, les 4 tâches seront effectuées en parallèle, c'est-à-dire pour démarrer la tâche suivante, il n'est pas nécessaire d'attendre que la précédente soit terminée, donc si nous démarrons notre tâche en 4 threads, alors le temps de calcul total sera égal au temps de calcul de la plus grande tâche, dans notre cas c'est la tâche t3, dont la durée de calcul dans notre exemple est 5 unités temporaires, respectivement, et le temps d'exécution des 4 opérations dans ce cas sera égal à 5 unités temporaires.
Quels packages utiliserons-nous
Pour les calculs en mode multithread, nous utiliserons les doSNOW foreach , doSNOW et doParallel .
Le package foreach vous permet d'utiliser la construction foreach , qui est essentiellement une boucle for améliorée.
Les doSNOW et doParallel sont essentiellement des frères jumeaux, vous permettant de créer des clusters virtuels et de les utiliser pour effectuer des calculs parallèles.
À la fin de l'article, à l'aide du package rbenchmark nous mesurerons et comparerons la durée des opérations de collecte de données à partir de l'API Yandex.Direct en utilisant toutes les méthodes décrites ci-dessous.
Pour travailler avec l'API Yandex.Direct, nous utiliserons le package ryandexdirect, dans cet article, nous l'utiliserons comme exemple, plus de détails sur ses capacités et fonctions peuvent être trouvés dans la documentation officielle .
Code pour installer tous les packages nécessaires:
install.packages("foreach") install.packages("doSNOW") install.packages("doParallel") install.packages("rbenchmark") install.packages("ryandexdirect")
Défi
Vous devez écrire un code qui demandera une liste de mots clés à n'importe quel nombre de comptes publicitaires Yandex.Direct. Le résultat doit être collecté dans un cadre de date, dans lequel il y aura un champ supplémentaire avec la connexion du compte publicitaire auquel appartient le mot-clé.
De plus, notre tâche est d'écrire un code qui effectuera cette opération le plus rapidement possible sur n'importe quel nombre de comptes publicitaires.
Autorisation dans Yandex.Direct
Pour fonctionner avec l'API de la plate-forme publicitaire Yandex.Direct, il est initialement nécessaire de passer par une autorisation sous chaque compte auprès duquel nous prévoyons de demander une liste de mots-clés.
Tout le code donné dans cet article reflète un exemple de travail avec des comptes publicitaires Yandex.Direct réguliers, si vous travaillez sous un compte d'agent, vous devez utiliser l'argument AgencyAccount et lui transmettre la connexion au compte d'agent. Vous pouvez en savoir plus sur l'utilisation des comptes d'agent de Yandex.Direct à l'aide du package ryandexdirect ici .
Pour l'autorisation, il est nécessaire d'exécuter la fonction yadirAuth partir du package yadirAuth , pour répéter le code ci-dessous est nécessaire pour chaque compte à partir duquel vous demanderez une liste de mots-clés et leurs paramètres.
ryandexdirect::yadirAuth(Login = " ")
Le processus d'autorisation dans Yandex.Direct via le package ryandexdirect totalement sûr, malgré le fait qu'il passe par un site tiers. J'ai déjà parlé en détail de la sécurité de son utilisation dans l'article "Comment il est sûr d'utiliser les packages R pour travailler avec l'API Advertising Systems" .
Après l'autorisation, un fichier login.yadirAuth.RData sera créé sous chaque compte dans votre répertoire de travail, qui stockera les informations d'identification pour chaque compte. Le nom de fichier commencera à la connexion spécifiée dans l'argument de connexion . Si vous devez enregistrer les fichiers non pas dans le répertoire de travail actuel, mais dans un autre dossier, utilisez l'argument TokenPath , mais dans ce cas, lorsque vous demandez des mots clés à l'aide de la fonction yadirGetKeyWords vous devez également utiliser l'argument TokenPath et spécifier le chemin d'accès au dossier dans lequel vous avez enregistré les fichiers. avec des informations d'identification.
Solution séquentielle monothread utilisant for loop
La façon la plus simple de collecter des données de plusieurs comptes à la fois est d'utiliser la boucle for . Simple mais pas le plus efficace, car l'un des principes de développement en langage R est d'éviter l'utilisation de boucles dans le code.
