
L'apprentissage automatique est activement utilisé dans de nombreux domaines de notre vie. Les algorithmes aident à reconnaître les panneaux de signalisation, à filtrer le spam, à reconnaître les visages de nos amis sur Facebook et même à échanger en bourse. L'algorithme prend des décisions importantes, vous devez donc être sûr qu'il ne peut pas être dupe.
Dans cet article, qui est le premier d'une série, nous vous présenterons le problème de la sécurité des algorithmes d'apprentissage automatique. Cela ne nécessite pas un niveau élevé de connaissance de l'apprentissage automatique du lecteur, il suffit d'avoir une idée générale de ce domaine.
Tout d'abord, nous donnons les termes utilisés dans le sujet de la sécurité des algorithmes d'apprentissage automatique:
Un exemple contradictoire est un vecteur qui alimente une entrée d'un algorithme sur lequel l'algorithme produit une sortie incorrecte.
Attaque contradictoire - un algorithme d'action dont le but est d'obtenir un exemple contradictoire.
Pour comprendre le problème des exemples contradictoires, rappelons l'une des tâches de l'apprentissage automatique - l'apprentissage avec un enseignant en notation. Dans ce problème, nous avons des paires «objet-étiquette» et nous devons apprendre à prédire la valeur de nouveaux objets.
Si nous considérons ce problème d'un point de vue géométrique, il est nécessaire de diviser l'espace de manière à prédire la classe «correcte» sur le nouvel objet. De plus, si nous avions un ensemble de données générales (par exemple, pour un ensemble de chiffres manuscrits MNIST pour avoir toutes sortes d'images de tous les chiffres), cet hyperplan pourrait être réalisé idéalement à condition que les classes soient séparables. Mais comme la population générale n'existe pas le plus souvent, pour résoudre ce problème, nous utilisons des algorithmes d'apprentissage automatique pour approximer l'hyperplan «idéal» aussi précisément que possible en utilisant les données dont nous disposons.
Toute déviation de l'hyperplan par rapport à l'idéal donne lieu à un certain «vide», tombant dans lequel les objets sont mal classés. C'est pourquoi des exemples tels que le panda, classé comme gibbon, apparaissent. Et la tâche de l'attaquant se réduit à changer le vecteur des paramètres de l'objet pour qu'il tombe dans cet «espace».
Exemples d'attaques contradictoires
Il existe un réseau de neurones qui détecte le visage sur une photo. Elle réussit à faire face à la tâche (image à gauche). Mais après avoir ajouté un peu de bruit à cette photo (image de droite), l'algorithme de l'exemple contradictoire obtenu (image au centre) ne détecte plus le visage dans l'image.

Cet exemple, démontré dans l'article « Attaques contradictoires sur les détecteurs de visage utilisant l'optimisation contrainte basée sur Neural Net », est intéressant parce que de nombreux systèmes de reconnaissance de visage réels utilisent des approches de réseau neuronal pour détecter les visages. Une personne ne remarquera pas la différence en regardant les deux images.
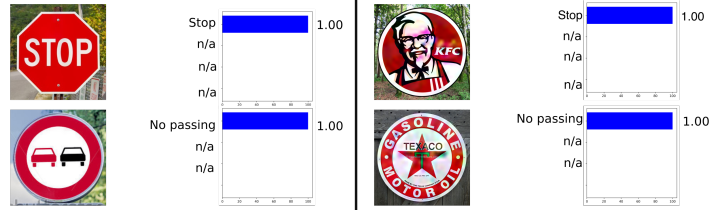
L'exemple suivant est tiré de l'automobile, à savoir la reconnaissance des panneaux de signalisation. Cet exemple est intéressant en ce que l'exemple contradictoire n'a pas à être un objet au moins quelque peu proche des objets sur lesquels le réseau a été formé. Par exemple, dans Rogue Signs: Deceiving Traffic Sign Recognition with Malicious Ads and Logos , il a été montré que l'exemple contradictoire du signe KFC sera «reconnu» par le réseau neuronal d'origine comme un signe STOP avec une probabilité de 100%.
