Brève connaissance de kubernetes pour les développeurs par l'exemple du déploiement d'un site de modèle simple, de sa configuration pour la surveillance, l'exécution de travaux planifiés et de vérifications de l'état (tous les codes source sont joints)
-
Installer Kubernetes-
Installer l'interface utilisateur-
Lancez votre application dans le cluster-
Ajout de métriques personnalisées à l'application-
Collecte de métriques via Prometheus-
Afficher les métriques dans Grafana-
Tâches planifiées-
Tolérance aux pannes-
Conclusions-
Remarques-
RéférencesInstaller Kubernetes
ne convient pas aux utilisateurs de linux, vous devez utiliser minikube- Avez-vous un bureau docker
- Vous devez y trouver et activer le cluster à un seul nœud Kubernetes
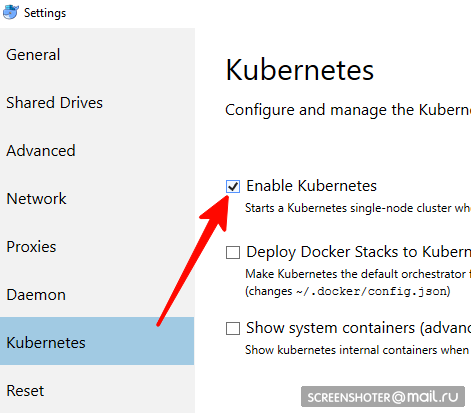
- Vous avez maintenant une API http: // localhost: 8001 / pour travailler avec kubernetis
- La communication avec lui se fait via un utilitaire pratique kubectl
Vérifiez sa version avec la commande> kubectl version
La dernière information pertinente est écrite ici https://storage.googleapis.com/kubernetes-release/release/stable.txt
Vous pouvez le télécharger sur le lien approprié https://storage.googleapis.com/kubernetes-release/release/v1.13.2/bin/windows/amd64/kubectl.exe kubectl cluster-info que le cluster fonctionne> kubectl cluster-info
Installation de l'interface utilisateur
- L'interface est déployée dans le même cluster
kubectl create -f https://raw.githubusercontent.com/kubernetes/dashboard/master/aio/deploy/recommended/kubernetes-dashboard.yaml
- Obtenez un jeton pour accéder à l'interface
kubectl describe secret
Et copier
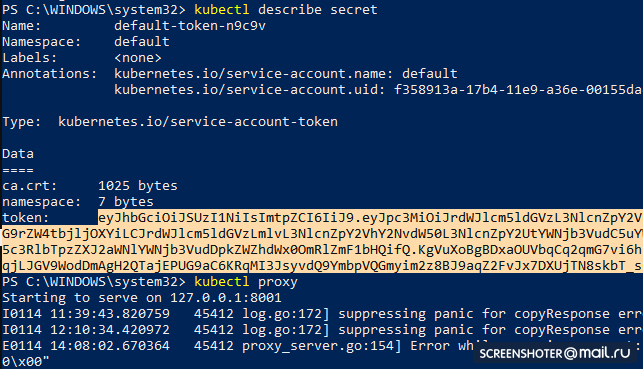
- Maintenant, lancez le proxy
kubectl proxy
- Et vous pouvez utiliser http: // localhost: 8001 / api / v1 / namespaces / kube-system / services / https: kubernetes-dashboard: / proxy /
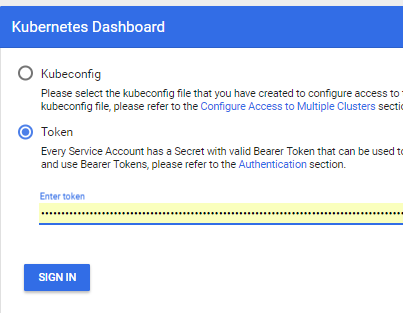
Exécution de votre application dans un cluster
- J'ai fait une application mvc netcoreapp2.1 standard via le studio https://github.com/SanSYS/kuberfirst
- Dockerfile:
FROM microsoft/dotnet:2.1-aspnetcore-runtime AS base WORKDIR /app EXPOSE 80 FROM microsoft/dotnet:2.1-sdk AS build WORKDIR /src COPY ./MetricsDemo.csproj . RUN ls RUN dotnet restore "MetricsDemo.csproj" COPY . . RUN dotnet build "MetricsDemo.csproj" -c Release -o /app FROM build AS publish RUN dotnet publish "MetricsDemo.csproj" -c Release -o /app FROM base AS final WORKDIR /app COPY --from=publish /app . ENTRYPOINT ["dotnet", "MetricsDemo.dll"]
- Rassemblé cette chose avec la balise metricsdemo3
docker build -t metricsdemo3 .
