
Je m'appelle Elena Rastorgueva, je suis responsable du produit Factor chez
HFLabs . The Factor est une entreprise algorithmique extrêmement complexe qui traite des données à l'échelle industrielle.
Dans l'article, je vais vous expliquer comment nous avons commencé à tester le «Factor», comment les autotests ont été développés et pourquoi nous sommes arrivés aux frameworks auto-écrits.
De quel type de produit s'agit-il - «Facteur»
"Factor" nettoie les données dans des bases de données avec des millions de clients: supprime les fautes de frappe dans le nom, le téléphone et l'e-mail, vérifie les passeports, fait beaucoup plus. Le plus difficile est de corriger les adresses postales.
 Les adresses sont écrites de centaines de façons, donc le Facteur a un puissant appareil algorithmique sous le capot
Les adresses sont écrites de centaines de façons, donc le Facteur a un puissant appareil algorithmique sous le capot"Factor" fonctionne comme un service: données d'entrée - données de sortie.
Il s'agit d'un système sans état où chaque appel est indépendant des précédents. L'apatridie simplifie considérablement la vie du testeur. Il est beaucoup plus difficile de tester un système avec état lorsqu'une séquence d'actions est importante.
Le produit doit être fiable comme l'ISS, car il est utilisé par les banques, les opérateurs mobiles, les assurances et les détaillants de niveau Lenta. Nous répondons des erreurs de notre tête dans la mesure où l'absence d'erreurs fait partie du SLA dans le contrat avec le client.
En raison des exigences de fiabilité des autotests, nous avons écrit dès le début du développement. L'un des critères de préparation de la tâche est «Ajout d'autotests».
Commencé par des vérifications manuelles et des autotests
Nous avons lancé le Factor en 2005 et l'avons d'abord testé avec nos mains. Le matin, le testeur a effectué des autotests sur un fichier contenant des cas et a comparé le résultat du traitement des données avec le résultat de la veille: ce qui a changé après la validation du code d'hier.
Le processus pouvait prendre une demi-journée, cet alignement n'était pas bon. Par conséquent, nous avons pris l'ensemble minimal de tests pour la fonctionnalité clé et enveloppé dans des tests unitaires. Ces tests sont rapides et le développeur lui-même les a exécutés avant de s'engager.
Les tests unitaires sont si pratiques et si rapides que nous en avons ajouté des milliers. Et puis nous sommes tombés dessus: lorsque les tests ressemblent à une feuille de milliers de morceaux de code, il n'est même pas facile de faire défiler jusqu'au bon endroit. Sans parler de l'ajout ou de la mise à jour.
 Test unitaire pour vérifier le format SNILS
Test unitaire pour vérifier le format SNILSDe plus, quelque chose d'inattendu apparaît soudain dans les données industrielles qui ne couvre pas les tests unitaires. Par exemple, un nouveau client est venu avec de nouvelles fonctionnalités dans les adresses, les tests unitaires ne couvrent pas ces fonctionnalités. Vous devez vous asseoir et voir quels tests ajouter pour de nouvelles données. Nous l'avons toujours fait manuellement.
Créez votre propre framework
Dans les tests unitaires traditionnels, les données et le code sont mélangés; il est difficile de trouver les bonnes pièces.
Par conséquent, nous avons essayé les autotests dans le paradigme
DDT (Data Driven Testing) . DDT est lorsque les données de test sont stockées séparément du code de test.
Les cas ont été chargés à partir d'un fichier Excel, ils se trouvaient dans les colonnes «Données brutes» et «Résultat attendu». Le DDT a été une percée: la mise à jour des cas dans "l'exelnik" est inexplicablement plus simple.
Petit à petit, nous avons développé une approche et développé notre propre framework de test. Il reçoit des fichiers texte en entrée, à l'intérieur d'eux se trouvent les données source et le résultat attendu.