Beaucoup pourraient douter de l'utilisation d'exemples contradictoires dans le monde réel, puisque les exemples précédents ont été testés sur ordinateur, alors que dans la vie réelle, un tel objet est difficilement possible à obtenir. Mais ce n'est pas le cas. La synthèse d'exemples contradictoires robustes a montré qu'un exemple contradictoire réalisé sur un ordinateur peut être imprimé avec succès sur une imprimante 3D, et l'algorithme fera les mêmes erreurs qu'avec une simulation informatique.

Ici, vous voyez une tortue imprimée sur une imprimante 3D, qui n'a été reconnue comme tortue sous aucun angle.
L'exemple suivant montre ce qui peut être fait si nous allons au-delà de la compréhension habituelle des attaques accusatoires. À savoir, reprogrammer le réseau source pour utiliser sa propre charge utile. En d'autres termes, nous apprenons à utiliser le réseau neuronal de quelqu'un d'autre pour résoudre le problème posé par l'attaquant. Par exemple, l' Adversrial Reprogramming of Neural Network a démontré comment un réseau formé sur ImageNet a parfaitement calculé le nombre de carrés dans une image et reconnu les nombres de l'ensemble MNIST.
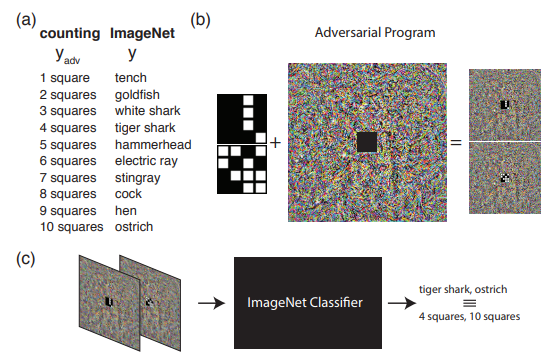
L'image montre l'algorithme de reprogrammation contradictoire, qui est recommandé pour mieux se connaître dans l'article original.
Dans cet article, je voudrais parler spécifiquement des méthodes pour générer des exemples contradictoires, et dans le deuxième article, nous allons passer aux méthodes de protection et tester les algorithmes d'apprentissage automatique.
Classification d'attaque
Toutes les attaques peuvent être divisées en 2 classes: WhiteBox (WB) et BlackBox (BB) . Dans le cas de WB, nous connaissons toutes les informations sur le modèle entraîné de l'algorithme, tandis que dans le cas de BB, nous n'avons accès qu'aux entrées et sorties du modèle. En fait, l'option GrayBox est toujours possible lorsque nous ne connaissons pas les informations sur le modèle entraîné, mais il existe des informations sur le type d'algorithme et ses hyperparamètres. Mais ce type ne se démarque pas dans une classe distincte, car des informations supplémentaires ne suffisent pas pour aller à WB, ce qui signifie qu'il ne s'agit que d'un ensemble d'informations supplémentaires pour mener une attaque BB.
Ensuite, il vaut la peine de classer les attaques ciblées et non ciblées . Les attaques ciblées signifient que l'attaque est menée dans une certaine direction. Par exemple, sur l'ensemble de données MNIST, nous formons le réseau neuronal et prenons l'image 0 de l'ensemble de test. Un réseau neuronal entraîné produit une probabilité de classe 0 de 1,00 dans cet objet. Si nous voulons que l'exemple accusatoire soit reconnu comme classe 1 après avoir appliqué l'attaque accusatoire, nous utiliserons l'attaque ciblée. Sinon, s'il n'est pas particulièrement important pour nous de quelle classe le réseau neuronal recevra l'image (l'essentiel est qu'il ne soit plus de classe 0), alors une telle attaque sera non ciblée.