Vous trouverez ci-dessous un exemple de code pour collecter des données à partir de 4 comptes à l'aide de la boucle for.En fait, vous pouvez utiliser cet exemple pour collecter des données à partir de n'importe quel nombre de comptes publicitaires.
Code 1: Nous traitons 4 comptes en utilisant la boucle for habituelle library(ryandexdirect) # logins <- c("login_1", "login_2", "login_3", "login_4") # res1 <- data.frame() # for (login in logins) { temp <- yadirGetKeyWords(Login = login) temp$login <- login res1 <- rbind(res1, temp) }
La mesure du temps d'exécution à l'aide de la fonction system.time a donné le résultat suivant:
Temps de travail:
Utilisateur: 178.83
système: 0,63
réussi: 320,39
La collecte de mots-clés pour 4 comptes a pris 320 secondes et, à partir des messages d'information que la fonction yadirGetKeyWords affiche pendant le fonctionnement, le plus grand compte est vu, dont 5970 mots-clés ont été reçus, 142 secondes ont été traités.
Solution de multithreading dans R
J'ai déjà écrit ci-dessus que pour le multithreading, nous utiliserons les doSNOW et doParallel .
Je veux attirer l'attention sur le fait que presque toutes les API ont leurs propres limites, et l'API Yandex.Direct ne fait pas exception. En fait, l' aide pour travailler avec l'API Yandex.Direct dit:
Pas plus de cinq demandes d'API simultanées sont autorisées au nom d'un utilisateur.
Par conséquent, malgré le fait que dans ce cas, nous considérerons un exemple avec la création de 4 flux, en travaillant avec Yandex.Direct, vous pouvez créer 5 flux même si vous envoyez toutes les demandes sous le même utilisateur. Mais il est plus rationnel d'utiliser 1 thread pour 1 cœur de votre processeur, vous pouvez déterminer le nombre de cœurs de processeur physique à l'aide de la commande parallel::detectCores(logical = FALSE) , le nombre de cœurs logiques peut être trouvé à l'aide de parallel::detectCores(logical = TRUE) . Une compréhension plus détaillée de ce qu'un tel noyau physique et logique est possible sur Wikipédia .
En plus de la limite du nombre de demandes, il y a une limite quotidienne sur le nombre de points d'accès à l'API Yandex.Direct, elle peut être différente pour tous les comptes, chaque demande consomme également un nombre différent de points en fonction de l'opération effectuée. Par exemple, pour interroger une liste de mots-clés, vous serez déduit de 15 points pour une requête terminée et de 3 points pour chaque 2000 mots, vous pouvez savoir comment les points sont radiés dans le certificat officiel . Vous pouvez également voir des informations sur le nombre de points marqués et disponibles, ainsi que leur limite quotidienne dans les messages d'information renvoyés à la console par la fonction yadirGetKeyWords .
Number of API points spent when executing the request: 60 Available balance of daily limit API points: 993530 Daily limit of API points:996000
doSNOW et doParallel dans l'ordre.
Package DoSNOW et fonctionnalités multithread
Nous réécrivons la même opération pour le mode de calcul multithread, créons 4 threads dans ce cas, et au lieu de la boucle for , nous utilisons la construction foreach .
Code 2: calcul parallèle avec doSNOW library(foreach) library(doSNOW) # logins <- c("login_1", "login_2", "login_3", "login_4") cl <- makeCluster(4) registerDoSNOW(cl) res2 <- foreach(login = logins, # - .combine = 'rbind', # .packages = "ryandexdirect", # .inorder=F ) %dopar% {cbind(yadirGetKeyWords(Login = login), login) } stopCluster(cl)
Dans ce cas, la mesure de l'exécution à l'aide de la fonction system.time a donné le résultat suivant:
Temps de travail:
utilisateur: 0,17
système: 0,08
réussi: 151,47
Le même résultat, c'est-à-dire nous avons reçu la collection de mots clés de 4 comptes Yandex.Direct en 151 secondes, soit 2 fois plus rapide. De plus, je viens d'écrire dans le dernier exemple combien de temps il a fallu pour charger une liste de mots clés à partir du plus grand compte (142 secondes), c'est-à-dire dans cet exemple, le temps total est presque identique au temps de traitement du plus grand compte. Le fait est qu'avec l'aide de la fonction foreach , nous avons simultanément lancé le processus de collecte de données en 4 flux, c'est-à-dire en même temps, les données collectées sur les 4 comptes respectivement, le temps total est égal au temps de traitement du plus grand compte.