- Mais! Coober tire par défaut des images du hub, donc je lève le registre local
- note - n'a pas essayé de courir dans kubernetis
docker create -p 5000:5000 --restart always --name registry registry:2
- Et je le prescrit comme dangereux non autorisé:
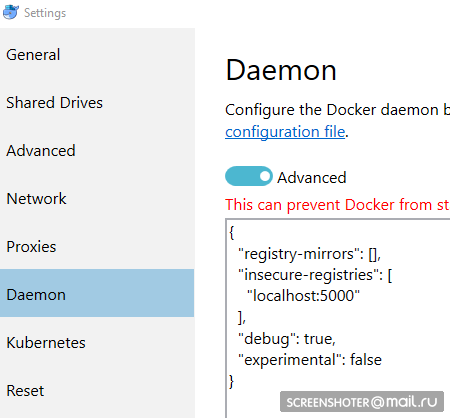
{ "registry-mirrors": [], "insecure-registries": [ "localhost:5000" ], "debug": true, "experimental": false }
- Avant de pousser dans le registre quelques gestes de plus
docker start registry docker tag metricsdemo3 localhost:5000/sansys/metricsdemo3 docker push localhost:5000/sansys/metricsdemo3
- Cela ressemblera à ceci:

Lancer via l'interface utilisateur
S'il démarre, alors tout va bien et vous pouvez commencer à fonctionner
Créer un fichier de déploiement
1-deployment-app.yaml kind: Deployment apiVersion: apps/v1 metadata: name: metricsdemo labels: app: web spec: replicas: 2
Petite description
- Kind - indique le type d'entité décrit dans le fichier yaml
- apiVersion - vers quelle api l'objet est transféré
- étiquettes - essentiellement des étiquettes (les touches à gauche et les valeurs peuvent être définies par vous-même)
- sélecteur - vous permet d'associer des services à un déploiement, par exemple via des étiquettes
Suivant:
kubectl create -f .\1-deployment-app.yaml
Et vous devriez voir votre déploiement dans l'interface
http: // localhost: 8001 / api / v1 / namespaces / kube-system / services / https: kubernetes-dashboard: / proxy / #! / Deployment? Namespace = defaultÀ l'intérieur duquel se trouve un jeu de réplicas, montrant que l'application s'exécute dans deux instances (pods) et qu'il existe un service associé avec une adresse extérieure pour ouvrir une application doublée dans le navigateur
Ajout de mesures personnalisées à l'application
Ajout du package
https://www.app-metrics.io/ à l' application
Je ne décrirai pas en détail comment je vais les ajouter, pour l'instant brièvement - j'enregistre le middleware pour incrémenter les compteurs d'appels aux méthodes api
Voici le middleware private static void AutoDiscoverRoutes(HttpContext context) { if (context.Request.Path.Value == "/favicon.ico") return; List<string> keys = new List<string>(); List<string> vals = new List<string>(); var routeData = context.GetRouteData(); if (routeData != null) { keys.AddRange(routeData.Values.Keys); vals.AddRange(routeData.Values.Values.Select(p => p.ToString())); } keys.Add("method"); vals.Add(context.Request.Method); keys.Add("response"); vals.Add(context.Response.StatusCode.ToString()); keys.Add("url"); vals.Add(context.Request.Path.Value); Program.Metrics.Measure.Counter.Increment(new CounterOptions { Name = "api",
Et les métriques collectées sont disponibles sur
http: // localhost: 9376 / metrics