De plus, les attaques sont divisées en une métrique selon laquelle 2 objets sont considérés comme similaires - normes. norm - le nombre de paramètres modifiés. Distance euclidienne entre deux vecteurs. différence maximale par élément entre deux vecteurs.
Bibliothèques Python
Les bibliothèques de données Python vous permettent de travailler avec des exemples contradictoires. Ce sont FoolBox, CleverHans et ART-IBM.
| Foolbox | Cleverhans | ART-IBM |
|---|
| Cadres pris en charge | TensorFlow, Keras, Theano, PyTorch, Lasagne, MXNet | TensorFlow, Keras | TensorFlow, Keras, promettent MXNet, PyTorch |
Examinons maintenant les attaques plus en détail et commençons par les attaques WhiteBox.
Attaque L-BFGS
L'énoncé de la méthode L-BFGS peut être écrit comme suit.
Il en résulte que nous voulons minimiser la fonction de perte en direction de la classe cible avec la restriction que les changements introduits étaient minimes. Dans le même temps, il a été proposé de résoudre un tel problème dans l'article d'origine en utilisant la méthode L-BFGS, d'où le nom de cette attaque.
Article d'origine - Propriétés intrigantes des réseaux de neurones
Cette attaque est présentée dans 2 des 3 bibliothèques précédemment exprimées - FoolBox et CleverHans.
Et l'application de cette attaque sur FoolBox prend 3 lignes de code en Python:
from foolbox.attacks import LBFGSAttack attack = LBFGSAttack(fmodel) adversarial = attack(image, label)
L'utilisation de L-BFGS vous aidera à trouver les meilleurs exemples contradictoires en fonction de vos limites, mais, premièrement, la recherche d'un tel exemple peut prendre beaucoup de temps, et deuxièmement, il est fort possible que la méthode ne converge tout simplement pas.
Attaque FGSM
La prochaine étape de développement a été la FGSM (Fast Sign Gradient Method), qui peut être montrée en utilisant la formule:
Cette méthode fonctionne beaucoup plus rapidement que le L-BFGS. Ici, nous prenons simplement les signes de la fonction de gradient de la fonction de perte d'origine, en multipliant le signe par certains , ajoutez à l'image d'origine.

Voici un exemple de fonctionnement de cette méthode. Une carte du bruit avec égal à 0,007, et il s'avère que la photo du panda est maintenant reconnue comme Gibbon avec une probabilité de 99,3%
Cette méthode est simple à mettre en œuvre, mais en même temps, le résultat de cette méthode est très bruyant.
Article d'origine - Expliquer et exploiter les exemples contradictoires
Vous pouvez trouver l'implémentation de cette méthode dans les bibliothèques, et l'utilisation de foolbox ne prendra pas non plus beaucoup de temps.
from foolbox.attacks import FGSM attack = FGSM(fmodel) adversarial = attack(image, label)
Attaque Deepfool
DeepFool est une méthode non ciblée. Sa principale différence avec les méthodes précédentes est qu'il essaie de faire une carte de bruit minimale, ce qui trompera l'algorithme. La méthode ne vous permet pas de créer une classe particulière à partir d'une classe, mais fait toute autre qui est la plus proche de l'image d'origine.

Un exemple montre l'image d'origine, sur la dernière ligne - la méthode FGSM, et au milieu - juste une attaque DeepFool. On peut voir que la carte de bruit est beaucoup plus petite qu'avec le FGSM.
Article original - DeepFool: une méthode simple et précise pour tromper les réseaux de neurones profonds
Une telle attaque peut être effectuée à l'aide de l'une des bibliothèques répertoriées, et l'implémentation sur ART-IBM ne prend que 3 lignes de code:
from art.attacks import DeepFool attack = DeepFool(model) img_adv = attack.generate(img)
Attaque de carte de saillance jacobienne
Dans la méthode JSMA, une dérivée directe est considérée, sur la base de laquelle une carte de gradient est construite. Sur la carte, chaque paramètre de l'objet correspond en fait à la contribution de ce paramètre à la modification du résultat final de l'algorithme. Ainsi, la méthode vous permet de modifier le moins de paramètres possible dans l'objet attaqué. Et, en conséquence, cela fonctionne sur normal.
