En 2016, en raison du rêve de longue date des jeux vidéo et du «battage médiatique» autour de l'IA, j'ai commencé à apprendre le Python.
L'informatique est amusante car il y a seulement une semaine, j'ai formé le premier modèle de reconnaissance, mais sans utiliser Python (il y a beaucoup de tentations en informatique). Comme l'avait prédit Andrei Sebrant (Yandex), une nouvelle révolution technologique s'est produite. Pourquoi? Rendre une application de reconnaissance d'image plus facile qu'un jeu d'ordinateur. Assez pour une heure ou deux.

J'ai choisi la voie "difficile" - je n'ai pas choisi parmi quatre modèles déjà entraînés, mais j'ai formé le mien. La bibliothèque Core ML d'Apple vous permet de le faire avec 6 lignes de code ou via l'interface graphique dans les aires de jeux.
import CreateMLUI let builder = MLImageClassifierBuilder() builder.showInLiveView()
La plupart du temps a été consacré à la collecte et au filtrage des données pour la formation, 70 photos de chiens, de chats et de personnes, mais un script rapidement écrit a rendu ce processus semi-automatique.
J'avais l'habitude de lire sur l'apprentissage automatique. Lorsque je l'ai essayé moi-même, j'ai rencontré trois problèmes / conclusions attendus:
- Les données sont la partie la plus importante.
- Interface conviviale (CoreML). Tout fonctionne et je ne veux pas vraiment entrer dans le code source pour comprendre les détails. L'apprentissage automatique est accessible à tout utilisateur, mais les ingénieurs d'Apple ont tenté de masquer des détails complexes.
- Le modèle est une boîte noire. Je ne connais pas les règles selon lesquelles le modèle croit que deux pour cent du «chat» sur la photo.
L'expérience de la reconnaissance des «chats humains» a conduit à l'idée que l'algorithme de classification s'adaptera au «style».
J'ai sélectionné quatre photographes et une centaine de photographies chacun. Je n'ai pas essayé de choisir soigneusement des exemples, mais j'ai simplement copié de ma collection la première ou la centaine d'images d'
Evgeny Mokhorev et d'
Oleg Videnin . Il n'y avait pas assez de photographies de
Maxim Shumilin , car non seulement les portraits étaient sélectionnés. Mais les photos de
Yegor Voinov ont été choisies avec plus de soin, puisque j'ai téléchargé deux sections consacrées au portrait sur son site Internet.
J'ai commencé à former l'algorithme et, en moyenne, j'ai obtenu une précision de reconnaissance de 80% (résultats des tests lors de la création).
Il y a eu un moment étrange. J'ai doublé le nombre de photos d'Oleg Videnin et le système n'a appris que 30%, et la précision de reconnaissance a diminué à 20%.
Le système a dû être vérifié afin d'éviter en quelque sorte les biais, j'ai demandé à Yegor Voinov d'envoyer des photos qui ne sont pas sur le site. En conséquence, l'algorithme a confirmé que 20 photos sur 26 sont similaires à la façon dont Yegor Voinov prend un portrait.
Cela a confirmé la précision de reconnaissance de 77% obtenue lors de la création du classificateur.