* IMetricRoot ou son abstraction peut être facilement enregistré dans les services et utilisé dans l'application (
services.AddMetrics (Program.Metrics); )
Collection de métriques via Prometheus
Le paramètre prometheus le plus basique: ajoutez une nouvelle tâche à sa configuration (prometheus.yml) et alimentez-la une nouvelle cible:
global: scrape_interval: 15s evaluation_interval: 15s rule_files:
Mais prometheus a un support natif pour la collecte de mesures à partir de kubernetis
https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_configJe souhaite surveiller chaque service individuellement en filtrant par type d'application: étiquette commerciale
Une fois familiarisé avec le quai, le travail est le suivant:
- job_name: business-metrics
Dans kubernetis, il y a un endroit spécial pour stocker les fichiers de configuration -
ConfigMapJ'enregistre cette config là:
2-prometheus-configmap.yaml apiVersion: v1 kind: ConfigMap
Départ pour Kubernetis
kubectl create -f .\2-prometheus-configmap.yaml
Vous devez maintenant déployer prometheus avec ce fichier de configuration
kubectl create -f. \ 3-deployment-prometheus.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: prometheus namespace: default spec: replicas: 1 template: metadata: labels: app: prometheus-server spec: containers: - name: prometheus image: prom/prometheus args: - "--config.file=/etc/config/prometheus.yml" - "--web.enable-lifecycle" ports: - containerPort: 9090 volumeMounts: - name: prometheus-config-volume
Faites attention - le fichier prometheus.yml n'est spécifié nulle part
Tous les fichiers qui ont été spécifiés dans la config-map deviennent des fichiers dans la section prometheus-config-volume, qui est montée dans le répertoire / etc / config /
En outre, le conteneur a des arguments de démarrage avec le chemin d'accès à la configuration
--web.enable-lifecycle - dit que vous pouvez tirer POST / - / reload, qui appliquera de nouvelles configurations (utile si la configuration change "à la volée" et que vous ne voulez pas redémarrer le conteneur)
Déployer réellement
kubectl create -f .\3-deployment-prometheus.yaml
Suivez les petites étapes et allez à l'adresse
http: // localhost: 9090 / cibles , vous devriez y voir les points de terminaison de votre service
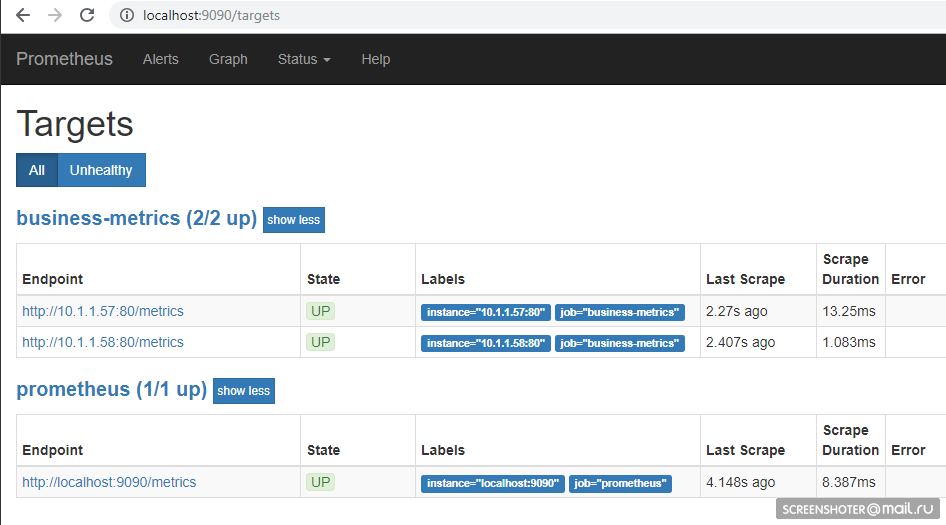
Et sur la page principale, vous pouvez écrire des demandes au prometheus
sum by (response, action, url, app) (delta(application_api[15s]))
À condition que quelqu'un visite le site, cela se passera comme suit Langage de requête -
https://prometheus.io/docs/prometheus/latest/querying/basics/Afficher les métriques dans Grafana
Nous avons eu de la chance - jusqu'à la version 5, les configurations de tableau de bord ne pouvaient être glissées que via l'API HTTP, mais maintenant vous pouvez faire la même astuce qu'avec Prometeus