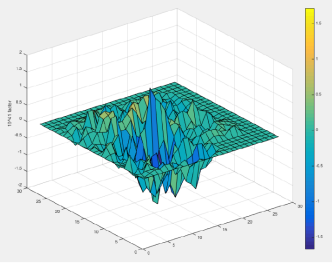
Article d'origine - Les limites de l'apprentissage en profondeur en milieu contradictoire
Cette attaque peut être effectuée à l'aide de CleverHans ou ART-IBM. Et sur CleverHans, cela ressemble à ceci:
from cleverhans.attacks import SaliencyMapMethod jsma = SaliencyMapMethod(model, sees=sees) jsma_params = { 'theta' : 1., 'gamma' : 0.1, 'clip_min' : 0., 'clip_max' : 1., 'y_target' : None} adv_x = jsma.generate_np(img, **jsma_params)
Attaque à un pixel
La question logique est, quel est le nombre minimum de pixels qui doivent être modifiés pour mener une attaque sur l'algorithme, et comme beaucoup l'ont déjà deviné par le nom de l'attaque, 1 pixel suffit.

Par exemple, l'image d'un cheval avec un seul pixel modifié devient une grenouille avec une probabilité de 99,9%
Article d'origine - Attaque d'un pixel pour tromper les réseaux de neurones profonds
Cette attaque est prise en charge uniquement dans FoolBox et son implémentation est la suivante:
from foolbox.attacks import SinglePixelAttack attack = SinglePixelAttack(fmodel) adversarial = attack(image,max_pixel=1)
Ici, il vaut la peine de faire une réserve et de dire que la mise en œuvre de l'algorithme dans Foolbox, par rapport à l'article d'origine, a bien un objectif commun (changer le nombre spécifique de pixels dans l'image), mais diffère dans la méthode d'obtention de l'image.
Méthodes basées sur la généralisation du modèle BlackBox
La plupart des méthodes nécessitent une compréhension de la façon dont l'architecture du modèle est structurée, une connaissance des valeurs exactes de ses paramètres, mais en pratique, cela est rarement possible. Et c'est pourquoi une direction d'attaque distincte apparaît - les attaques BlacBox / GrayBox. Pour de telles attaques, il suffit d'avoir accès aux entrées et sorties du modèle.
L'une des méthodes pour implémenter une attaque sur le modèle BlackBox est de généraliser ce modèle au modèle Student (dans l'image de substitution).
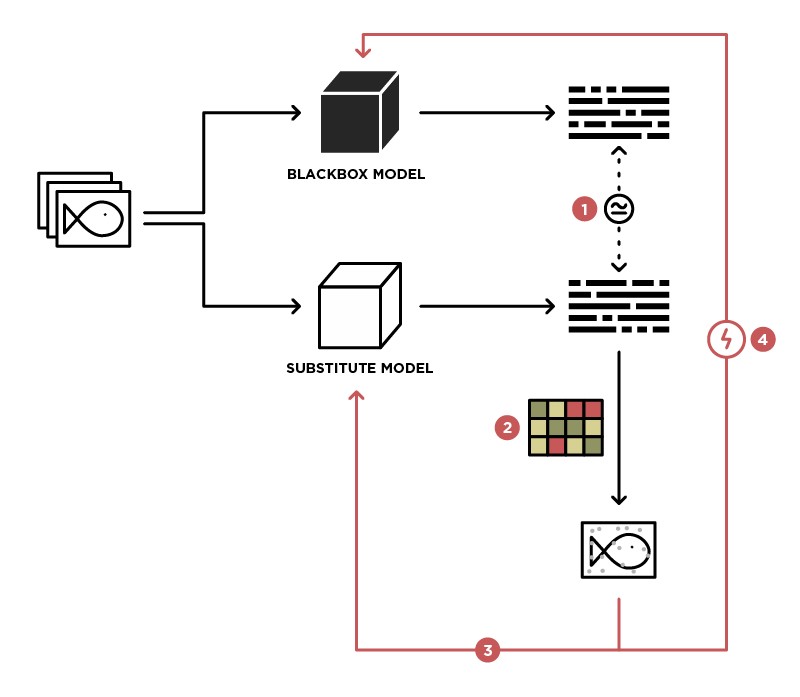
Ayant accès pour envoyer des données au modèle BlackBox (enseignant) et accès à la sortie de ce modèle, nous pouvons créer un ensemble de données sur lequel il est possible de former notre propre modèle (étudiant), généralisant ainsi le modèle enseignant. Après cela, vous pouvez utiliser l'attaque WhiteBox sur le modèle Student, et avec un degré élevé de probabilité, cette attaque aura également lieu sur le modèle Teacher. La probabilité d'une telle attaque est la plus élevée, plus nous avons de connaissances sur le modèle Teacher. Par exemple, nous savons que le modèle Teacher traite des images, le plus souvent des architectures pré-formées (ResNet, Inception) avec des poids ImageNet sont utilisées pour le traitement d'images. Basé sur le modèle Student avec la même architecture, la probabilité d'une attaque réussie sera maximisée.