Je makeCluster donner une petite explication au code 2 , la fonction makeCluster responsable du nombre de threads, dans ce cas, nous avons créé un cluster de 4 cœurs de processeur, mais comme je l'ai écrit plus tôt en travaillant avec l'API Yandex.Direct, vous pouvez créer 5 threads, quel que soit le nombre de comptes vous devez traiter 5-15-100 ou plus, vous pouvez envoyer 5 demandes à l'API en même temps.
Ensuite, la fonction registerDoSNOW démarre le cluster créé.
Après cela, nous utilisons la construction foreach , comme je l'ai dit plus tôt, cette construction est une boucle for améliorée. Vous définissez le compteur comme premier argument, dans l'exemple que j'ai appelé login et il itérera sur les éléments du vecteur de connexion à chaque itération, nous obtiendrions le même résultat dans la boucle for si nous écrivions for ( login in logins) .
Ensuite, vous devez indiquer dans l'argument .combine la fonction avec laquelle vous combinerez les résultats obtenus à chaque itération, les options les plus courantes sont:
rbind - joindre les tables résultantes ligne par ligne les unes sous les autres;cbind - joint les tables résultantes en colonnes;"+" - résume le résultat obtenu à chaque itération.
Vous pouvez également utiliser toute autre fonction, même auto-écrite.
L'argument .inorder = F vous permet d'accélérer un peu plus la fonction si vous ne vous souciez pas de l'ordre de combinaison des résultats, dans ce cas, l'ordre n'est pas important pour nous.
Vient ensuite l'opérateur %dopar% , qui démarre la boucle en mode de calcul parallèle, si vous utilisez l'opérateur %do% , les itérations seront exécutées séquentiellement, ainsi que lors de l'utilisation de la boucle for habituelle.
La fonction stopCluster arrête le cluster.
Le multithreading, ou plutôt la construction foreach en mode multithread, a quelques fonctionnalités, en fait, dans ce cas, nous démarrons chaque processus parallèle dans une nouvelle session R propre. Par conséquent, afin d'utiliser les fonctions génériques et les objets à l'intérieur qui ont été définis en dehors de la construction foreach , vous devez les exporter à l'aide de l'argument .export . Cet argument prend un vecteur de texte contenant les noms des objets que vous utiliserez à l'intérieur de foreach .
De plus, foreach , en mode parallèle, ne voit pas les packages précédemment connectés par défaut, ils devront donc également être passés à l'intérieur de foreach à l'aide de l'argument .packages . Il est également nécessaire de transférer des packages en listant leurs noms dans un vecteur texte, par exemple .packages = c("ryandexdirect", "dplyr", "lubridate") . Dans l'exemple de code 2 ci-dessus, nous chargeons simplement de cette manière le package ryandexdirect à chaque itération de foreach .
Forfait DoParallel
Comme je l'ai écrit ci-dessus, les doSNOW et doParallel sont des jumeaux, ils ont donc la même syntaxe.
Code 5: calcul parallèle avec doParallel library(foreach) library(doParallel) logins <- c("login_1", "login_2", "login_3", "login_4") cl <- makeCluster(4) registerDoParallel(cl) res3 <- data.frame() res3 <- foreach(login=logins, .combine= 'rbind', .inorder=F) %dopar% {cbind(ryandexdirect::yadirGetKeyWords(Login = login), login) stopCluster(cl)
Temps de travail:
utilisateur: 0,25
système: 0,01
réussi: 173,28
Comme vous pouvez le voir dans ce cas, le temps d'exécution diffère légèrement de l'exemple précédent de code informatique parallèle utilisant le package doSNOW .
Test de vitesse entre les trois approches examinées
Exécutez maintenant le test de vitesse à l'aide du package rbenchmark .