 Nous avons refusé les fichiers Excel comme stockage: les fichiers texte s'ouvrent plus rapidement, ne modifient pas le contenu, il est plus facile de collecter des données à partir d'eux
Nous avons refusé les fichiers Excel comme stockage: les fichiers texte s'ouvrent plus rapidement, ne modifient pas le contenu, il est plus facile de collecter des données à partir d'euxLe cadre est aidé par des outils standard:
- TeamCity exécute automatiquement des tests tous les soirs;
- testNG compare les résultats attendus et réels.
 Si le résultat est différent de celui attendu, dans TeamCity le test rougit. Si tout est comme il se doit, le test est vert
Si le résultat est différent de celui attendu, dans TeamCity le test rougit. Si tout est comme il se doit, le test est vertVous avez modifié le cadre pour vous-même
12 ans se sont écoulés depuis. Pendant ce temps, le cadre a envahi des capacités qui ne sont pas dans les solutions standard.
Comptabilisation de l'état des tâches dans Jira. HFLabs adhère au
développement piloté par les tests : nous écrivons d'abord un test ou ajoutons des cas de test pour de nouveaux comportements, puis nous modifions ensuite les fonctionnalités.
Nous avons désactivé de nouveaux cas en commentant la ligne. Sinon, ils sont d'abord tombés et sont intervenus, car les cas ont ajouté des fonctionnalités ou des corrections de bugs auparavant.
Mais la tâche peut ne pas être en mesure de terminer le cas de test correspondant: le bogue se révélera extrêmement rare ou le client apportera quelque chose de plus important. Certaines tâches ont été suspendues pendant des mois avec une faible priorité et des cas déconnectés se sont accumulés. Dans le même temps, il n'est pas clair à quelle tâche appartient chaque cas, si ce cas peut être supprimé.
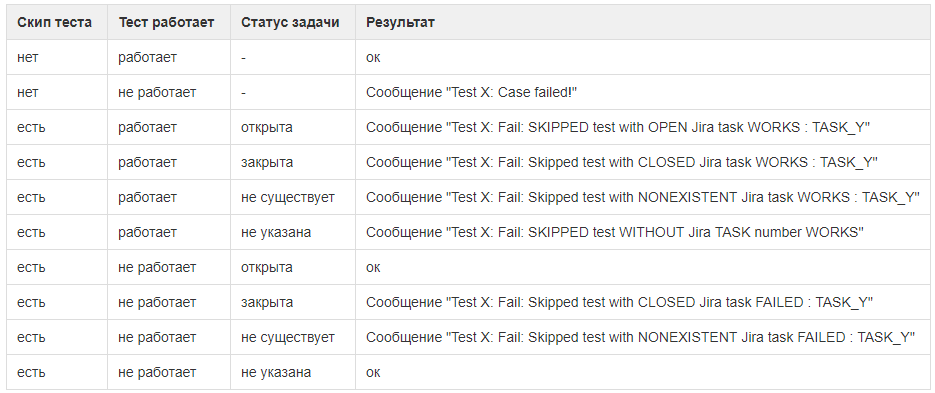
Par conséquent, nous avons ajouté un numéro de tâche aux cas déconnectés et gâché un peu d'automatisation. Maintenant, tout fonctionne comme ceci:
- le scénario de test est désactivé en le faisant correspondre à une tâche ouverte dans Jira;

Pour joindre un cas à une tâche, écrivez devant celui-ci # et le numéro de tâche
- le framework exécute des tests même sur les cas désactivés. Mais ignore les plantages lorsque la tâche est ouverte dans Jira;
- dès que la tâche est close, le test commence à tomber sur les cas qui lui sont attachés. C'est un signal: ils ont réussi la tâche, mais ont oublié d'activer les boîtiers;
- si tout à coup le test du cas déconnecté a commencé à passer avec une tâche ouverte, le framework en informera également. Il est peut-être temps d'activer le boîtier ou de fermer la tâche qui lui est associée (ainsi que de mettre à jour les notes de publication et d'informer les clients).

