Dans True Engineering, sur un projet, le besoin est venu de changer la version de PostgreSQL de 9.6 à 11.1.
Pourquoi? La base de données sur le projet a déjà une taille de 1,5 To et se développe. La performance est l'une des principales exigences du système. Et la structure de données elle-même évolue: de nouvelles colonnes sont ajoutées, celles existantes sont modifiées. La nouvelle version de Postgres a appris à travailler efficacement avec l'ajout de nouvelles colonnes avec une valeur par défaut, il n'est donc pas nécessaire de clôturer les béquilles personnalisées au niveau de l'application. Même dans la nouvelle version, plusieurs nouveaux modes de partitionnement des tables ont été ajoutés, ce qui est également extrêmement utile dans des conditions de grande quantité de données.
Donc, c'est décidé, nous migrons. Bien sûr, vous pouvez créer une nouvelle version du serveur PostgreSQL en parallèle avec l'ancienne, arrêter l'application, utiliser dump / restore (ou pg_upgrade) pour déplacer la base de données et redémarrer l'application. Cette solution ne nous convenait pas en raison de la grande taille de la base, en plus, l'application fonctionne en mode combat, et il n'y a que quelques minutes pour les temps d'arrêt.
Par conséquent, nous avons décidé d'essayer la migration en utilisant la réplication logique dans PostgreSQL en utilisant un plugin tiers appelé
pglogical .
Dans le processus «d'essai», nous sommes tombés sur une documentation très fragmentaire sur ce processus (et en russe, ce n'est pas du tout), ainsi que sur certains pièges et nuances non évidentes. Dans cet article, nous voulons présenter notre expérience sous la forme d'un tutoriel.
 TL; DR
TL; DR- Tout s'est avéré (non sans béquilles, un article à leur sujet).
- Vous pouvez migrer dans la version PostgreSQL de 9.4 à 11.x, de n'importe quelle version vers n'importe quelle version, vers le bas ou vers le haut.
- Le temps d'arrêt est égal au temps nécessaire à votre application pour se reconnecter au nouveau serveur de base de données (dans notre cas, il s'agissait d'un redémarrage de l'application entière, mais dans la nature, évidemment, "options possibles").
Pourquoi la solution «front» ne nous convenait-elle pas
Comme nous l'avons déjà dit, la solution la plus simple consiste à augmenter la nouvelle version du serveur PostgreSQL en parallèle avec l'ancienne, à arrêter l'application, à utiliser dump / restore (ou pg_upgrade) pour déplacer la base de données et à redémarrer l'application. Pour les bases de données de petit volume, en principe, c'est une option tout à fait appropriée (ou, dans le cas général, le volume est sans importance lorsque vous avez la possibilité d'indisponibilité de l'application pour la période de "transfusion" de la base de données de l'ancien serveur au nouveau, quelle que soit la durée). Mais dans notre cas, la base de données prend environ 1,5 To sur le disque, et le déplacer n'est pas une question de minutes, mais de plusieurs heures. L'application, à son tour, fonctionne en mode combat, et je voulais vraiment éviter les temps d'arrêt pendant plus de quelques minutes.
Cette option était également contre le fait que nous utilisons la réplication maître-esclave et que nous ne pouvons pas désactiver le serveur esclave du flux de travail en toute sécurité. Ainsi, pour basculer l'application de l'ancienne version de PostgreSQL vers la nouvelle après la migration du serveur maître, il serait nécessaire de préparer un nouveau serveur esclave avant le démarrage de l'application. Et c'est encore quelques heures de temps d'arrêt jusqu'à ce que l'esclave soit créé (bien que beaucoup moins que la migration du maître).
Par conséquent, nous avons décidé d'essayer la migration en utilisant la réplication logique dans PostgreSQL en utilisant un plugin tiers appelé pglogical.
Informations générales
pglogical est un système de réplication logique utilisant le décodage logique natif dans PostgreSQL et implémenté en tant qu'extension PostgreSQL. Vous permet de configurer la réplication sélective à l'aide du modèle d'abonnement / publication. Il ne nécessite pas la création de déclencheurs dans la base de données ni l'utilisation d'aucun utilitaire externe pour la réplication.
L'extension fonctionne sur n'importe quelle version de PostgreSQL, à partir de 9.4 (depuis le décodage logique est apparue pour la première fois en 9.4), et vous permet de migrer entre toutes les versions prises en charge de PostgreSQL dans n'importe quelle direction.
