Nous continuons à parler de projets de recherche communs entre nos étudiants et JetBrains Research. Dans cet article, nous parlerons des algorithmes d'apprentissage profond de renforcement qui sont utilisés pour simuler l'appareil moteur humain.
Simuler tous les mouvements humains possibles et décrire tous les scénarios de comportement est une tâche assez difficile. Si nous apprenons à comprendre comment une personne se déplace et pouvons reproduire ses mouvements «à l'image et à la ressemblance» - cela facilitera grandement l'introduction de robots dans de nombreux domaines. Juste pour que les robots apprennent à répéter et à analyser les mouvements eux-mêmes, et l'apprentissage automatique est appliqué.

À propos de moi
Je m'appelle Alexandra Malysheva, je suis diplômée du baccalauréat en mathématiques appliquées et en informatique de l'Université universitaire de Saint-Pétersbourg et depuis l'automne de cette année, je suis une étudiante de première année au HSE de Saint-Pétersbourg en programmation et analyse de données. En outre, je travaille dans le laboratoire des systèmes d'agents et de l'apprentissage renforcé, JetBrains Research, et dirige également des cours - conférences et pratiques - dans le programme de premier cycle de Saint-Pétersbourg HSE.
En ce moment je travaille sur plusieurs projets dans le domaine du deep learning avec renforcement (nous avons commencé à parler de ce que c'est dans l'article précédent). Et aujourd'hui, je veux montrer mon premier projet, qui s'est déroulé en douceur de ma thèse.
Description de la tâche

Pour simuler l'appareil moteur humain, des environnements spéciaux sont créés qui tentent de simuler le monde physique aussi précisément que possible pour résoudre un problème spécifique. Par exemple, le concours
NIPS 2017 s'est concentré sur la création d'un robot humanoïde qui simule la marche humaine.
Pour résoudre ce problème, des méthodes d'apprentissage en profondeur avec renforcement sont généralement utilisées, ce qui conduit à une bonne stratégie, mais pas optimale. De plus, dans la plupart des cas, le temps de formation est trop long.
Comme cela a été correctement noté dans l'
article précédent , le principal problème dans la transition de tâches fictives / simples à des tâches réelles / pratiques est que les récompenses dans de tels problèmes sont généralement très rares. Par exemple, nous ne pouvons évaluer le passage d'une longue distance que lorsque l'agent a atteint la ligne d'arrivée. Pour ce faire, il doit effectuer une séquence d'actions complexe et correcte, ce qui n'est pas toujours le cas. Ce problème peut être résolu en donnant à l'agent au début des exemples de la façon de «jouer» - les soi-disant démonstrations d'experts.
J'ai utilisé cette approche pour résoudre ce problème. Il s'est avéré améliorer considérablement la qualité de l'entraînement, nous pouvons utiliser des vidéos qui montrent les mouvements d'une personne en courant. En particulier, vous pouvez essayer d'utiliser les coordonnées du mouvement de parties spécifiques du corps (par exemple, les pieds) extraites d'une vidéo sur YouTube.
L'environnement
Dans les tâches d'apprentissage par renforcement, l'interaction de l'agent et de l'environnement est prise en compte. L'un des environnements modernes de modélisation de l'appareil moteur humain est l'environnement de simulation OpenSim utilisant le moteur physique Simbody.
