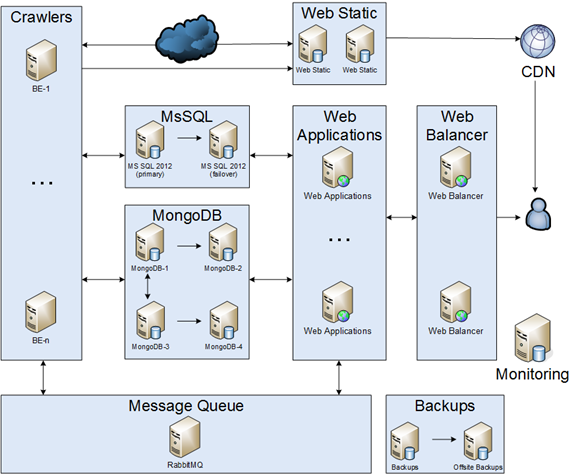
Je voudrais partager mon histoire sur l'application de migration de monolithes dans des microservices. S'il vous plaît, gardez à l'esprit que c'était entre 2012 et 2014. Il s'agit de la transcription de ma présentation à dotnetconf (RU) . Je vais partager une histoire sur la modification de chaque partie de l'infrastructure.
Description du projet

L'idée principale du projet était d'explorer des articles à partir d'Internet, de l'analyser, d'enregistrer et de créer un flux utilisateur. D'une part, notre infrastructure devait être fiable, mais d'autre part, nous étions sur un budget. En conséquence, nous avons convenu que:
- La dégradation des performances du système est autorisée.
- Certaines parties de notre infrastructure pourraient être en panne pendant 30 minutes.
- En cas de catastrophe, le temps d'arrêt peut être de quelques jours.
Rampeurs
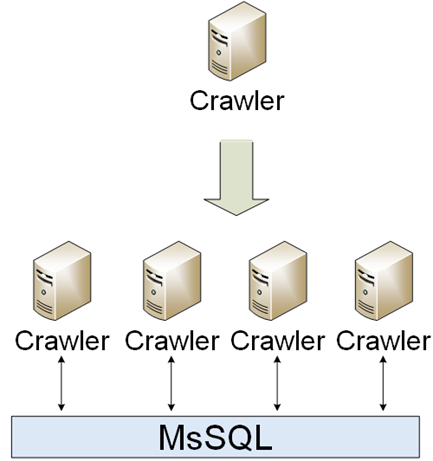
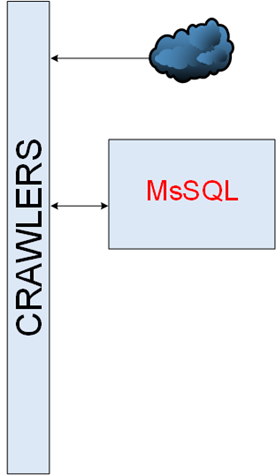
C'était une simple partie de l'infrastructure. Les robots doivent télécharger, analyser et enregistrer. La première implémentation était un seul robot, cependant, le monde changeait et beaucoup de robots différents sont apparus. Les crawlers communiquaient entre eux par MsSQL.
Les temps d'arrêt n'étaient pas un problème pour les robots, il était donc très facile de les faire évoluer:
- Automatisez la mise à disposition.
- Ajoutez des mesures commerciales.
- Collectez les erreurs.
Msql
Notre base de données était d'environ 1 To.
Cluster MsSQL
Il y avait différentes façons de créer un cluster:
- Mise en miroir SQL.
- Cluster de basculement Windows - ce n'était pas un cas car il n'y avait pas de san / Nas.
- AlwaysOn - c'était complètement nouveau pour nous et il n'y avait aucune expertise, donc ce n'était pas un cas pour nous.
En conséquence, nous avons décidé d'utiliser le 1er. Je voudrais noter que nous n'avons pas utilisé de témoin en raison du mode asynchrone, nous avons donc créé des scripts pour le commutateur automatique maître -> esclave et esclave manuel -> maître.
Performances MsSQL

L'horloge tournait, une performance se dégradait, nous recherchions des goulots d'étranglement. Parfois, ce n'était pas facile, c'est-à-dire que l'optimisation des requêtes SQL par disque io, lorsque, nous avons constaté que les performances étaient faibles en raison du manque de RAM. Mais ce n'était pas suffisant, en tant que solution temporaire, nous avons migré du HDD vers le SSD. D'une part, cela a considérablement augmenté les performances, mais d'autre part, ce n'était pas une solution à long terme.
File d'attente des messages
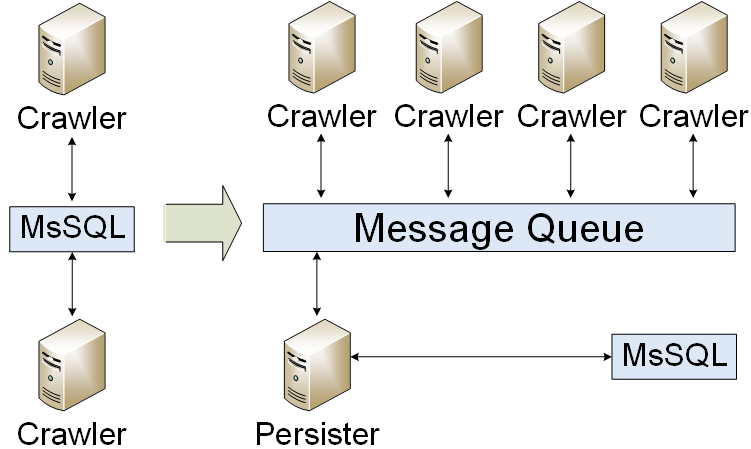
Notre application a été migrée vers une file d'attente de messages. Nous écrivions uniquement les résultats dans la base de données. En conséquence, nous avons réduit la charge de la base de données. Mais nous avons rencontré un problème: comment organiser un cluster de files d'attente de messages? Au début, nous avons créé un standby à froid.
WEB