Configurer manuellement la réplication à l'aide de pglogical n'est pas très simple, bien qu'en principe cela soit tout à fait possible. Heureusement, il existe un utilitaire tiers
pgrepup pour automatiser le processus de configuration, que nous utiliserons.
Mémo d'espace disque
Étant donné que nous prévoyons de mettre à jour la nouvelle version de PostgreSQL sur les mêmes serveurs en parallèle avec l'ancienne, les exigences de disque pour la base de données sur les serveurs maître et esclave sont doublées. Il semblerait que cela soit évident, mais ... Prenez juste suffisamment d'espace libre avant de commencer la réplication, afin de ne pas regretter les années passées sans but.
Dans notre cas, des modifications de la base de données étaient nécessaires, ainsi que le format de stockage lors de la migration entre 9,6 et 11 «houles» en faveur de la dernière version, donc l'espace disque devait être augmenté non pas de 2, mais d'environ 2,2 fois. Louez LVM, cela peut être fait dans le processus de migration à la volée.
En général, prenez-en soin.
Installer PostgreSQL 11 sur Master
Remarque: Nous utilisons Oracle Linux et tous les éléments suivants seront affinés pour cette distribution. Il est possible que d'autres distributions Linux nécessitent une petite révision avec un fichier, mais il est peu probable qu'elles soient significatives.
L'ancien datadir est situé dans
/var/lib/pgsql/9.6/data , le nouveau, en conséquence, se trouve dans
/ var / lib / pgsql / 11 / dataCopiez les paramètres d'accès (
pg_hba.conf ) et les paramètres du serveur (
postgresql.conf ) de 9,6 à 11.
Pour exécuter deux serveurs PostgreSQL sur la même machine, dans la configuration de configuration
postgresql.conf 11, changez le port en 15432 (port = 15432).
Ici, vous devez réfléchir soigneusement à ce que vous devez faire d'autre dans la nouvelle version de PostgreSQL spécifiquement dans votre cas, afin qu'il commence par votre
postgresql.conf (et que votre application puisse éventuellement fonctionner avec). Dans notre cas, il était nécessaire d'installer les extensions PostgreSQL utilisées par nous dans la nouvelle version. Cela dépasse le cadre de l'article, faites simplement démarrer le nouveau PostgreSQL, travaillez-le et faites-le vous convenir complètement :)
Nous regardons dans
/ var / lib / pgsql / 11 / data / pg_log / . Tout va bien? Nous continuons!
Installer et configurer pgrepup

Nuances:
- En tant que propriétaire de l'application, nous spécifions l'utilisateur sous lequel les serveurs PostgreSQL s'exécutent.
- Pour Base de données, spécifiez template1 .
- Nom d'utilisateur et mot de passe - données pour l'accès superutilisateur. Dans notre cas, la méthode de confiance a été spécifiée dans pg_hba.conf pour les connexions locales de l'utilisateur postgres , vous pouvez donc spécifier un mot de passe arbitraire.
Configurer la réplication
Nous obtenons la sortie d'une liste de nombreux paramètres qui doivent être configurés selon les besoins.
Exemples de résultats de vérification:
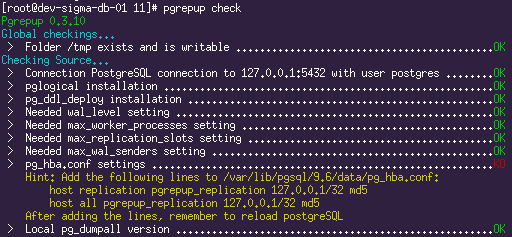

Toutes les erreurs lors de la vérification devront être éliminées. Dans les paramètres des deux serveurs, définissez
wal_level = LOGICAL (pour que le décodage logique fonctionne), les paramètres nécessaires pour le moteur de réplication (nombre d'emplacements et
wal_senders ). Les conseils de l'utilitaire pgrepup sont assez informatifs; les questions ne devraient pas se poser sur la plupart des points.
Nous faisons tous les réglages nécessaires que pgrepup demande.
Dans les deux fichiers
pg_hba.conf , nous ajoutons des autorisations pour l'utilisateur qui effectuera la réplication, le tout à l'invite pgrepup:
host replication pgrepup_replication 127.0.0.1/32 md5 host all pgrepup_replication 127.0.0.1/32 md5
Ajouter des clés primaires
Pour que la réplication fonctionne, une clé primaire doit être définie dans toutes les tables.