Le cadre dit que l'affaire déconnectée est en cours. Peut-être que quelqu'un a corrigé le code dans le cadre d'une autre tâche, et maintenant tout fonctionne
Nous avons donc sauvé TDD et vaincu l'oubli lors de la gestion des cas de test.
 Nous avons documenté toutes les options avec l'état des cas de test et des tâches associées, afin de ne pas oublierMise à jour des cas de test en mode semi-automatique.
Nous avons documenté toutes les options avec l'état des cas de test et des tâches associées, afin de ne pas oublierMise à jour des cas de test en mode semi-automatique. Il semblerait que si le test se bloque, recherchez une erreur dans le code. Mais pour nous, ce n'est pas toujours le cas. Il arrive parfois que les cas de test doivent être mis à jour, car les exigences pour le résultat ont changé.
Par exemple, avant que le client de l'adresse effacée ne souhaite "g. Moscou »dans un domaine. Maintenant qu'il a changé l'architecture de la base de données, il veut la "ville" dans un domaine, "Moscou" dans un autre. Il est temps de changer les cas de test.
Pour le test tombé, TeamCity montre la différence entre les résultats attendus et réels. Auparavant, nous avons copié cette différence et mis à jour les cas de test avec nos mains. Pour des changements massifs - un événement très coûteux.
 Un exemple vivant: nous avons appris «Factor» pour déterminer un pays par numéro de téléphone, les tests dans TeamCity sont tombés. Un nouveau repère peut être tiré du résultat réel, mais cela prend beaucoup de temps
Un exemple vivant: nous avons appris «Factor» pour déterminer un pays par numéro de téléphone, les tests dans TeamCity sont tombés. Un nouveau repère peut être tiré du résultat réel, mais cela prend beaucoup de tempsNous avons fait la mise à jour du cadre de référence lui-même. Pour ce faire, après avoir exécuté les tests, il remplace les résultats de nettoyage attendus dans la norme par ceux réels où ils ne correspondaient pas. Le résultat est enregistré dans des artefacts en tant que fichier de mise à jour de cas.
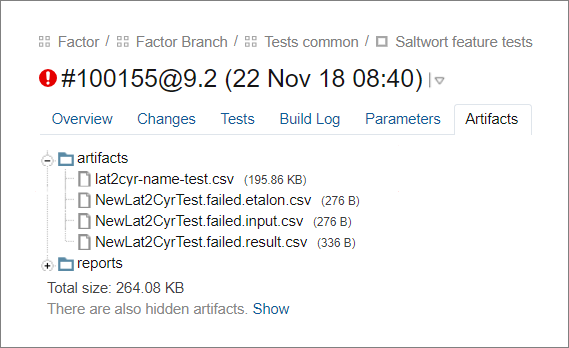 Le premier fichier est une nouvelle référence dans laquelle le cadre a mis à jour les résultats attendus. Les fichiers restants sont les données d'entrée, l'ancienne norme et les données réelles pour les cas abandonnés.
Le premier fichier est une nouvelle référence dans laquelle le cadre a mis à jour les résultats attendus. Les fichiers restants sont les données d'entrée, l'ancienne norme et les données réelles pour les cas abandonnés.Avec la nouvelle référence, le testeur met à jour les cas en trois étapes.
- Téléchargez le fichier généré.
- Vérifie à travers n'importe quel outil de fusion quels changements sont dans le nouveau benchmark. Ne laisse que le nécessaire.
- Valider
 Le testeur vérifie si les mises à jour de la nouvelle norme sont correctes et les valide
Le testeur vérifie si les mises à jour de la nouvelle norme sont correctes et les valideOui, s'il est mis à jour irréfléchi, rien de bon n'en sortira. Mais il existe un risque de mise à jour irréfléchie lorsque vous travaillez manuellement.