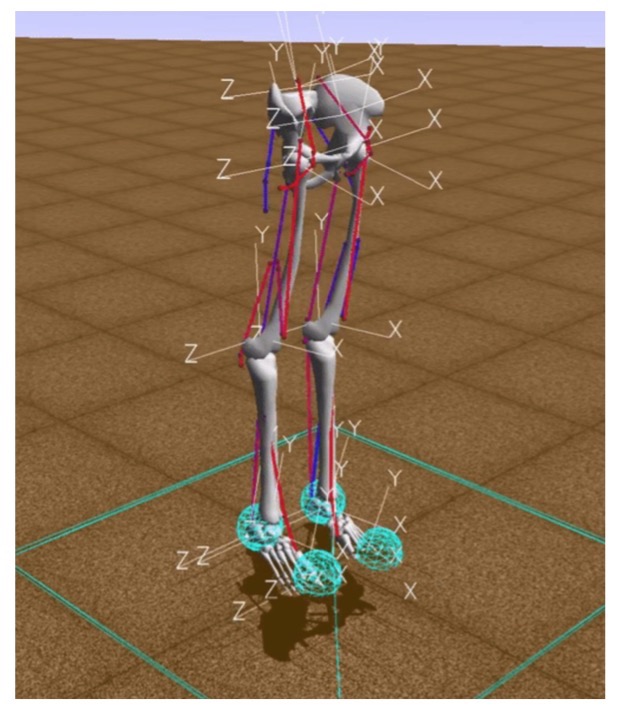
Dans cet environnement, «environnement» est un monde en trois dimensions avec des obstacles, «agent» est un robot humanoïde avec six articulations (cheville, genoux et hanches sur deux jambes) et des muscles qui simulent le comportement musculaire humain, et «l'action de l'agent» est des valeurs réelles de 0 à 1, qui spécifient la tension des muscles existants.
La récompense est calculée comme le changement de la position du bassin le long de l'axe x moins la pénalité pour l'utilisation des ligaments. Ainsi, d'une part, vous devez aller le plus loin possible dans un certain temps, et, d'autre part, faire travailler vos muscles le moins possible. L'épisode d'entraînement prend fin si 1000 itérations sont réalisées ou si la hauteur pelvienne est inférieure à 0,65 mètre, ce qui signifie que le modèle de la personne tombe.
Implémentation de base
L'objectif principal de la formation de renforcement est d'apprendre au robot à se déplacer rapidement et efficacement dans l'environnement.
Afin de tester l'hypothèse de savoir si la formation aux démonstrations aide, il était nécessaire de mettre en œuvre un algorithme de base qui apprendrait à fonctionner rapidement, mais sous-optimal, comme de nombreux exemples existants.
Pour ce faire, nous avons appliqué quelques astuces:
- Pour commencer, il a fallu adapter l'environnement OpenSim afin de pouvoir utiliser efficacement les algorithmes d'apprentissage par renforcement. En particulier, dans la description de l'environnement, nous avons ajouté des coordonnées bidimensionnelles des positions des parties du corps par rapport au bassin.
- Le nombre d'exemples de dépassement de distance dû à la symétrie du milieu a été augmenté. Dans la position initiale, l'agent se tient absolument symétriquement par rapport aux côtés gauche et droit du corps. Par conséquent, après une distance, vous pouvez ajouter deux exemples à la fois: celui qui s'est produit et le miroir symétrique par rapport au côté gauche ou droit du corps de l'agent.
- Pour augmenter la vitesse de l'algorithme, des trames ont été sautées: l'algorithme de sélection de la prochaine action d'agent n'a été lancé qu'une fois sur trois, dans les autres cas, la dernière action sélectionnée a été répétée. Ainsi, le nombre d'itérations du lancement de l'algorithme de sélection d'action d'agent a été réduit de 1000 à 333, ce qui a réduit le nombre de calculs requis.
- Les modifications précédentes ont nettement accéléré l'apprentissage, mais le processus d'apprentissage était encore lent. Par conséquent, une méthode d'accélération a également été mise en œuvre, associée à une diminution de la précision des calculs: le type de valeurs utilisées dans le vecteur d'état de l'agent est passé de double à flottant.

Ce graphique montre l'amélioration après chacune des optimisations décrites ci-dessus, il montre la récompense reçue pour une époque à partir de la formation.
Alors, qu'est-ce que YouTube a à voir avec ça?
Après avoir développé le modèle de base, nous avons ajouté une génération de récompense basée sur la fonction potentielle. Une fonction potentielle est introduite afin de donner au robot des informations utiles sur le monde qui nous entoure: nous disons que certaines positions corporelles prises par le personnage en cours d'exécution sur la vidéo sont plus «rentables» (c'est-à-dire qu'il reçoit une récompense plus importante pour elles) que d'autres.