Dans notre cas, PK n'était pas partout, par conséquent, au moment de la réplication, vous devez l'ajouter et, à la fin de la réplication, si nécessaire, le supprimer.
Une liste de tables sans PK, entre autres, produit
pgrepup check . Pour toutes les tables de cette liste, vous devez ajouter une clé primaire de la manière qui vous convient. Dans notre cas, c'était quelque chose comme:
ALTER TABLE %s ADD COLUMN temporary_pk BIGSERIAL NOT NULL PRIMARY KEY
L'utilitaire pgrepup possède une commande intégrée pour effectuer cette opération (
pgrepup fix ), et même s'il est utilisé, il est entendu que si la réplication
pgrepup fix , ces colonnes temporaires seront automatiquement supprimées. Mais, malheureusement, cette fonctionnalité était tellement illusoire et incroyablement buggée sur de grandes bases que nous avons décidé de ne pas l'utiliser, mais de faire cette opération manuellement, car cela nous convient.
Installer l'extension pglogical
Les instructions d'installation de l'extension sont disponibles
ici . L'extension doit être installée sur les deux serveurs.
Ajoutez la charge de bibliothèque dans
postgresql.conf des deux serveurs:
shared_preload_libraries = 'pglogical'
Installer l'extension pgl_ddl_deploy
Il s'agit d'une extension d'assistance que pgrepup utilise pour la réplication DDL logique.
Ajoutez la charge de bibliothèque dans
postgresql.conf des deux serveurs:
shared_preload_libraries = 'pglogical,pgl_ddl_deploy'
Vérification des modifications
Maintenant, en utilisant
pgrepup check vous devez vous assurer que tout va bien avec le serveur cible et que tous les commentaires concernant le serveur cible ont été complètement éliminés.
Si tout va bien, vous pouvez redémarrer l'ancien serveur. Ici, vous devez réfléchir à la façon dont votre application réagira au redémarrage du serveur de base de données, vous devriez peut-être l'arrêter en premier.
Maintenant, dans la sortie de la commande, tous les éléments doivent être marqués comme OK.
Il semblerait que vous puissiez commencer la migration, mais ...
Correction des bugs de pgrepup
Il existe plusieurs bogues dans la version actuelle de pgrepup qui rendent la migration impossible. Des demandes d'extraction ont été envoyées, mais hélas, elles sont ignorées, vous devrez donc apporter des corrections manuellement.
Nous allons dans le dossier d'installation de pgrepup (notre cas est
/usr/lib/python2.7/site-packages/pgrepup/commands/ ).
Faites-le une fois. Dans chaque fichier
* .py , ajoutez les
**kwargs manquants dans la description de la fonction. Une image vaut mieux que mille mots:
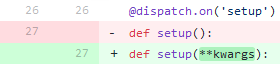
Engagez-vous
ici .
Faites deux. Dans
setup.py, nous recherchons «sh -c», deux entrées, toutes les commandes shell multi-lignes doivent être effectuées sur une seule ligne.
Engagez-vous
ici .
Lancer la migration
Avec cette commande, pgrepup prépare les deux serveurs à démarrer la réplication, crée un utilisateur, configure pglogical, transfère le schéma de la base de données.