Un composant WebPart se composait de deux parties: contenu statique et contenu dynamique utilisateur.
WEB statique

La partie statique WEB de l'infrastructure était d'environ 2 To, elle devait:
- Stockez des images.
- Convertissez des images.
- Explorer l'image d'origine et recadrer si nécessaire.

Il y avait 2 problèmes majeurs: comment synchroniser des fichiers et comment créer un cluster Web. Il y avait plusieurs façons de synchroniser des fichiers: acheter un stockage, utiliser DFS et enregistrer des fichiers sur chaque serveur. Ce fut une décision difficile, cependant, nous avons décidé de choisir la 3e voie. Pour le cluster Web, nous avons décidé d'utiliser NLB & CDN.
Équilibreur WEB

Ce n'est pas vraiment une bonne idée d'utiliser un seul serveur pour un projet à forte charge, vous devez équilibrer le trafic d'une manière ou d'une autre. Il y avait 4 façons dans notre cas:
- Équilibreur matériel - c'était trop cher pour nous.
- IIS & ARR - c'était trop compliqué à supporter.
- Nginx - c'était assez bon, cependant, nous avons rencontré des problèmes avec les bilans de santé.
- Haproxy - c'était une solution avec l'un des plus petits frais généraux.
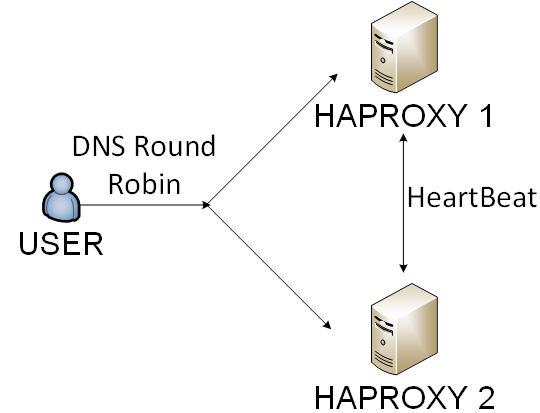
Nous avons choisi la 4ème voie. Nous équilibrions haproxy par round robin DNS et utilisateurs par cookie.
Mongodb

Quelques mois plus tard, nous avons dû constater que les performances SQL n'étaient plus suffisantes. C'était un problème sophistiqué, cependant, après de longues conversations, nous avons décidé de choisir la tolérance de disponibilité et de partition du théorème CAP . En conséquence, nous avons implémenté un cluster MongoDB (partitionnement et réplique). Il y a eu une expérience intéressante: comment créer une sauvegarde MongoDB, comment mettre à niveau et beaucoup de bogues MongoDB.
Sauvegardes et surveillance
Nous avons implémenté la règle 3-2-1:
- Au moins 3 exemplaires.
- Au moins 2 types de stockage différents.
- Au moins 1 copie doit être stockée quelque part à l'extérieur.
Nous avons également créé et testé un plan de reprise après sinistre. Vous pouvez lire sur la surveillance ici .
Mises à jour des applications
Comme vous pouvez le voir, l'infrastructure n'était pas aussi simple que possible. Nous avons dû le mettre à jour d'une manière ou d'une autre. La mise à jour occasionnelle ressemblait à:
- Faites un peu de préparation.
- Migration de Ran.
- Mettez à jour les applications Web.
- Mettre à jour les applications backend.
Toutes les étapes logiques étaient identiques pour les environnements de mise en scène / préprod / production, mais elles étaient légèrement différentes dans les détails. Nous avons donc créé des scripts PowerShell avec la magie OOP. C'était un processus continu d'amélioration de notre infrastructure CI / CD.
Conclusion
| 2012 | 2014 |
|---|
| Serveurs | 3 | 60 |
| RAM Go | 72 | 800 |
| SSD GB | 200 | 10 000 |
| MsSQL gb | 150 | 700 |
| MongoDB GB | 0 | 700 |
| Articles par jour | 10 000 | 150 000 |
C'était une histoire incroyable sur le transfert de 3 PC de bureau dans une infrastructure fiable. Soyez patient et faites des plans.
PS