Grafana par défaut au démarrage
peut extraire les configurations de source de données et les tableaux de bord
/etc/grafana/provisioning/datasources/ - configs source (paramètres d'accès à prometeus, postgres, zabbiks, élastique, etc.)/etc/grafana/provisioning/dashboards/ - paramètres d'accès au /etc/grafana/provisioning/dashboards//var/lib/grafana/dashboards/ - ici je vais stocker les tableaux de bord eux-mêmes sous forme de fichiers json
Il s'est avéré comme ça apiVersion: v1 kind: ConfigMap metadata: creationTimestamp: null name: grafana-provisioning-datasources namespace: default data: all.yml: | datasources: - name: 'Prometheus' type: 'prometheus' access: 'proxy' org_id: 1 url: 'http://prometheus:9090' is_default: true version: 1 editable: true --- apiVersion: v1 kind: ConfigMap metadata: creationTimestamp: null name: grafana-provisioning-dashboards namespace: default data: all.yml: | apiVersion: 1 providers: - name: 'default' orgId: 1 folder: '' type: file disableDeletion: false updateIntervalSeconds: 10
Le déploiement lui-même, rien de nouveau apiVersion: extensions/v1beta1 kind: Deployment metadata: name: grafana namespace: default labels: app: grafana component: core spec: replicas: 1 template: metadata: labels: app: grafana component: core spec: containers: - image: grafana/grafana name: grafana imagePullPolicy: IfNotPresent resources: limits: cpu: 100m memory: 100Mi requests: cpu: 100m memory: 100Mi env: - name: GF_AUTH_BASIC_ENABLED value: "true" - name: GF_AUTH_ANONYMOUS_ENABLED value: "true" - name: GF_AUTH_ANONYMOUS_ORG_ROLE value: Admin readinessProbe: httpGet: path: /login port: 3000
Développer
kubectl create -f .\4-grafana-configmap.yaml kubectl create -f .\5-deployment-grafana.yaml
N'oubliez pas que le graphan ne monte pas immédiatement, il est un peu amorti par les migrations sqlite, que vous pouvez
voir dans les logsAllez maintenant sur
http: // localhost: 3000 /Et cliquez sur le tableau de bord
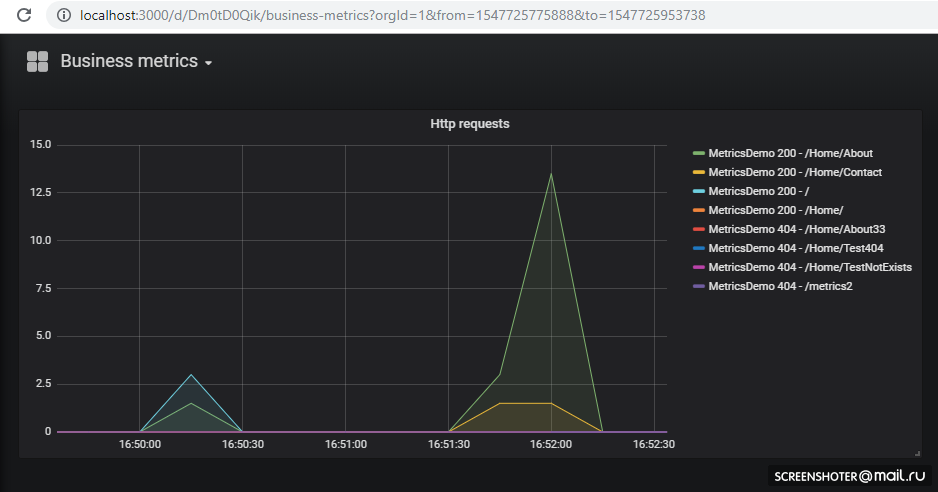
Si vous voulez ajouter une nouvelle vue ou changer une vue existante - changez-la directement dans l'interface, puis cliquez sur Enregistrer, vous obtiendrez une fenêtre modale avec json, que vous devez mettre dans la carte de configuration
Tout est déployé et fonctionne très bien Tâches planifiées
Pour effectuer des tâches sur la couronne dans le cuber il y a le concept de CronJob
Avec CronJob, vous pouvez définir un calendrier pour n'importe quelle tâche, l'exemple le plus simple:
La section horaire établit la règle classique pour la couronne
Le déclencheur démarre le pod du conteneur (busybox) dans lequel je tire la méthode api du service metricsdemo
Vous pouvez utiliser la commande pour suivre le travail.
