Présentation
Dans un article précédent (
«Partie 2: Utilisation de blocs UDB Cypress PSoC pour réduire le nombre d'interruptions dans une imprimante 3D» ), j'ai noté un fait très intéressant: si une machine dans UDB supprimait trop rapidement des données de FIFO, elle réussissait à remarquer l'état qu'il y avait de nouvelles il n'y a pas de données dans FIFO, après quoi elles passent dans un faux état
Idle . Bien sûr, j'étais intéressé par ce fait. J'ai montré les résultats ouverts à un groupe de connaissances. Une personne a répondu que tout cela était tout à fait évident et a même cité les raisons. Les autres n'étaient pas moins surpris que moi au début de la recherche. Certains experts ne trouveront donc rien de nouveau ici, mais ce serait bien de porter ces informations à la disposition du grand public afin que tous les programmeurs de microcontrôleurs les aient en tête.
Non pas que ce soit une panne d'une sorte de couverture. Il s'est avéré que tout cela est bien documenté, mais le problème est que ce n'est pas dans l'ensemble, mais dans des documents supplémentaires. Et personnellement, j'étais dans une ignorance heureuse, croyant que le DMA est un sous-système très agile qui peut augmenter considérablement l'efficacité des programmes, car il y a un transfert systématique de données sans distraire l'incrément de registre et organiser le cycle avec les mêmes commandes. Quant à l'amélioration de l'efficacité - tout est vrai, mais en raison de choses légèrement différentes.
Mais tout d'abord.
Expériences avec Cypress PSoC
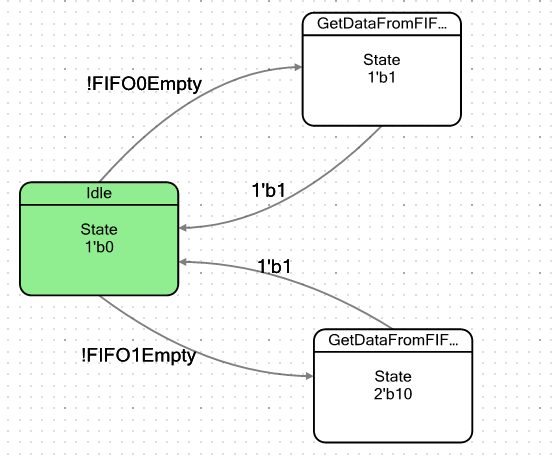
Faisons une machine simple. Il aura conditionnellement deux états: l'état inactif et l'état dans lequel il tombera lorsqu'il y aura au moins un octet de données dans FIFO. En entrant dans cet état, il prendra simplement ces données, puis échouera à nouveau dans un état de repos. Le mot «conditionnel» que je n'ai pas cité accidentellement. Nous avons deux FIFO, donc je vais créer deux de ces états, un pour chaque FIFO, pour m'assurer qu'ils sont complètement identiques dans leur comportement. Le graphique de transition pour la machine s'est avéré comme ceci:
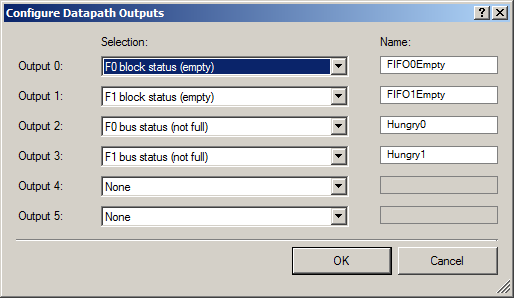
Les indicateurs de sortie de l'état inactif sont définis comme suit:
N'oubliez pas de soumettre les bits du numéro d'état aux entrées Datapath:

À l'extérieur, nous émettons deux groupes de signaux: une paire de signaux que FIFO a de l'espace libre (pour que DMA puisse commencer à y télécharger des données), et quelques signaux que FIFO est vide (pour afficher ce fait sur un oscilloscope).

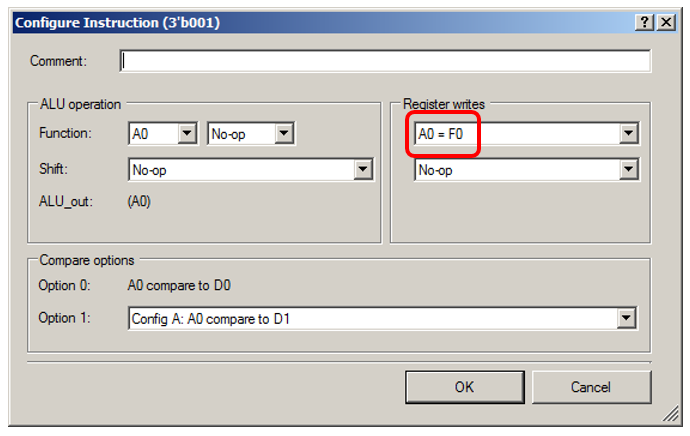
ALU prendra simplement fictivement des données de FIFO:

Permettez-moi de vous montrer les détails de l'état "0001":
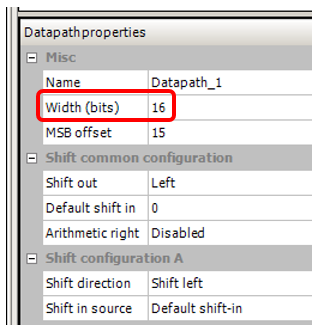
J'ai également réglé la largeur du bus, qui était dans le projet sur lequel j'ai remarqué cet effet, 16 bits:
Nous passons au schéma du projet lui-même. Extérieurement, je donne non seulement des signaux indiquant que le FIFO est vide, mais aussi des impulsions d'horloge. Cela me permettra de me passer de mesures de curseur sur un oscilloscope. Je peux simplement prendre des mesures avec mon doigt.
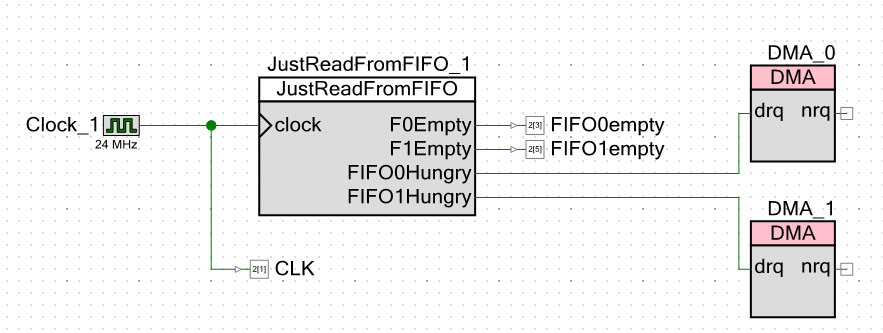
Apparemment, j'ai fait une vitesse d'horloge de 24 mégahertz. La fréquence centrale du processeur est exactement la même. Plus la fréquence est basse, moins il y a d'interférences sur un oscilloscope chinois (officiellement il a une bande de 250 MHz, mais ensuite des mégahertz chinois), et toutes les mesures seront effectuées par rapport aux impulsions d'horloge. Quelle que soit la fréquence, le système fonctionnera toujours à leur égard. J'aurais réglé un mégahertz, mais l'environnement de développement m'a interdit d'entrer une valeur de fréquence centrale de processeur inférieure à 24 MHz.
Maintenant, le test. Pour écrire sur FIFO0, j'ai fait cette fonction:
void WriteTo0FromROM() { static const uint16 steps[] = { 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001, 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001 }; // DMA , uint8 channel = DMA_0_DmaInitialize (sizeof(steps[0]),1,HI16(steps),HI16(JustReadFromFIFO_1_Datapath_1_F0_PTR)); CyDmaChRoundRobin (channel,1); // , uint8 td = CyDmaTdAllocate(); // . , . CyDmaTdSetConfiguration(td, sizeof(steps), CY_DMA_DISABLE_TD, TD_INC_SRC_ADR / TD_AUTO_EXEC_NEXT); // CyDmaTdSetAddress(td, LO16((uint32)steps), LO16((uint32)JustReadFromFIFO_1_Datapath_1_F0_PTR)); // CyDmaChSetInitialTd(channel, td); // CyDmaChEnable(channel, 1); }
Le mot ROM dans le nom de la fonction est dû au fait que le tableau à envoyer est stocké dans la zone ROM, et le Cortex M3 a une architecture Harvard. La vitesse d'accès au bus RAM et au bus ROM peut varier, je voulais le vérifier, j'ai donc une fonction similaire pour envoyer un tableau depuis la RAM (le tableau des
étapes n'a pas de modificateur de
const statique dans son corps). Eh bien, il y a la même paire de fonctions pour l'envoi vers FIFO1, le registre récepteur y est différent: pas F0, mais F1. Sinon, toutes les fonctions sont identiques. Comme je n'ai pas remarqué beaucoup de différence dans les résultats, je considérerai les résultats de l'appel exact de la fonction ci-dessus. Une impulsion d'horloge jaune, sortie bleue
FIFO0empty .