Stabilisation des données de test avec des talons. "Factor" renvoie les données traitées dans des dizaines de champs. Il y a un tas de composants dans une seule adresse: index, région, type de région, type de ville, ville, type de rue, maison, bâtiment, bâtiment, appartement. Pour eux, le «Facteur» attrape IFTS, OKATO, OKTMO et même les petites choses. Donc, à partir d'une ligne à l'entrée, des dizaines de valeurs sont obtenues.
Tous les champs du résultat ne doivent pas être vérifiés avec des cas de test. Par exemple, la reconnaissance de la même adresse dépend directement du répertoire d'état - FIAS. Et en elle, les domaines changent régulièrement, pour nos tâches ils sont complètement étrangers. La mise à jour de certains codes CLADR pour les maisons a supprimé des centaines de cas de test.
Nous avons ajouté des talons au résultat attendu lorsque nous avons réalisé que nous perdions notre temps à analyser des chutes sans importance.
Lorsque le champ n'a pas du tout besoin d'être vérifié, le testeur écrit un symbole dans le résultat attendu:
$$ DNV $$ . Quand le champ doit être rempli, mais la valeur elle-même n'est pas importante:
$$ NE $$ .
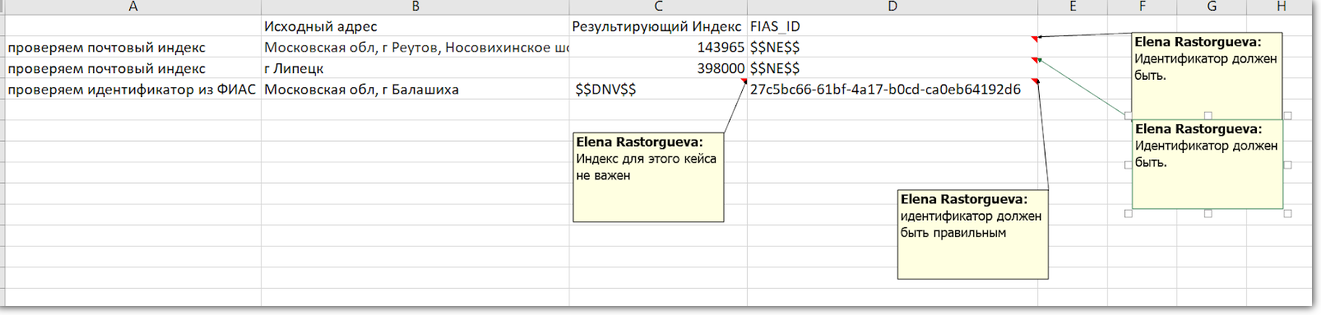 L'ID FIAS est toujours dans l'adresse, nous le vérifions donc lors de tous les tests. Si le champ est vide, quelque chose ne va pas. Mais l'index peut ne pas l'être, par conséquent, lors de la vérification de l'ID FIAS, nous ignorons l'index
L'ID FIAS est toujours dans l'adresse, nous le vérifions donc lors de tous les tests. Si le champ est vide, quelque chose ne va pas. Mais l'index peut ne pas l'être, par conséquent, lors de la vérification de l'ID FIAS, nous ignorons l'indexVous pouvez aller dans l'autre sens et séparer les tests: chaque champ a le sien. Mais c'est difficile, car tout ne peut pas être isolé. Par exemple, «ville» et «rue» font partie d'une adresse et sans elles n'ont aucun sens.
Un cadre auto-écrit est plus pratique
Par conséquent, je ne considère pas du tout la création de mon propre cadre comme une entreprise stupide. Si nous n'avions pas créé notre propre outil, nous n'aurions pas reçu autant de nouvelles opportunités et une telle flexibilité.
Désactiver le casse de texte par statut de tâche, générer un nouveau test de référence et des talons pour le résultat sont les choses que nos testeurs demandent maintenant dans d'autres cadres. Si nous prenions des solutions standard, nous ne pourrions jamais le faire.
Si vous aimez faire des choses complexes en entreprise, venez chez nous. Maintenant, nous recherchons un développeur Java , salaire de 135 000 ₽ sans impôt sur le revenu des particuliers.