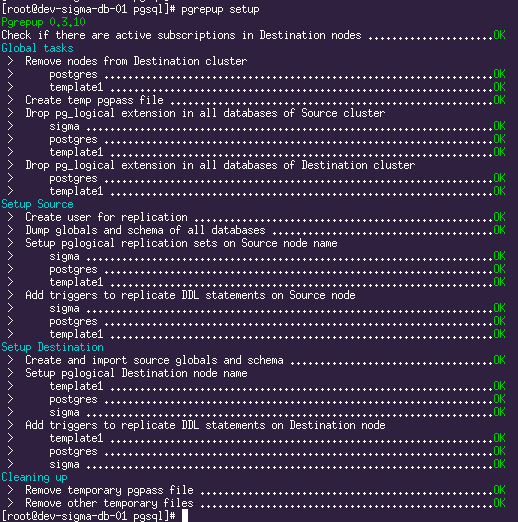
Il a dit: "Allons-y!" et agita la main:

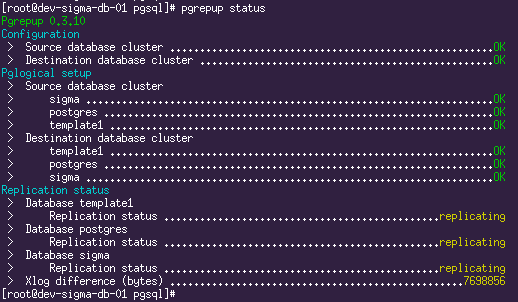
La réplication est en cours d'exécution. La situation actuelle peut être vue en utilisant la commande
pgrepup status :
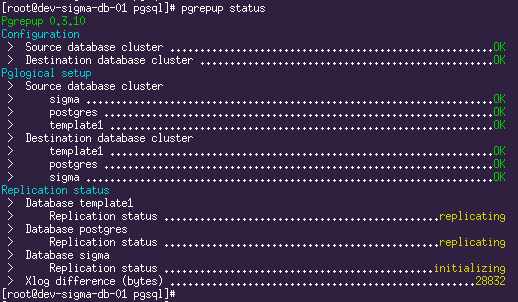
Ici, nous voyons que deux bases de données ont déjà été déplacées et que la réplication est en cours et qu'une est toujours en cours de déplacement. Maintenant, il ne reste plus qu'à boire du café et attendre que tout le volume de la base de données d'origine soit pompé.
En chemin, vous pouvez regarder plus profondément dans la façade de pgrepup et voir ce qui se passe sous le capot. Pour les esprits curieux, voici une liste de requêtes comme point de départ:
SELECT * FROM pg_replication_origin_status ORDER BY remote_lsn DESC; SELECT *,pg_xlog_location_diff(s.sent_location,s.replay_location) byte_lag FROM pg_stat_replication s; SELECT query FROM pg_stat_activity WHERE application_name='subscription_copy'
Avoir beaucoup de café (sur le serveur de test lors de la rédaction de cet article, la migration de ~ 700 Go de données a duré environ une journée), nous voyons enfin l'image suivante:
Et cela signifie qu'il est temps de préparer un nouvel esclave.
Installer PostgreSQL 11 sur Slave
Ici tout est simple et selon le manuel, pas de nuances.
Copiez les paramètres d'accès (
pg_hba.conf ) et les paramètres du serveur (
postgresql.conf ) de 9,6 à 11. Dans la configuration de la version
postgresql.conf 11, changez le port en 15432 (port = 15432)
# Master SELECT *,pg_wal_lsn_diff(s.sent_lsn,s.replay_lsn) AS byte_lag FROM pg_stat_replication s; # Slave SELECT now()-pg_last_xact_replay_timestamp();
Sous-totaux
Après toutes ces procédures, nous obtenons ce schéma de réplication délicat:

Ici, comme dernière vérification (et, au final, c'est tout simplement magnifique), vous pouvez effectuer une MISE À JOUR dans la base de données 9.6 Master et voir comment elle est répliquée sur les trois autres serveurs.

Passer de l'application à la nouvelle version de PostgreSQL
Jusqu'à présent, notre application n'a rien suspecté de la nouvelle version de PostgreSQL, il est temps de la corriger. Les options ici dépendent fondamentalement de seulement deux choses:
Allez-vous l'emporter sur les nouveaux services sur les mêmes ports sur lesquels les anciens fonctionnaient,
et si votre application nécessite un redémarrage lors du redémarrage du serveur de base de données.
Pour le plaisir, nous répondrons «oui» aux deux questions et continuerons.
Nous arrêtons l'application.
# , , : SELECT * FROM pg_stat_activity;

Nous renvoyons le port standard dans la configuration
postgresql.conf de la nouvelle version à Master et Slave.
Sur le nouvel esclave, nous changeons également le port en celui standard dans
recovery.conf .
En cours de route, il y a une suggestion de sin pour changer davantage le port sur l'ancienne version qui devient inactive:
Nous exposons le port non standard dans
postgresql.conf de l' ancienne version à Master et Slave.
Sur l'ancien esclave, nous changeons également le port en un port non standard dans
recovery.conf .
Vérifiez les journaux.
Vérifiez l'état de la réplication sur le maître.
SELECT *,pg_wal_lsn_diff(s.sent_lsn,s.replay_lsn) AS byte_lag FROM pg_stat_replication s;
Nous lançons l'application. Nous sommes heureux pendant une demi-heure.
Et enfin, une littérature utile sur le sujet:Bonne chance!