Tout d'abord, vérifiez la plausibilité de la raison pour laquelle la FIFO est remplie sur deux cycles d'horloge. Voyons ce site plus en détail:
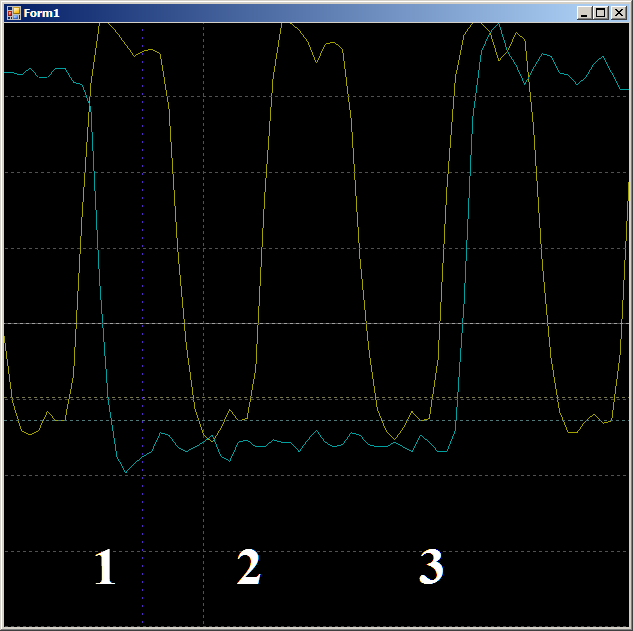
Sur le bord 1, les données tombent dans FIFO, le drapeau
FIFO0enmpty tombe. Sur le bord 2, l'automate entre dans l'état
GetDataFromFifo1 . Au bord 3, dans cet état, les données de FIFO sont copiées dans le registre ALU, FIFO est vidé, le drapeau
FIFO0empty est de nouveau
levé . Autrement dit, la forme d'onde se comporte de manière plausible, vous pouvez compter sur elle le cycle d'horloge. Nous obtenons 9 pièces.
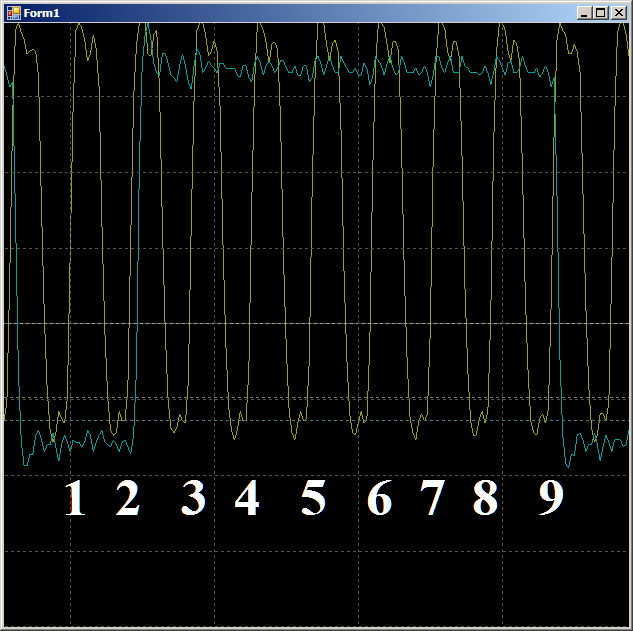 Au total, dans la zone inspectée, il faut 9 cycles d'horloge pour copier un mot de données de la RAM vers l'UDB en utilisant le DMA.
Au total, dans la zone inspectée, il faut 9 cycles d'horloge pour copier un mot de données de la RAM vers l'UDB en utilisant le DMA.Et maintenant la même chose, mais avec l'aide du cœur du processeur. Tout d'abord, un code idéal difficilement réalisable dans la vie réelle:
volatile uint16_t* ptr = (uint16_t*)JustReadFromFIFO_1_Datapath_1_F0_PTR; ptr[0] = 0; ptr[0] = 0;
ce qui va se transformer en code assembleur:
ldr r3, [pc, #8] ; (90 <main+0xc>) movs r2, #0 strh r2, [r3, #0] strh r2, [r3, #0] bn 8e <main+0xa> .word 0x40006898
Pas de pauses, pas de cycles supplémentaires. Deux paires de mesures d'affilée ...
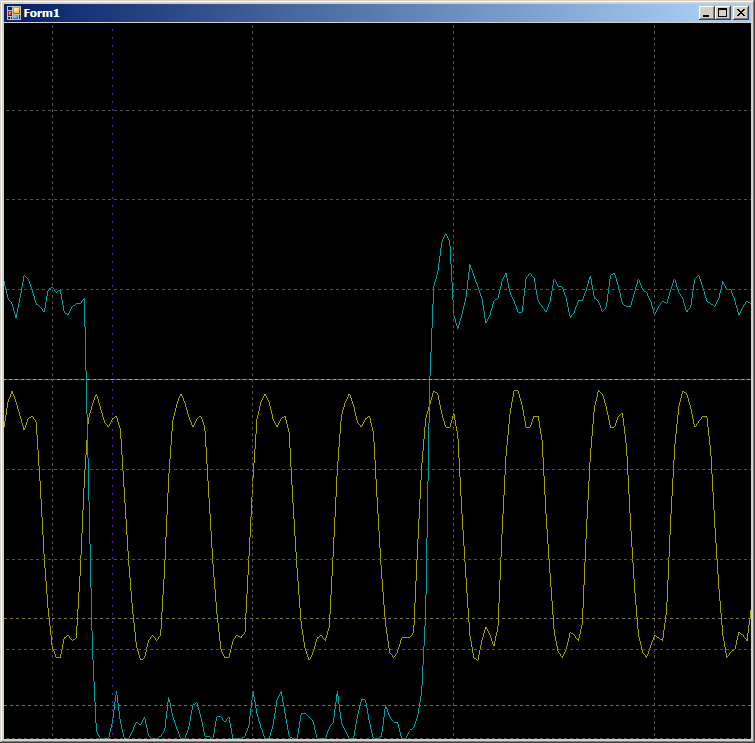
Rendons le code un peu plus réel (avec la surcharge d'organisation du cycle, la récupération des données et l'incrémentation des pointeurs):
void SoftWriteTo0FromROM() { // . // static const uint16 steps[] = { 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001, 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001 }; uint16_t* src = steps; volatile uint16_t* dest = (uint16_t*)JustReadFromFIFO_1_Datapath_1_F0_PTR; for (int i=sizeof(steps)/sizeof(steps[0]);i>0;i--) { *dest = *src++; } }
code assembleur reçu:
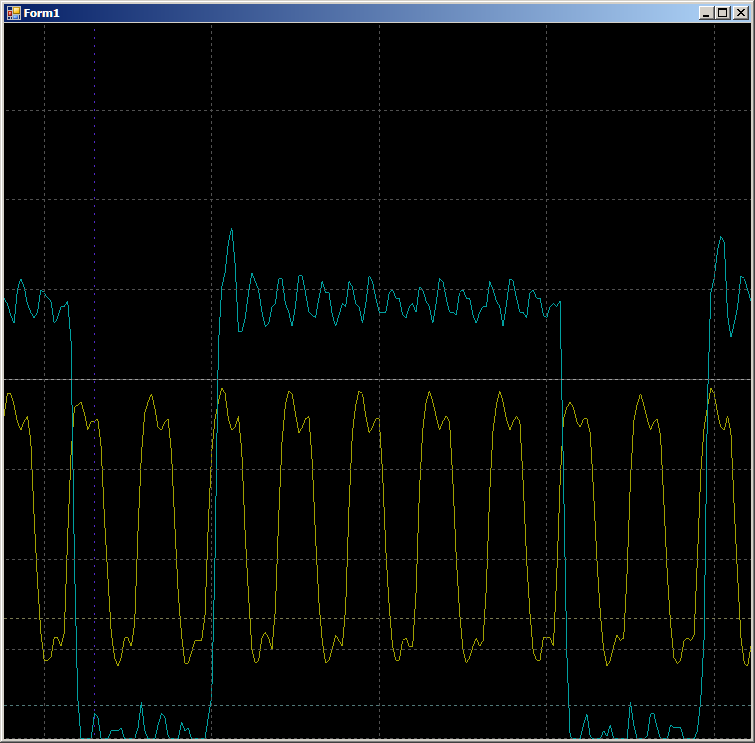
ldr r3, [pc, #14] ; (9c <CYDEV_CACHE_SIZE>) ldr r0, [pc, #14] ; (a0 <CYDEV_CACHE_SIZE+0x4>) add.w r1, r3, #28 ; 0x28 ldrh.w r2, [r3], #2 cmp r3, r1 strh r2, [r0, #0] bne.n 8e <main+0xa>
Sur l'oscillogramme, nous ne voyons que 7 cycles par cycle contre neuf dans le cas du DMA:
Un peu de mythe
Pour être honnête, ce fut à l'origine un choc pour moi. Je suis en quelque sorte habitué à croire que le mécanisme DMA vous permet de transférer des données rapidement et efficacement. 1/9 de la fréquence du bus n'est pas si rapide. Mais il s'est avéré que personne ne le cachait. Le document TRM pour PSoC 5LP contient même un certain nombre de considérations théoriques, et le document «AN84810 - Sujets DMA avancés PSoC 3 et PSoC 5LP» décrit en détail le processus d'accès à DMA. La latence est à blâmer. Le cycle d'échange avec le bus prend un certain nombre de ticks. En effet, ce sont ces mesures qui jouent un rôle déterminant dans la survenance d'un retard. En général, personne ne cache rien, mais vous devez le savoir.
Si le fameux GPIF utilisé dans FX2LP (une autre architecture fabriquée par Cypress) ne limite rien, alors la limite de vitesse est due aux latences qui se produisent lors de l'accès au bus.Vérification DMA sur STM32
J'étais tellement impressionné que j'ai décidé de mener une expérience sur STM32. Un STM32F103 ayant le même noyau de processeur Cortex M3 a été pris comme lapin expérimental. Il n'a pas d'UDB à partir duquel des signaux de service pourraient être dérivés, mais il est tout à fait possible de vérifier le DMA. Qu'est-ce qu'un GPIO? Il s'agit d'un ensemble de registres dans un espace d'adressage commun. C’est bien. Nous configurons le DMA en mode de copie «mémoire-mémoire», en spécifiant la mémoire réelle (ROM ou RAM) comme source, et le registre de données GPIO sans l'incrément d'adresse comme récepteur. Nous y enverrons alternativement 0 ou 1, et fixerons le résultat avec un oscilloscope. Pour commencer, j'ai choisi le port B, c'était plus facile de s'y connecter sur la maquette.