Nous avons construit la fonction sur la base de données vidéo extraites de vidéos YouTube illustrant le déroulement de personnes réelles et de personnages humains de dessins animés et de jeux informatiques. La fonction potentielle totale a été définie comme la somme des fonctions potentielles pour chaque partie du corps: le bassin, deux genoux et deux pieds. En suivant l'approche basée sur les potentiels pour la formation de la rémunération, à chaque itération de l'algorithme, l'agent reçoit une rémunération supplémentaire correspondant à un changement des potentiels de l'état précédent et actuel. Les fonctions potentielles de différentes parties du corps ont été construites en utilisant les distances inverses entre les coordonnées correspondantes de la partie du corps dans les données générées par vidéo et le robot humanoïde.
Nous avons examiné trois sources de données:
 Becker Alan. Animation des cycles de marche - 2010
Becker Alan. Animation des cycles de marche - 2010 ProcrastinatorPro. QWOP Speedrun - 2010
ProcrastinatorPro. QWOP Speedrun - 2010 ShvetsovLeonid.HumanSpeedrun - 2015
ShvetsovLeonid.HumanSpeedrun - 2015... et trois fonctions de distance différentes:
Ici dx (dy) est la différence absolue entre la coordonnée x (y) des parties du corps correspondantes extraites des données vidéo et la coordonnée x (y) de l'agent.
Voici les résultats obtenus en comparant diverses sources de données pour une fonction potentielle basée sur PF2:

Résultats
Comparaison de la productivité entre le niveau de base et l'approche de formation de la rémunération:

Il s'est avéré que la formation de la rémunération accélère considérablement l'apprentissage, atteignant une vitesse double en 12 heures de formation. Le résultat final après 24 heures montre encore un avantage significatif de l'approche utilisant la méthode des fonctions potentielles.
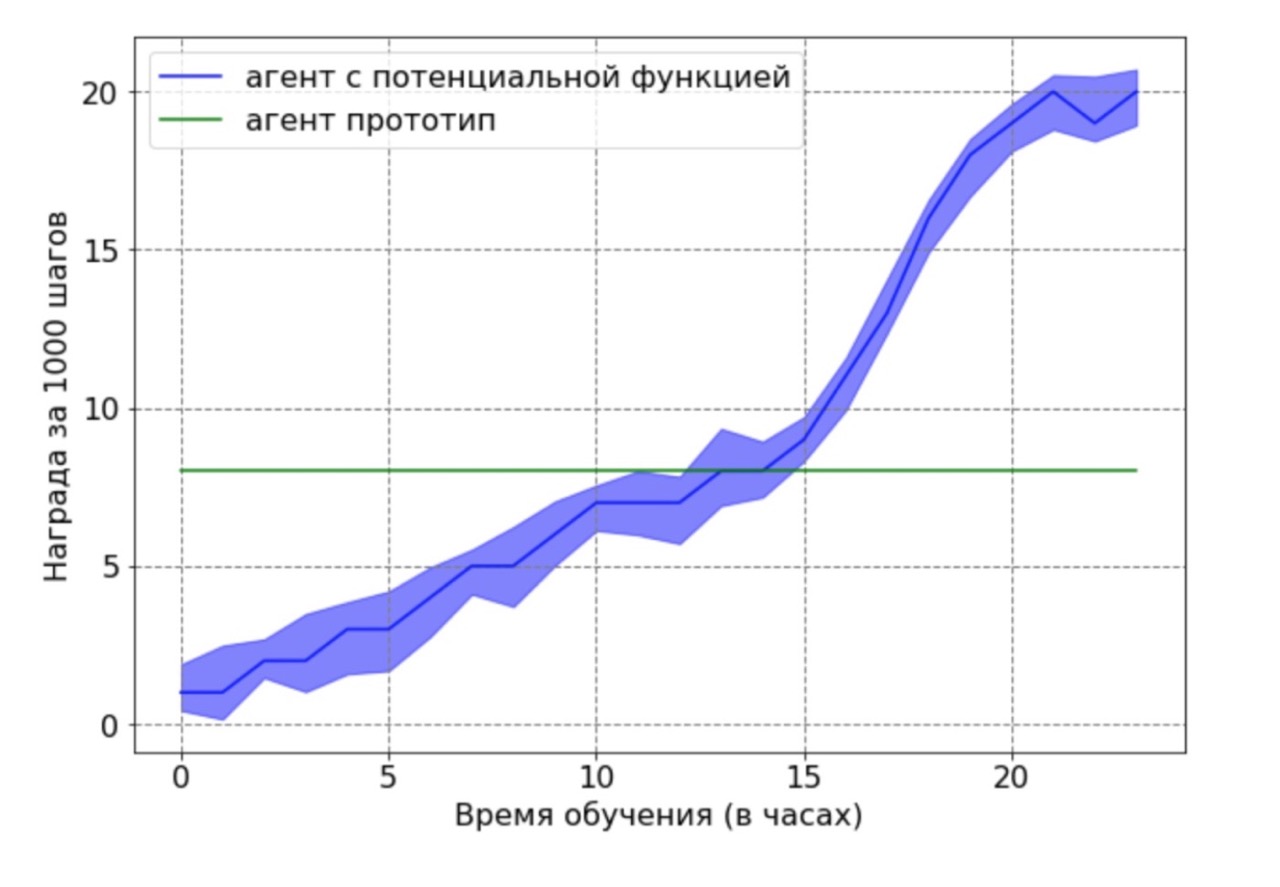