kubectl.exe get cronjob runapijob --watch
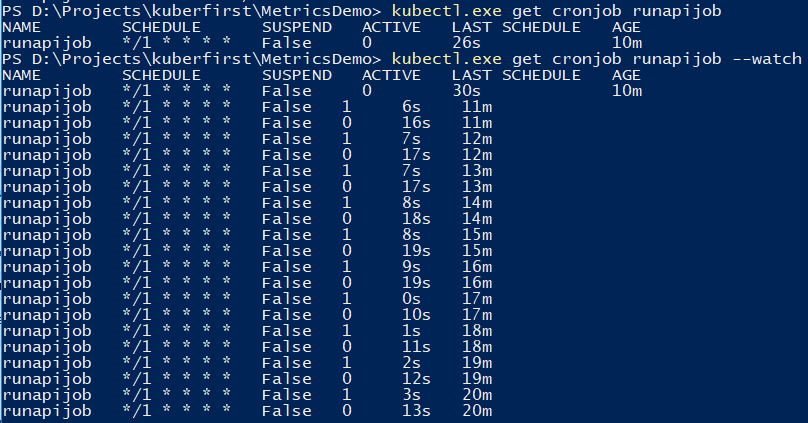
Le service principal qui se détache du travail est lancé dans plusieurs cas, car l'appel au service va à l'un des foyers avec une répartition approximativement uniforme
À quoi cela ressemble-t-il à Prométhée Afin de déboguer le travail, vous pouvez déclencher manuellement Une petite démo sur l'exemple de calcul du nombre de π, sur la différence de lancements depuis la console
Tolérance aux pannes
Si l'application se termine de façon inattendue, le cluster redémarre le pod
Par exemple, j'ai fait une méthode qui laisse tomber l'api
[HttpGet("kill/me")] public async void Kill() { throw new Exception("Selfkill"); }
* L'exception qui s'est produite dans l'API dans la méthode async void est considérée comme une exception non gérée, ce qui bloque complètement l'application.Je
lance un appel à
http: // localhost: 9376 / api / job / kill / meLa liste des foyers montre qu'un des foyers du service a été redémarré
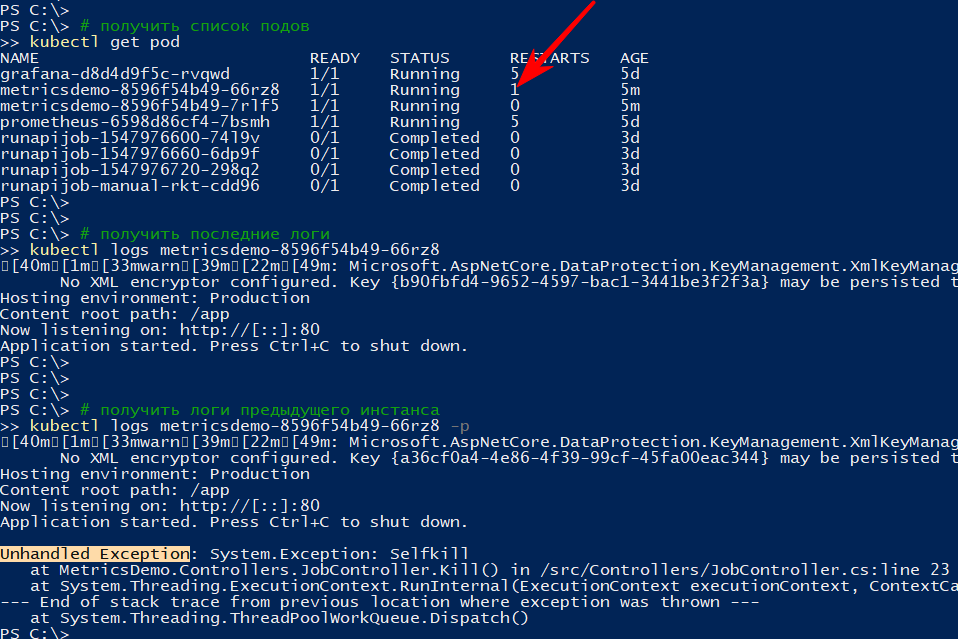
La commande logs affiche la sortie actuelle et, avec l'option -p, elle affiche les journaux de l'instance précédente. De cette façon, vous pouvez trouver la raison du redémarrage
Je pense qu'avec une simple chute, tout est clair: est tombé - rose
Mais l'application peut être conditionnelle, c'est-à-dire pas tombé, mais ne faisant rien ou faisant son travail, mais lentement
Selon la
documentation, il existe au moins deux types de contrôles de «survivabilité» des applications dans les pods
- état de préparation - ce type de vérification est utilisé pour comprendre s'il est possible de démarrer le trafic sur ce module. Sinon, le pod est dérégulé jusqu'à ce qu'il revienne à la normale.