J'ai vraiment aimé compter les mesures avec un doigt, pas avec des curseurs. Est-il possible de faire de même sur ce contrôleur? Tout à fait! Prenez la fréquence d'horloge de référence pour l'oscilloscope de la jambe MCO, qui est connectée au port PA8 sur le STM32F10C8T6. Le choix des sources pour ce cristal pas cher n'est pas génial (le même STM32F103, mais plus impressionnant, il donne bien plus d'options), nous enverrons un signal SYSCLK à cette sortie. Étant donné que la fréquence sur le MCO ne peut pas être supérieure à 50 MHz, nous réduirons la vitesse d'horloge globale du système à 48 MHz. Nous multiplierons la fréquence du quartz 8 MHz non par 9, mais par 6 (puisque 6 * 8 = 48):

Même texte: void SystemClock_Config(void) { RCC_OscInitTypeDef RCC_OscInitStruct; RCC_ClkInitTypeDef RCC_ClkInitStruct; RCC_PeriphCLKInitTypeDef PeriphClkInit; /**Initializes the CPU, AHB and APB busses clocks */ RCC_OscInitStruct.OscillatorType = RCC_OSCILLATORTYPE_HSE; RCC_OscInitStruct.HSEState = RCC_HSE_ON; RCC_OscInitStruct.HSEPredivValue = RCC_HSE_PREDIV_DIV1; RCC_OscInitStruct.HSIState = RCC_HSI_ON; RCC_OscInitStruct.PLL.PLLState = RCC_PLL_ON; RCC_OscInitStruct.PLL.PLLSource = RCC_PLLSOURCE_HSE; // RCC_OscInitStruct.PLL.PLLMUL = RCC_PLL_MUL9; RCC_OscInitStruct.PLL.PLLMUL = RCC_PLL_MUL6; if (HAL_RCC_OscConfig(&RCC_OscInitStruct) != HAL_OK) { _Error_Handler(__FILE__, __LINE__); }
Nous programmerons l'AGC en utilisant la bibliothèque
mcucpp de Konstantin Chizhov (à partir de maintenant je conduirai tous les appels à l'équipement via cette merveilleuse bibliothèque):
// MCO Mcucpp::Clock::McoBitField::Set (0x4); // MCO Mcucpp::IO::Pa8::SetConfiguration (Mcucpp::IO::Pa8::Port::AltFunc); // Mcucpp::IO::Pa8::SetSpeed (Mcucpp::IO::Pa8::Port::Fastest);
Eh bien, maintenant, nous définissons la sortie du tableau de données dans le GPIOB:
typedef Mcucpp::IO::Pb0 dmaTest0; typedef Mcucpp::IO::Pb1 dmaTest1; ... // GPIOB dmaTest0::ConfigPort::Enable(); dmaTest0::SetDirWrite(); dmaTest1::ConfigPort::Enable(); dmaTest1::SetDirWrite(); uint16_t dataForDma[]={0x0000,0x8001,0x0000,0x8001,0x0000, 0x8001,0x0000,0x8001,0x0000,0x8001,0x0000,0x8001,0x0000,0x8001}; typedef Mcucpp::Dma1Channel1 channel; // dmaTest1::Set(); dmaTest1::Clear(); dmaTest1::Set(); // , DMA channel::Init (channel::Mem2Mem|channel::MSize16Bits|channel::PSize16Bits|channel::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); while (1) { } }
La forme d'onde résultante est très similaire à celle du PSoC.

Au milieu, une grande bosse bleue. Il s'agit du processus d'initialisation DMA. Les impulsions bleues de gauche ont été reçues uniquement par logiciel sur PB1. Étirez-les plus large:

2 mesures par impulsion. Le fonctionnement du système est conforme aux attentes. Mais maintenant, regardons la plus grande zone marquée sur la forme d'onde principale avec un fond bleu foncé. À ce stade, le bloc DMA est déjà en cours d'exécution.
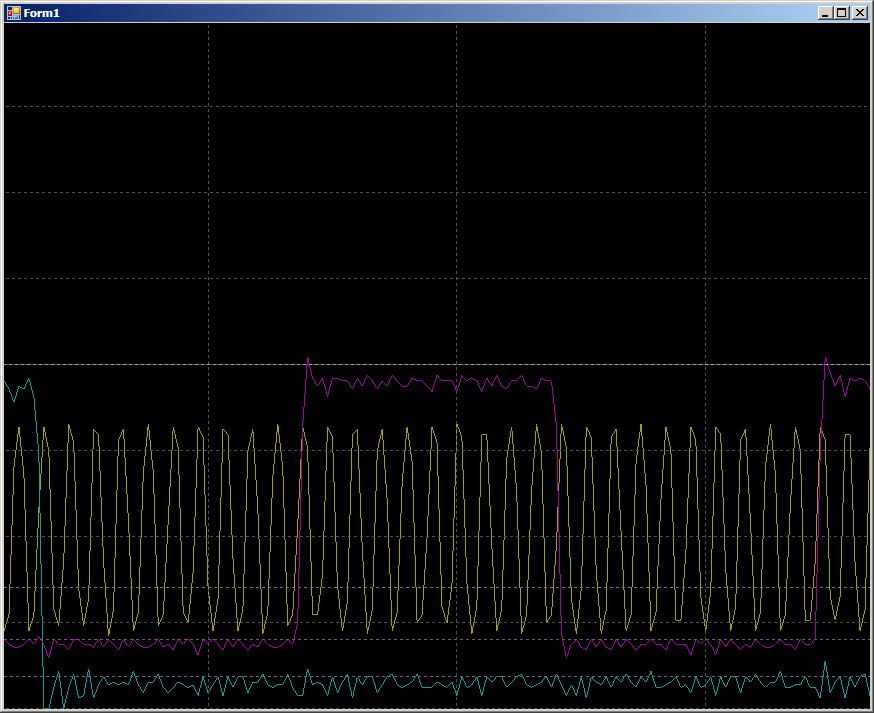
10 cycles par changement de ligne GPIO. En fait, le travail va de pair avec la RAM et le programme est bouclé dans un cycle constant. Il n'y a aucun appel à la RAM depuis le cœur du processeur. Le bus est complètement à la disposition de l'unité DMA, mais 10 cycles. Mais en fait, les résultats ne sont pas très différents de ceux vus sur le PSoC, alors commencez simplement à chercher des notes d'application liées à DMA sur STM32. Il y en avait plusieurs. Il y a AN2548 sur F0 / F1, il y a AN3117 sur L0 / L1 / L3, il y a AN4031 sur F2 / F4 / F77. Il y en a peut-être d'autres ...
Mais, néanmoins, nous voyons qu’ici aussi, la latence est à blâmer. De plus, l'accès par lots F103 au bus avec DMA est impossible. Ils sont possibles pour F4, mais pas plus que pour quatre mots. Là encore, le problème de latence se posera.
Essayons d'exécuter les mêmes actions, mais à l'aide d'un enregistrement de programme. Ci-dessus, nous avons vu que l'enregistrement direct sur les ports se fait instantanément. Mais le record était plutôt parfait. Rangées:
// dmaTest1::Set(); dmaTest1::Clear(); dmaTest1::Set();
sous réserve de ces paramètres d'optimisation (vous devez spécifier l'optimisation pour le temps):