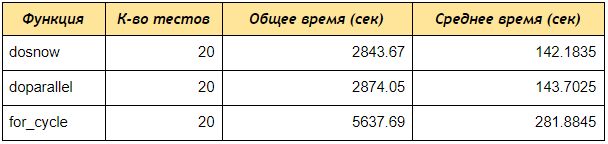
Comme vous pouvez le voir, même sur un test de 4 comptes, les doSNOW et doParallel reçu des données par mots-clés 2 fois plus rapidement que la boucle séquentielle for, si vous créez un cluster de 5 cœurs et traitez 50 ou 100 comptes, la différence sera encore plus significative.
Code 6: Script pour comparer la vitesse du multithreading et du calcul séquentiel # library(ryandexdirect) library(foreach) library(doParallel) library(doSNOW) library(rbenchmark) # for for_fun <- function(logins) { res1 <- data.frame() for (login in logins) { temp <- yadirGetKeyWords(Login = login) res1 <- rbind(res1, temp) } return(res1) } # foreach doSNOW dosnow_fun <- function(logins) { cl <- makeCluster(4) registerDoSNOW(cl) res2 <- data.frame() system.time({ res2 <- foreach(login=logins, .combine= 'rbind') %dopar% {temp <- ryandexdirect::yadirGetKeyWords(Login = login } }) stopCluster(cl) return(res2) } # foreach doParallel dopar_fun <- function(logins) { cl <- makeCluster(4) registerDoParallel(cl) res2 <- data.frame() system.time({ res2 <- foreach(login=logins, .combine= 'rbind') %dopar% {temp <- ryandexdirect::yadirGetKeyWords(Login = login) } }) stopCluster(cl) return(res2) } # within(benchmark(for_cycle = for_fun(logins = logins), dosnow = dosnow_fun(logins = logins), doparallel = dopar_fun(logins = logins), replications = c(20), columns=c('test', 'replications', 'elapsed'), order=c('elapsed', 'test')), { average = elapsed/replications })
En conclusion, je donnerai une explication du code 5 ci-dessus, avec lequel nous avons testé la vitesse de travail.
Au départ, nous avons créé trois fonctions:
for_fun - une fonction demandant des mots clés à partir de plusieurs comptes, les triant séquentiellement à travers un cycle régulier.
dosnow_fun - une fonction demandant une liste de mots clés en mode multithread, en utilisant le package doSNOW .
dopar_fun - une fonction demandant une liste de mots clés en mode multithread, en utilisant le package doParallel .
Ensuite, à l'intérieur de la construction within, nous rbenchmark la fonction benchmark partir du package rbenchmark , rbenchmark les noms des tests (for_cycle, dosnow, doparallel) et chaque fonction, nous for_fun(logins = logins) les fonctions, respectivement: for_fun(logins = logins) ; dosnow_fun(logins = logins) ; dopar_fun(logins = logins) .
L'argument des réplications est responsable du nombre de tests, c'est-à-dire combien de fois allons-nous exécuter chaque fonction.
L'argument colonnes vous permet de spécifier quelles colonnes vous souhaitez recevoir, dans notre cas `` test '', `` réplications '', `` écoulé '' signifie retourner les colonnes: nom du test, nombre de tests, durée totale d'exécution de tous les tests.
Vous pouvez également ajouter des colonnes calculées, ( { average = elapsed/replications } ), c'est-à-dire la sortie sera une colonne moyenne qui divisera le temps total par le nombre de tests, nous calculons donc le temps d'exécution moyen de chaque fonction.
l'ordre est responsable du tri des résultats du test.
Conclusion
Dans cet article, en principe, une méthode assez universelle pour accélérer le travail avec l'API est décrite, mais chaque API a ses limites, par conséquent, spécifiquement sous cette forme, avec autant de threads, l'exemple ci-dessus convient pour travailler avec Yandex.Direct API, pour l'utiliser avec l'API d'autres services, il est initialement nécessaire de lire la documentation sur les limites de l'API pour le nombre de demandes envoyées simultanément, sinon vous risquez d'obtenir une erreur Too Many Requests .
La suite de cet article est disponible ici .