Article d'origine - Attaques pratiques en boîte noire contre l'apprentissage automatique
Cette méthode n'est présentée dans aucune des bibliothèques et nécessite une implémentation indépendante du modèle Student, et des attaques contre elle peuvent être effectuées en utilisant les méthodes décrites ci-dessus.
Méthodes basées sur GAN
La prochaine étape dans le développement des attaques BlackBox a été les attaques basées sur l'intégration du modèle BlackBox dans l'architecture du réseau génératif-accusatoire (GAN), un réseau qui permet la génération de nouveaux objets, qui seront ensuite transférés au modèle Black-Box.
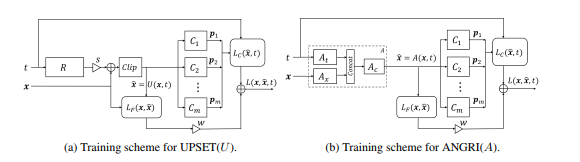
Cette méthode a permis de générer des exemples contradictoires pour presque toutes les architectures. Il nécessite également l'accès à l'entrée et à la sortie du modèle attaqué.
En savoir plus sur cette méthode dans l'article d'origine - UPSET et ANGRI: Briser les classificateurs d'images haute performance
Comme vous l'avez peut-être deviné, ces méthodes ne sont représentées dans aucune des bibliothèques.
Conclusion
En fait, il y a un grand nombre d'attaques. Cet article n'en couvre que quelques-uns. Nous espérons que ce matériel vous a aidé à comprendre les concepts de base des exemples contradictoires et leurs algorithmes de génération. Pour un examen plus détaillé, nous vous recommandons de lire les articles et documents originaux de la liste de références.
Rendez-vous dans le prochain article, qui se concentrera sur les méthodes de protection et de test des algorithmes d'apprentissage automatique.
Les références
- Menace d'attaques contradictoires sur l'apprentissage profond en vision par ordinateur: une enquête - un excellent aperçu des méthodes d'attaque des algorithmes d'apprentissage en profondeur en vision par ordinateur
- Attaquer l'apprentissage automatique avec des exemples contradictoires - un blog OpenAI dédié aux exemples contradictoires
- Awesome Adversarial Machine Learning - github avec des liens vers de nombreux documents utiles sur des sujets contradictoires
- Présentation sur Adversarial Machine Learning - Présentation de la conférence MoscowPythonConf2018 sur Adversarial Machine Learning