transformé en code assembleur suivant:
STR r6,[r2,#0x00] MOV r0,#0x20000 STR r0,[r2,#0x00] STR r6,[r2,#0x00]
Dans la copie réelle, il y aura un appel à la source, au récepteur, un changement dans la variable de boucle, une ramification ... En général, beaucoup de surcharge (ce qui, comme on le croit, soulage simplement le DMA). Quelle sera la vitesse des changements dans le port? Nous écrivons donc:
uint16_t* src = dataForDma; uint16_t* dest = (uint16_t*)&GPIOB->ODR; for (int i=sizeof(dataForDma)/sizeof(dataForDma[0]);i>0;i--) { *dest = *src++; }
Ce code C ++ se transforme en un tel code d'assembly:
MOVS r1,#0x0E LDRH r3,[r0],#0x02 STRH r3,[r2,#0x00] LDRH r3,[r0],#0x02 SUBS r1,r1,#2 STRH r3,[r2,#0x00] CMP r1,#0x00 BGT 0x080032A8
Et nous obtenons:
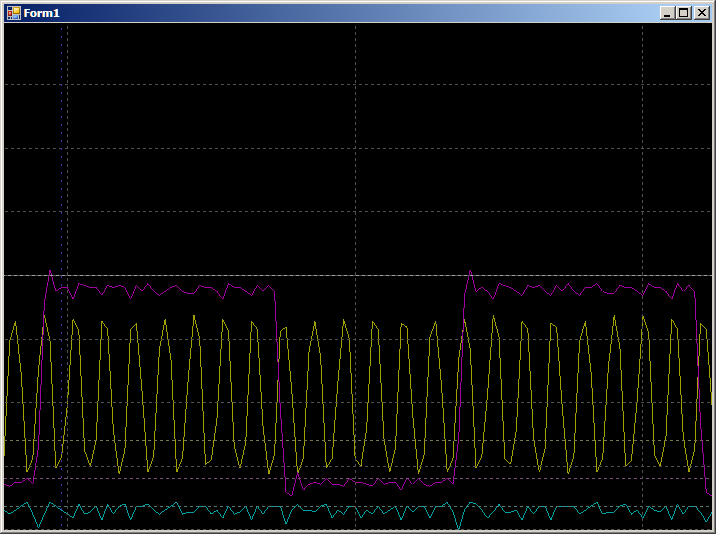
8 mesures dans le demi-cycle supérieur et 6 dans la moitié inférieure (j'ai vérifié, le résultat est répété pour toutes les demi-périodes). La différence est survenue car l'optimiseur a effectué 2 copies par itération. Par conséquent, 2 mesures dans l'une des demi-périodes s'ajoutent à l'activité de la succursale.
En gros, avec la copie de logiciels, 14 mesures sont dépensées pour copier deux mots contre 20 mesures sur le même, mais par DMA. Le résultat est assez documenté, mais très inattendu pour ceux qui n'ont pas encore lu la littérature étendue.Bon. Mais que se passe-t-il si vous commencez à écrire des données dans deux flux DMA à la fois? Quelle vitesse va chuter? Connectez le rayon bleu à PA0 et réécrivez le programme comme suit:
typedef Mcucpp::Dma1Channel1 channel1; typedef Mcucpp::Dma1Channel2 channel2; // , DMA channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
Examinons d'abord la nature des impulsions:
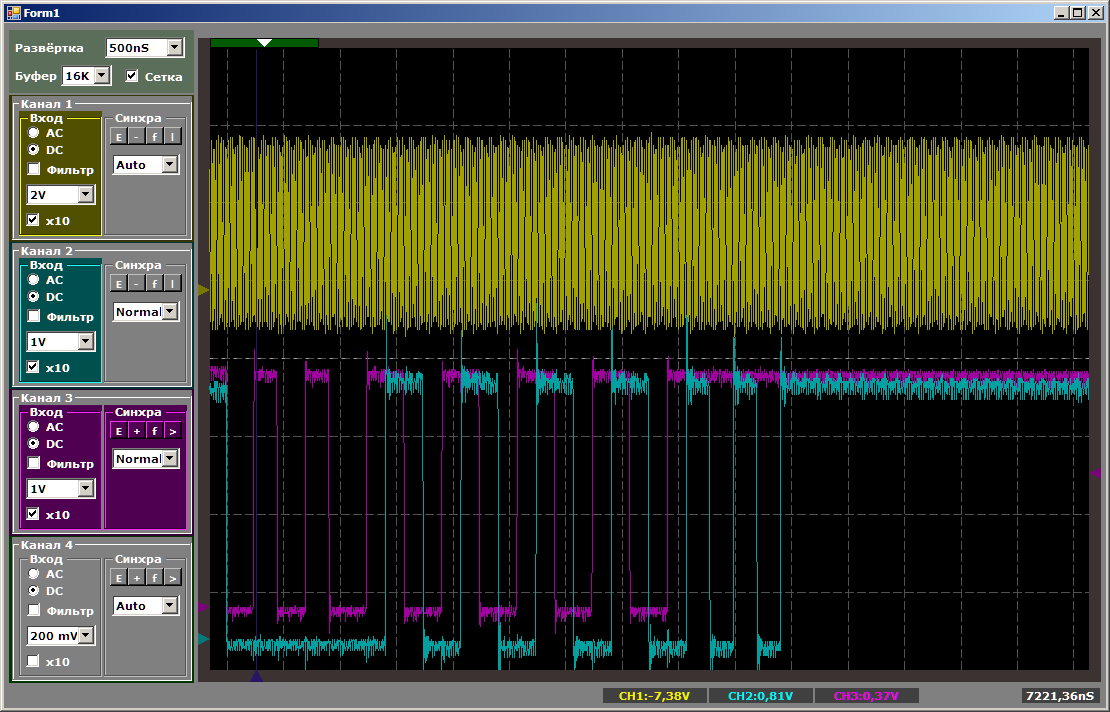
Pendant que le deuxième canal est réglé, la vitesse de copie du premier est plus élevée. Ensuite, lors de la copie par paire, la vitesse diminue. Lorsque le premier canal est terminé, le second commence à fonctionner plus rapidement. Tout est logique, il ne reste plus qu'à savoir exactement combien la vitesse baisse.
Bien qu'il n'y ait qu'un seul canal, l'enregistrement prend de 10 à 12 mesures (les chiffres flottent).