Séparément, je voudrais noter le résultat important suivant: nous avons pu théoriquement prouver qu'une rémunération basée sur une fonction potentielle n'aggrave pas une politique optimale. Afin de démontrer cet avantage dans ce contexte, nous avons utilisé un agent sous-optimal généré par l'agent de base après 12 heures de formation. L'agent prototype résultant a été utilisé comme source de données pour une fonction potentielle. De toute évidence, l'agent obtenu avec cette approche ne fonctionnera pas de manière optimale, et les positions des pieds et des genoux dans la plupart des cas ne seront pas dans des positions optimales. Ensuite, l'agent formé par l'algorithme DDPG utilisant la fonction potentielle a été formé sur les données obtenues. Ensuite, une comparaison a été faite des résultats d'apprentissage d'un agent ayant une fonction potentielle avec un agent prototype. Le calendrier de formation des agents montre que l'agent RL est capable de surmonter les performances sous-optimales de la source de données.
Premiers pas dans la science
J'ai terminé le projet de fin d'études assez tôt. Je voudrais noter que nous avons une approche très responsable de la protection d'un diplôme. Depuis septembre, les étudiants connaissent le sujet, les critères d'évaluation, quoi et quand faire. Quand tout est si clair, c'est très pratique de travailler, on n'a pas l'impression "J'ai une année entière devant moi, je peux commencer à faire la semaine / mois / six mois". Par conséquent, si vous travaillez efficacement, vous pouvez obtenir les résultats finaux de la thèse d'ici le Nouvel An et passer le temps restant à mettre en place le modèle, à collecter des résultats statistiquement significatifs et à rédiger le texte du diplôme. C'est exactement ce qui m'est arrivé.
Deux mois avant que le diplôme ne soit défendu, j'avais déjà le texte du travail prêt, et mon conseiller scientifique, Aleksey Aleksandrovich Shpilman, a suggéré d'écrire un article sur l'
atelier sur les agents adaptatifs et d'apprentissage (ALA) à l'ICML-AAMAS. La seule chose que je devais faire était de traduire et de reconditionner ma thèse. En conséquence, nous avons envoyé un article à la conférence et ... il a été accepté! C'était ma première publication et j'étais extrêmement heureux quand j'ai vu une lettre avec le mot "Accepté" dans mon courrier. Malheureusement, en même temps, je me suis entraîné en Corée du Sud et je n'ai pas pu assister personnellement à la conférence.