Et puis le plaisir commence.
Tout d'abord, le système peut être formé en ajoutant à nouveau des «erreurs» à l'ensemble de formation. Les résultats changent, mais le système ne se souvient pas des photographies, mais trouve des signes communs pour un auteur particulier. Certaines photos après avoir "travaillé sur des erreurs" ont été reconnues par le système comme des photos de Yegor Voinov, et d'autres non.
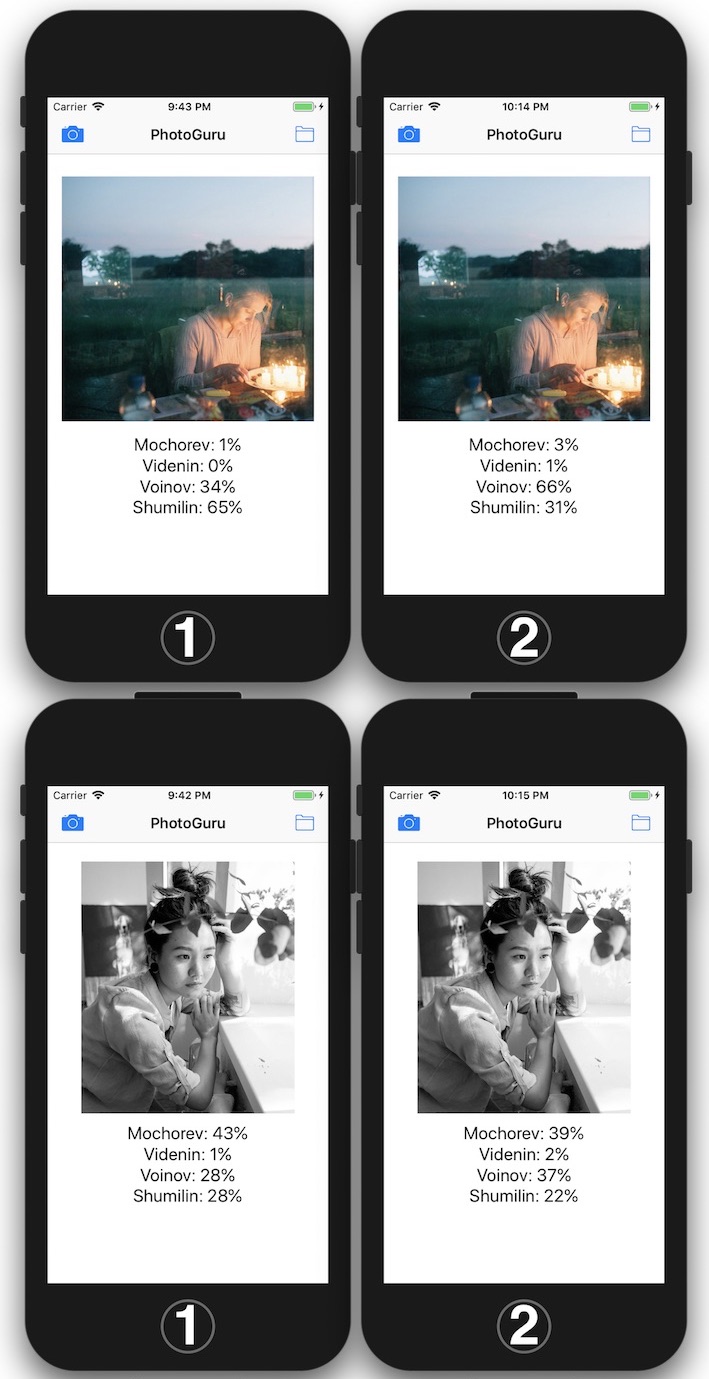
Deuxièmement, le système est enclin à attribuer le «nu» aux photographies d'Evgeny Mokhorev, c'est pourquoi il écrit sous le rare «nu» d'Oleg Videnin qu'il s'agit de photographies de Mokhorev. Et dès que vous montrez le «Mokhorev habillé», le système peut «voir Voinov». Et reconnaissez la photo de Yegor Voynov comme une photo d'Oleg Videnin.

La sélection parmi les photographies de Maxim Shumilin s'est avérée très hétérogène. Par conséquent, de petites figures et portraits avec un "flou" prononcé, le système fait référence aux photographies de Maxim.

Troisièmement, le système peut être vu par la photo de Maître Yoda.
Et vous pouvez simplement prendre une photo rapide et découvrir dans quel "style" la photo a été prise
Et voici le moment de vérité. J'ai téléchargé mes portraits pour savoir combien Mokhorev, Videnin, Voinov et Shumilin sont en moi.

Le projet d'application
PhotoGuru est prêt. Jusqu'à présent, il me semble que c'est un jouet amusant, mais je vais travailler sur la conception et développer les échantillons d'entraînement.
En un mot, vous devez choisir un cadre pour une étude plus approfondie du ML.