Pendant la collaboration, nous obtenons 16 cycles par enregistrement dans chaque port:
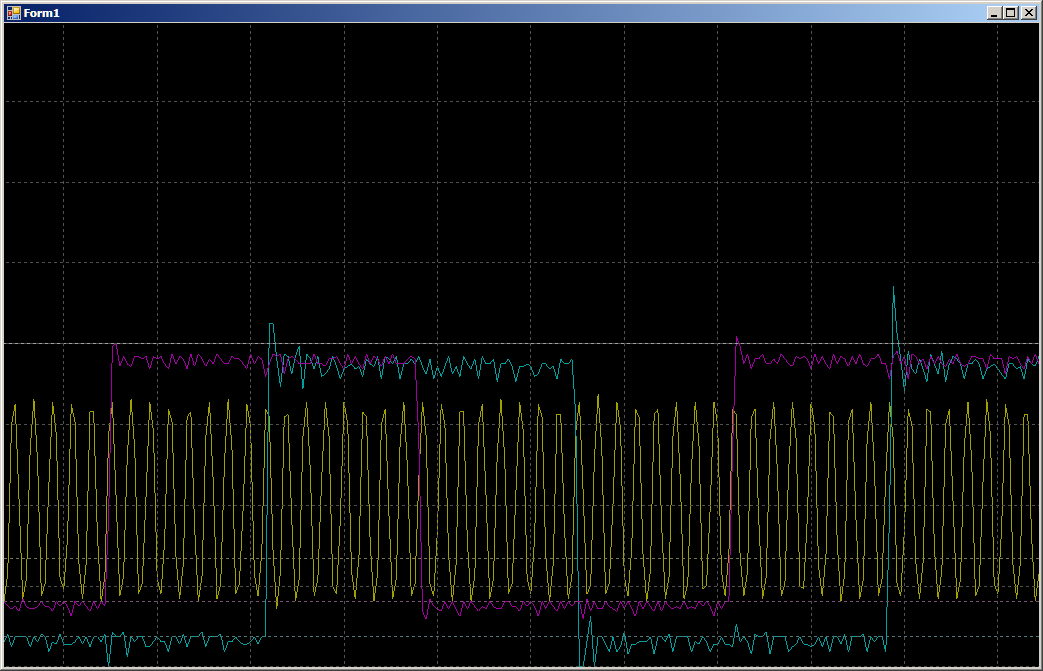
Autrement dit, la vitesse n'est pas réduite de moitié. Mais que faire si vous commencez à écrire en trois fils à la fois? Nous ajoutons du travail avec PC15, car PC0 n'est pas sorti (c'est pourquoi pas 0, 1, 0, 1 ..., mais 0x0000,0x8001, 0x0000, 0x8001 ... sont émis dans le tableau).
typedef Mcucpp::Dma1Channel1 channel1; typedef Mcucpp::Dma1Channel2 channel2; typedef Mcucpp::Dma1Channel3 channel3; // , DMA channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2);
Ici, le résultat est tellement inattendu que j'éteins le faisceau affichant la fréquence d'horloge. Nous n'avons pas de temps pour les mesures. Nous regardons la logique du travail.

Jusqu'à ce que la première chaîne ait terminé ses travaux, la troisième n'a pas commencé à fonctionner. Trois canaux en même temps ne fonctionnent pas! Quelque chose sur ce sujet peut être déduit d'AppNote à DMA, il dit que F103 n'a que deux moteurs dans un bloc (et nous copions en utilisant un bloc de DMA, le second est maintenant inactif et le volume de l'article est déjà tel que je peux l'utiliser) Je ne le ferai pas). Nous réécrivons l'exemple de programme afin que le troisième canal démarre plus tôt que tout le monde:

Même texte: // , DMA channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
L'image changera comme suit:

La troisième chaîne a été lancée, elle a même collaboré avec la première, mais à mesure que la deuxième est entrée dans l'entreprise, la troisième a été supplantée jusqu'à ce que la première chaîne soit terminée.
Un peu de priorités
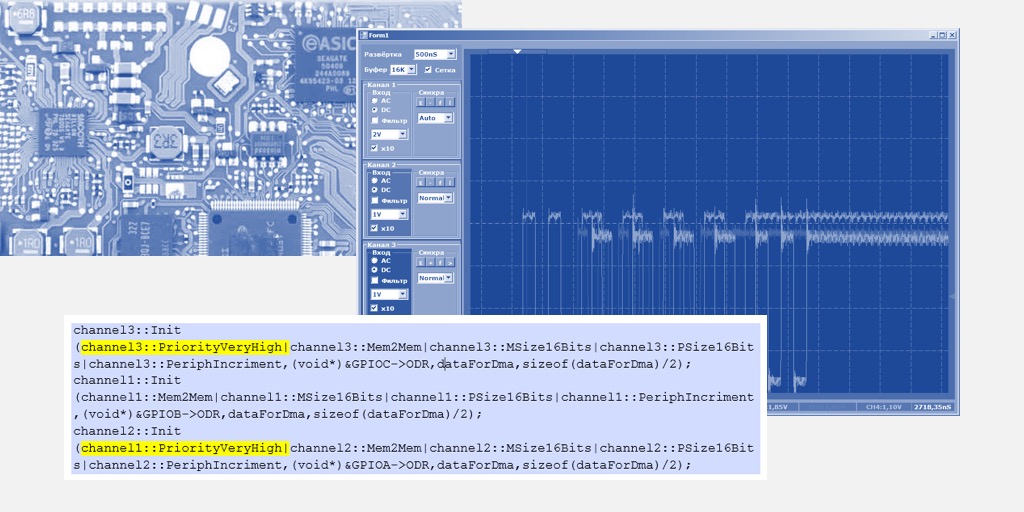
En fait, l'image précédente est liée aux priorités de DMA, il y en a. Si tous les canaux de travail ont la même priorité, leurs numéros entrent en jeu. Dans une priorité donnée, celle qui en a le plus petit nombre est celle qui a la priorité. Essayons le troisième canal pour indiquer une priorité globale différente, en l'élevant au-dessus de tous les autres (en cours de route, nous augmenterons également la priorité du deuxième canal):