- vivacité - vérifier l'application "pour la survie". En particulier, s'il n'y a pas d'accès à une ressource vitale ou si l'application ne répond pas du tout (par exemple, blocage et donc un timeout), le conteneur sera redémarré. Tous les codes http entre 200 et 400 sont considérés comme réussis, les autres échouent
Je vérifierai le redémarrage par timeout, pour cela j'ajouterai une nouvelle méthode api, qui selon une certaine commande commencera à ralentir la méthode de vérification de la survie pendant 123 sec
static bool deadlock; [HttpGet("alive/{cmd}")] public string Kill(string cmd) { if (cmd == "deadlock") { deadlock = true; return "Deadlocked"; } if (deadlock) Thread.Sleep(123 * 1000); return deadlock ? "Deadlocked!!!" : "Alive"; }
J'ajoute quelques sections au fichier 1-deployment-app.yaml dans le conteneur:
containers: - name: metricsdemo image: localhost:5000/sansys/metricsdemo3:6 ports: - containerPort: 80 readinessProbe:
Je suis sûr que l'application a démarré et que je suis abonné aux événements
kubectl get events --watch
J'appuie sur le menu Deadlock me (
http: // localhost: 9376 / api / job / alive / deadlock )

Et dans les cinq secondes, je commence à observer le problème et sa solution
1s Warning Unhealthy Pod Liveness probe failed: Get http://10.1.0.137:80/api/job/alive/check: net/http: request canceled (Client.Timeout exceeded while awaiting headers) 1s Warning Unhealthy Pod Liveness probe failed: Get http://10.1.0.137:80/api/job/alive/check: net/http: request canceled (Client.Timeout exceeded while awaiting headers) 0s Warning Unhealthy Pod Liveness probe failed: Get http://10.1.0.137:80/api/job/alive/check: net/http: request canceled (Client.Timeout exceeded while awaiting headers) 0s Warning Unhealthy Pod Readiness probe failed: Get http://10.1.0.137:80/health: dial tcp 10.1.0.137:80: connect: connection refused 0s Normal Killing Pod Killing container with id docker://metricsdemo:Container failed liveness probe.. Container will be killed and recreated. 0s Normal Pulled Pod Container image "localhost:5000/sansys/metricsdemo3:6" already present on machine 0s Normal Created Pod Created container 0s Normal Started Pod Started container
Conclusions
- D'une part, le seuil d'entrée s'est avéré être beaucoup plus bas que je ne le pensais, d'autre part, ce n'est pas du tout un véritable cluster kubernetes, mais seulement un ordinateur de développeur. Et les limites sur les ressources, les applications avec état, les tests A / B, etc. n'ont pas été prises en compte.
- Prometeus l'a essayé pour la première fois, mais la lecture de divers documents et exemples lors de l'examen du cuber a montré qu'il est très bon pour collecter des métriques du cluster et des applications
- Il est si bon qu'il permet au développeur d'implémenter une fonctionnalité sur son ordinateur et de joindre, en plus des informations au déploiement, le déploiement du planning au graphan. En conséquence, de nouvelles mesures automatiquement sans supplément. les efforts commenceront à être montrés sur scène et prod. Pratique
Remarques
- Les applications peuvent se contacter par le
: , ce qui a été fait avec grafana → prometeus. Pour ceux qui connaissent le docker-compose, il n'y a rien de nouveau kubectl create -f file.yml - crée une entitékubectl delete -f file.yml - supprime une entitékubectl get pod - obtenir une liste de tous les foyers (service, points de terminaison ...)--namespace=kube-system - filtrage par namespace-n kube-system - similaire
kubectl -it exec grafana-d8d4d9f5c-cvnkh -- /bin/bash - fixation en baskubectl delete service grafana - supprime un service, pod. déploiement (--all - supprimer tout)kubectl describe - décrit l'entité (vous pouvez tout faire en même temps)kubectl edit service metricsdemo - modifiez tous les yamls à la volée lors du lancement du bloc-noteskubectl --help - grande aide)- Un problème typique est qu'il y a un pod (considérez - une image en cours d'exécution), quelque chose s'est mal passé et il n'y a pas d'options, sauf qu'il n'y a aucun moyen de déboguer à l'intérieur (via tcpdump / nc etc.). - Yuzai kubectl-debug habr.com/en/company/flant/blog/436112
Les références
- Qu'est-ce que les métriques d'application?
- Kubernetes
- Prométhée
- Configuration de grafana pré-préparée
- Regarder comment les gens font (mais il y a déjà des choses dépassées) - là, en principe, il y a aussi la journalisation, les alertes, etc.
- Helm - Le gestionnaire de paquets pour Kubernetes - grâce à lui, il était plus facile d'organiser prometeus + grafana, mais manuellement - une meilleure compréhension apparaît
- Cubes pour Prométhée de Coober
- Histoires d'échecs de Kubernetes
- Kubernetes-HA. Déployer le cluster de basculement Kubernetes avec 5 assistants
 Code source et jams disponibles sur github
Code source et jams disponibles sur github