En plus de
publier et de reconnaître le travail accompli, la première conférence m'a apporté un autre résultat agréable. Alexey Alexandrovich a commencé à m'attirer pour écrire une critique du travail des autres. Il me semble que cela est très utile pour acquérir de l'expérience dans l'évaluation de nouvelles idées: de cette façon, vous pouvez apprendre à analyser le travail existant, vérifier l'originalité et la pertinence de l'idée.
Écrire un article sur l'atelier, c'est bien, mais sur la voie principale c'est mieux
Après la Corée, j'ai obtenu un stage chez JetBrains Research et j'ai continué à travailler sur le projet. C'est à ce stade que nous avons testé trois formules différentes pour une fonction potentielle et fait une comparaison. Nous voulions vraiment partager les résultats de notre travail, nous avons donc décidé d'écrire un article complet lors de la conférence sur la piste principale de l'
ICARCV à Singapour.
Écrire un article dans un atelier, c'est bien, mais sur une piste principale c'est mieux. Et, bien sûr, j'étais très heureux quand j'ai découvert que l'article avait été accepté! De plus, nos collègues et sponsors de JetBrains ont accepté de payer mon voyage à la conférence. Un énorme bonus a été l'occasion de se familiariser avec Singapour.
Lorsque les billets ont déjà été achetés, l'hôtel était réservé et je n'ai pu obtenir qu'un visa, j'ai reçu une lettre par la poste:

Je n'ai pas obtenu de visa malgré le fait que j'avais des documents confirmant mon discours à la conférence! Il s'avère que l'ambassade de Singapour n'accepte pas les candidatures de filles célibataires et sans emploi de moins de 35 ans. Et même si la fille travaille mais n'est pas mariée, la chance d'obtenir un refus est toujours très grande.
Heureusement, j'ai appris que les citoyens de la Fédération de Russie voyageant en transit peuvent rester à Singapour jusqu'à 96 heures. En conséquence, je me suis envolé pour la Malaisie via Singapour, où j'ai passé près de huit jours au total. La conférence elle-même a duré six jours. En raison de restrictions, j'ai assisté aux quatre premiers, puis j'ai dû quitter pour revenir pour la fermeture. Après la conférence, j'ai décidé de me sentir comme un touriste et j'ai juste fait le tour de la ville pendant deux jours et visité des musées.
J'ai préparé un discours à l'ICARCV à l'avance, de retour à Saint-Pétersbourg. Répété lors d'un atelier de formation en renforcement. Par conséquent, parler à la conférence était excitant, mais pas effrayant. La présentation elle-même a duré 15 minutes, mais après elle, il y avait une section de questions, qui m'a semblé très utile.
On m'a posé des questions assez intéressantes qui ont suscité de nouvelles idées. Par exemple, sur la façon dont nous avons balisé les données. Dans notre travail, nous avons annoté les données manuellement et on nous a proposé d'utiliser une bibliothèque qui comprend automatiquement où se trouvent les parties du corps humain. Maintenant, nous venons de commencer à mettre en œuvre cette idée. Vous pouvez lire l'ensemble du travail
ici .
À l'ICARCV, j'ai aimé communiquer avec les scientifiques et j'ai appris beaucoup de nouvelles idées. Le nombre d'articles intéressants que j'ai rencontrés ces derniers jours a été supérieur à celui des quatre années précédentes. Il existe désormais un «battage médiatique» pour l'apprentissage automatique dans le monde, et chaque jour des dizaines de nouveaux articles apparaissent sur Internet, parmi lesquels il est très difficile de trouver quelque chose qui en vaille la peine. C'est pour cela, il me semble, qu'il vaut la peine d'aller à des conférences: pour trouver des communautés qui discutent de nouveaux sujets intéressants, apprennent de nouvelles idées et partagent les leurs. Et faites-vous des amis!