Même texte: channel3::Init (channel3::PriorityVeryHigh|channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel1::PriorityVeryHigh|channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
Désormais, le premier qui était le plus cool sera désavantagé.
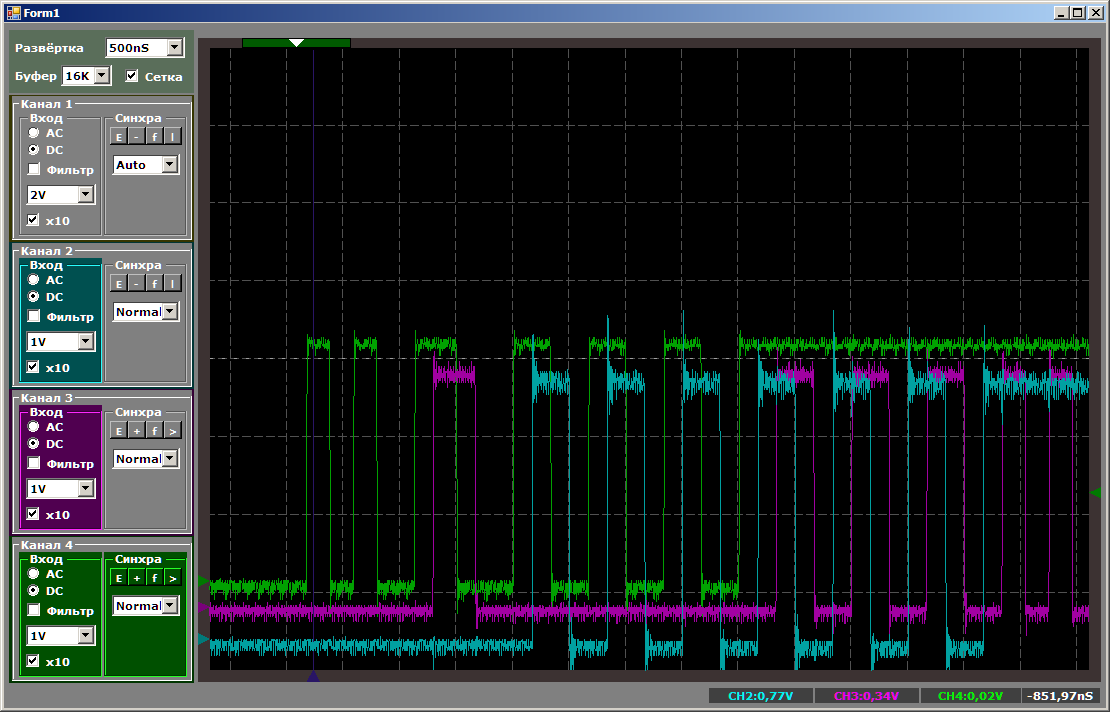
Au total, nous voyons que même en jouant dans les priorités, STM32F103 ne peut pas lancer plus de deux threads sur un bloc DMA. En principe, le troisième thread peut être exécuté sur le cœur du processeur. Cela nous permettra de comparer les performances.
// , DMA channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); uint16_t* src = dataForDma; uint16_t* dest = (uint16_t*)&GPIOB->ODR; for (int i=sizeof(dataForDma)/sizeof(dataForDma[0]);i>0;i--) { *dest = *src++; }
Tout d'abord, l'image générale, qui montre que tout fonctionne en parallèle et que le cœur du processeur a la vitesse de copie la plus élevée:
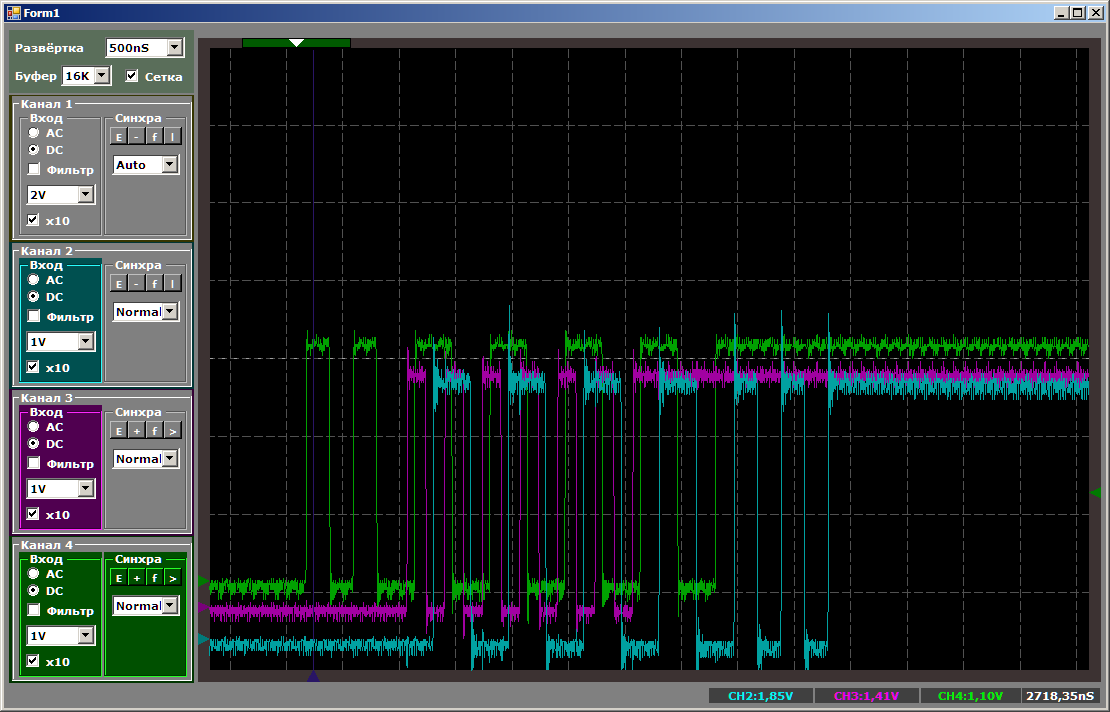
Et maintenant, je vais donner à chacun la possibilité de compter les mesures à un moment où tous les flux de copie sont actifs:
Le cœur du processeur priorise tous
Revenons maintenant au fait que pendant le fonctionnement à deux threads, alors que le deuxième canal était réglé, le premier donnait des données pour un nombre différent de cycles d'horloge. Ce fait est également bien documenté dans AppNote sur DMA. Le fait est que lors de la configuration du deuxième canal, des demandes à la RAM ont été périodiquement envoyées, et le cœur du processeur a une priorité plus élevée lors de l'accès à la RAM que le cœur DMA. Lorsque le processeur a demandé des données, le DMA a supprimé les cycles d'horloge, il a reçu les données avec un retard, par conséquent, il a copié plus lentement. Faisons la dernière expérience pour aujourd'hui. Apportons le travail à un plus réel. Après le démarrage de DMA, nous n'entrerons pas dans un cycle vide (lorsqu'il n'y a certainement pas d'accès à la RAM), mais effectuerons une opération de copie de la RAM vers la RAM, mais cette opération ne concernera pas le fonctionnement des cœurs DMA:
channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); uint32_t src1[0x200]; uint32_t dest1 [0x200]; while (1) { uint32_t* src = src1; uint32_t* dest = dest1; for (int i=sizeof(src1)/sizeof(src1[0]);i>0;i--) { *dest++ = *src++; } }

À certains endroits, le cycle s'étendait de 16 à 17 mesures. J'avais peur que ce soit pire.
Commencez à tirer des conclusions
En fait, nous nous tournons vers ce que je voulais dire.
Je pars de loin. Il y a quelques années, en commençant à étudier STM32, j'ai étudié les versions de MiddleWare pour USB qui existaient à l'époque et je me suis demandé pourquoi les développeurs avaient supprimé le transfert de données via DMA. Il était évident qu'au départ, une telle option était en vue, puis elle a été retirée dans les arrière-cours, et à la fin il n'y a eu que des rudiments. Maintenant, je commence à soupçonner que je comprends les développeurs.
Dans le
premier article sur UDB, j'ai dit que même si UDB peut fonctionner avec des données parallèles, il est peu probable qu'il puisse remplacer GPIF par lui-même, car le bus USB PSoC fonctionne à pleine vitesse par rapport à haute vitesse pour FX2LP. Il s'avère qu'il existe un facteur limitant plus sérieux. DMA n'a tout simplement pas le temps de fournir des données à la même vitesse que le GPIF, même au sein du contrôleur, sans tenir compte du bus USB.
Comme vous pouvez le voir, il n'y a pas de DMA d'entité unique. Tout d'abord, chaque fabricant fait sa propre voie. Non seulement cela, même un fabricant pour différentes familles peut varier l'approche de la construction de DMA. Si vous prévoyez de charger sérieusement cet appareil, vous devez soigneusement examiner si les besoins seront satisfaits.
Probablement, il est nécessaire de diluer le flux pessimiste avec une remarque optimiste. Je vais même la mettre en valeur.
Les contrôleurs DMA des Cortex M vous permettent d'augmenter les performances du système sur le principe des fameux Javelins: «Lancez et oubliez». Oui, la copie de données par logiciel est un peu plus rapide. Mais si vous avez besoin de copier plusieurs threads, aucun optimiseur ne peut faire en sorte que le processeur les pilote tous sans la surcharge des boucles de rechargement et de rotation des registres. De plus, pour les ports lents, le processeur doit toujours attendre la disponibilité, et DMA le fait au niveau matériel.Mais même ici, diverses nuances sont possibles. Si le port n'est que relativement lent ... Eh bien, disons, un SPI fonctionnant à la fréquence la plus élevée possible, alors il y a théoriquement des situations où le DMA n'a pas le temps de collecter des données à partir du tampon et un débordement se produit. Ou vice versa - mettez les données dans le registre tampon. Lorsque le flux de données est unique, il est peu probable que cela se produise, mais quand il y en a beaucoup, nous avons vu quelles superpositions étonnantes peuvent se produire. Pour y faire face, vous devez développer des tâches non pas séparément, mais en combinaison. Et les testeurs essaient de provoquer de tels problèmes (un travail si destructeur pour les testeurs).
Encore une fois, personne ne cache ces données. Mais pour une raison quelconque, tout cela n'est généralement pas contenu dans le document principal, mais dans les notes d'application. Ma tâche était donc d'attirer l'attention des programmeurs sur le fait que le DMA n'est pas une panacée, mais juste un outil pratique.
Mais, bien sûr, non seulement les programmeurs, mais aussi les développeurs de matériel. Disons que dans notre organisation, un grand complexe logiciel et matériel est en cours de développement pour le débogage à distance des systèmes embarqués. L'idée est que quelqu'un développe un appareil, mais veut commander le «firmware» sur le côté. Et pour une raison quelconque, ne peut pas fournir d'équipement sur le côté. Il peut être volumineux, il peut être coûteux, il peut être unique et «vous en avez besoin», différents groupes peuvent travailler avec lui dans différents fuseaux horaires, fournissant une sorte de travail à plusieurs équipes, il peut être constamment évoqué ... En général, vous pouvez trouver des raisons beaucoup, notre groupe a laissé cette tâche pour acquise.
En conséquence, le complexe de débogage devrait être capable de simuler autant de périphériques externes que possible, de la simulation triviale des pressions de boutons aux différents protocoles SPI, I2C, CAN, 4-20 mA et autres, pour que, grâce à eux, les émulateurs puissent recréer différents comportements des externes blocs connectés à l'équipement en cours de développement (j'ai personnellement fait à un moment donné beaucoup de simulateurs pour le débogage au sol des accessoires pour hélicoptères, sur notre
site Web les cas correspondants sont recherchés par le mot Cassel Aero ).
Et donc, dans les exigences techniques pour le développement de certaines exigences. Tant de SPI, tant d'I2C, tant de GPIO. Ils doivent fonctionner à telles et telles fréquences extrêmes. Tout semble clair. Nous avons mis STM32F4 et ULPI pour travailler avec USB en mode HS. La technologie est éprouvée. Mais voici un long week-end avec les vacances de novembre, que j'ai découvert avec UDB. Voir que quelque chose n'allait pas, le soir, j'ai obtenu les résultats pratiques qui sont donnés au début de cet article. Et j'ai réalisé que tout, bien sûr, était super, mais pas pour ce projet. Comme je l'ai déjà noté, lorsque les performances maximales possibles du système approchent de la limite supérieure, tout doit être conçu non pas séparément, mais dans un complexe.
Mais ici, la conception intégrée des tâches ne peut pas être en principe. , — . . , FTDI. -- , USB . Hélas. DMA. , , , , – , .
. DMA (, 10: 1 , , 1 , 10 ) .